※2018年06月23日追記
PyTorchを使用した最新版の内容を次の書籍にまとめました。
つくりながら学ぶ! 深層強化学習 ~PyTorchによる実践プログラミング~ 18年6月28日発売
強化学習の代表的な手法である「SARSA法」と「モンテカルロ法」の、実装コード紹介と解説を行います
学習する対象には、強化学習の「Hello World!」的存在である「CartPole」を使用します。
概要
強化学習の代表的な手法であるSARSA法、モンテカルロ法の2通りを実装・解説します。
※ディープラーニングは使用しません。古典的?な強化学習です。
・どちらも150行程度の短いプログラムです
・外部の強化学習ライブラリなどを使用せず、自力で組んでいます
・コメント多めです
・保守性よりも、初学者が分かりやすいことを優先してコードを書いています
【対象者】
・Qiitaの強化学習の記事「ゼロからDeepまで学ぶ強化学習」を読み、次は実装方法を知りたい方
・強化学習に興味はあるが、実装方法が思い浮かばない方
・SARSAやモンテカルロ法を、実装してみたい方
・難しい数式を並べられるよりも、実際のコードを見たほうが理解が進む方
【得られるもの】
SARSA法およびモンテカルロ法を用いた「シンプルミニマムな強化学習の実装例」を知ることができます。
【注意】
本記事に入る前に、以下の記事で、強化学習、Q学習について概要をつかんでください。
SARSA、モンテカルロ法の説明もあります。
●強化学習入門 ~これから強化学習を学びたい人のための基礎知識~
その後、以下の記事で、棒立て問題を制御する「Open AI gymのCartPoleの使い方」と「Q学習の実装方法」をご覧ください。
●CartPoleでQ学習(Q-learning)を実装・解説【Phythonで強化学習:第1回】
それではまずSARSA法について説明します。
SARSA法
SARSAとは、
State, Action, Reward, State(next), Action(next)の頭文字をとった手法です。
SARSA法とQ学習と比べてみると、Q関数の更新方法が少し異なるだけです。
Q学習の実装を理解していれば、SARSAは簡単に理解することができます。
まずおさらいとして、Q学習での
Q関数 = Q(State, Action)
の更新について説明します。
Q学習では、Q(State, Action)が
Reward + γ*MAX[Q(State(next), Action(next))]
に近づくように更新しました。
(γは時間割引率)
そしてQ関数更新後に、実際に行う次の行動Action(next)を、ε-greedy法にしたがって決定しました。
※ε-greedy法
報酬が最大になると期待される行動を選択するが、ときおりランダムに行動して、探索と最適化のバランスをとる手法
そのため、Q学習の場合はQ関数の更新に使用したAction(next)と、次の時刻での実際の行動Action(next)が異なる可能性がありました。
次に、SARSA法でのQ(State, Action)の更新について説明します。
SARSAでは次の時刻の行動Action(next)を、Q関数の更新より前に決定します。
なお、SARSAでも、次の行動Action(next)はε-greedy法にしたがって決定します。
そしてQ関数の更新を
Q(State, Action)が
Reward + γ*Q(State(next), Action(next))
に近づくように更新します。
つまりSARSAでは、実際に行う次の行動のQ値を使用して、Q関数を更新します。
ステップ数が進み、ε-greedy法がほとんど探索を行わず最適行動のみを行う場合には、Q学習もSARSAも同じとなります。
一方で試行の初期で探索が多い場面では、SARSAは実際の行動を反映し、Q学習は期待される最大のものを使用するという特徴があります。
一般的にSARSAはQ関数の更新に最適値を使わないため、Q学習よりも収束が遅いですが、局所解に陥りにくいそうです。by これからの強化学習
SARSAという方法もあること、そしてその実装方法を知っておくのは良いと思います。
SARSAでの学習は約1000試行で収束し、例えば以下のような結果になります。
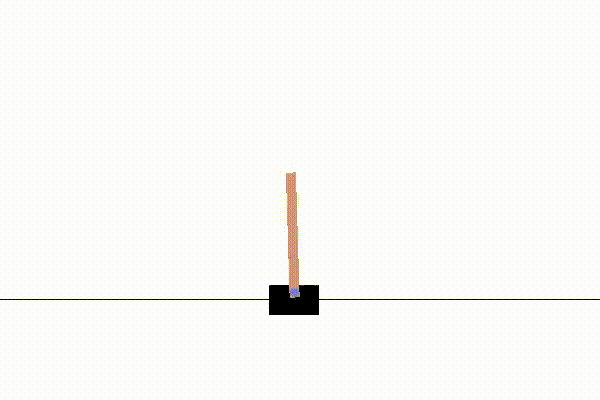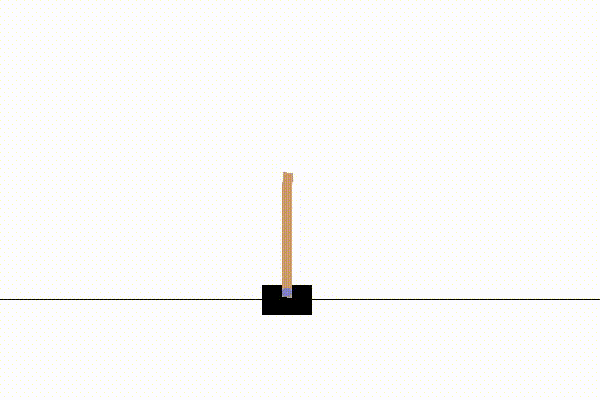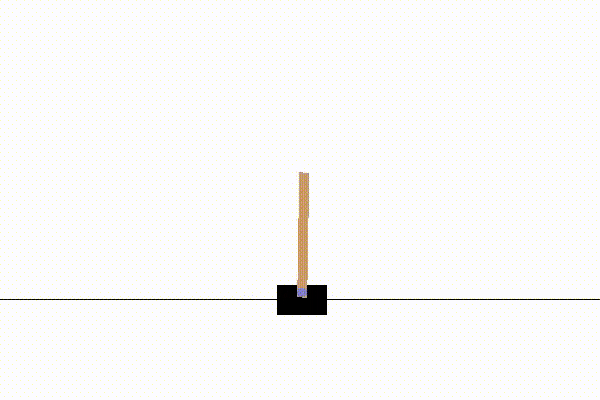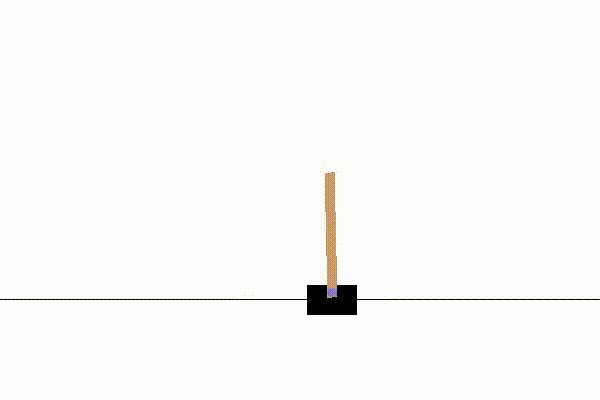
実装:SARSA
実装コードは以下の通りです。
# coding:utf-8
# [0]ライブラリのインポート
import gym #倒立振子(cartpole)の実行環境
