※学習中のため間違っている箇所があるかもしれません。
はじめに
前回はSQLの基本構文であるSELECT/INSERT/UPDATE/DELETEを学習しました。
今回は上記基本構文に追加して、集約、整形するためのクエリWHERE/ORDER BY/GROUP BY/HAVINGを学習していきます。
ダミーデータの作成
まず、上記SQL文を使用するためにダミーデータを作成していきましょう。
ダミーデータとは、テストやデモ用の開発環境で使用される架空のデータです。
A5M2の機能で簡単に作成できるので、クエリ練習前にダミーデータを作成していきましょう。
対象のテーブルをダブルクリック
今回は以前作成したusersテーブルにデータを挿入していきます。
そのため「mysqlstudy」→「テーブル」→「users」の順で選択していきましょう。
ダミーデータ作成画面
まず、上部にある丸いボタンをクリックしましょう。
※画像の赤枠内
そうすると、テスト用ダミーデータ作成画面が表示されます。
※既存データをすべて削除する警告が出ますが、今回は気にせず削除しましょう。
実際の現場で使用する場合は、ほかへの影響がないかどうかを確認してください。
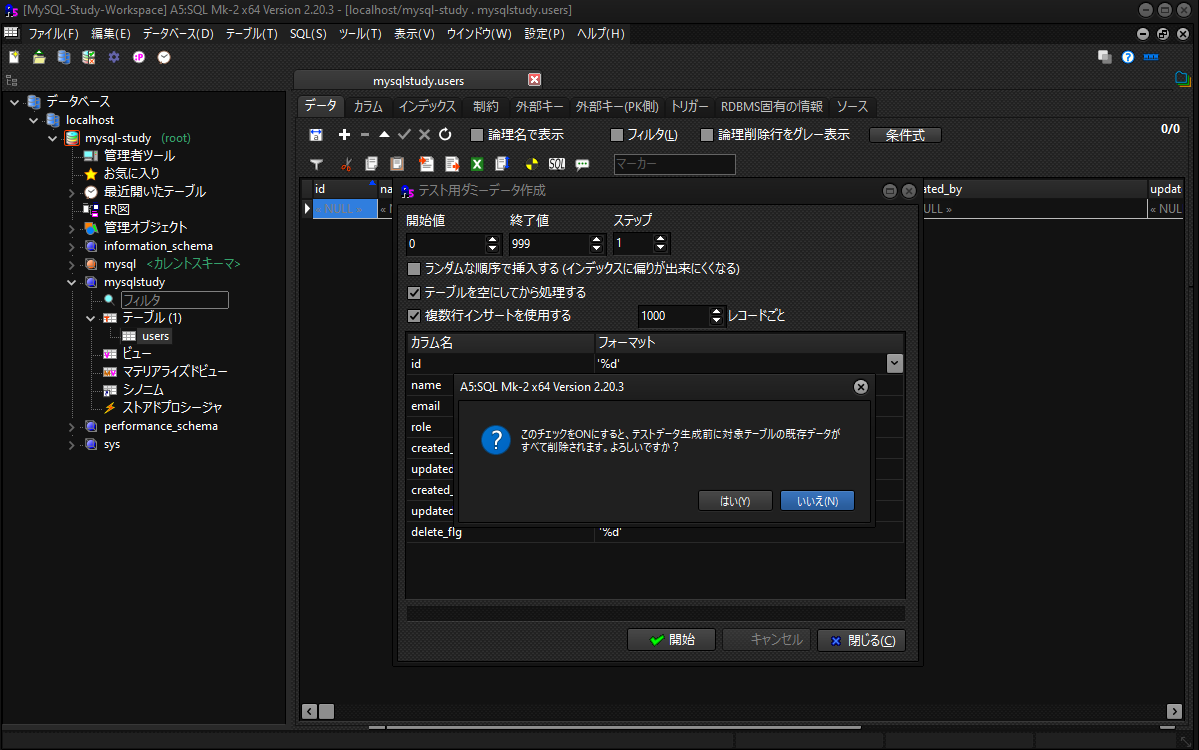
値の設定
テスト用ダミーデータ生成画面では、カラムとフォーマットが表示されています。
これはカラムに対して、どのような値を生成するかを設定する項目です。
開始ボタンを押してデータを作成しましょう。
※以下の値に関してフォーマットを変更しています。
皆さんは作成しているテーブルに合わせて変更しましょう。
name:FULLNAME_jp
email:EMAIL
role:'USER'
delete_flg:'0'
created_at:DATE
updated_at:DATE
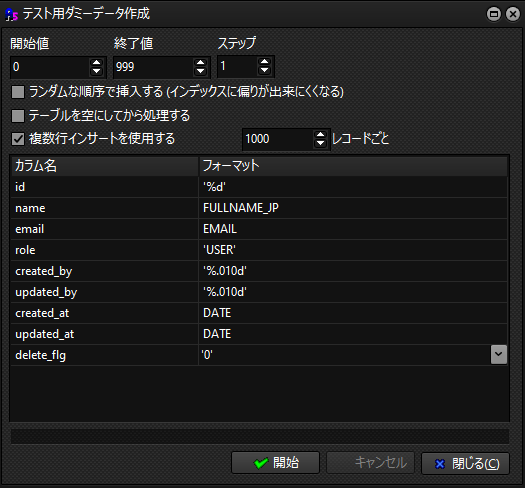
※補足:A5M2以外で使用することはないですが、以下にフォーマットを簡単にまとめます。
