この投稿では、PostgreSQLで相互排他的な一対一関連を実現する方法を説明します。
相互排他的な関連とは何でしょうか? あるテーブルがあるとします。このテーブルをAテーブルとします。Aテーブルは、Bテーブルとのone-to-one関連があります。さらに、AテーブルはCテーブルともone-to-one関連があります。ここまでは、普通の関連です。ここに特別ルールを加えます。Aテーブルの行が持っていい関連は、BテーブルかCテーブルどちらか一方のみとすること。これが相互排他的な関連になります。
例えば、イベント(催し物)のエンティティを考えてみます。イベントは2種類の形式があり、ひとつは単発イベント。もうひとつは繰り返しイベントです。単発イベントは、イベントがいつ執り行われるか日付が明確で一回きりのイベントです。一方、繰り返しイベントは、「いつから」「いつまでに」「どういった頻度で」開催されるかといった複合的な情報を持ち、何度か執り行われるイベントを言います。ER図で示すと次のようになります:
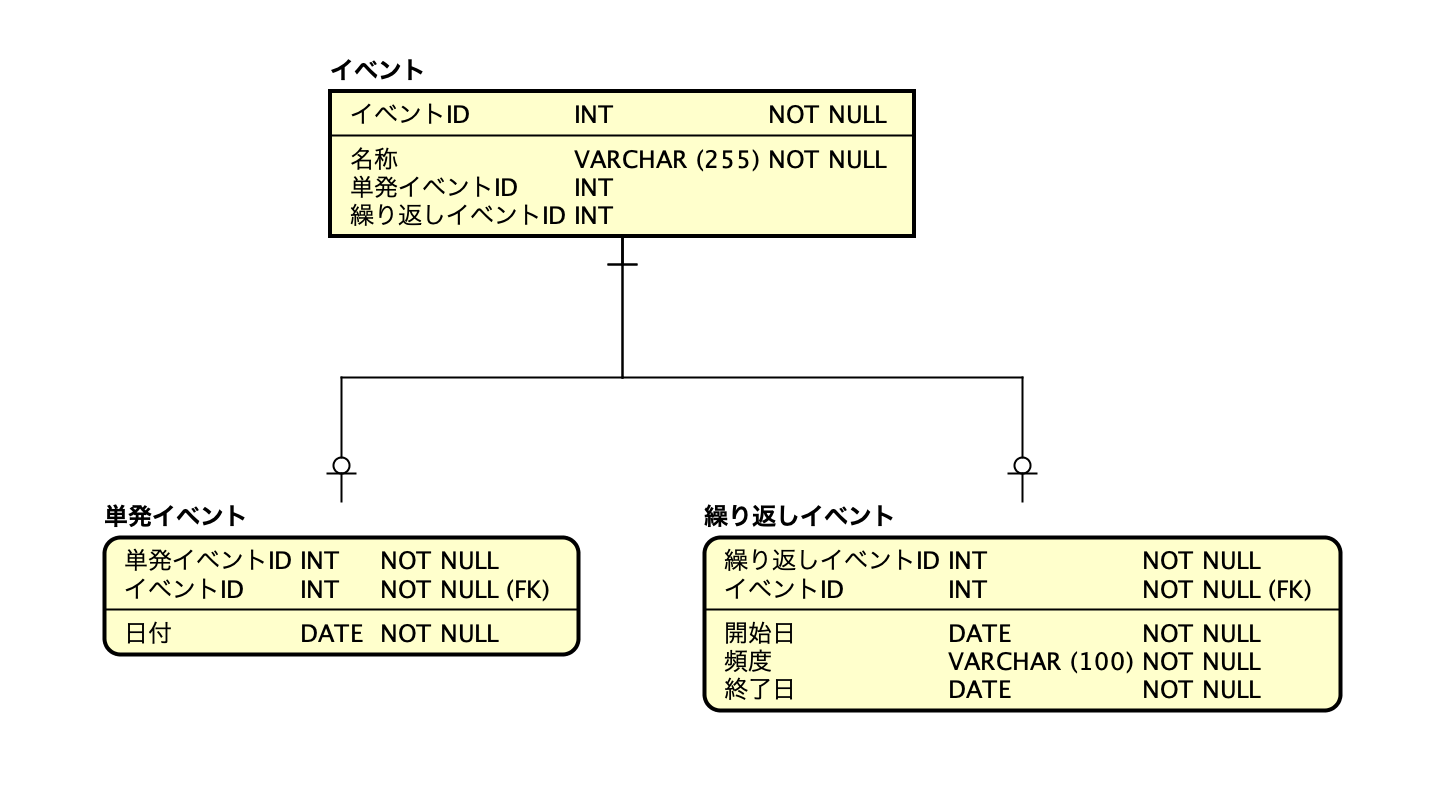
単発イベントであると同時に繰り返しイベントであるイベントというのは存在しえないので、イベントにとって単発イベントと繰り返しイベントは「相互排他的」になるわけです。
この投稿では、このイベントテーブルを具体例に、PostgreSQLでどうやって実装するのか見てきます。
相互排他的なone-to-one関連の作り方
上で示したER図は我々日本語話者にわかりやすいように論理名で示しましたが、実装は物理名(英語)を使うので、上のER図を物理名に翻訳します。翻訳した図が次です。
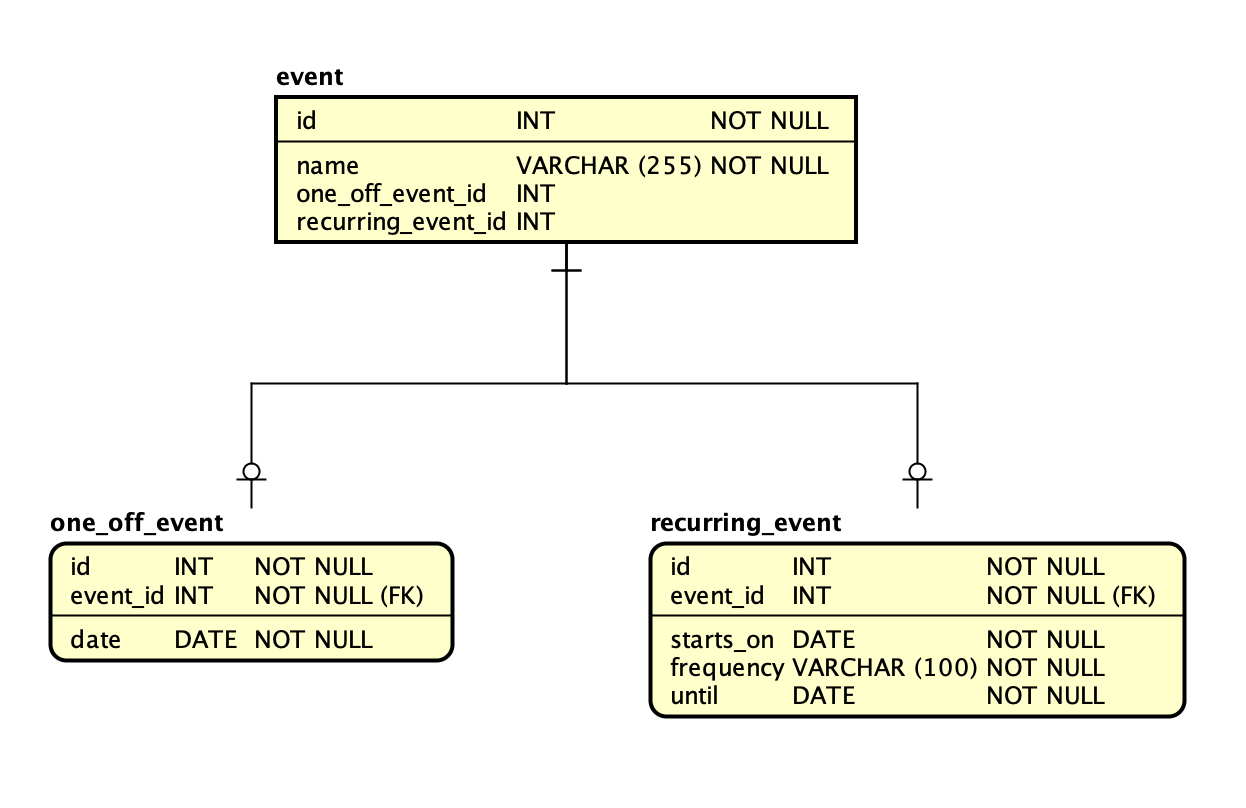
(※作図ツールの制約で、関連線がexactly one-to-oneが表現できず、one-to-zero-or-oneになっていますが本筋とは関係ないので無視してください。)
それでは、相互排他的なone-to-one関連の作り方を順を追って見ていきましょう。
ステップ1: 軸となるテーブルを作る
まず、軸となるテーブルeventを作ります。そのためのSQLが次です。
create table event
(
id serial not null primary key,
name varchar not null,
one_off_event_id int,
recurring_event_id int,
/* 関連の相互排他性を制約で縛る↓ */
constraint either_one_off_event_id_or_recurring_event_id_is_required check (
(one_off_event_id is not null and recurring_event_id is null)
or
(one_off_event_id is null and recurring_event_id is not null)
)
);
基本的な構造は普通のテーブルを作るのと同じですが、ポイントとしては
- one_off_event_idやrecurring_event_idの外部キー制約はまだつけない
- 相互排他性はPostgreSQLの制約(constrait)機能でがんばる
ことです。
ステップ2: 関連テーブルを作る
eventテーブルを作ったら、関連テーブルであるone_off_eventとrecurring_eventを作ります。
まず、one_off_eventテーブル作成のSQLです:
create table one_off_event
(
id serial not null primary key,
event_id int not null
