この記事は MIXI DEVELOPERS Advent Calendar 2022 - Qiita の8日目です。
エンジニアからPOにジョブチェンジしてちょうど1年になりました。開発からもすっかり手離れし、もはやコードらしきものを書くのはBigQueryぐらいです。
解析をするときはなぜか時間に追われていることが多いためついつい雑な書き方になりがち。後から何がしたかったのか思い出せないクエリになっていることもしばしば……。
エンジニアらしく可読性と保守性の高いクエリにしていきたい!という気持ちをこめて、よく使う変換式や関数をまとめてみました。
初歩的なところも多く記載していますが、改めてなにか一つ学びがあれば嬉しいです。
はじめに
記事の対象者
- 基本的なSQLは理解している人
- 毎回検索してコピペでなんとかしてしまいしがちな人
- GoogleAnalytics4(以下GA4)+BigQueryなデータを解析することが多い人
- GA4のコンソールよりも精緻な数値を取得したい人
- (もしくはGA4のコンソールを使いこなせない人←私)
注意事項
- この記事内ではコードの可読性を(比較的)重視しており、そのためクエリのパフォーマンスへの配慮は特にしておりません
- 同様に課金額への考慮もしておりません。BigQueryでは実行時にジョブ情報欄から「処理されたバイト数」「課金されるバイト数」等を見ることができますので状況に応じてご利用ください
説明のために使用するデータ
GA4の公開データ bigquery-public-data.ga4_obfuscated_sample_ecommerce.events_* を利用します。
導入方法: Google アナリティクス 4 e コマースウェブ実装向けの BigQuery サンプル データセット | Google Analytics BigQuery Export | Google Developers
よく使う、基本的なフィールド加工〜コンソールの使い方を添えて〜
ユーザーの閲覧環境でセグメント分けする
ここでは「ユーザーの閲覧環境ごとのPV、UU、PV/UUを計測する」というお題をベースに、BigQuery コンソールに備わった機能を合わせて紹介していきます。
まずはデータを知るところから
BigQueryのコンソールでは、「プレビュー」を使うことで、それぞれのカラムにどんなデータが入っているのかすぐに確認できます。
また、「スキーマ」というタブではデータの型が記載されています。なんとなくでやっていくよりも型を理解したほうが早いです。