from gym import wrappers #gymの画像保存
import numpy as np
import time
# [1]Q関数を離散化して定義する関数 ------------
# 観測した状態を離散値にデジタル変換する
def bins(clip_min, clip_max, num):
return np.linspace(clip_min, clip_max, num + 1)[1:-1]
# 各値を離散値に変換
def digitize_state(observation):
cart_pos, cart_v, pole_angle, pole_v = observation
digitized = [
np.digitize(cart_pos, bins=bins(-2.4, 2.4, num_dizitized)),
np.digitize(cart_v, bins=bins(-3.0, 3.0, num_dizitized)),
np.digitize(pole_angle, bins=bins(-0.5, 0.5, num_dizitized)),
np.digitize(pole_v, bins=bins(-2.0, 2.0, num_dizitized))
]
return sum([x * (num_dizitized**i) for i, x in enumerate(digitized)])
# [2]行動a(t)を求める関数 -------------------------------------
def get_action(next_state, episode): # 徐々に最適行動のみをとる、ε-greedy法
epsilon = 0.5 * (1 / (episode + 1))
if epsilon <= np.random.uniform(0, 1):
next_action = np.argmax(q_table[next_state])
else:
next_action = np.random.choice([0, 1])
return next_action
# [3]Qテーブルを更新する関数(SARSA) *Qlearningと異なる* -------------------------------------
def update_Qtable_sarsa(q_table, state, action, reward, next_state, next_action):
gamma = 0.99
alpha = 0.5
q_table[state, action] = (1 - alpha) * q_table[state, action] +\
alpha * (reward + gamma * q_table[next_state, next_action])
return q_table
# [4]. メイン関数開始 パラメータ設定--------------------------------------------------------
env = gym.make('CartPole-v0')
max_number_of_steps = 200 #1試行のstep数
num_consecutive_iterations = 100 #学習完了評価に使用する平均試行回数
num_episodes = 2000 #総試行回数
goal_average_reward = 195 #この報酬を超えると学習終了(中心への制御なし)
# 状態を6分割^(4変数)にデジタル変換してQ関数(表)を作成
num_dizitized = 6 #分割数
q_table = np.random.uniform(low=-1, high=1, size=(num_dizitized**4, env.action_space.n))
total_reward_vec = np.zeros(num_consecutive_iterations) #各試行の報酬を格納
final_x = np.zeros((num_episodes, 1)) #学習後、各試行のt=200でのxの位置を格納
islearned = 0 #学習が終わったフラグ
isrender = 0 #描画フラグ
# [5] メインルーチン--------------------------------------------------
for episode in range(num_episodes): #試行数分繰り返す
# 環境の初期化
observation = env.reset()
state = digitize_state(observation)