%d:1,2,3...といった連番を付与します。
%.010d:0000000001,000000002...といった先頭10文字を0埋めした連番を付与します。
NOW:これは現在時刻を挿入します。
※「ステップ」に関して
ステップは数値を一回にどれだけ増やすかを表しています。
1に設定した場合は、0,1,2,3~999となり、2に設定すると0,2,4~となります。
以下のエラーが出る場合
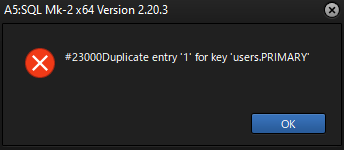
このエラーはテーブルのAUTO_INCREMENTが影響している可能性があります。
AUTO_INCREMENTはテーブル作成時にオプションで指定し、特定のカラムを自動連番で挿入する機能ですが、
前のデータを削除する際にAUTO_INCREMENTがリセットされていない可能性があります。
その際は以下の構文を使用しましょう。
TRUNCATE TABLE users;
これはテーブルの中身をすべて削除し、リセットする構文です。
データがすべて消えてしまうので業務で使用する際は注意して使用しましょう。
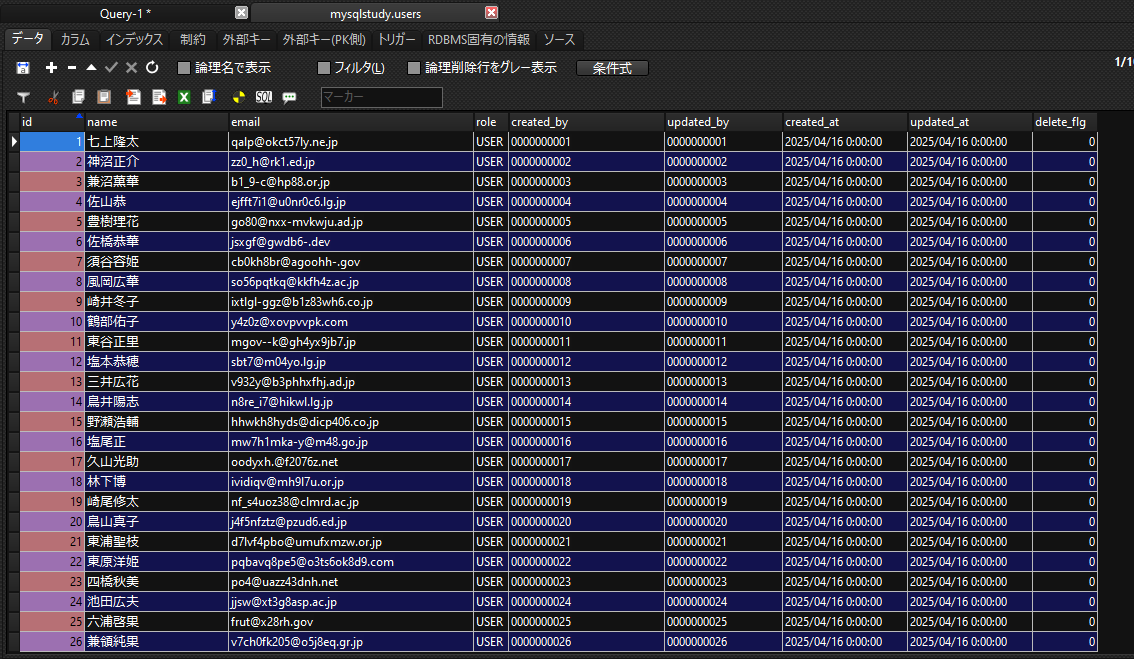
データの作成
期待通り、ダミーデータが作成されていれば完成です。
WHERE
WHERE句はSELECT、DELETE、UPDATEの基本構文を使用する際に、検索結果や更新対象に条件を指定するための句です。
※INSERTに関しては、レコードを挿入するだけなのでWHERE区を使用することはありません。
構文
SELECT
SELECT * FROM テーブル名 WHERE カラム名=条件
UPDATE
UPDATE テーブル名 SET カラム名=値 WHERE カラム名=条件
DELETE
DELETE FROM テーブル名 WHERE カラム名=条件
それぞれ「カラム=条件」で指定した値に合致しているものを対象とします。
先ほど作成したダミーデータで確認していきましょう。
WHERE区確認