慣れないうちはこちらの画面を別タブで開いたままにしておき、確認しながら進めるといいかもしれません。
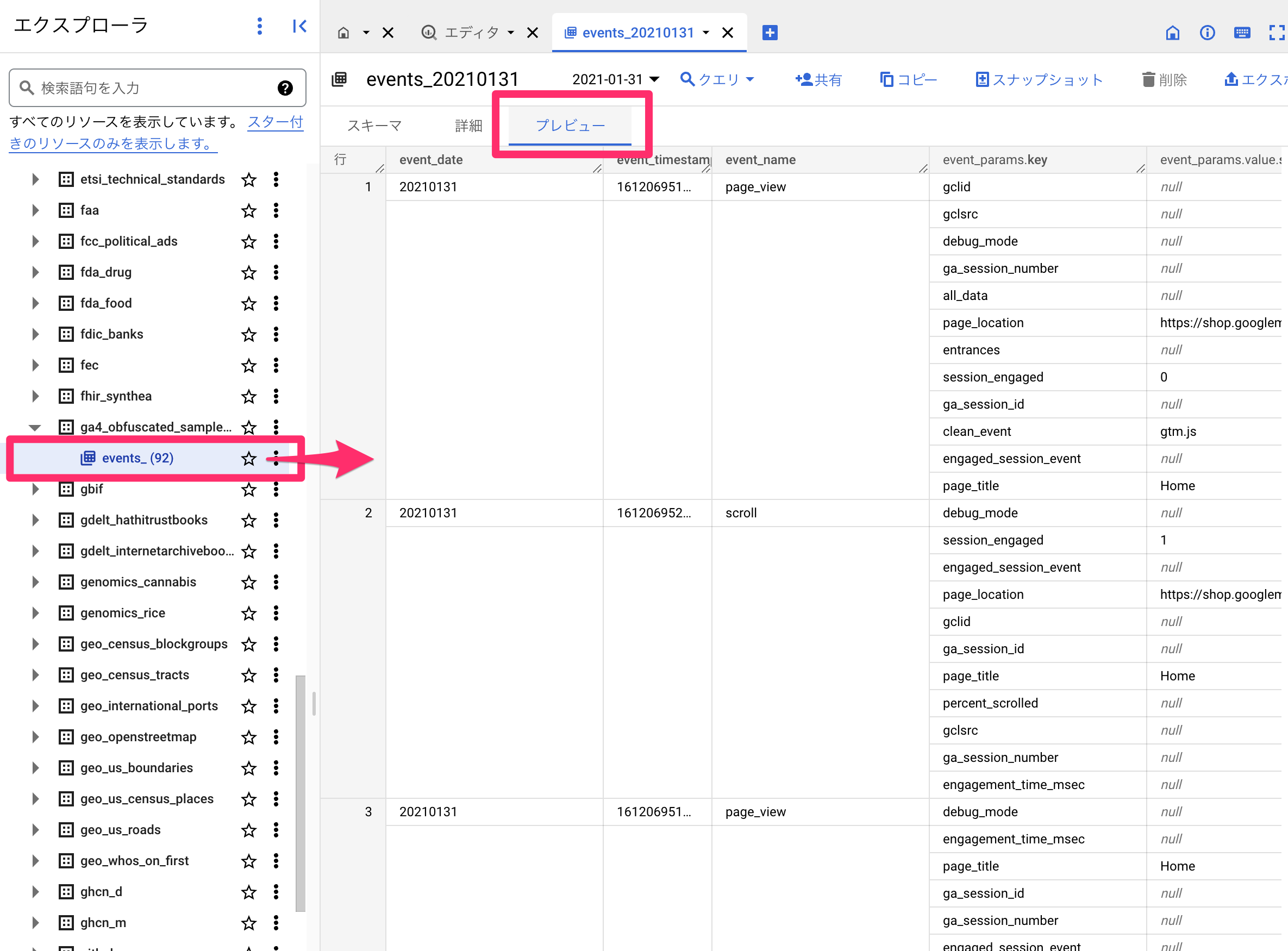
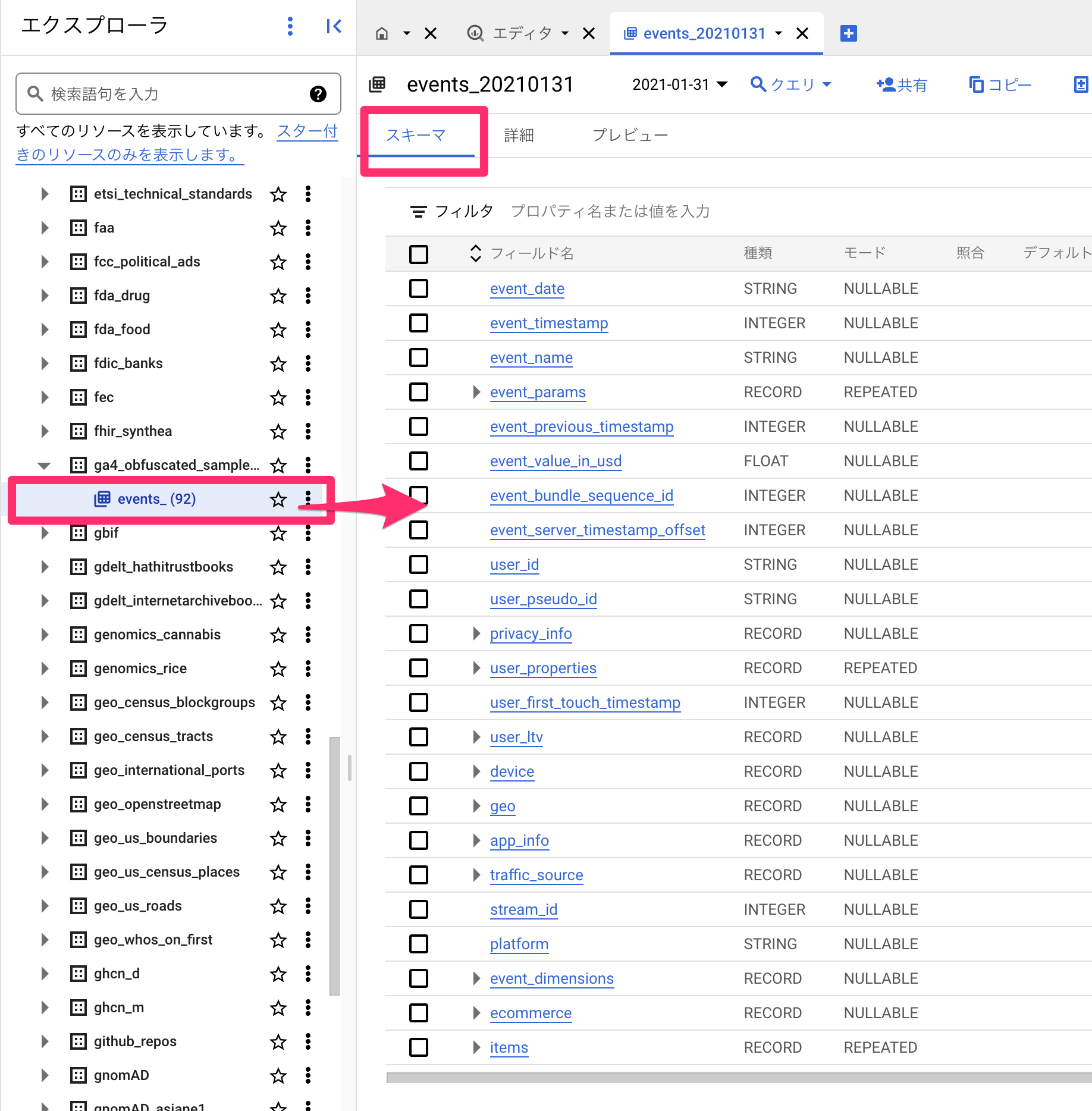
スキーマについては記事の後半でも紹介します。
クエリを書く
基本的なSQLと大きく変わるところはありませんので割愛します。
以下のようなクエリができあがったとしましょう。
SELECT
device.category,
platform,
COUNT(user_pseudo_id) AS pv,
COUNT(DISTINCT user_pseudo_id) AS uu,
COUNT(user_pseudo_id)/COUNT(DISTINCT user_pseudo_id) AS pv_per_uu
FROM
`bigquery-public-data.ga4_obfuscated_sample_ecommerce.events_20210131`
WHERE event_name in ('page_view', 'screen_view') -- page_viewはwebのPV、screen_viewはアプリのPVに相当するもの
GROUP BY
device.category,
platform
ORDER BY pv DESC
memo: コメント
クエリにコメントを書くには以下の方法があります。
適宜コメントを残してクエリの可読性を担保しましょう。
-- このコメントはシングルラインコメントです
SELECT -- このコメントはインラインコメントです
/*
このコメントはマルチラインコメントです。
複数行のコメントを書けます。
*/
hoge_item
FROM hoge_table
WHERE /* このコメントはインラインコメントです */ hoge_param = true
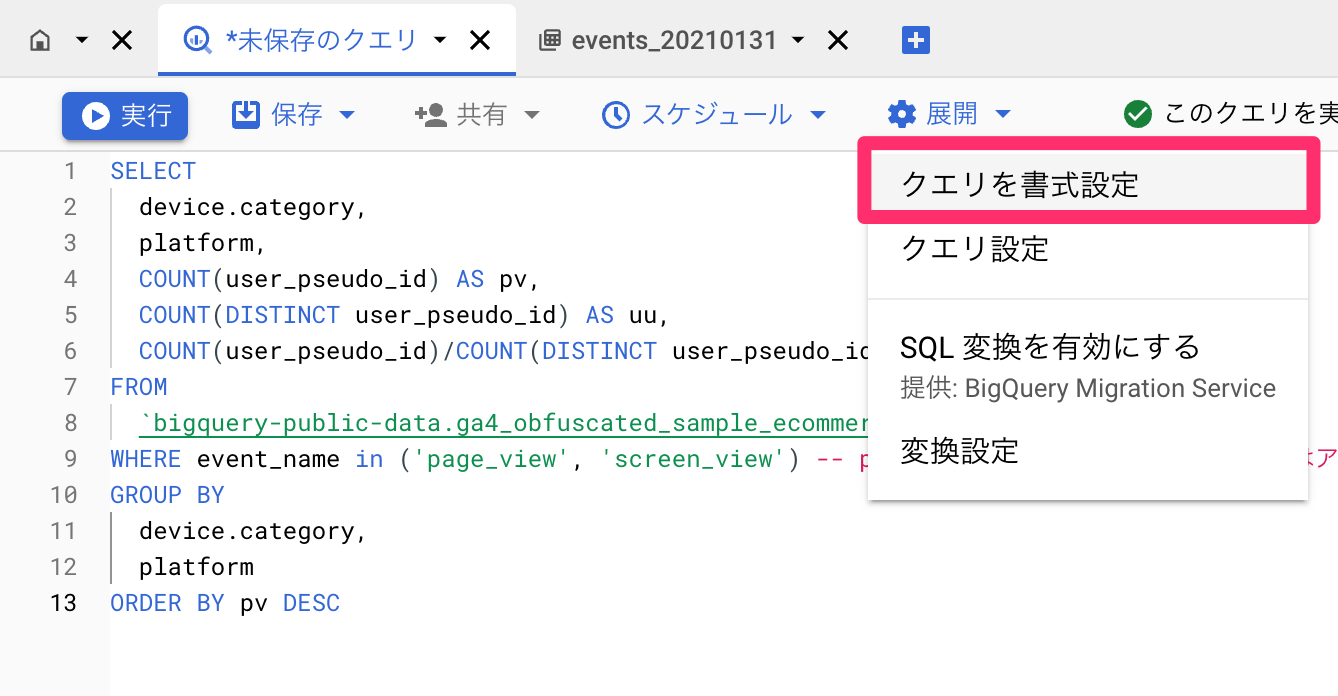
memo: フォーマット
クエリを書いたら適宜右上の「展開>クエリを書式設定」を使ってフォーマットをかけましょう。
文法の誤りに気が付きやすくなります。
クエリを実行してみる
さて、先ほどのクエリを実行してみます。
実行結果

ユーザーの閲覧環境はGA4で標準的に取得される以下のフィールドから得られます。
- device: デバイス。使っているスマホやPCがどういったものか
- category: 大まかなカテゴリ。mobile, tablet, desktop, smart tv
- 他、メーカー、OSバージョンブラウザなどetc...