references event (id)
on update cascade
on delete cascade,
date date not null
);
ここは特段、特別なことはしなくて良いです。event_idカラムにはeventテーブルのidの外部キー制約をつけておきます。
次に、recurring_eventテーブルのSQLです:
create table recurring_event
(
id serial not null primary key,
event_id int not null
references event (id)
on update cascade
on delete cascade,
starts_on date not null,
frequency varchar not null,
until date not null
);
これも特別なことはありません。
ステップ3: 軸となるテーブルにあとづけて外部キー制約を加える
軸となるテーブルeventのone_off_event_id、recurring_event_idに外部キー制約がついていなかったので、ここではeventテーブルを修正して2つの外部キー制約を加えます。
alter table event
add constraint one_off_event_id_fkey
foreign key (one_off_event_id)
references one_off_event (id)
on update cascade
on delete cascade,
add constraint recurring_event_id_fkey
foreign key (recurring_event_id)
references recurring_event (id)
on update cascade
on delete cascade;
これで、eventテーブルとone_off_event/recurring_eventとの整合性はかなり強いものになります。
この整合性のいいところは、eventからレコードをdeleteしたとき、それに関連するone_off_eventもしくはrecurring_eventも同時に消えるだけでなく、one_off_eventのレコードを消したら、それに関連するeventレコードも消えるという点です。うっかりどちらかが残ってしまうという不整合がありません。
相互排他的な関連の作り方は以上です。
相互排他的な関連に行を作る方法
上で作った相互排他的な関連では、相互に外部キー制約を持っているので、通常のINSERTでは行を作ることができません。例えば、eventテーブルに行を作るには、one_off_eventのIDを知っておく必要がありますが、しかし、one_off_eventを作るにはeventのIDを知っておく必要があります。堂々巡りです。
-- eventに行を作るには、one_off_event_idが必要です
insert into event (id, name, one_off_event_id, recurring_event_id)
values (default, 'test1', null, null);
--=> ERROR: new row for relation "event" violates check constraint "either_one_off_event_id_or_recurring_event_id_is_required"
-- one_off_eventに行を作るには、event_idが必要です
insert into one_off_event(id, event_id, date)