action = np.argmax(q_table[state])
episode_reward = 0
for t in range(max_number_of_steps): #1試行のループ
if islearned == 1: #学習終了したらcartPoleを描画する
env.render()
time.sleep(0.1)
print (observation[0]) #カートのx位置を出力
# 行動a_tの実行により、s_{t+1}, r_{t}などを計算する
observation, reward, done, info = env.step(action)
# 報酬を設定し与える
if done:
if t < 195:
reward = -200 #こけたら罰則
else:
reward = 1 #立ったまま終了時は罰則はなし
else:
reward = 1 #各ステップで立ってたら報酬追加
episode_reward += reward #報酬を追加
# 離散状態s_{t+1}を求める
next_state = digitize_state(observation) #t+1での観測状態を、離散値に変換
# *ここがQlearningと異なる*
next_action = get_action(next_state, episode) # 次の行動a_{t+1}を求める
q_table = update_Qtable_sarsa(q_table, state, action, reward, next_state, next_action)
# 次の行動と状態に更新
action = next_action # a_{t+1}
state = next_state # s_{t+1}
# 終了時の処理
if done:
print('%d Episode finished after %f time steps / mean %f' %
(episode, t + 1, total_reward_vec.mean()))
total_reward_vec = np.hstack((total_reward_vec[1:],
episode_reward)) #報酬を記録
if islearned == 1: #学習終わってたら最終のx座標を格納
final_x[episode, 0] = observation[0]
break
if (total_reward_vec.mean() >=
goal_average_reward): # 直近の100エピソードが規定報酬以上であれば成功
print('Episode %d train agent successfuly!' % episode)
islearned = 1
#np.savetxt('learned_Q_table.csv',q_table, delimiter=",") #Qtableの保存する場合
if isrender == 0:
#env = wrappers.Monitor(env, './movie/cartpole-experiment-1') #動画保存する場合
isrender = 1
#10エピソードだけでどんな挙動になるのか見たかったら、以下のコメントを外す
#if episode>10:
# if isrender == 0:
# env = wrappers.Monitor(env, './movie/cartpole-experiment-1') #動画保存する場合
# isrender = 1
# islearned=1;
if islearned:
np.savetxt('final_x.csv', final_x, delimiter=",")
Q学習のコード
CartPoleでQ学習(Q-learning)を実装・解説【Phythonで強化学習:第1回】
に比べて、
[3] Qテーブルを更新する関数(SARSA)
のQ関数更新部分が異なっています。
Q学習では次の行動を決めておく必要はありませんでしたが、SARSAでは次の行動Action(next)を決め、Q関数の更新に使用しています。
それでは次に、モンテカルロ法による強化学習について説明します。
モンテカルロ法による強化学習
モンテカルロ法による強化学習は、Q学習やSARSAとは少し毛色が異なります。
Q関数を使用するという点は同じです。
一方で、モンテカルロ法では、各ステップごとにQ関数を更新しないという特徴があります。
その代わりに、試行が終了した時点で、Q関数を全ステップ分、一気に更新します。
そのため、試行終了までの、各ステップでの(状態s、行動a、得た報酬r)をすべて記憶しておきます。
それではモンテカルロ法でのQ関数の更新を説明します。
例えば、ステップ t = T で、Poleが倒れたとします。