それでは一つずつ結果を確認していきましょう。
SELECT
以下で名前が'七上隆太'のレコードのみに絞って検索することができます。
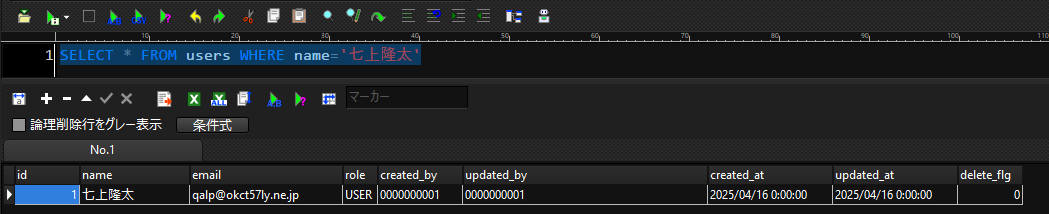
SELECT * FROM users WHERE name='七上隆太'
結果
nameカラムが七上隆太のレコードだけ取得できているのがわかります。
UPDATE
UPDATEでは検索条件を名前が七上隆太のカラムに絞って、そのカラムの名前を七上テストに変更します。
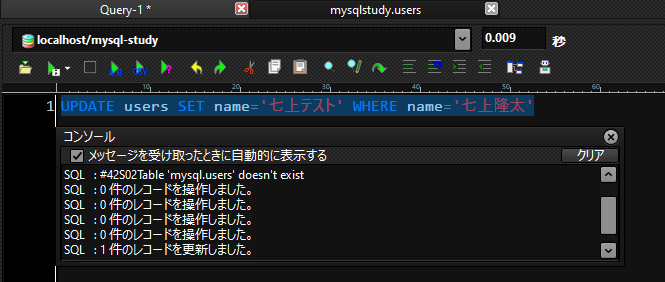
UPDATE users SET name='七上テスト' WHERE name='七上隆太'
結果
1件のレコードが正常に更新されているのがわかります。
検索してみると、id=1の名前が七上テストに変更されているのがわかります。
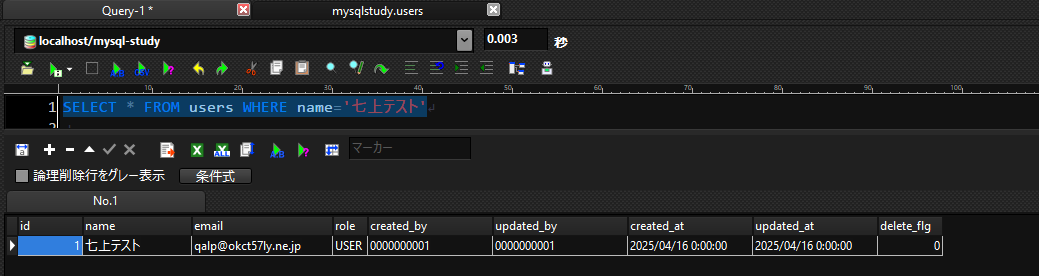
DELETE
DELETEでは検索条件を名前が七上テストのカラムに絞って、そのカラム1件を削除します。
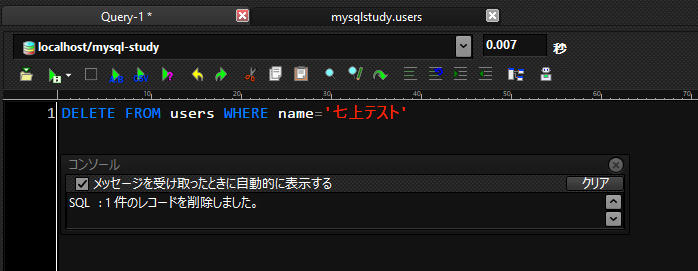
DELETE FROM users WHERE name='七上テスト'
結果
1件のレコードが正常に削除されているのがわかります。
検索してみると、データが出力されません。
正常に削除されているようです。
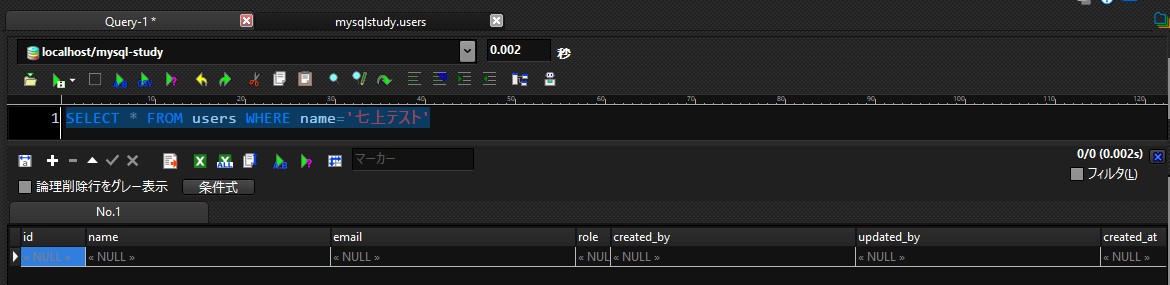
このようにWHERE区では条件を決めて、検索、更新、削除を行うことができます。
実務でも使用することが多いのでしっかりと学んでいきましょう。
複数WHERE区を使用する
WHERE区を使用する場合、カラムを複数条件として指定することができます。
今回はSELECTで動作を確認していきましょう。
構文
構文1
SELECT * FROM users WHERE カラム=条件 AND カラム < 条件
構文2