values (default, null, '2020-01-01');
--=> ERROR: null value in column "event_id" violates not-null constraint
これを解決するには、eventテーブルへの書き込みと、one_off_eventテーブルへの書き込みを同時に行う必要があります。この考え方で作ったSQLが次です。
with evt(id, one_off_event_id) as (
insert into event (name, one_off_event_id)
values ('test 1', nextval('one_off_event_id_seq'))
returning id, one_off_event_id
)
insert
into one_off_event(id, event_id, date)
select evt.one_off_event_id, evt.id, '2020-01-01'
from evt;
結構複雑ですが、これは2つの部分に分けて考えます。
-- 1
with evt(id, one_off_event_id) as (
insert into event (name, one_off_event_id)
values ('test 1', nextval('one_off_event_id_seq'))
returning id, one_off_event_id
)
-- 2
insert
into one_off_event(id, event_id, date)
select evt.one_off_event_id, evt.id, '2020-01-01'
from evt;
1つ目のクエリは、eventテーブルにinsertするものです。特別なところはone_off_event_idの値をシーケンスから直接発番しているところです。このクエリが成功すると、eventのidが発番され、returningによってevt仮テーブルに入ります。
2つ目のクエリは、one_off_eventテーブルにinsertするものです。event_idとone_off_eventのidは、1つ目のクエリで発番されているので、それが入っているevt仮テーブルから値を持ってくるようにしています。
そして、最初のwith句はこれら2つのクエリを一個のクエリとして行うためのものです。
この一連のクエリを実行すると、eventテーブルとone_off_eventテーブルにそれぞれ1行ずつレコードが追加されます。
-- レコードが追加されたか確認するクエリ
select e.*, ooe.date
from event e
join one_off_event ooe on ooe.id = e.one_off_event_id;
上のクエリの結果:

ここまではone_off_eventテーブルにレコードを登録する例を見てきましたが、recurring_eventテーブルに追加するクエリもほぼ同じです。異なるのはrecurring_event_idのシーケンス名と、2つ目のクエリのカラム数です:
with evt(id, recurring_event_id) as (
insert into event (name, recurring_event_id)
values ('test 2', nextval('recurring_event_id_seq'))
returning id, recurring_event_id
)
insert
into recurring_event(id, event_id, starts_on, frequency, until)