そのときの状態と行動はs(T)とa(T)と表されます。
またそのステップで得た報酬はr(T)となります。
するとQ関数の更新は、
Q(s_T, a_T) が r(T) に近づくように更新します。
その後、現在時刻を含めその先で得られた報酬を、total_reward_tとして表すことにします。
時刻Tでは
total_reward_t = r(T)
です。
total_reward_tは、次のステップ以降で順繰りに使用します。
次にステップを一つ前に戻り、t = T-1 を更新します。
そこでの更新は、
Q(s_{T-1}, a_{T-1})が、
r(T-1) + γ * r(T) に近づくように更新します。
これは先ほど定義したtotal_reward_tを使用すれば、
r(T-1) + γ * total_reward_t
と表されます。
先に
total_reward_t ← γ * total_reward_t
と更新しておけば、
r(T-1) + γ * r(T) は、r(T-1) + total_reward_t と表されます。
そのため、Q(s_{T-1}, a_{T-1}) が
r(T-1) + total_reward_t
に近づくように更新することになります。
最後に、
total_reward_t ← r(T-1) + total_reward_t
と更新しておきます。
次にさらにステップを一つさかのぼり、t = T-2 を考えます。
そこでの更新は、
Q(s_{T-2}, a_{T-2})が、
r(T-2) + γ * r(T-1) + γ * γ * r(T)
に近づくように更新します。
先に
total_reward_t ← γ * total_reward_t
と更新しておけば、
r(T-2) + total_reward_t
となります。
そのため、Q(s_{T-2}, a_{T-2})が
r(T-2) + total_reward_t
に近づくように更新することになります。
最後に、
total_reward_t ← r(T-2)+total_reward_t
と更新しておきます。
次は t = T-3 を行います。
total_reward_t ← γ * total_reward_t
と更新して、
Q(s_{T-3}, a_{T-3})が
r(T-3) + total_reward_t
に近づくように更新することになります。
ずっとこの繰り返しです。
このようにQ関数を、試行の最後のステップから時刻0まで順番に更新していきます。
モンテカルロ法には試行の途中でQ関数を更新できないという欠点があります。
一方で2つの利点があります
1つ目の利点は、実際に得た報酬でQ関数を更新できるという点です。
Q学習やSARSAの場合にはQ関数:Q(s_t, a_t)の更新にQ(s_{t+1}, a_{t+1})というまだ学習が終わっていないQ関数を使用していました。
一方でモンテカルロ法では実際に得た報酬を更新に使用するので、学習初期でQ関数が確かな方向に学習しやすいという利点につながります。
2つ目の利点が、「試行の途中で報酬がもらえない」、もしくは「報酬をうまく規定しづらいタスク」の学習に対応しやすいということです。
例えば囲碁や将棋などでは、途中の報酬を決めるのが難しいです。
(飛車を取られても、局面が有利になることもあるかもしれないですし)
その場合、最終的に勝った、負けた、だけが、信頼ある報酬と考えることができます。
このような最終的結果からQ関数を学習することができます。
私がモンテカルロ法を知ってはじめに疑問だったのが「行動の決め方」です。
ですが、これは通常のε-greedy法で大丈夫です。
以上の点を踏まえて、結果とコードを紹介します。
だいたい1000試行以下で学習が収束します。
例えば以下のような結果になります。
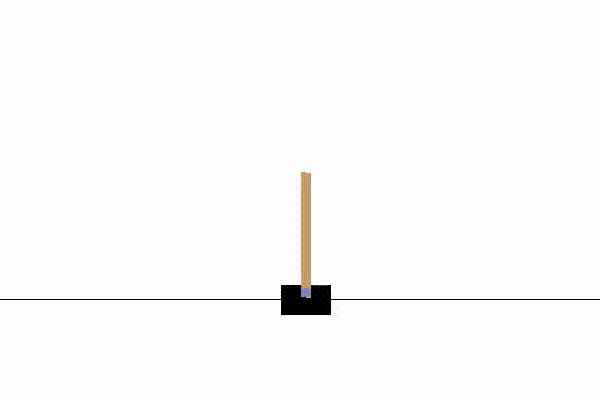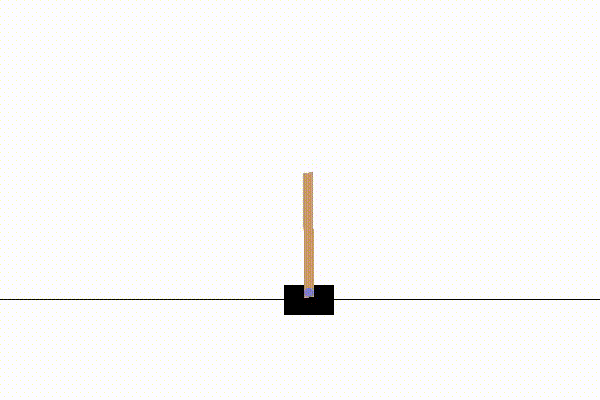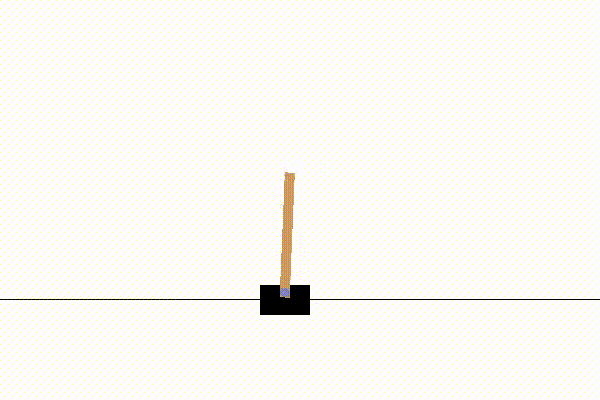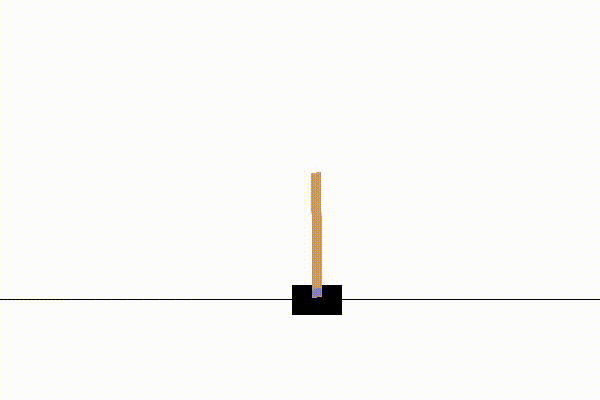
実装:モンテカルロ法
実装したコードがこちらです。
# coding:utf-8
# [0]ライブラリのインポート
import gym # 倒立振子(cartpole)の実行環境
from gym import wrappers #gymの画像保存
import numpy as np
import time
from collections import deque
# [1]Q関数を離散化して定義する関数 ------------
# 観測した状態を離散値にデジタル変換する
def bins(clip_min, clip_max, num):