SELECT * FROM users WHERE カラム=条件 OR カラム < 条件
AND
ANDを使用することで
A AND BのAとBの両方に合致する値を取得することができます。
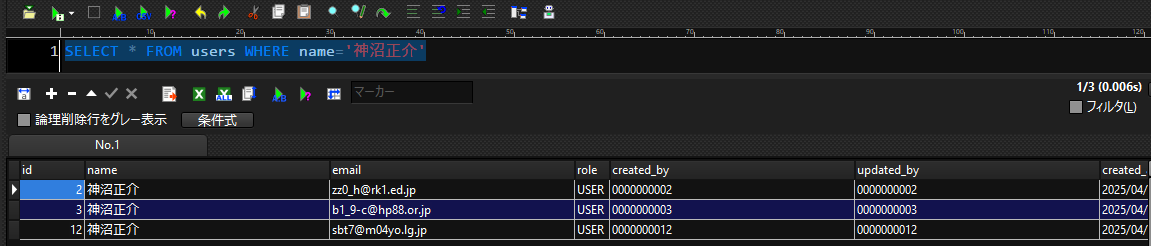
以下のようなデータがあったとします。
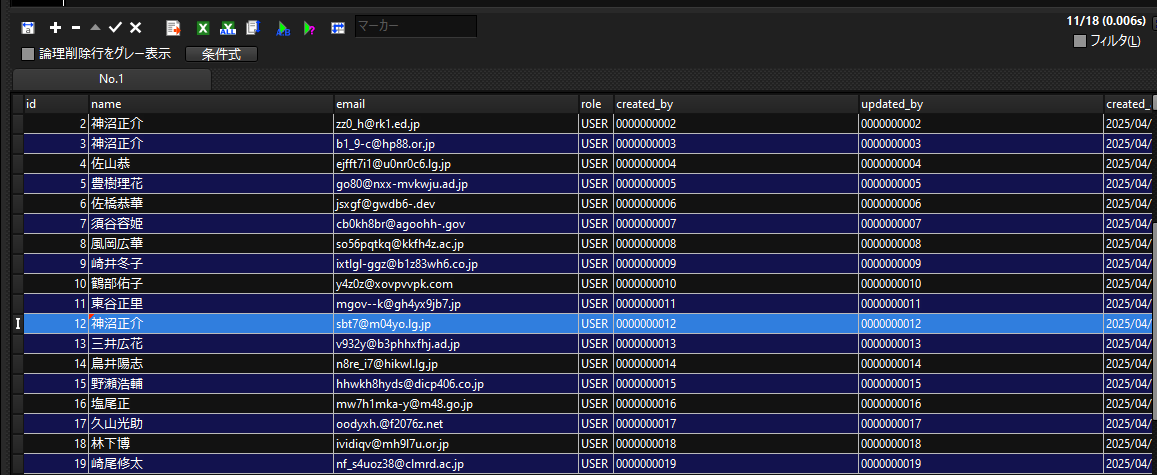
name='神沼正介'が複数存在していて、名前だけでは特定のレコードを取得できません。
試しに名前だけを条件として取得してみましょう。
このようにデータが3件取得できます。
これでは特定のレコードを一件取得したい場合に、不要なカラムまで取得してしまいます。
そこで検索条件を追加し、さらに絞っていきましょう。
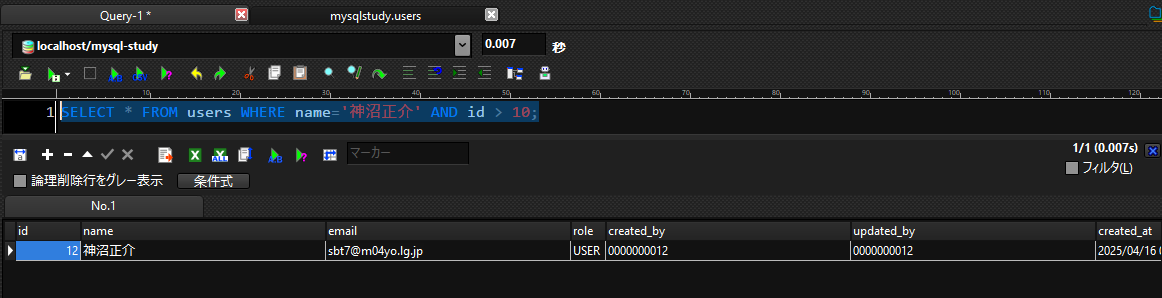
以下の構文を使用することで
name='神沼正介' と id > 10の両方に合致する値を取得できます。
SELECT * FROM users WHERE name='神沼正介' AND id > 10;
実行結果
複数の条件を設定することで、特定の一件を取得することに成功しました。
このように複数条件を指定するのは業務上でも特に使用するので覚えておきましょう。
OR
ORを使用することで
A OR BのA または Bに合致する値を取得することができます。
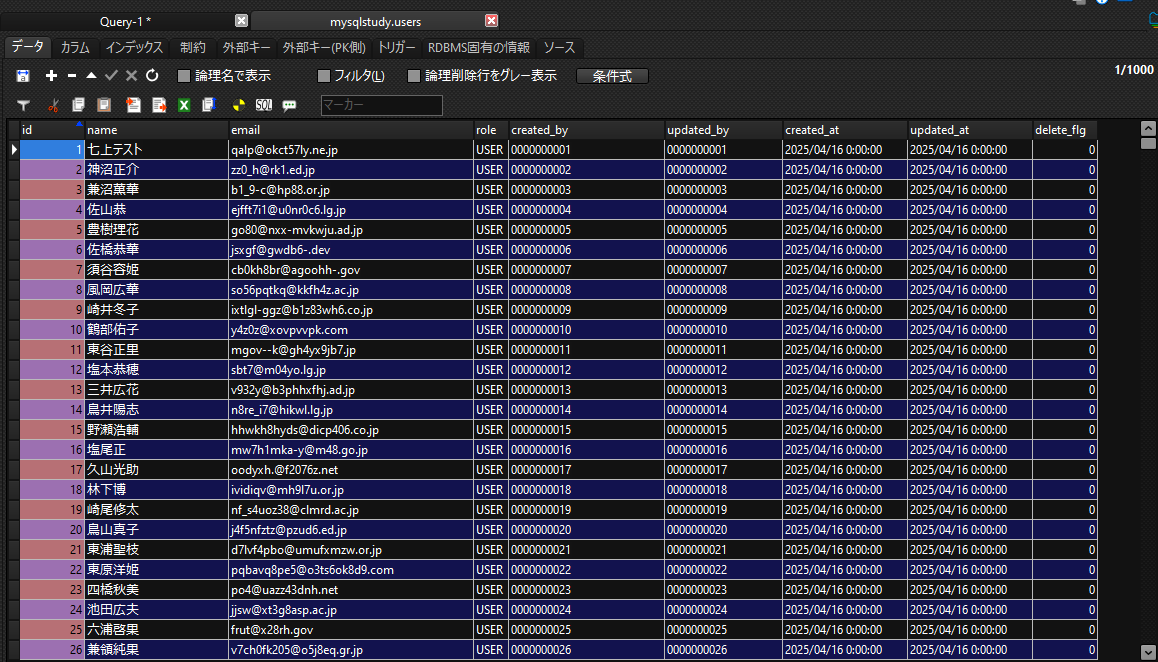
以下のデータで名前が久山光助とidが5以下の値両方の値を取得したい状況があったとします。
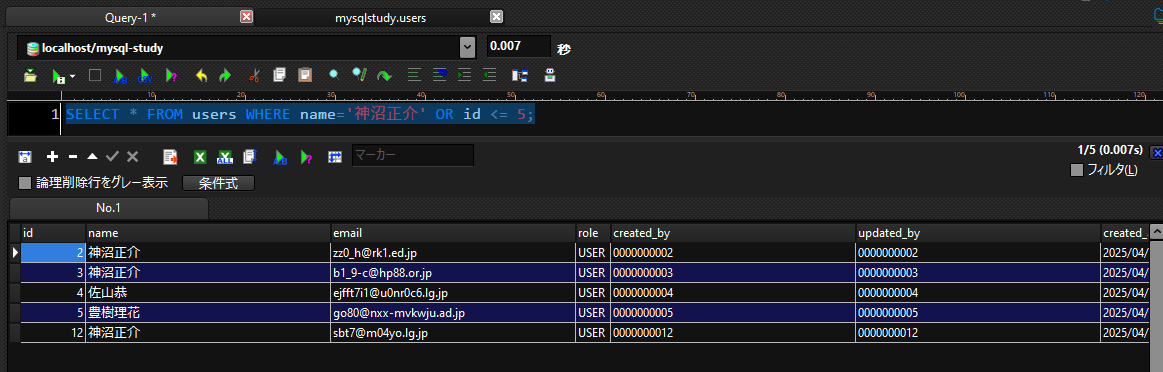
以下の構文を使用することで
name='神沼正介' と id <= 5に合致する値をそれぞれ取得することができます。
SELECT * FROM users WHERE name='神沼正介' OR id <= 5;
実行結果
このようにidが5以下のレコードと名前が神沼正介のレコード両方を取得することができます。
