本シリーズでは、「FXの予測プログラム」を作りながら、機械学習・ディープラーニングを解説します。
(注)のび太くんは有名漫画のキャラとは一切関係ありません。
この物語は、大学生のび太くんが、家庭教師のすぐるさんから機械学習を学び、将来D-mind社を起業して、汎用人工知能搭載型ロボットを誕生させるまでの記録です。
これまでのお話
のび太くんはiPhone Xを買うために、FX予測プログラムを作成しようと、すぐるさんから機械学習を学び始めました。
第1話:のび太、if文でFXを予想する
第2話:のび太、線形回帰を学ぶ
今回は、前話で学習した線形回帰を利用して、ついにのび太くんのFX予想プログラムが完成します。
(注)本ページを参考にして生じた損益については責任を持てませんので、あしからず。
第3話:のび太、完成:FX予測プログラム(線形回帰版)
さて、のび太くん、本日は「線形回帰」を利用したFX予測プログラムを作成しようか。
今日は突然本題から入るんだね。
よしやるぞ!
ところで、線形回帰は覚えているかい?
もちろんさ。本を買って、復習もしたよ。
学習データの$Y_{train}$と$X_{train}$の間にある線形モデル
y_p(t)=\mathbf{w}^T\mathbf{x}(t)+b
を求めて、その後テストデータで予測具合を確かめる。
この線形モデルの係数、$\mathbf{w}=w_0~w_{N}$と$b$は、学習データの「予測の2乗誤差の和」
E(\mathbf{w}, b)=\sum_{t=0}^{M}\left [ {y_{train}(t)-y_p(t)} \right ]^2=\sum_{t=0}^{M}\left [ {y_{train}(t)-\left \{\mathbf{w}^T\mathbf{x}(t)+b \right \}} \right ]^2
に対して、$E$が最小値となる値を、$\mathbf{w}$と$b$で$E(\mathbf{w}, b)$を偏微分して、少しずつ更新して求める。
これで合っている?
すごいな、のび太くん。正解だよ。
補足すると、実際の線形回帰は勾配降下法ではなく、一度の計算で$\mathbf{w}$と$b$を求めているけど、やりたいことは一緒だよ。
あと前回言い忘れたけど、$Y$を被説明変数や目的変数と呼び、$X$を説明変数と呼ぶよ。
やった!じゃあ、今日は早速FXのデータでやろうよ!
ツネ夫がiPhone Xをもう持っていて、自慢してくるんだよ・・・
よし、少しずつコードを作りながら、説明していこう。
実装その1
まず作りたいプログラムを整理しよう。
2007年~2016年のドル円の日足データを学習データとして使用し、
翌日のドル円の終値が、当日の終値に対して、何円高いか(もしくは安いか)を予測するプログラムを作成するよ。
入力データには過去25日分のデータを使用する。
うん、25日分でだいたい1ヶ月のデータになるからだよね。
そうだね。
このような、入力データから数値を予測する機械学習を「回帰」と呼ぶよ。
さあ、早速作っていこう。
今回のコードは全部僕のGitHubにおいて置くね。
本記事の掲載コードはこちら
最初はいつものおまじないゾーンだ。
って言っても、これから使うライブラリを宣言しているだけだよ。
# import関連
import numpy as np
import pandas as pd
import matplotlib
import matplotlib.pylab as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore') # 実行上問題ない注意は非表示にする
%matplotlib inline
次に、ドル円の為替データを読み込むよ。
フォルダの場所はのび太くんが為替データを置いた場所を指定してね。
為替データは、GitHubに置いているよ。
データはこちら
※為替データは、フリーでログイン不要のデータサイトStooqから取得しました。
Stooq
# dataフォルダの場所を各自指定してください
data_dir = "./"
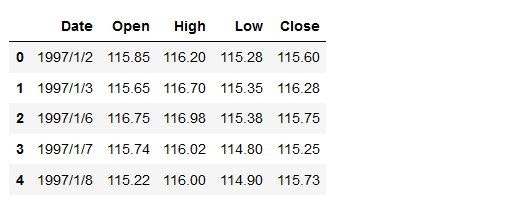
data = pd.read_csv(data_dir + "USDJPY_1997_2017.csv") # FXデータの読み込み(データは同じリポジトリのdataフォルダに入っています)
data.head() # データの概要を見てみます
つぎに、読み込んだデータをNumPyの形式に変換するよ。
# pandasのDataFrameのままでは、扱いにくい+実行速度が遅いので、numpyに変換して処理します
data2 = np.array(data)
どうして、numpyに変換するの?
