はじめに
近年、人工知能ブームにより、人工知能を使ったトレーディング手法が盛んである。そこで、今回は深層強化学習を用いたシステムトレーディングを実施した。
まず、実際の深層強化学習モデルである。agentの行動として、 BUY、HOLD、SELLの三つの内一つを選択する。環境の戻り値として、状態(今現在保有しているポジションの価格、市場価格、手持ちのキャッシュ)、報酬(手持ちのキャッシュの変化値(含む益も含む))、終了(取引の終了か否か)、情報(ターミナルにディスプレイする情報)を返す。

使用データについて
トレンド傾向の掴みやすさから、yahoo financeからGSPCの日足を使用した。
訓練データの期間:2015/1/1 - 2017/6/30
テストデータの期間:2017/7/1 - 2021/1/1
以下ソースコード
Q学習
Q(s_t,a_t) \leftarrow Q(s_t,a_t) + \eta (R_{t+1} + \gamma \max_a Q(s_{t+1},a_t) -Q(s_t,a_t))
Q学習は価値ベース手法の代表的な例の一つ。Q学習は状況に応じて、agentに報酬を最大化するのにどのような行動を取るのが良いかを教えるシステム。
SARSA
Q(s_t,a_t) \leftarrow Q(s_t,a_t) + \eta (R_{t+1} + \gamma Q(s_{t+1},a_{t+1}) -Q(s_t,a_t))
SARSAは、Q学習において、行動の選択が最大値を取るところを、実際に行う行動を入れる、より方策ベースの行動を取りやすくしいてる。
ε - greedy法
行動の初期に、ランダムな行動をし、報酬の局所的な最大化を防ぐ、方法を ε - greedy 法という。実行回数の増大化に伴い、 ε が減少し、ランダムな行動の回数が減り、その代わり、学習による行動が増える。1
下記図は、条件分岐フロー

また、今回は割引率の違いによる、イプシロンと減少の関係と学習の累積度数を調べた。
r: 割引率、左軸: ε 右軸: 累積度数

以下、ソースコード
価値ベース手法と方策ベース手法
深層強化学習には、大別すると価値ベース、方策ベース、ゲームAIの三つの手法がある。
その中の価値ベース、方策ベースを解説したい。
価値ベース手法
価値観数Qを学習を通じ、最適な行動を目指す。
行動の選択は決定論に準ずる。
※sarsa,Q学習はここに含む。
方策ベース手法
agentの方策の条件付き確率πを学習し、価値観数Qを使わず、最適な行動を目指す。
行動の選択は確率論に準ずる。
売買ルール
1.空売りは認めない
2.ポジションを持っている場合、追加注文を出せない。
3.最後のステップでポジションを全て売却する。
4.ポジションは全買い、全売り
5.所持金は1000000ドル
実装と結果
比較のため、ネガティブコントロールとして、ランダムによる売買を入れた。
以下、共に訓練モードのソースコード
ランダム
Q学習
SARSA
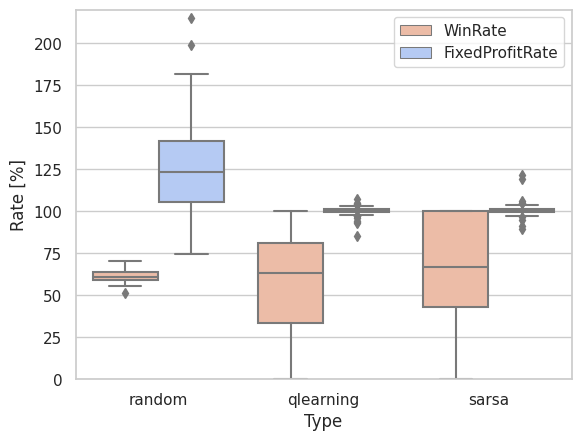
ランダムに対して、Q学習、SARSAともに勝率では勝ち、収益率が負けている。学習がうまくいっていると言える。
ソースコードはこちら
-
Richard S. Sutton and Andrew G. Barto(2015),'Reinforcement Learning: An Introduction',The MIT Press Cambridge, Massachusetts London, England ↩