ANDやORは業務でもよく使用するためしっかり確認しておきましょう。
ORDER BY
次はORDER BYに関して学習していきます。
ORDER BYは検索結果の並び替えに使用します。
何を基準に並び替えるのか、降順、昇順を指定することで、結果を好きな順番に並び替えることができます。
構文
SELECT * FROM テーブル名 ORDER BY カラム名 DESC(またはASC)
DESC:降順(最大値が先頭)
ASC:昇順(最小値が先頭)
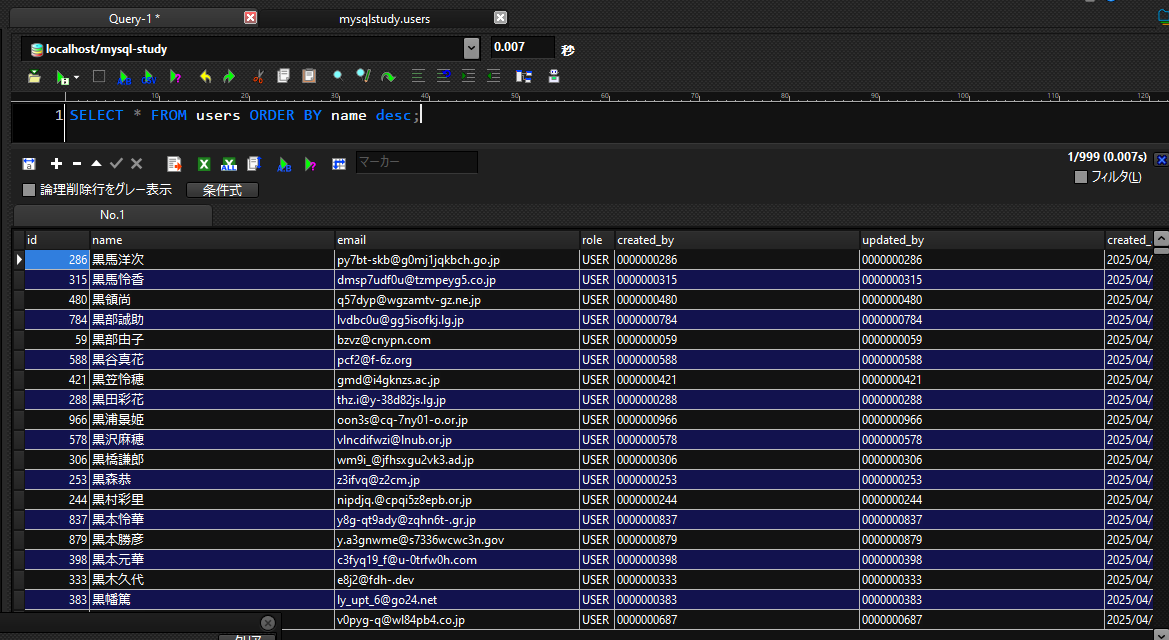
実際にダミーデータで試してみましょう。
SELECT * FROM users ORDER BY name desc;
実行結果
このようにname descと指定することで、通常はid順で表示されますが、
名前を基準とし、降順に並び替えることができます。
これも業務ではよく使用されるものです。
身近なシステムでいえば、ECサイトなどで使用する商品の並び替えでもこのORDER BYを使用しています。
GROUP BY
GROUP BYは指定した値をグループ化し、集約関数を使用し、平均値、件数、最大値、最小値を出力することができます。
グループ化とは、例えばusersテーブルの場合nameを指定することで複数同じ名前がnameカラムに存在する場合、それらをひとつのレコードにまとめることができます。
テーブル作成
今回のGROUP BYではusersテーブルだとあまり適切ではないため、新たにテーブルを作成しましょう。
今回は簡単な商品テーブルを作成します。
CREATE TABLE items (
id int AUTO_INCREMENT PRIMARY KEY NOT NULL,
name VARCHAR(50) NOT NULL,
price int NOT NULL,
purchase_date timestamp default current_timestamp,
user_id int NOT NULL,