- platform: プラットフォーム。サービス側の提供しているどのプラットフォームのものを使っているか。WEB, IOS, ANDROID
サンプルデータセットにはアプリのデータは含まれていないようなので、参考に別PJのデータで実行した結果はこちらです。platformにANDROID, IOSが増えていますね。

扱いやすいようにまとめてみる
一般的なwebサービスの集計でよく使うパターンだとこのような感じでしょうか。
パターンが多すぎても扱いづらいので、iOS, Android, Web(PC), Web(SP) にまとめてみました。
複数カラムの結果を1つの情報にまとめる際に CASE 文は便利です。
SELECT
(CASE platform
WHEN 'IOS' THEN 'iOS'
WHEN 'ANDROID' THEN 'Android'
WHEN 'WEB' THEN ( CASE device.category
WHEN 'mobile' THEN 'WEB(SP)'
WHEN 'desktop' THEN 'WEB(PC)'
ELSE
'WEB(others)'
END
)
ELSE
'unknown'
END
) AS custom_device,
COUNT(user_pseudo_id) AS pv,
COUNT(DISTINCT user_pseudo_id) AS uu,
COUNT(user_pseudo_id)/COUNT(DISTINCT user_pseudo_id) AS pv_per_uu
FROM
`bigquery-public-data.ga4_obfuscated_sample_ecommerce.events_20210131`
GROUP BY
custom_device
ORDER BY pv DESC
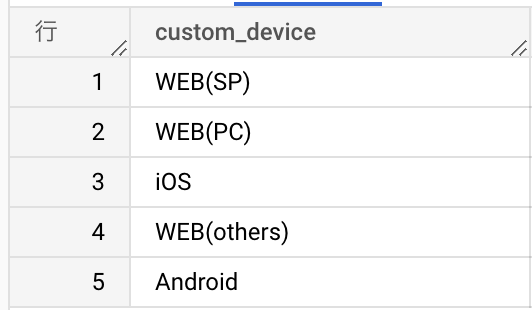
それぞれの項目にどのようなデータが入るかはGA4やFirebaseのヘルプにまとめられています(プラットフォーム / デバイス の項目)。
memo: よく使うクエリは保存しておこう
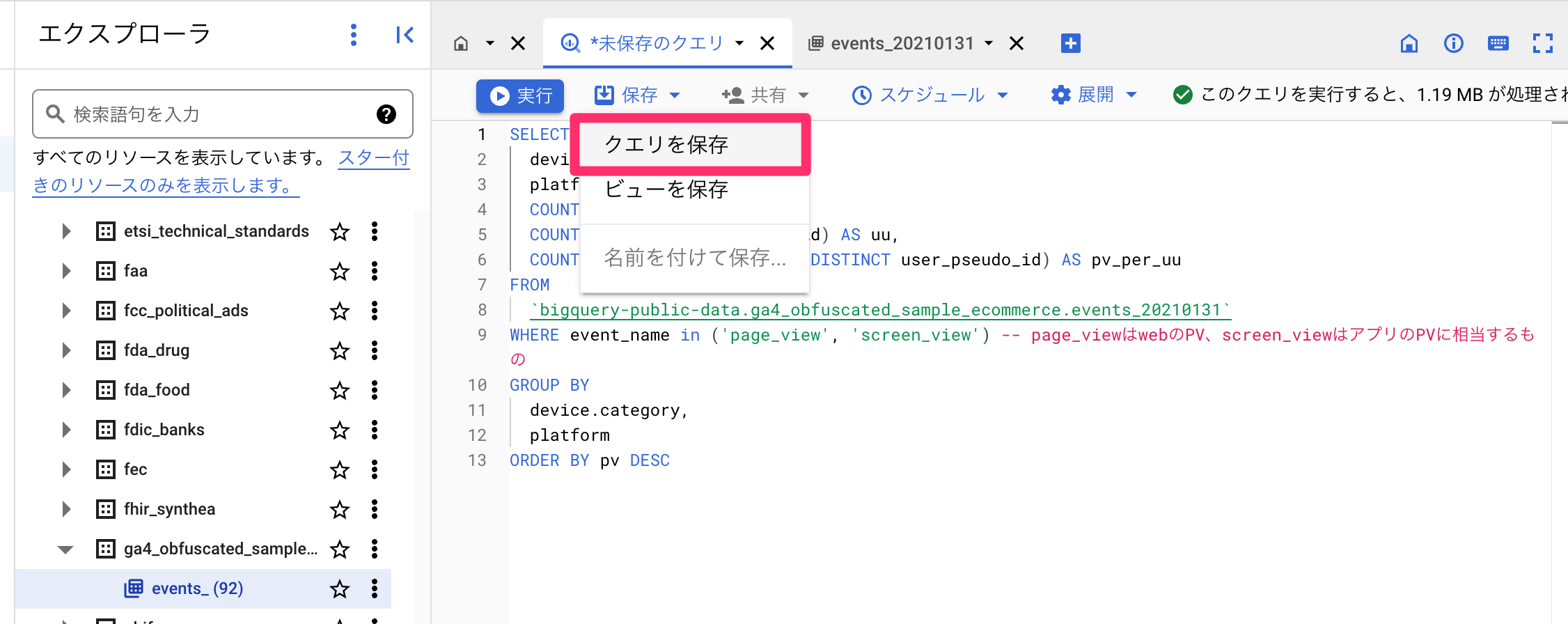
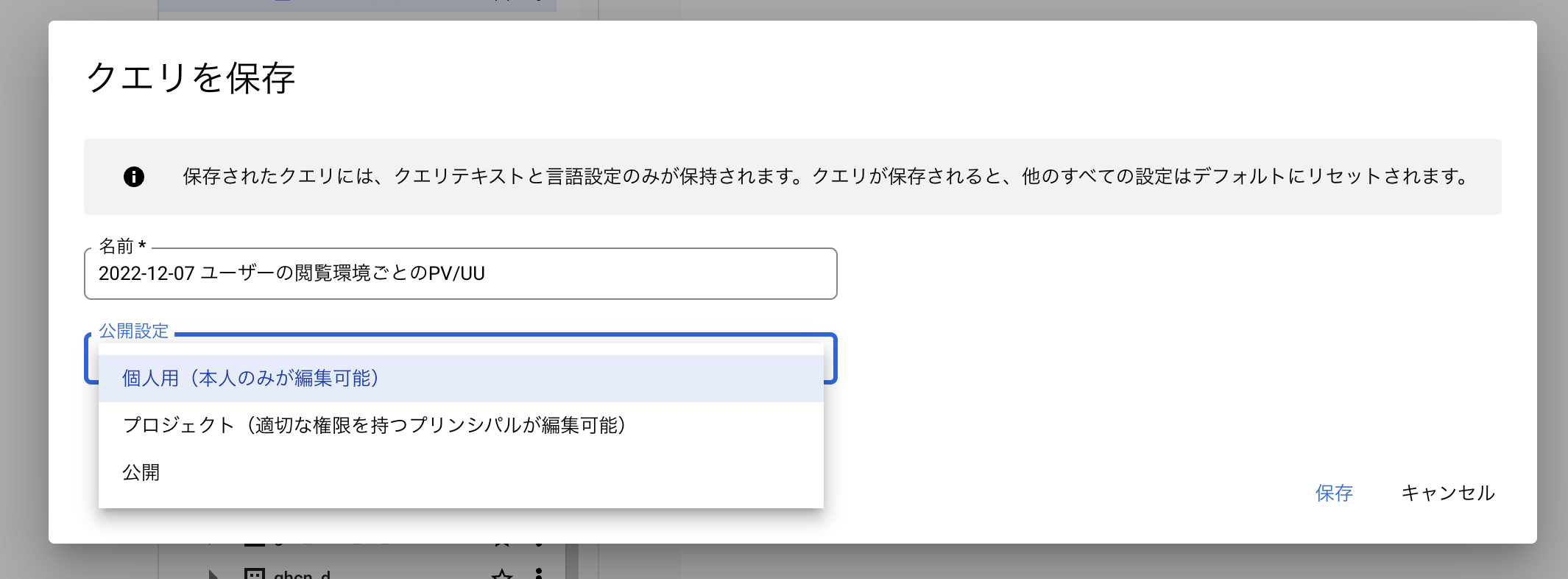
よく使うクエリは、実行ボタンの右隣の「保存>クエリを保存」から保存しておきましょう。
分かりやすい名前をつけておきましょう。
また、チームメンバーにも使ってほしい場合は公開設定を「プロジェクト」にすると他の人もクエリが扱えるようになります。見えるだけでなく編集もできてしまう点は注意ですが、うまく情報共有して活用してください。
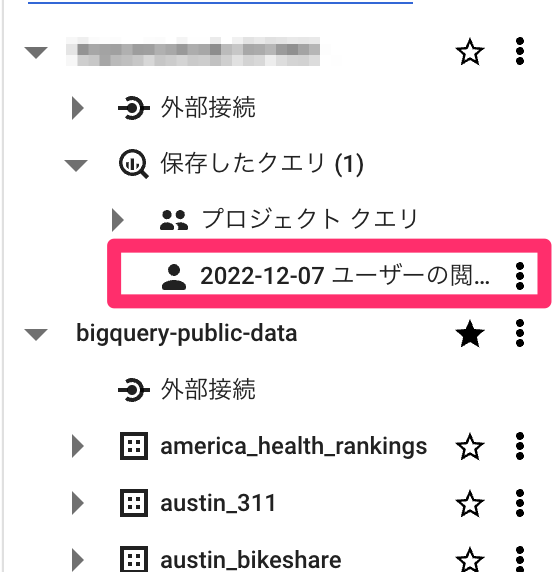
保存したクエリはサイドバーの「保存したクエリ」の中にあります。
memo: AS alias のできること
SELECT hoge_long_name AS hoge FROM...