pandasはデータ形式としては扱いやすいけど、数値計算が遅いし、有効桁数も少ないからだよ。
numpyは数値計算に適したデータ形式なんだ。
次に説明変数$X$を作成するよ。
Xは、行ごとに、当日から24日前までの終値を列方向に並べた25列の行列になるよ。
# 説明変数となる行列Xを作成します
day_ago = 25 # 何日前までのデータを使用するのかを設定
num_sihyou = 1 # 終値
X = np.zeros((len(data2), day_ago*num_sihyou))
# 終値をfor文でday_ago日前まで一気に追加する
for i in range(0, day_ago):
X[i:len(data2),i] = data2[0:len(data2)-i,4]
なんだか、難しいfor文でよく分からないよ。
何をしているの?
data2の列4は当日終値だよ。
これは過去25日分のデータを横向きに並べているんだよ。
一度Xをpandasに戻して、中身を見てみようか。
# Xの確認です
data_show = pd.DataFrame(X)
data_show
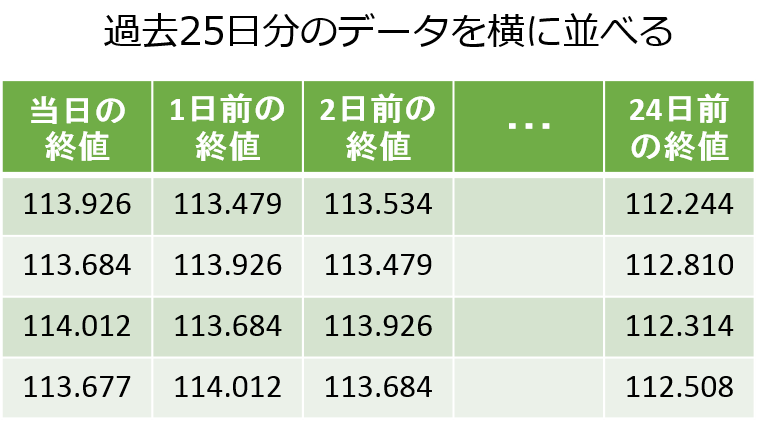
当日の終値が、1行下の翌日には、1日前の終値に入っているんだね。
なるほど。
分かった。じゃあ、同じように目的変数(被説明変数)$Y$も作成してみるよ。
# 被説明変数となる Y = pre_day後の終値-当日終値 を作成します
Y = np.zeros(len(data2))
# 何日後を値段の差を予測するのか決めます
pre_day = 1
Y[0:len(Y)-pre_day] = X[pre_day:len(X),0] - X[0:len(X)-pre_day,0]
うん、のび太くん、OKだ。良い感じだね。
ここから重要ポイントに入るね。
データを「正規化」するよ。
正規化?
正規化にもいろいろあるけど、一般には、各データに対して、平均を引き算し、標準偏差で割って
平均0、標準偏差1になるように変換することだよ。
う~ん、難しい話だね。
要は、1ドル110円台のときのデータも、100円台のときのデータも同じように扱えるようにしたいんだよ。
ただ、FXの為替データの場合は、個人的には標準偏差で割らないほうが良いと感じている。
どうして?
標準偏差のような変動の上下幅の大きさは、為替では重要な情報になるからだよ。
よく分からないや・・・
とりあえず、平均を引き算するんだね。
よしコードを書いてみるよ。
いやここは難しいから、僕が書こう。
# 【重要】X, Yを正規化します
original_X = np.copy(X) # コピーするときは、そのままイコールではダメ
tmp_mean = np.zeros(len(X))
for i in range(day_ago,len(X)):
tmp_mean[i] = np.mean(original_X[i-day_ago+1:i+1,0]) # 25日分の平均値
for j in range(0, X.shape[1]):
X[i,j] = (X[i,j] - tmp_mean[i]) # Xを正規化
Y[i] = Y[i] # X同士の引き算しているので、Yはそのまま
ただ、引き算するだけなのに、なんかややこしいね。
np.copy(X)って何?
numpyは単純に
original_X = X
ってしてしまうと、Xが変化したときに、original_Xも変化してしまうんだよ。
それを避けるために、np.copyを使っているよ。
どうしてoriginal_Xまで変わるの?