FOREIGN KEY (user_id) REFERENCES users(id)
)
テーブルのダミーデータを作成しましょう
(同じ商品名が欲しいので、nameは手動で入力)
※id=1は削除したので2からスタート
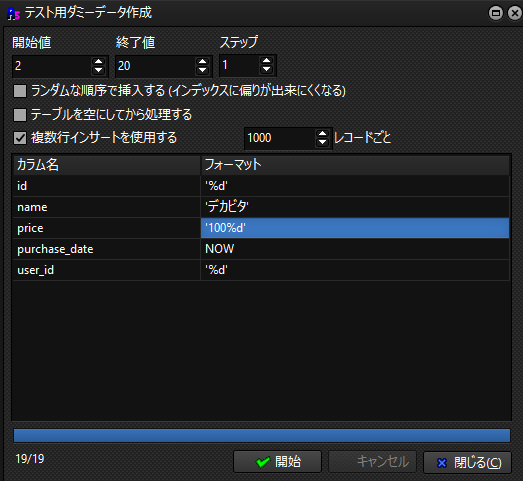
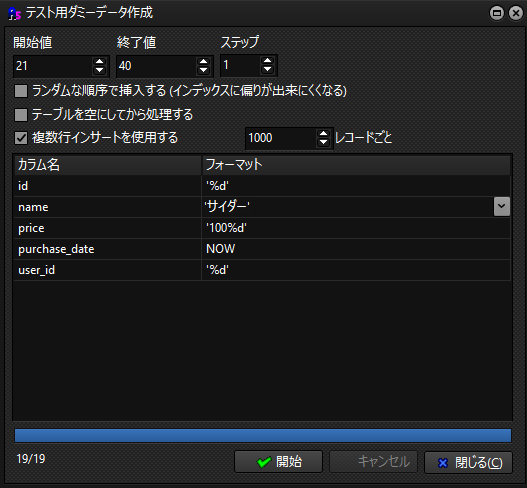
これでテーブルのデータが作成されました
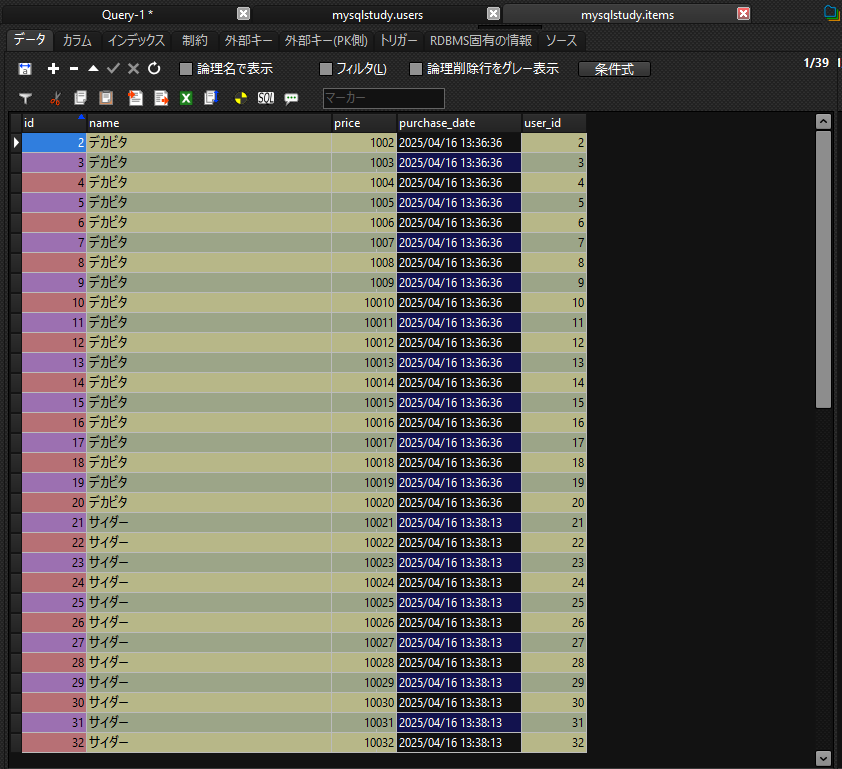
それでは作成したデータでGROUP BYを学んでいきましょう。
構文
SELECT カラム名 FROM テーブル名 GROUP BY カラム名, 条件
※GROUP BYを使用したい場合、*(全選択)を使用することはできません。
まずはGROUP BYを使用してみましょう。
SELECT name FROM items GROUP BY name;
結果
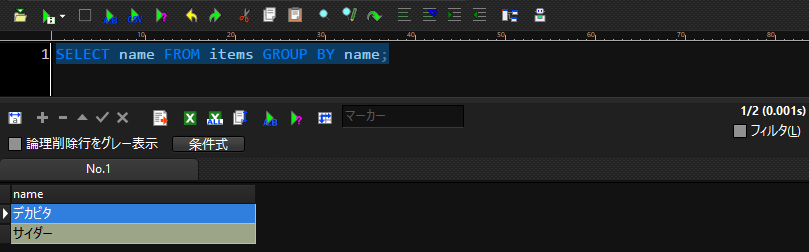
このようにnameカラムが2つだけ出力されました。
GROUP BYでnameを指定したことで、重複しているnameがすべて一行にまとめられているということです。
これを利用することで、商品の販売合計価格や販売数を簡単に取得することができます。
合計
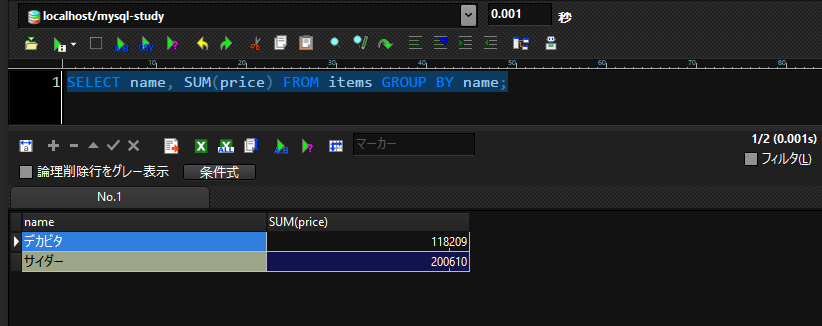
SELECT name, SUM(price) FROM items GROUP BY name;
※SUMは対象のカラムの合計値を取得することあできる関数です。
結果
これで二つの商品の販売合計価格が取得できました。
平均
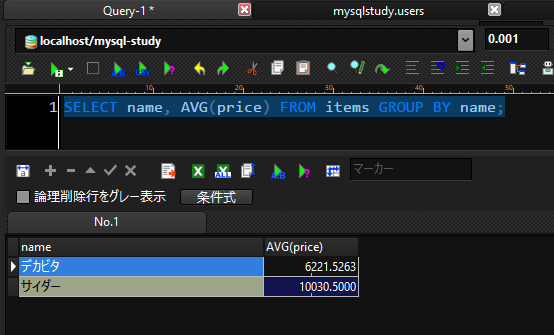
SELECT name, AVG(price) FROM items GROUP BY name;
※AVG:平均値を取得します。
結果
priceの平均値を取得することができました
個数
