本稿では、Node.jsのWorker Threadsとその基本的な使い方について説明します。
本稿で知れること
- Worker Threadsの概要
- Worker Threadsとは何か?
- それが解決してくれる問題は何か?
- worker_threadsモジュールの基本的な使い方
- スレッド起動時にデータを渡すにはどうしたらいいか?
- 3秒かかる処理を、並列処理で1秒に短縮する方法。
Worker Threadsとは?
- CPUがボトルネックになる処理を、別スレッドに負荷分散し、効率的に処理する仕組み。
- マルチプロセスではなく、シングルプロセス+マルチスレッドのいわゆる「本物のスレッド」です。
Worker Threadsが解決する問題
- Node.jsはシングルプロセス、シングルスレッド。
- シングルプロセス、シングルスレッドは、シンプルさという利点がある。
- 一方で、CPUに高い負荷がかかる処理は、他の処理を止めてしまう欠点があった。
- Worker Threadsは、複数のスレッドを使えるようにすることで、この欠点を解決する。
Worker Threadsが解決しない問題
- I/Oがボトルネックになる処理。
- これは、Node.jsの非同期I/OのほうがWorkerより効率的に処理できる。
worker_threadsモジュールとは?
- JavaScriptを並列(parallel)で実行するスレッドが利用できるモジュール。
- libuvを用いた本物のスレッド(イベントループやマルチプロセスはない)。
- Web WorkerそっくりのAPI。つまりフロントエンドの知識が活きる。
- Node.js 10.5.0から使える。
- Node.js 11.7.0未満は、
--experimental-workerフラグをつけてNodeを起動する必要があった。
child_processモジュール、clusterモジュールとの違い
- worker_threadsはメモリを共有できる。
- child_processとclusterはメモリが共有できない。
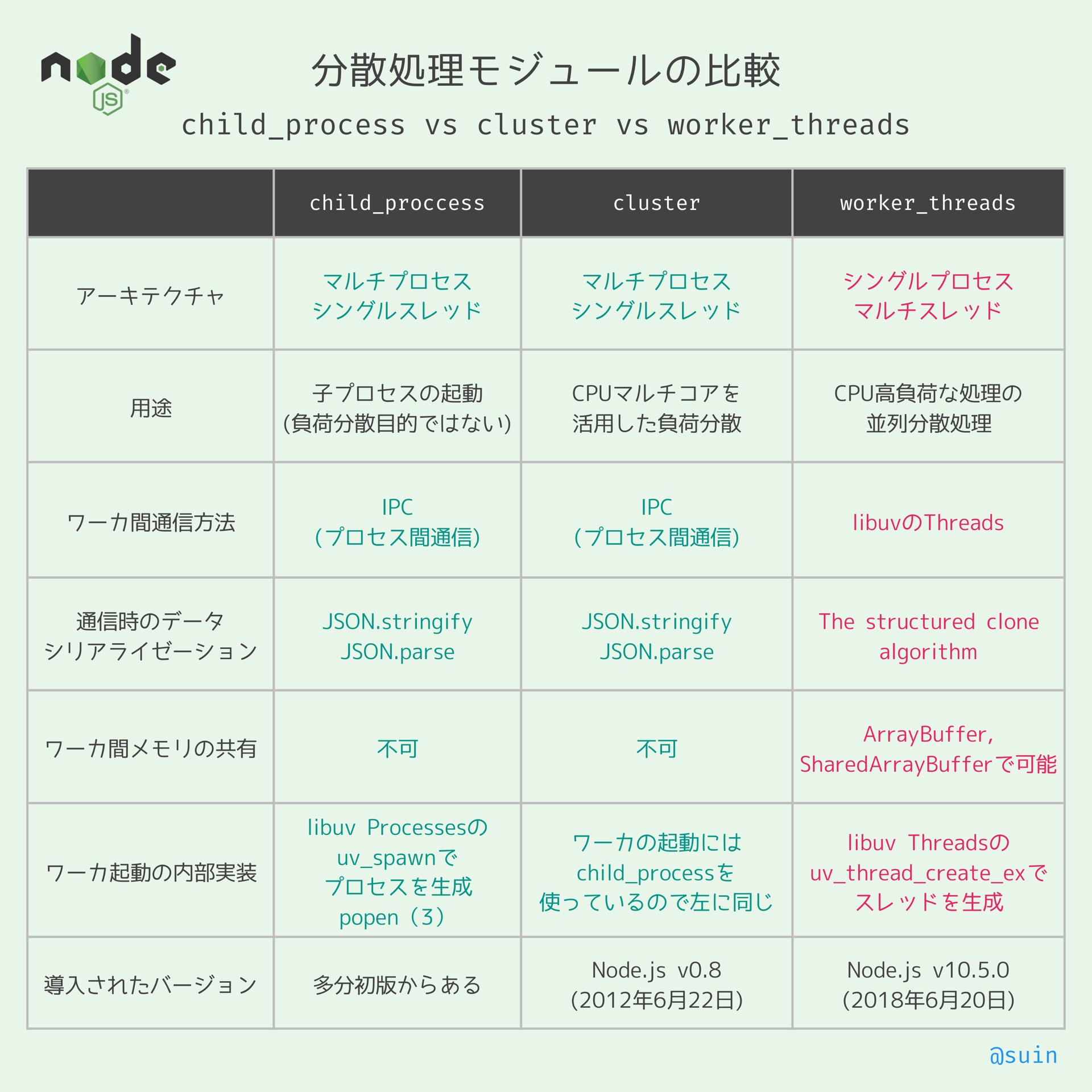
- child_process, clusterはワーカー間の通信時にデータを一旦JSONに変換するため、JSONライブラリの制約を受ける。
- 再帰的なオブジェクトを転送できない。
-
MapやSetはデータが消される。
- worker_threadsはThe structured clone algorithmでデータを複製するため、再帰的なオブジェクトや
MapやSetも送ることが可能。
worker_threadsモジュール入門
worker_threadsモジュールの基本的な使い方を見ていきましょう。
Workerを起動するには?
まず、Workerを起動する方法を見ておきましょう。Workerの起動はシンプルに言って、Workerクラスをnewするだけです。第一引数は、ワーカーの処理を書いたファイル名です。