numpyはポインタ参照で値を受け渡すからだよ。
うん、難しいや。
とりあえず、単純に = で変数をコピーできないことは分かったよ。
正規化で$Y$はそのままなんだね。
$Y$は$X$の引き算になっているから、平均値を引く操作はそこでキャンセルされるからだよ。
この正規化しだいで、予測の性能が大きく変わるから、とても重要なんだよ。
さて、次に$X$と$Y$を学習データとテストデータに分けてみようか。
ここはのび太くん、書いてくれるかな。
ただし、最初のほうは使わないで、行200から使ってくれるかな。
うん、えーと・・・
カタカタ・・・
# XとYを学習データとテストデータ(2017年~)に分ける
X_train = X[200:5193,:] # 次のプログラムで200日平均を使うので、それ以降を学習データに使用します
Y_train = Y[200:5193]
X_test = X[5193:len(X)-pre_day,:]
Y_test = Y[5193:len(Y)-pre_day]
OKだよ。のび太くん。
行5193からが2017年だからね。
でも、どうして行200からを使用したの?
これはちょっと先を見越しての話だから、とりあえず保留でいいかな。
怪しいな~。分かったよ。
学習データとテストデータができたら、前回の線形回帰の練習問題と同じだね。
前と同じようにやってみるよ。
第2話:のび太、線形回帰を学ぶ
# 学習データを使用して、線形回帰モデルを作成します
from sklearn import linear_model # scikit-learnライブラリの関数を使用します
linear_reg_model = linear_model.LinearRegression()
linear_reg_model.fit(X_train, Y_train) # モデルに対して、学習データをフィットさせ係数を学習させます
print("回帰式モデルの係数")
print(linear_reg_model.intercept_)
print(linear_reg_model.coef_)
のび太くん、OKだよ。
じゃあテストデータで予測してみよう。
前回のコードに加えて、予測の正答率も計算してくれるかな。
えっと、
カタカタ・・・
# 2017年のデータで予想し、グラフで予測具合を見る
Y_pred = linear_reg_model.predict(X_test) # 予測する
result = pd.DataFrame(Y_pred) # 予測
result.columns = ['Y_pred']
result['Y_test'] = Y_test
sns.set_style('darkgrid')
sns.regplot(x='Y_pred', y='Y_test', data=result) #plotする
# 正答率を計算
success_num = 0
for i in range(len(Y_pred)):
if Y_pred[i] * Y_test[i] >=0:
success_num+=1
print("予測日数:"+ str(len(Y_pred))+"、正答日数:"+str(success_num)+"正答率:"+str(success_num/len(Y_pred)*100))
予測日数:214、正答日数:103、正答率:48.13084112149533
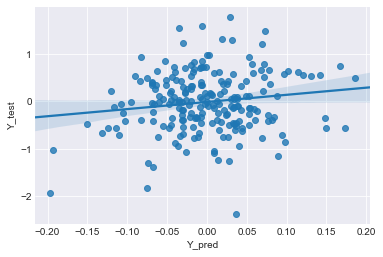
あれ、前回と違って、近似直線の周りに薄い青の塗りが出てきたよ。
これは、regplotでデータ数が多いと、自動で95%範囲を表示してくれるんだよ。
95%範囲?
近似直線は95%の確率でこの薄い青色範囲内にありますよってことを示している。
正答率を見ると、48%だから、適当に上がるか下がるかを予測した場合(50%)とほぼ変わらないね。
テスト期間(2017年1月初日から10月末まで)の予測結果の合計と変化を見てみようか。
# 2017年の予測結果の合計を計算ーーーーーーーーー
# 前々日終値に比べて前日終値が高い場合は、買いとする
sum_2017 = 0
for i in range(0,len(Y_test)): # len()で要素数を取得しています
if Y_pred[i] >= 0:
sum_2017 += Y_test[i]
else:
sum_2017 -= Y_test[i]
print("2017年の利益合計:%1.3lf" %sum_2017)
# 予測結果の総和グラフを描くーーーーーーーーー
total_return = np.zeros(len(Y_test))
if Y_pred[i] >=0: # 2017年の初日を格納
total_return[0] = Y_test[i]
else:
total_return[0] = -Y_test[i]
for i in range(1, len(result)): # 2017年の2日以降を格納
if Y_pred[i] >=0:
total_return[i] = total_return[i-1] + Y_test[i]
else:
total_return[i] = total_return[i-1] - Y_test[i]
plt.plot(total_return)
2017年の利益合計:0.245
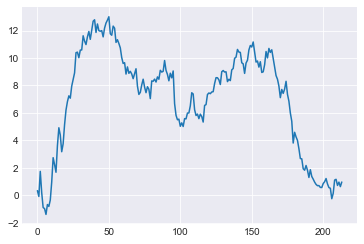
すぐるさん、0.245って少しプラスになったけど、だめだ~。
グラフを見ると、50日目くらいで14まで増えたのに、後半すごい減っているよ・・・
そうだね。
正答率も48%だし、やっぱりうまくいっていないね。
って!!すぐるさん、教えてくれるって言ったじゃないか!