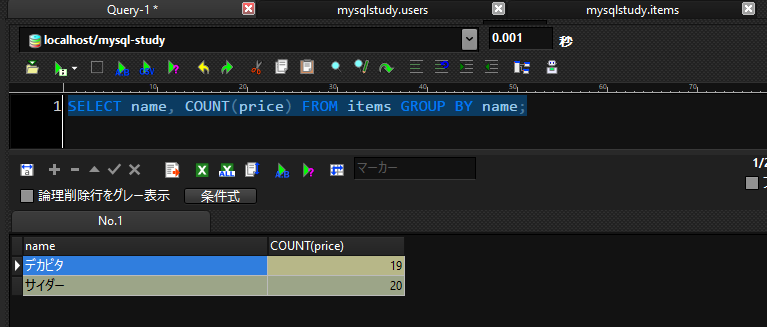
SELECT name, COUNT(price) FROM items GROUP BY name;
※COUNT:件数を取得します。
結果
各項目の件数を取得できました
注意
以下のように、priceカラムを使用する際に、関数を使用せずに記載するとエラーが発生するので気を付けてください。
SELECT name, price FROM items GROUP BY name;
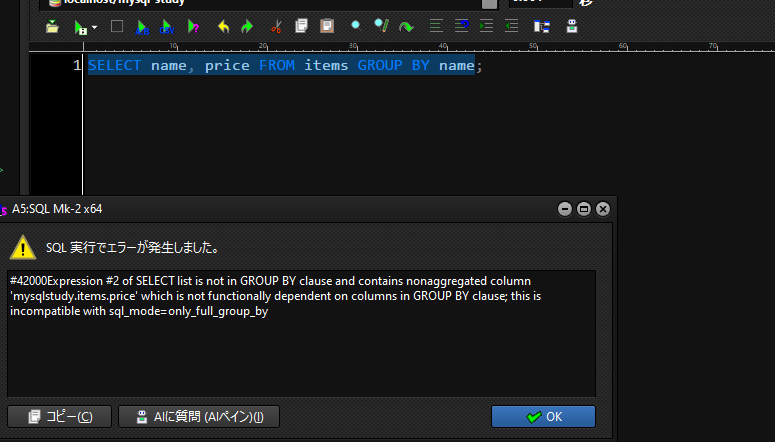
※補足
また、これ以外にも最大値、最小値を取得するための関数があり、
それもGROUP BYと合わせて使用することができます。
最大値
SELECT name, MAX(price) FROM items GROUP BY name;
最小値
SELECT name, MIN(price) FROM items GROUP BY name;
HAVING
HAVINGは出力する値をフィルターしたい場合に使用します。
SELECT カラム名 FROM テーブル名 GROUP BY カラム名 HAVING 条件式
条件式には主に
カラム=値
NOT NULL
などが入ります
先ほどの商品テーブルで試していきましょう。
まず、わかりやすいようにデータを少し追加
HAVINGは基本的にGROUP BYと一緒に使用します。
※理由は後述
以下を実際に実行してみましょう。
※HAVINGは通常GROUP BYとセットで使用し、集計結果に条件をかける際に使用します。
まずはGROUP BYで全体を一度集計してい見ましょう。
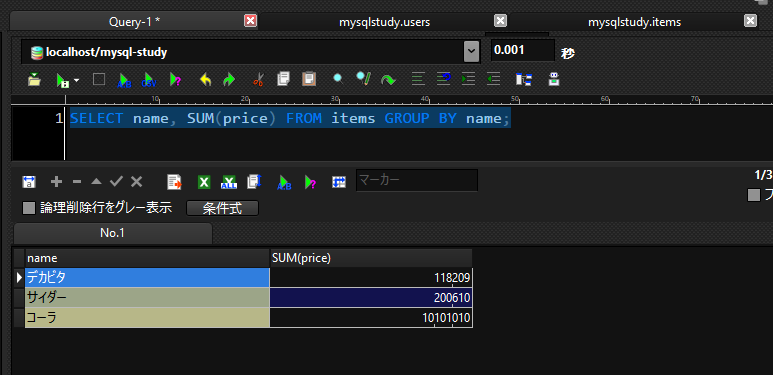
SELECT name, SUM(price) FROM items GROUP BY name;
デカビタ、サイダー、コーラに集計されました。
SUMを使用しているため、各レコードの合計値が出力されています。
HAVINGはこれをさらに絞り込むために使用します。