select evt.recurring_event_id, evt.id, '2021-01-01', 'monthly', '2021-12-31'
from evt;
ちなみに繰り返しイベントを取得するクエリは次のようになります:
-- 繰り返しイベントを取得するクエリ
select e.*, re.starts_on, re.frequency, re.until
from event e
join recurring_event re on e.id = re.event_id;
以上のようにinsertは複雑ですが、updateやdeleteは通常のクエリで行えます。
テーブルを分けなければいいのでは?
相互排他的な関連。ここまで複雑なことをするなら、素直にテーブルを一つにしてしまえばいいのではとも考えられます。それも設計のひとつとして、ありだと思います。その場合は、次のクエリのように、各カラムがnullableになることは許容することになります。
create type event_type as enum ('one-off', 'recurring');
create table event
(
id serial not null primary key,
name varchar not null,
type event_type not null,
/* one-off event columns */
date date,
/* recurring event columns */
starts_on date,
frequency varchar,
until date
);
「nullableは不整合の元だから絶対にイヤ!」という場合は、constraintで縛ることもできます:
create type event_type as enum ('one-off', 'recurring');
create table event
(
id serial not null primary key,
name varchar not null,
type event_type not null,
/* one-off event columns */
date date,
/* recurring event columns */
starts_on date,
frequency varchar,
until date,
/* 単発と繰り返しのnull可能性は相互排他的であること */
constraint nullability_of_one_off_and_recurring_must_be_mutually_exclusive
check (
(type = 'one-off' and
date is not null and
starts_on is null and
frequency is null and
until is null)
or (type = 'recurring' and
date is null and
starts_on is not null and
frequency is not null and
until is not null)
)
);
このテーブル設計なら整合性がかなり良くなります。しかし、テーブル単体でも見たときの複雑性は低くなく、特にconstraintの条件部分はしっかりテストしておいたほうが良さそうです。また、単発イベント部分や繰り返しイベント部分にカラムが増えたとき、constraintの部分も修正が必要になり、ここは見落としやすかったり、ちゃんとした条件式を書けないとバグになりやすい部分だと思うので、変更のしやすさの観点からすると、ちょっと微妙かなと思います。
その点、相互排他的な関連テーブルは、テーブル個別に見たときはシンプルですし、カラム追加などの変更はしやすいかと思います。