あとちょっとだよ、のび太くん。
どうしてうまくいかないのか、考えるんだ。
・
・
・
実装その2
う~ん・・・
分からないよ。
そうだね。一緒に考えてみようか。
機械学習の性能は、
(機械学習の性能) = (入力データ) × (モデルの表現力)
で概念的に表されるよ。
今回は線形モデルというとても単純なモデルを使用しているから、(モデルの表現力)がとても低いんだ。
例えば、最近はやりのディープラーニングの場合は(モデルの表現力)が高いから、入力データが単純でも良い予測ができる。
ってことは、線形モデルは(モデルの表現力)が低いから、もっと良い入力データを入れれば良くなるってこと?
単純にそうとは言い切れないけど、多くの場合はその通りだよ、のび太くん。
でも、これ以上何を入力データに加えればよいんだろう・・・?
分からないよ。
そうだね。いろいろな選択肢があるけど、
FXで頻繁に使用されるテクニカル指標を使うのが良いよ。
なぜならそのテクニカル指標を使って多くの人が判断しているから、将来の為替の結果に影響するんだ。
どんなテクニカル指標があるの?
いろいろあるけど、今回は移動平均線と一目均衡表、ボリンジャーバンドの3種類を使用しよう。
移動平均線は一定期間のただの平均だよ。
一目均衡表は期間内の最高値と最安値を使った指標だよ。
ボリンジャーバンドは一定期間の標準偏差を使った指標だよ。
今回追加するテクニカル指標のパラメータには代表的な数値を使用しよう。
FXのお話ではなく、機械学習のお話だから、詳しくは自分で調べてみてね。
例えば: 外為オンラインのFX実戦チャート術ページ
よし、これらを加えたプログラムに修正してみよう。
修正コードも僕のGitHubにおいて置くね。
本記事の掲載コードはこちら
まず、5日の移動平均線を追加しよう。
# 5日移動平均を追加します
data2 = np.c_[data2, np.zeros((len(data2),1))] # 列の追加
ave_day = 5
for i in range(ave_day, len(data2)):
tmp =data2[i-ave_day+1:i+1,4].astype(np.float) # pythonは0番目からindexが始まります
data2[i,5] = np.mean(tmp)
pythonはスライスといって、行列の要素を 0 : i みたいにindexで指定したときと、ダイレクトにindexの i って指定したときで、挙動が異なるから、気をつけてね。
例えば以下のプログラムの出力は
x = [10, 20, 30, 40, 50]
i=4
print(x[0:i])
print(x[i])
[10, 20, 30, 40]
50
ってなるよ。
指標を作るときに未来の情報がXに入っちゃうと、予測できて当然になるから気をつけてね。
同じように25, 75, 200日の移動平均線を追加してみて。
うん、カタカタ・・・
# 25日移動平均を追加します
data2 = np.c_[data2, np.zeros((len(data2),1))]
ave_day = 25
for i in range(ave_day, len(data2)):
tmp =data2[i-ave_day+1:i+1,4].astype(np.float)
data2[i,6] = np.mean(tmp)
# 75日移動平均を追加します
data2 = np.c_[data2, np.zeros((len(data2),1))] # 列の追加
ave_day = 75
for i in range(ave_day, len(data2)):
tmp =data2[i-ave_day+1:i+1,4].astype(np.float)
data2[i,7] = np.mean(tmp)
# 200日移動平均を追加します
data2 = np.c_[data2, np.zeros((len(data2),1))] # 列の追加
ave_day = 200
for i in range(ave_day, len(data2)):
tmp =data2[i-ave_day+1:i+1,4].astype(np.float)
data2[i,8] = np.mean(tmp)
次は一目均衡表とボリンジャーバンドを足すね。
ここは僕が書こう
# 一目均衡表を追加します (9,26, 52)
para1 =9
para2 = 26
para3 = 52
# 転換線 = (過去(para1)日間の高値 + 安値) ÷ 2
data2 = np.c_[data2, np.zeros((len(data2),1))] # 列の追加
for i in range(para1, len(data2)):
tmp_high =data2[i-para1+1:i+1,2].astype(np.float)
tmp_low =data2[i-para1+1:i+1,3].astype(np.float)
data2[i,9] = (np.max(tmp_high) + np.min(tmp_low)) / 2