const {Worker} = require('worker_threads')
const worker = new Worker('./worker.js')
console.log('Hello from worker')
このmain.jsをnodeで起動すれば、worke.jsがスレッドで実行されます。
$ node main.js
Hello from worker
Worker起動時にデータを渡すには?
次に、Worker起動時にmain.jsからデータを渡す方法を見てみましょう。データを渡すには、Workerクラスをnewするときに、第2引数にworkerDataに渡したいデータを入れます。
const {Worker} = require('worker_threads')
const worker = new Worker('./worker.js', {
workerData: 'message from main.js!',
})
ワーカー側のコードでは、workerDataをworker_threadsモジュールからインポートすることで、渡されたデータを参照できます。
const {workerData} = require('worker_threads')
console.log('Hello from worker')
console.log(workerData)
この例では、'message from main.js!'がワーカーに伝わっているのがわかります。
$ node main.js
Hello from worker
message from main.js!
workerDataは複製される
Workerにデータを渡せることは渡せるのですが、共有はされないので注意してください。次の例では、配列をワーカーに渡し、ワーカーがその配列を変更するコードですが、main.jsにはワーカーが加えた変更が伝わってきません。つまり、workerDataで渡されるデータは、複製されるのです。
const {Worker} = require('worker_threads')
const workerData = [1, 2, 3]
const worker = new Worker('./worker.js', { workerData }) // オブジェクトを渡す
setTimeout(() => console.log('main.js: %O', workerData), 1000) // どうなる?
const {workerData} = require('worker_threads')
console.log('worker.js %O', workerData)
workerData.push(4, 5, 6) // Worker側で変更を加える
console.log('worker.js %O', workerData)
worker.js [ 1, 2, 3 ]
worker.js [ 1, 2, 3, 4, 5, 6 ]
main.js: [ 1, 2, 3 ]
複数のWorkerを起動するには?