といった形で AS を使ってフィールドにエイリアスを設定することは多々あると思いますが、どんな場面で使えるか確認しておきます。
-
ASを使える箇所はSELECTとFROM句 -
ASは省略可能 - エイリアスには英数字とアンダースコア(
_)からなる300文字以内の文字列のみ設定可能(日本語使いたいな…) -
SELECTで設定したエイリアスを利用できる箇所はGROUP BY句、ORDER BY句、HAVING句(上のクエリでORDER BY pv DESCとできたように) -
FROM句で設定したエイリアスを利用できる箇所はFROM句でその後に続くパス式のみ(パス式とはt.hoge_fieldのように子要素にアクセスする形式のこと/この説明は不正確かもしれません…)
詳細: クエリ構文 | BigQuery | Google Cloud
時間表記を変換する
様々な時間表記を変換してみます。
その前に基本をおさらい
BigQuery向けの標準SQLには以下の4つの型が用意されています。
memo: タイムゾーンについて事前補足
List of tz database time zones - Wikipedia
こちらの表の TZ database name 列の表記を使うのが間違いないです。abbreviation(略語)の方は関数によって使えたり使えなかったりするようでした。
memo: DATE 型(日付)
2022-12-03 のような形式。タイムゾーン未指定の場合はUTCとなります。
SELECT
CURRENT_DATE() AS utc,
CURRENT_DATE('Asia/Tokyo') AS jst, -- 'JST' でも ok
CURRENT_DATE('HST') AS hst; -- 'Pacific/Honolulu' のこと

memo: TIME 型(時間)
07:07:24.231025 のような形式。タイムゾーン未指定の場合はUTCとなります。
SELECT
CURRENT_TIME() AS utc,
CURRENT_TIME('Asia/Tokyo') AS jst,
CURRENT_TIME('HST') AS hst;

memo: DATETIME 型(日時)
2022-12-03T07:04:53.215916 のような形式。タイムゾーン未指定の場合はUTCとなります。
SELECT
CURRENT_DATETIME() AS utc,
CURRENT_DATETIME('Asia/Tokyo') AS jst,
CURRENT_DATETIME('HST') AS hst;

memo: TIMESTAMP 型(タイムスタンプ)
タイムゾーンなどに関係なく、絶対的な時刻を返します。
日付としての実用上は DATETIME でも TIMESTAMP でも変わらないことが解析の現場では多いのではないでしょうか。
とはいえ値の扱い方は大きく変わるので注意が必要です。
SELECT
CURRENT_TIMESTAMP() AS utc

memo: TIMESTAMP 型を日本時間表記にする
フォーマットの書き方はこちらを参照
[形式設定要素 | BigQuery | Google Cloud]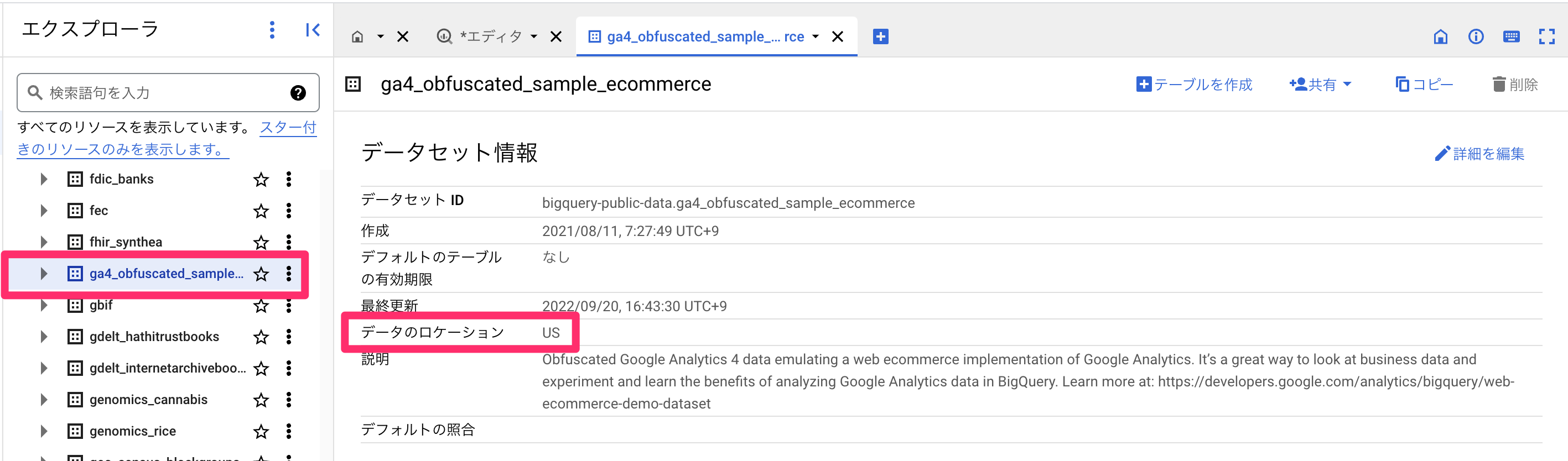
(https://cloud.google.com/bigquery/docs/reference/standard-sql/format-elements?hl=ja#format_elements_date_time)
なお、以下のようにフォーマットした後の型は STRING となるため、他の時間情報と比較する際などに必要なタイムゾーン情報などは失われています。フォーマットは最後にするように心がけた方がよさそうです。
SELECT
CURRENT_TIMESTAMP() AS utc,
FORMAT_TIMESTAMP('%Y-%m-%d %H:%M:%S', CURRENT_TIMESTAMP(), 'UTC') AS formatted_utc,
FORMAT_TIMESTAMP('%F %T', CURRENT_TIMESTAMP(), 'UTC') AS formatted_utc_2, -- %F は %Y-%m-%d, %T は %H:%M:%S と同義
FORMAT_TIMESTAMP('%F %T', CURRENT_TIMESTAMP(), 'Asia/Tokyo') AS formatted_jst,
FORMAT_TIMESTAMP('%F %T', CURRENT_TIMESTAMP(), 'HST') AS formatted_hst;

evnet_timestamp 1612069510766593 → 2021-01-31 05:05:10 (日本時間)
ここからが本題です。
前述の TIMESTAMP 型とまぎらわしいのですが、GA4のイベントに含まれる event_timestamp というフィールドは INTEGER 型であり、UNIXTIMEにおけるマイクロ秒を表しています。
これを見やすい日本時間表記にするには、以下のように2段階の変換を行う必要があります。
- INTEGER -> TIMESTAMP
- TIMESTAMP -> STRING
SELECT
event_timestamp,
TIMESTAMP_MICROS(event_timestamp) AS utc,
FORMAT_TIMESTAMP('%Y-%m-%d %H:%M:%S', TIMESTAMP_MICROS(event_timestamp), 'UTC') AS formatted_utc,
FORMAT_TIMESTAMP('%F %T', TIMESTAMP_MICROS(event_timestamp), 'UTC') AS formatted_utc_2,
-- %F は %Y-%m-%d, %T は %H:%M:%S と同義
FORMAT_TIMESTAMP('%F %T', TIMESTAMP_MICROS(event_timestamp), 'Asia/Tokyo') AS formatted_jst,
FORMAT_TIMESTAMP('%F %T', TIMESTAMP_MICROS(event_timestamp), 'HST') AS formatted_hst
FROM
`bigquery-public-data.ga4_obfuscated_sample_ecommerce.events_20210131`