return np.linspace(clip_min, clip_max, num + 1)[1:-1]
# 各値を離散値に変換
def digitize_state(observation):
cart_pos, cart_v, pole_angle, pole_v = observation
digitized = [
np.digitize(cart_pos, bins=bins(-2.4, 2.4, num_dizitized)),
np.digitize(cart_v, bins=bins(-3.0, 3.0, num_dizitized)),
np.digitize(pole_angle, bins=bins(-0.5, 0.5, num_dizitized)),
np.digitize(pole_v, bins=bins(-2.0, 2.0, num_dizitized))
]
return sum([x * (num_dizitized**i) for i, x in enumerate(digitized)])
# [2]行動a(t)を求める関数 -------------------------------------
def get_action(next_state, episode): # 徐々に最適行動のみをとる、ε-greedy法
epsilon = 0.5 * (1 / (episode + 1))
if epsilon <= np.random.uniform(0, 1):
next_action = np.argmax(q_table[next_state])
else:
next_action = np.random.choice([0, 1])
return next_action
# [3]1試行の各ステップの行動を保存しておくメモリクラス
class Memory:
def __init__(self, max_size=200):
self.buffer = deque(maxlen=max_size)
def add(self, experience):
self.buffer.append(experience)
def sample(self):
return self.buffer.pop() # 最後尾のメモリを取り出す
def len(self):
return len(self.buffer)
# [4]Qテーブルを更新する(モンテカルロ法) *Qlearningと異なる* -------------------------------------
def update_Qtable_montecarlo(q_table, memory):
gamma = 0.99
alpha = 0.5
total_reward_t = 0
while (memory.len() > 0):
(state, action, reward) = memory.sample()
total_reward_t = gamma * total_reward_t # 時間割引率をかける
# Q関数を更新
q_table[state, action] = q_table[state, action] + alpha*(reward+total_reward_t-q_table[state, action])
total_reward_t = total_reward_t + reward # ステップtより先でもらえた報酬の合計を更新
return q_table
# [5]. メイン関数開始 パラメータ設定--------------------------------------------------------
env = gym.make('CartPole-v0')
max_number_of_steps = 200 #1試行のstep数
num_consecutive_iterations = 100 #学習完了評価に使用する平均試行回数
num_episodes = 2000 #総試行回数
goal_average_reward = 195 #この報酬を超えると学習終了(中心への制御なし)
# 状態を6分割^(4変数)にデジタル変換してQ関数(表)を作成
num_dizitized = 6 #分割数
memory_size = max_number_of_steps # バッファーメモリの大きさ
memory = Memory(max_size=memory_size)
q_table = np.random.uniform(low=-1, high=1, size=(num_dizitized**4, env.action_space.n))