Workerにデータを渡す方法が分かったので、今度は複数のWorkerを起動してみましょう。
複数のWorkerを起動するには、単純にWorkerインスタンスを複数作るだけです:
const {Worker} = require('worker_threads')
const worker1 = new Worker('./worker.js', {
workerData: 'worker1',
})
const worker2 = new Worker('./worker.js', {
workerData: 'worker2',
})
const {workerData} = require('worker_threads')
console.log(`I'm a ${workerData}`)
$ node main.js
I'm a worker1
I'm a worker2
CPU高負荷な処理を分散してみよう
worker_threadsモジュールの基本的な使い方が分かったと思うので、CPU高負荷な処理をマルチスレッドで分散することを試してみましょう。
高負荷な関数を準備する
処理分散を試すために、CPUに高負荷がかかり、処理に時間がかかる関数を用意します。
このhighLoadTask関数は、単純に20億回ループするだけですが、実行するとCPU使用率が100%になるくらいの負荷が発生します。(CPUの性能によって実行時間が左右されるので、手元の環境で実行してみる際は、20億回の部分を調整して数秒で終わる程度の回数に直してください)
function highLoadTask() {
for (let i = 0; i < 2_000_000_000; i++) {
}
}
module.exports = {highLoadTask}
どのくらい負荷と時間がかかるか確認してみよう
highLoadTask関数をシングルスレッドで3回実行するようにしたコードが次です:
const {highLoadTask} = require('./highLoadTask')
console.time('total')
console.time('task#1')
highLoadTask()
console.timeEnd('task#1')
console.time('task#2')
highLoadTask()
console.timeEnd('task#2')
console.time('task#3')
highLoadTask()
console.timeEnd('task#3')
console.timeEnd('total')
このスクリプトを実行すると、(僕のPCでは)合計で約3秒かかります:
node main.js
task#1: 1.455s
task#2: 1.460s
task#3: 478.089ms
total: 3.399s
CPU負荷のほうは、Activity Monitorで「node」に検索を絞って、モニタリングすると、99%が使われていることがわかります。使用率が100%を超えていないので、当てられているCPUコア数は1個ということもわかります。(CPU使用率が上がりきらない場合は、highLoadTask関数のループ数を増やしてください)

CPU高負荷処理は非同期処理でも解決しない
ちなみに、次のようにPromiseを使って各タスクを非同期処理にしても、かかる時間は変わりませんので、この関数はシングルスレッドでは限界があるということが確認できます:
const {highLoadTask} = require('./highLoadTask')
function asyncHighLoadTask(taskName) {
return new Promise(resolve => {
console.time(taskName)
highLoadTask()
console.timeEnd(taskName)
resolve()
})
}
(async function () {
console.time('total')
await Promise.all([
asyncHighLoadTask('task#1'),
asyncHighLoadTask('task#2'),
asyncHighLoadTask('task#3'),
])
console.timeEnd('total')
})()
Workerを使って3秒かかる処理を1秒にする
では実際にWorkerを使って、処理を分散するコードを書いてみます。
まず、Worker側の実装です:
const {workerData} = require('worker_threads')
const {highLoadTask} = require('./highLoadTask')
console.time(workerData)
highLoadTask()
console.timeEnd(workerData)
次に、メイン側の実装です。
const {Worker} = require('worker_threads')
console.time('total')
const worker1 = new Worker('./worker.js', {
workerData: 'worker1',
})
const worker2 = new Worker('./worker.js', {
workerData: 'worker2',
})
const worker3 = new Worker('./worker.js', {
workerData: 'worker3',
})
Promise.all([
new Promise(r => worker1.on('exit', r)),
new Promise(r => worker2.on('exit', r)),
new Promise(r => worker3.on('exit', r)),
]).then(() => console.timeEnd('total'))
main.jsでは、ワーカーを3つ起動して、3並列で処理させるようにしました。
最後のPromise.allの部分は、ワーカーの終了を待って合計所要時間を計測するためのコードですので、ここでは気にしないでください。
実行してみましょう:
$ node main.js
worker1: 1.526s
worker3: 1.529s
worker2: 1.529s
total: 1.579s
実行結果を見てのとおり、各タスクの処理は1.5秒程度で変化はありませんが、並列実行したため3秒かかっていた合計所要時間が1.5秒に短縮されました。
気になるCPU使用率は、298%になっているので、コアが3つがきびきび働いているのがわかります。

おわり
本稿では、Node.jsのWorker Threadsの概要と、worker_threadsモジュールの基本的な使い方を解説しました。
CPUがボトルネックとなる処理をマルチスレッドで分散すると、マルチコア環境で眠っているCPUを効率的に働かせられたり、その結果処理時間を短縮できることが分かったかと思います。
今後投稿するかもしれないこと
本稿では基本的なことがらにしか触れませんでしたが、下記のような疑問も気になるところなので、追って投稿できたらと思います。
- スレッドで例外が発生したらどうなる?
- メインスレッドとの通信方法は?
- 素のNode, child_process, worker_threadsのアーキテクチャ上どういう違いが出てくるか?
- メモリ共有は具体的にどうやるのか?
- Workerを扱いやすくするライブラリはある?
- Workerを停止するには?
- 通信のオーバーヘッドは?
- Worker生成のオーバヘッドはどのくらい?
最後までお読みくださりありがとうございました。Twitterでは、Qiitaに書かない技術ネタなどもツイートしているので、よかったらフォローお願いします![]() →Twitter@suin
→Twitter@suin