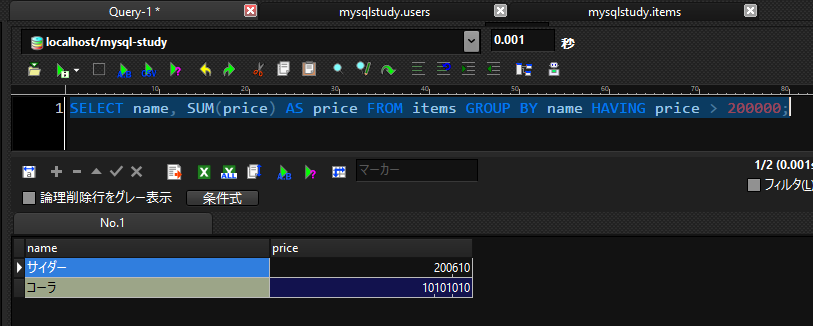
例えば売り上げが200000円以上の商品を知りたい場合、以下SQLで取得することができます。
SELECT name, SUM(price) AS price FROM items GROUP BY name HAVING price > 200000;
結果
結果として合計金額が200000円以上の商品が出力されました。
つまり集計(グループ化)→フィルターといった流れです。
疑問
HAVINGとWHEREに関して、何が違うのか?
と思う方がいると思います。(私です)
HAVINGとWHEREは基本的に動作は同じです。
何が違うのかというと、実行順序が違います。
SQLは下記順序で基本的に実行されていきます
FROM>JOIN>WHERE>GROUP BY>HAVING>SELECT>DISTINCT>ORDER BY>LIMIT
つまり、WHEREはGROUP BYでグループ化される前に条件を適用します。
HAVINGはGROUP BYでグループ化された後に条件を適用します。
そのためGROUP BYの使用や集計関数の有無でどちらを使うか判断していきましょう。
まとめ
今回は以下の構文を学習しました。
-
WHERE:条件指定 -
ORDER BY:並び替え -
GROUP BY:グループ化 -
HAVING:条件指定
これらの語句は業務でもたびたび使用することがあるので、しっかり覚えておきましょう。
次回はINNER JOIN/LEFT JOIN/集計関数について学習していきます。
引き続き、SQLの基礎力を高める学習記事を投稿していきます!
前:SQL学習入門 | INSERT/SELECT/DELETE/UPDATE 基本構文を学習してみた
次:SQL学習入門 | INNER JOINとOUTER JOINの違いを実例で解説
参考文献
【22日間で学ぶ】SQL文、分析関数、テーブル設計、SQLチューニングまでMySQLで覚えるSQL実践講座