total_reward_vec = np.zeros(num_consecutive_iterations) #各試行の報酬を格納
final_x = np.zeros((num_episodes, 1)) #学習後、各試行のt=200でのxの位置を格納
islearned = 0 #学習が終わったフラグ
isrender = 0 #描画フラグ
# [5] メインルーチン--------------------------------------------------
for episode in range(num_episodes): #試行数分繰り返す
# 環境の初期化
observation = env.reset()
state = digitize_state(observation)
action = np.argmax(q_table[state])
episode_reward = 0
for t in range(max_number_of_steps): #1試行のループ
if islearned == 1: #学習終了したらcartPoleを描画する
env.render()
time.sleep(0.1)
print (observation[0]) #カートのx位置を出力
# 行動a_tの実行により、s_{t+1}, r_{t}などを計算する
observation, reward, done, info = env.step(action)
# 報酬を設定し与える
if done:
if t < 195:
reward = -200 #こけたら罰則
else:
reward = 1 #立ったまま終了時は罰則はなし
else:
reward = 1 #各ステップで立ってたら報酬追加
# メモリに、現在の状態と行った行動、得た報酬を記録する
memory.add((state, action, reward))
# 次ステップへ行動と状態を更新
next_state = digitize_state(observation) # t+1での観測状態を、離散値に変換
next_action = get_action(next_state, episode) # 次の行動a_{t+1}を求める
action = next_action # a_{t+1}
state = next_state # s_{t+1}
episode_reward += reward #報酬を追加
# 終了時の処理
if done:
# これまでの行動の記憶と、最終的な結果からQテーブルを更新していく
q_table = update_Qtable_montecarlo(q_table, memory)
print('%d Episode finished after %f time steps / mean %f' %
(episode, t + 1, total_reward_vec.mean()))
total_reward_vec = np.hstack((total_reward_vec[1:],
episode_reward)) #報酬を記録
if islearned == 1: #学習終わってたら最終のx座標を格納
final_x[episode, 0] = observation[0]
break
if (total_reward_vec.mean() >=
goal_average_reward): # 直近の100エピソードが規定報酬以上であれば成功
print('Episode %d train agent successfuly!' % episode)
islearned = 1
#np.savetxt('learned_Q_table.csv',q_table, delimiter=",") #Qtableの保存する場合
if isrender == 0:
# env = wrappers.Monitor(env, './movie/cartpole-experiment-1') #動画保存する場合
isrender = 1
#10エピソードだけでどんな挙動になるのか見たかったら、以下のコメントを外す
#if episode>10:
# if isrender == 0:
# env = wrappers.Monitor(env, './movie/cartpole-experiment-1') #動画保存する場合
# isrender = 1
# islearned=1;
if islearned:
np.savetxt('final_x.csv', final_x, delimiter=",")
以上、強化学習のSARSAとモンテカルロ法を紹介しました。
また次回も強化学習の実装を紹介する予定ですので、よろしくお願いします。
以上、ご一読いただき、ありがとうございました。