LIMIT
1

event_timestamp を使って時間の比較
この時間帯にどれくらいのアクセスがあったか、といった数値を調べるのに使える比較です。
クエリを書く側にとって理解しやすいように、タイムゾーンを考慮しつつ TIMESTAMP 形式にして比較し、 CASE文で時間帯をまとめています。
SELECT
CASE
WHEN TIMESTAMP_MICROS(event_timestamp) < TIMESTAMP('2021-01-31 00:00:00', 'Asia/Tokyo') THEN '2021-01-30'
WHEN TIMESTAMP_MICROS(event_timestamp) BETWEEN TIMESTAMP('2021-01-31 00:00:00', 'Asia/Tokyo') AND TIMESTAMP('2021-01-31 12:00:00', 'Asia/Tokyo') THEN '2021-01-31 AM'
WHEN TIMESTAMP_MICROS(event_timestamp) BETWEEN TIMESTAMP('2021-01-31 12:00:00', 'Asia/Tokyo') AND TIMESTAMP('2021-02-01 00:00:00', 'Asia/Tokyo') THEN '2021-01-31 PM'
ELSE '2021-02-01'
END
AS period,
COUNT(DISTINCT user_pseudo_id) AS uu
FROM
`bigquery-public-data.ga4_obfuscated_sample_ecommerce.events_2021013*` -- このデータセットはUS時間なので、日本時間の1月31日のAM/PMを正確に得るために30日、31日の2日分のデータを使ってみました
GROUP BY period
ORDER BY period

個人的な時短ワザとして、このあたりのよく使う日付変換は IME に登録してしまっています。最近は IME の辞書ツールにかなり長い文字列も登録できるので助かります。

event_date 20210131 → 2021-01-31
event_date は、YYYYmmddの8桁で表された文字列形式の日付です。パーティションの日付と同じ日付が入っています。
bigquery-public-data.ga4_obfuscated_sample_ecommerce.events_20210131
と指定したならそのデータセットの event_date はすべて 20210131 のはずです。
event_date をハイフンつなぎなど読みやすい形に変換する場合は以下のように2段階で変換する必要があります。
※こんなことをするよりは event_timestamp を利用したほうがいいと思いますが。。。
- STRING -> DATE (PARSE_DATE)
- DATE -> STRING (FORMAT_DATE)
SELECT
event_date,
PARSE_DATE('%Y%m%d', event_date) AS parse_date,
FORMAT_DATE('%Y-%m-%d', PARSE_DATE('%Y%m%d', event_date)) AS format_date
FROM
`bigquery-public-data.ga4_obfuscated_sample_ecommerce.events_20210131`
LIMIT
1

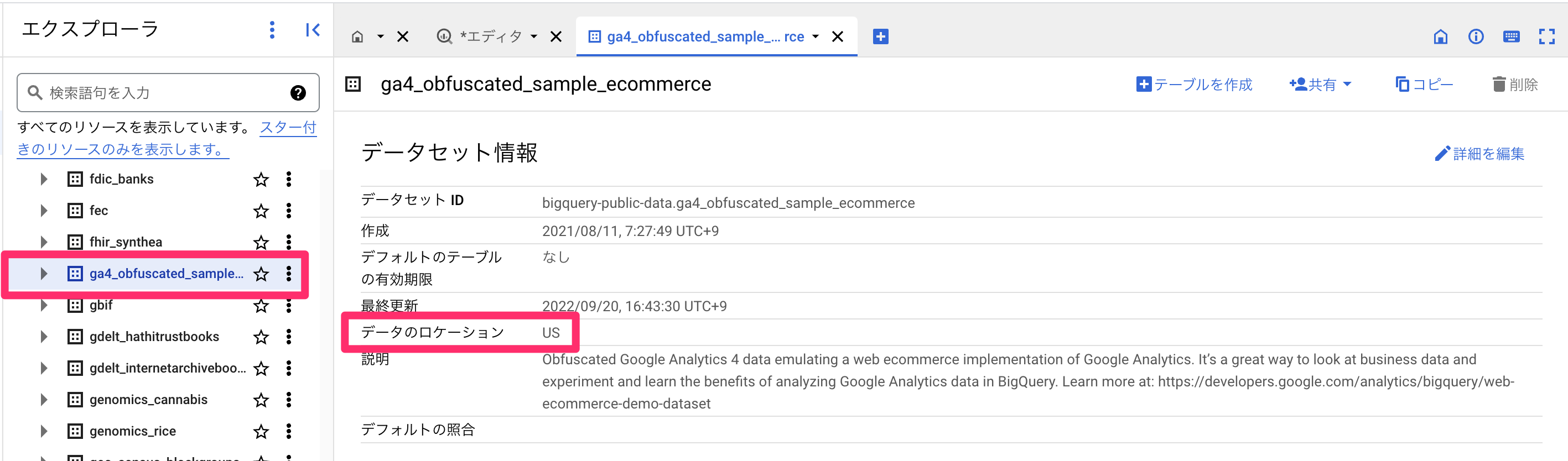
memo: BigQueryのデータのタイムゾーンについて
日本国内を中心としたプロダクトであれば日本時間の日付でエクスポートされるよう設定してあるはずです。グローバルなプロダクトの場合はUTCかもしれませんので、GA4のレポートのタイムゾーンまたはBigQueryコンソールから「データセット情報>データのロケーション」を確認してみてください。
[GA4] アナリティクスで新しいウェブサイトまたはアプリのセットアップを行う - アナリティクス ヘルプ
よく使う、ちょっとややこしいフィールド加工
UNNESTを理解してevent_paramsを扱う
BigQueryのデータの扱いでいちばん最初にハマるのが event_params だと思います。
event_params の型
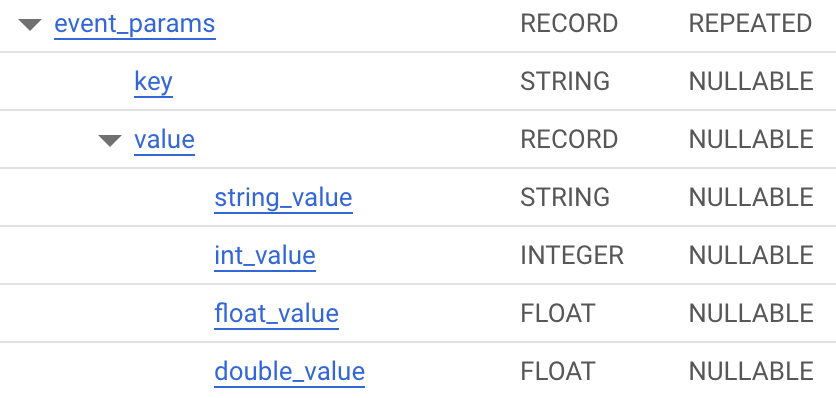
event_params は RECORD 型の構造体で、GAにイベントを送る時に追加した任意の情報が乗ってくるのもこのフィールドです。
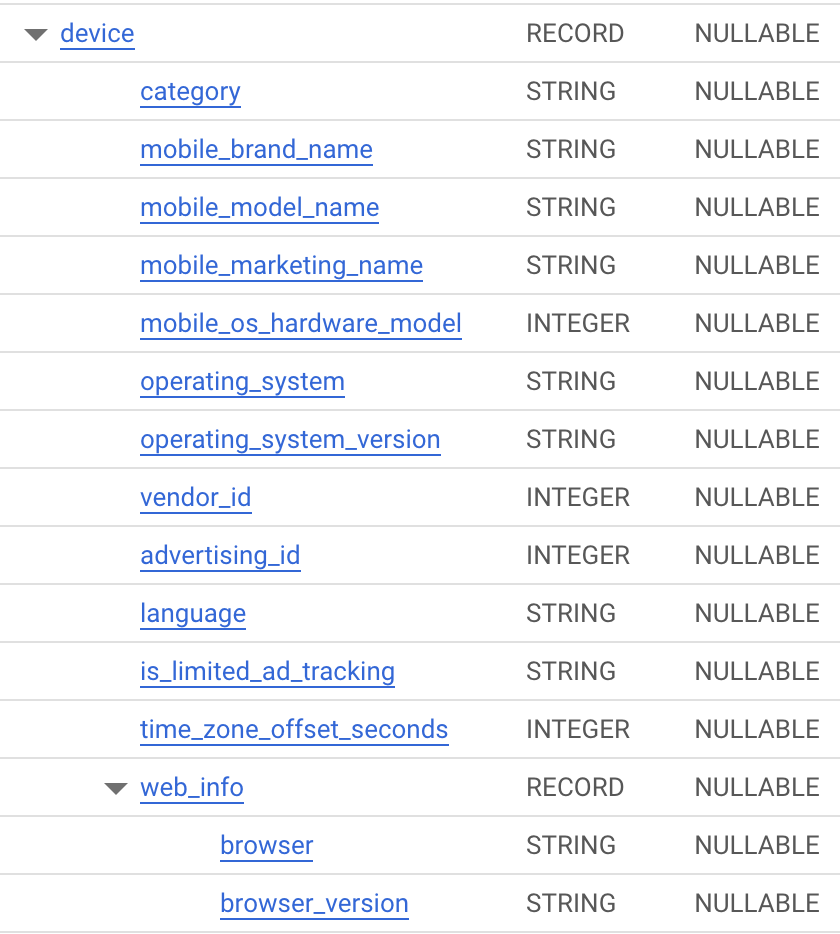
RECORD 型といえば初めに紹介した device も RECORD 型ですが、あちらは device.category のように簡単にアクセスすることができました。
ですが event_params はそういった書き方ができません。
いったい何が違うのでしょうか。
| event_params | device |
|---|---|
|
|
「種類」は同じ RECORD ですが、「モード」が REPEATED と NULLABLE で違うのが気になりますね。
REPEATED は繰り返し列であるということを意味しています。つまり device がただの単一の構造体であるのに対し、 event_params は 構造体の配列 だということです。
この画面(スキーマタブ)だと分かりづらいので、エラーメッセージを出して(力技)、本来の型を調べるとイメージしやすくなります。
ARRAY<
STRUCT<
key STRING,
value STRUCT<
string_value STRING,
int_value INT64,
float_value FLOAT64,
double_value FLOAT64
>
>
>
つまりイメージは…:
[{key_1: {string_value: 'hoge', int_value: null, ...}}, {key_2: {string_value: null, int_value: 123, ...}}, ...]
STRUCT<
category STRING,
mobile_brand_name STRING,
mobile_model_name STRING,
...