# 基準線 = (過去(para2)日間の高値 + 安値) ÷ 2
data2 = np.c_[data2, np.zeros((len(data2),1))]
for i in range(para2, len(data2)):
tmp_high =data2[i-para2+1:i+1,2].astype(np.float)
tmp_low =data2[i-para2+1:i+1,3].astype(np.float)
data2[i,10] = (np.max(tmp_high) + np.min(tmp_low)) / 2
# 先行スパン1 = { (転換値+基準値) ÷ 2 }を(para2)日先にずらしたもの
data2 = np.c_[data2, np.zeros((len(data2),1))]
for i in range(0, len(data2)-para2):
tmp =(data2[i,9] + data2[i,10]) / 2
data2[i+para2,11] = tmp
# 先行スパン2 = { (過去(para3)日間の高値+安値) ÷ 2 }を(para2)日先にずらしたもの
data2 = np.c_[data2, np.zeros((len(data2),1))]
for i in range(para3, len(data2)-para2):
tmp_high =data2[i-para3+1:i+1,2].astype(np.float)
tmp_low =data2[i-para3+1:i+1,3].astype(np.float)
data2[i+para2,12] = (np.max(tmp_high) + np.min(tmp_low)) / 2
# 25日ボリンジャーバンド(±1, 2シグマ)を追加します
parab = 25
data2 = np.c_[data2, np.zeros((len(data2),4))] # 列の追加
for i in range(parab, len(data2)):
tmp = data2[i-parab+1:i+1,4].astype(np.float)
data2[i,13] = np.mean(tmp) + 1.0* np.std(tmp)
data2[i,14] = np.mean(tmp) - 1.0* np.std(tmp)
data2[i,15] = np.mean(tmp) + 2.0* np.std(tmp)
data2[i,16] = np.mean(tmp) - 2.0* np.std(tmp)
これで最初は終値だけから予測していたのが、
終値1本、移動平均線4本、一目均衡表4本、ボリンジャー4本の合計13本になったよ。
すぐるさん、ということは13×25で、え~っと、
325個の入力データで線形モデルを作るってことだね。
ここで200日移動平均線を使用するから、最初のプログラムも200日以降を学習データにしたんだね。
その通りだよ。
じゃあ最初と同じように、各日ごとに325個が列方向に並ぶように変換してもらえるかな。
よし、カタカタ・・・
# 説明変数となる行列Xを作成します
day_ago = 25 # 何日前までのデータを使用するのかを設定
num_sihyou = 1 + 4 + 4 +4 # 終値1本、MVave4本、itimoku4本、ボリンジャー4本
X = np.zeros((len(data2), day_ago*num_sihyou))
for s in range(0, num_sihyou): # 日にちごとに横向きに並べる
for i in range(0, day_ago):
X[i:len(data2),day_ago*s+i] = data2[0:len(data2)-i,s+4]
あとは1回目と同じように線形回帰を実行してもらえるかな。
うん、カタカタ・・・
# 2017年のデータで予想し、グラフで予測具合を見る
Y_pred = linear_reg_model.predict(X_test) # 予測する
result = pd.DataFrame(Y_pred) # 予測
result.columns = ['Y_pred']
result['Y_test'] = Y_test
sns.set_style('darkgrid')
sns.regplot(x='Y_pred', y='Y_test', data=result) #plotする
# 正答率を計算
success_num = 0
for i in range(len(Y_pred)):
if Y_pred[i] * Y_test[i] >=0:
success_num+=1
print("予測日数:"+ str(len(Y_pred))+"、正解日数:"+str(success_num)+"正解率:"+str(success_num/len(Y_pred)*100))
予測日数:214、正解日数:124、正解率:57.943925233644855
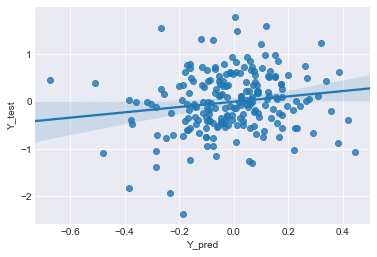
正答率が58%になったよ!!