>
つまりイメージは…:
{category: 'mobile', mobile_brand_name: 'apple'...}
実際のデータはこんな感じです。1レコードの情報量が多い。
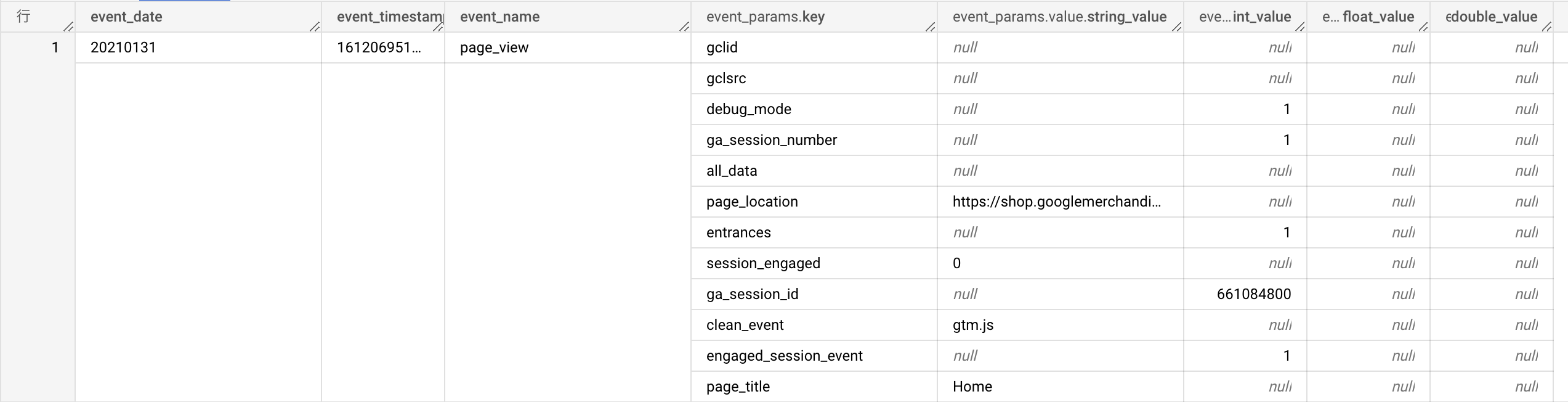
データを1件 SELECT してきて、「クエリ結果>JSON」を見てみるとより理解できるかもしれません。
event_paramsとdeviceをJSONで見てみる
[{
"event_params": [{
"key": "gclid",
"value": {
"string_value": null,
"int_value": null,
"float_value": null,
"double_value": null
}
}, {
"key": "gclsrc",
"value": {
"string_value": null,
"int_value": null,
"float_value": null,
"double_value": null
}
}, {
"key": "debug_mode",
"value": {
"string_value": null,
"int_value": "1",
"float_value": null,
"double_value": null
}
}, {
"key": "ga_session_number",
"value": {
"string_value": null,
"int_value": "1",
"float_value": null,
"double_value": null
}
}, {
"key": "all_data",
"value": {
"string_value": null,
"int_value": null,
"float_value": null,
"double_value": null
}
}, {
"key": "page_location",
"value": {
"string_value": "https://shop.googlemerchandisestore.com/",
"int_value": null,
"float_value": null,
"double_value": null
}
}, {
"key": "entrances",
"value": {
"string_value": null,
"int_value": "1",
"float_value": null,
"double_value": null
}
}, {
"key": "session_engaged",
"value": {
"string_value": "0",
"int_value": null,
"float_value": null,
"double_value": null
}
}, {
"key": "ga_session_id",
"value": {
"string_value": null,
"int_value": "661084800",
"float_value": null,
"double_value": null
}
}, {
"key": "clean_event",
"value": {
"string_value": "gtm.js",
"int_value": null,
"float_value": null,
"double_value": null
}
}, {
"key": "engaged_session_event",
"value": {
"string_value": null,
"int_value": "1",
"float_value": null,
"double_value": null
}
}, {
"key": "page_title",
"value": {
"string_value": "Home",
"int_value": null,
"float_value": null,
"double_value": null
}
}],
"device": {
"category": "mobile",
"mobile_brand_name": "Apple",
"mobile_model_name": "iPhone",
"mobile_marketing_name": "\u003cOther\u003e",
"mobile_os_hardware_model": null,
"operating_system": "Web",
"operating_system_version": "\u003cOther\u003e",
"vendor_id": null,
"advertising_id": null,
"language": "en-us",
"is_limited_ad_tracking": "No",
"time_zone_offset_seconds": null,
"web_info": {
"browser": "Safari",
"browser_version": "13.1"
}
}
}]
参考: テーブル スキーマでネストされた列と繰り返し列を指定する | BigQuery | Google Cloud
UNNEST 方式
構造を理解した上で、集計をしてみましょう。
event_params を使って集計をする際の基本的な使い方は、以下のように UNNEST した一時テーブルを作り、必要な key でフィルタリングすることです。UNNEST は SELECT 内でも WHERE 内でも行えます。
SELECT
event_name,
event_params,
(
SELECT
value.string_value
FROM
UNNEST(event_params)
WHERE
key = 'page_location') AS page_location,
FROM
`bigquery-public-data.ga4_obfuscated_sample_ecommerce.events_20210131`
LIMIT
1
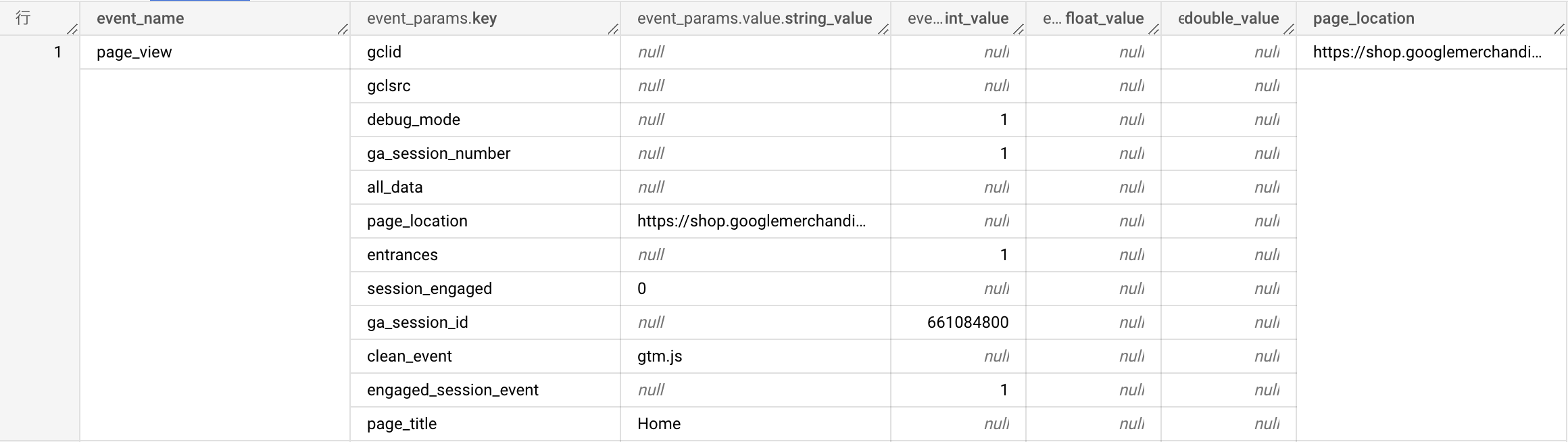
具体的な使用例はこんな感じでしょうか。
page_location ごとの PV、UU、PV/UUをPV降順で上位10件取得しています。
SELECT
(
SELECT
value.string_value
FROM
UNNEST(event_params)
WHERE
key = 'page_location') AS page_location,
COUNT(user_pseudo_id) AS pv,
COUNT(DISTINCT user_pseudo_id) AS uu,
COUNT(user_pseudo_id)/COUNT(DISTINCT user_pseudo_id) AS pv_per_uu
FROM
`bigquery-public-data.ga4_obfuscated_sample_ecommerce.events_20210131`
WHERE
event_name = 'page_view'
GROUP BY
page_location
ORDER BY
pv DESC
LIMIT 10
前述の通り、 SELECT 内で定義したエイリアスは GROUP BY や ORDER BY でも使えますので、そこまで複雑なクエリにならずにすみました。
ちなみに、UNNESTする際は
SELECT
(SELECT value.string_value FROM UNNEST(event_params) WHERE key = 'page_location') AS page_location,`
...
のように1行で書いた方がコード全体を俯瞰しやすい、というのが個人的な感覚としてあるのですが、コンソール標準搭載のフォーマッター(展開>クエリを書式設定)をかけると、上のコードのように細かく改行されて読みにくくなってしまうんですよね。1行にまとめてくれていいのに。フォーマッターに抗いたくもないので悩ましいところです。
CROSS JOIN 方式
ただし、 WHERE 内で page_location による絞り込みを行いたい場合は、エイリアスを使うことができません。
エイリアスを使わず前述のように UNNEST してもいいのですが、SELECT と WHERE で同じ変換を書くのは冗長に感じます。
こういった場合、おそらく以下のように書くのが最もシンプルになると思われます(ただしこれは event_params 内の1要素のみで絞り込めればいい場合のみ有効です)。
CROSS JOIN の説明は クエリ構文 | BigQuery | Google Cloud にゆずります。
SELECT
ep.value.string_value AS page_location,
COUNT(user_pseudo_id) AS pv,
COUNT(DISTINCT user_pseudo_id) AS uu,
COUNT(user_pseudo_id)/COUNT(DISTINCT user_pseudo_id) AS pv_per_uu
FROM
`bigquery-public-data.ga4_obfuscated_sample_ecommerce.events_20210131`
CROSS JOIN UNNEST(event_params) AS ep
-- `CROSS JOIN` は `,` に置き換え可能、テーブルに対する `AS` も省略可能なので
-- `, UNNEST(event_params) ep` とも書けます
WHERE
event_name = 'page_view'
AND ep.key = 'page_location' AND CONTAINS_SUBSTR(ep.value.string_value, 'Apparel') -- page_location に Apparel という文字列を含むものに絞る
GROUP BY
page_location
ORDER BY
pv DESC
LIMIT 10
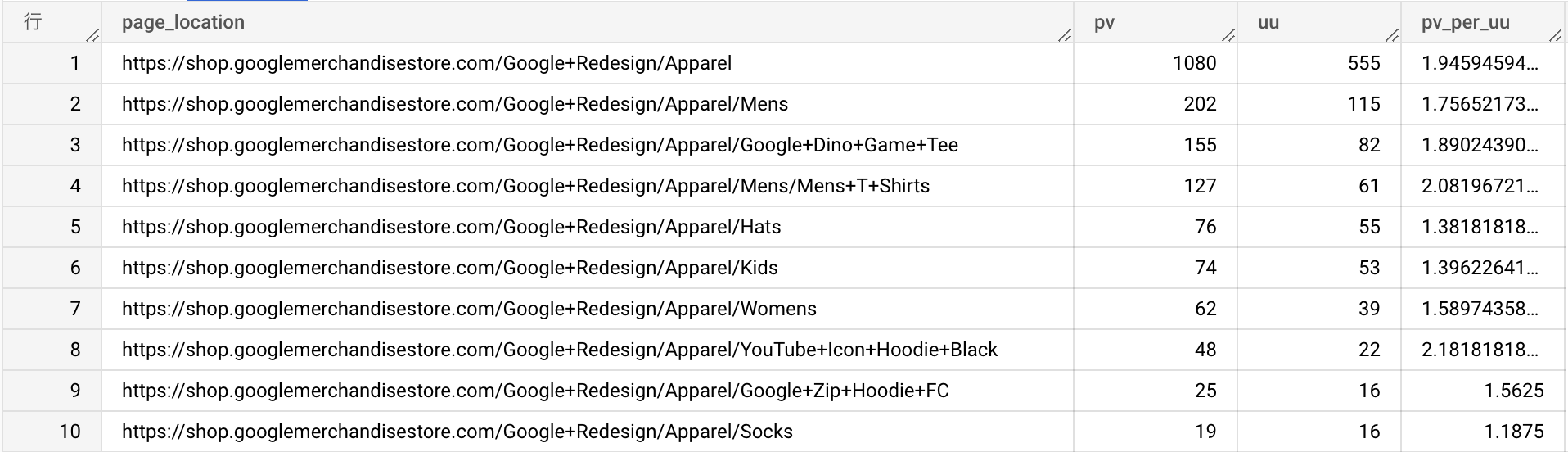
よく使う、クエリの可読性を上げる方法
一時テーブルを活用する
先ほど紹介した CROSS JOIN では一度に1つの条件で絞り込むことしかできませんので、多くの場合は UNNEST 方式を取ることになるでしょう。
ですが、実務の中で event_params を取り出して更に条件を入れて他のテーブルと結合して…といったことをやると、クエリがどんどん長く複雑になっていきます。
そんなときには WITH AS 句を使いましょう。
以下のクエリでは、
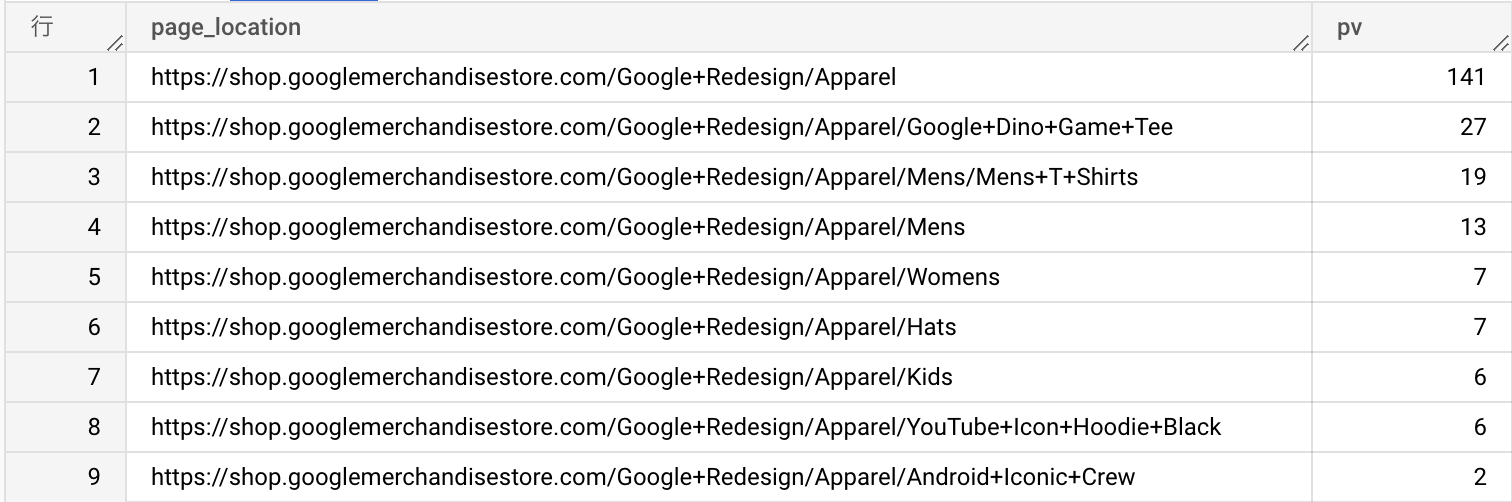
- まず
t1としてpage_viewイベントに絞り込んだあと、event_paramsのフィールドを取り出しています - 次に
t2としてt1テーブルからpage_locationがApparelの文字列を含みかつengagement_time_msec(ページ滞在時間)が10より大きいデータのみ残しています - 最後に
t2のデータをpage_locationでグルーピングしてpage_viewの総数を出しています
WITH
t1 AS(
SELECT
event_timestamp,
user_pseudo_id,
(
SELECT
value.string_value
FROM
UNNEST(event_params)
WHERE
key = 'page_location') AS page_location,
(
SELECT
value.int_value
FROM
UNNEST(event_params)
WHERE
key = 'engagement_time_msec') AS engagement_time_msec
FROM
`bigquery-public-data.ga4_obfuscated_sample_ecommerce.events_20210131`
WHERE
event_name = 'page_view' ),
t2 AS (
SELECT
*
FROM
t1
WHERE
CONTAINS_SUBSTR(page_location, 'Apparel')
AND engagement_time_msec > 10 )
SELECT
page_location,
COUNT(user_pseudo_id) AS pv
FROM
t2
GROUP BY
page_location
ORDER BY
pv DESC
正直、これくらいの変換であればこんなに何段階も一時テーブルを作る必要はないのですが、 WITH AS による定義は前に定義したテーブル( t2 にとっての t1 )も使っていけるということを説明するためこのようにしてみました。
ユーザー定義関数を使って可読性を高めミスを減らす
最後に、同じような処理を何度も書きたくないのでユーザー定義関数も使っていきます。
event_params を関数で展開してみる
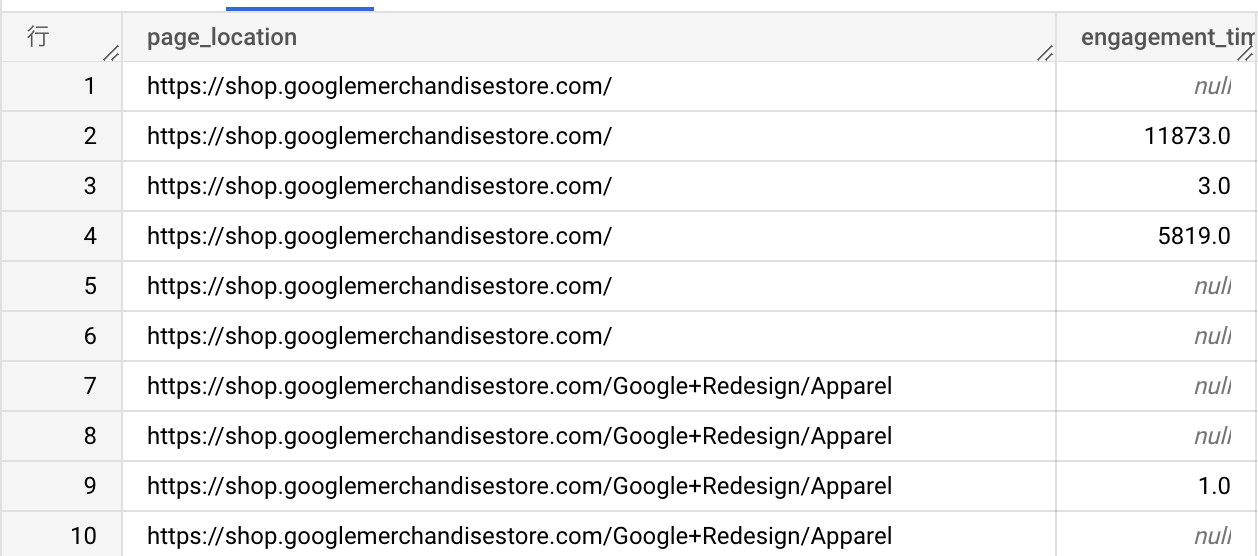
event_params の処理を関数にしてみました。コード全体の分量が増えていますし、数値系の型が失われているのでこれだけだと微妙かもしれませんが、メインのクエリ部分でやりたいことは読み取りやすくなったのではないでしょうか。
CREATE TEMP FUNCTION StringFromEventParams(event_params ANY TYPE, key_name STRING)
RETURNS STRING
AS
((
SELECT
value.string_value
FROM
UNNEST(event_params)
WHERE
key = key_name));
CREATE TEMP FUNCTION NumberFromEventParams(event_params ANY TYPE, key_name STRING)
-- RETURNS の型は省略できる
AS
((
SELECT
COALESCE(value.int_value, value.float_value, value.double_value) -- COALESCE は配列内の最初の非 null 値を取得するもの。int, float, doubleは共通のスーパータイプに変換可能なのでできる(stringは含められない)
FROM