うん、いい感じだね。
よし、合計も計算してみるぞ!
# 2017年の予測結果の合計を計算ーーーーーーーーー
# 前々日終値に比べて前日終値が高い場合は、買いとする
sum_2017 = 0
for i in range(0,len(Y_test)): # len()で要素数を取得しています
if Y_pred[i] >= 0:
sum_2017 += Y_test[i]
else:
sum_2017 -= Y_test[i]
print("2017年の利益合計:%1.3lf" %sum_2017)
# 予測結果の総和グラフを描くーーーーーーーーー
total_return = np.zeros(len(Y_test))
if Y_pred[0] >=0: # 2017年の初日を格納
total_return[0] = Y_test[0]
else:
total_return[0] = -Y_test[0]
for i in range(1, len(result)): # 2017年の2日以降を格納
if Y_pred[i] >=0:
total_return[i] = total_return[i-1] + Y_test[i]
else:
total_return[i] = total_return[i-1] - Y_test[i]
plt.plot(total_return)
2017年の利益合計:22.089
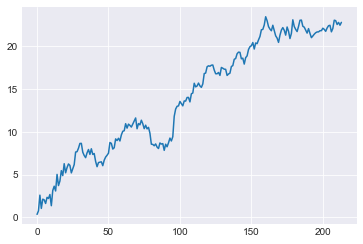
すぐるさん、22でプラスになったよ!!
やったー!!
ときおり減るときもあるけど、右肩上がりに増えているね。
完成したね!これが線形回帰でのFXの予測プログラムだよ。
本記事の掲載コードはこちら
+22ってことは、1000通貨だったら、22,000円、1万通貨なら22万円、10万通貨なら220万円儲かるってことだよね!
でも、手数料は考えなくていいの?
1日1回の取引なら、手数料はほぼ無視できると考えていいよ。
正確には手数料(本当はスプレッド)が0.3銭(0.003円)だとすると、約200日の取引で0.6くらいになるから、
22-0.6 が、正しい値だよ。
よし!じゃあこれでiPhone Xが買えるぞ!!
・
・
・
あれ?すぐるさんもこの方法でFXをやっているの?
いや、僕は使っていないよ。
これは、今回のび太くんの勉強のために作成したプログラムだからね。
のび太くん、線形回帰でFX(為替)を予測するプログラムなんて、20年以上も前からあるものなんだよ。
今回の場合、正解率も60%弱だし。
使えないことはないけど、最近の進歩した機械学習・AI技術を使えばもっと良いものが作れるよ。
たしかに最近、囲碁でAIがプロの方に勝ったニュースとか聞いたよ。
それもFXに使えるの?
もちろんさ。
囲碁のAIはディープラーニングや強化学習をベースにしているよ。
あまりFXに固執して欲しくないけど、ディープラーニングや強化学習は、FXを含め様々な場面で使用できるよ。
でも、AIとか良く分からないや・・・
難しいんでしょ?
大丈夫だよ。
今回みたいに、ひとつずつゆっくり勉強して、実際に実装してみれば、
のび太くんにもマスターできるよ。
僕が書いたAIのまとめ記事があるよ。
昔に一気に書いたから微妙なところもあるけど、まずはこちらをおすすめするよ。

AI関連の記事一覧:【図解:3分で解説】 人工知能・AIの歴史|機械学習、ディープラーニングとは、等
うん、読んでみるよ。
FXはともかく、もっとうまく未来を予測できるプログラムを作ってみたい!!
よし!!その意気だ、のび太くん。
じゃあ次回は、別の機械学習手法を学びながら、FXプログラムをさらに改善していこう!
・
・
・
【完】のび太と学ぶ「機械学習」シーズン1 ~線形回帰~
次回、シーズン2へ続く(のか・・・?)
以上、ご一読いただきありがとうございます。
「ここが分かりにくいよ~不明」など、気軽にコメントください。
可能な限り、加筆修正して、分かりやすくしたいです。
また、記事やコードの間違え、改善点、不明点、感想なども
気軽にコメントいただければ幸いです。