UNNEST(event_params)
WHERE
key = key_name));
SELECT
StringFromEventParams(event_params, 'page_location') as page_location,
NumberFromEventParams(event_params, 'engagement_time_msec') as engagement_time_msec
FROM
`bigquery-public-data.ga4_obfuscated_sample_ecommerce.events_20210131`
LIMIT 10
URL を関数でカテゴリに分類してみる
page_location は様々なクエリがついていてそのままでは扱いにくいことがあります。
ページをカテゴリごとにまとめるのに関数を使うとクエリがスッキリします。
CREATE TEMP FUNCTION
StringFromEventParams(event_params ANY TYPE,
key_name STRING)
RETURNS STRING AS ((
SELECT
value.string_value
FROM
UNNEST(event_params)
WHERE
key = key_name));
CREATE TEMP FUNCTION
GetCategoryNameFromPath(path STRING)
RETURNS STRING AS (
CASE
WHEN REGEXP_CONTAINS(path, r'^https://www.googlemerchandisestore.com/$') THEN 'トップ'
WHEN REGEXP_CONTAINS(path, r'^https://shop.googlemerchandisestore.com/\?*$') THEN 'ショップトップ'
WHEN REGEXP_CONTAINS(path, r'^https://shop.googlemerchandisestore.com/myaccount.html\?*$') THEN 'マイアカウント'
WHEN REGEXP_CONTAINS(path, r'^https://shop.googlemerchandisestore.com/register.html\?*$') THEN '登録'
WHEN REGEXP_CONTAINS(path, r'^https://shop.googlemerchandisestore.com/registersuccess.html\?*$') THEN '登録成功'
WHEN REGEXP_CONTAINS(path, r'^https://shop.googlemerchandisestore.com/revieworder.html\?*$') THEN 'レビューオーダー'
WHEN REGEXP_CONTAINS(path, r'^https://shop.googlemerchandisestore.com/store.html\?*$') THEN 'ストア'
WHEN REGEXP_CONTAINS(path, r'^https://shop.googlemerchandisestore.com/basket.html\?*$') THEN 'バスケット'
WHEN REGEXP_CONTAINS(path, r'^https://shop.googlemerchandisestore.com/Google\+Redesign/') THEN 'Google Redesign' -- 以下略!
WHEN path = '' THEN 'なし'
WHEN path IS NULL THEN 'なし'
ELSE
'その他'
END
);
SELECT
GetCategoryNameFromPath(StringFromEventParams(event_params,
'page_location')) AS page_location_category,
GetCategoryNameFromPath(StringFromEventParams(event_params,
'page_referrer')) AS page_referrer_category,
COUNT(user_pseudo_id) AS pv
FROM
`bigquery-public-data.ga4_obfuscated_sample_ecommerce.events_20210131`
WHERE
event_name = 'page_view'
GROUP BY
page_location_category,
page_referrer_category
ORDER BY
pv DESC

ちなみに、関数内の ELSE path 部分を以下のように書き換えると、機能追加により新たな path が観測されたときなどに、以下のように実行時エラーになってくれますので、重要なページが「その他」として埋もれてしまうのを防ぐのに役立ちます。
ELSE ERROR(CONCAT('Found unexpected path: ', path))
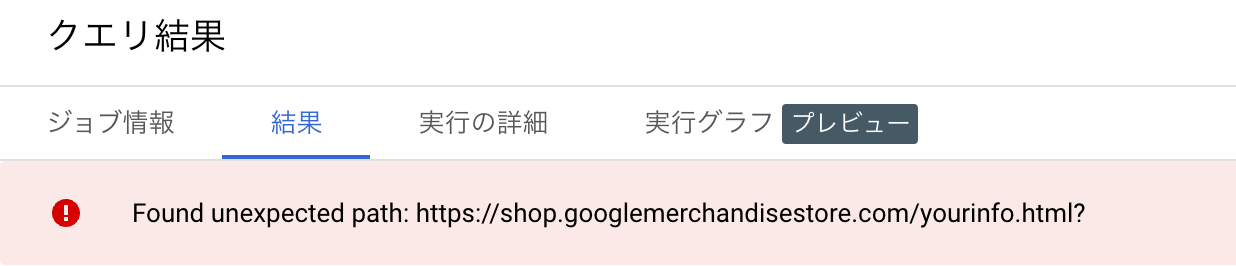
TEMP を省略することで一度定義したユーザー定義関数を永続的に使えるようプロジェクトに定義してしまうこともできます。
無闇に設定するのは危なそうですが、自分しか使わないプロジェクトなどでは有効活用できそうです。
記事の初めに書いた「ユーザーの閲覧環境をまとめる CASE 文」など、あまり頻繁に変更しないであろうセグメント分けなどは永続関数にしてしまってもいいかもしれませんね。
参考: ユーザー定義の関数 | BigQuery | Google Cloud
注意として、ユーザー定義関数は SELECT 句の中でしか使えないため、変数定義的に扱うのは( WHERE 句で使うシチュエーションの方が多そうなので)少し難しそうです。そういった縛りはありますが、うまく使えれば大きな武器になってくれるでしょう。
また、ユーザー定義関数は JavaScript でも書けるようですが、さすがにそこまで使う必要はないかな…と感じています。 JavaScript が得意な方は見てみるといいかもしれません。
まとめ
よく使う記法や覚えておきたい基本を雑多にまとめてみました。
特におすすめなのは最後のユーザー定義関数です。関数に切り出すことでクエリのネストを減らすことができ、コードの本筋を追いやすくなります。同じような変換を複数のフィールドに対して行う際にも、どれかひとつだけ間違った変換をかけてしまうような凡ミスを防げるでしょう。
あまり入り組んだことをやりすぎると一気に難読クエリになりそうなのでそこは要注意です。
他にも便利な記法があれば教えてください!