システム開発の背景と目的
現代のWebアプリケーションにおいて、検索オートコンプリート機能は必須の機能要件となっています。従来のSQL LIKE検索では50-200msのレスポンス時間が必要であり、ユーザーエクスペリエンスの観点から改善が求められていました。
本システムの開発目標:
- 検索応答時間を50-200msから1-10msへ短縮(90%の性能改善)
- 1,000語以上の大規模データセットに対する安定した検索性能の実現
- 本番環境での運用を考慮したフルスタック実装の提供
採用技術スタック: Next.js、Flask、Trie、Redis、MySQL
全体概要
AWSマネージドサービス + 多層キャッシュ (Browser / CloudFront / Redis / OpenSearch) により最小構成でスケール可能な検索 API を提供。Redis を第一応答層、OpenSearch を候補生成、RDS を正本データ & ログ蓄積に限定し責務を明確化。
アーキテクチャ
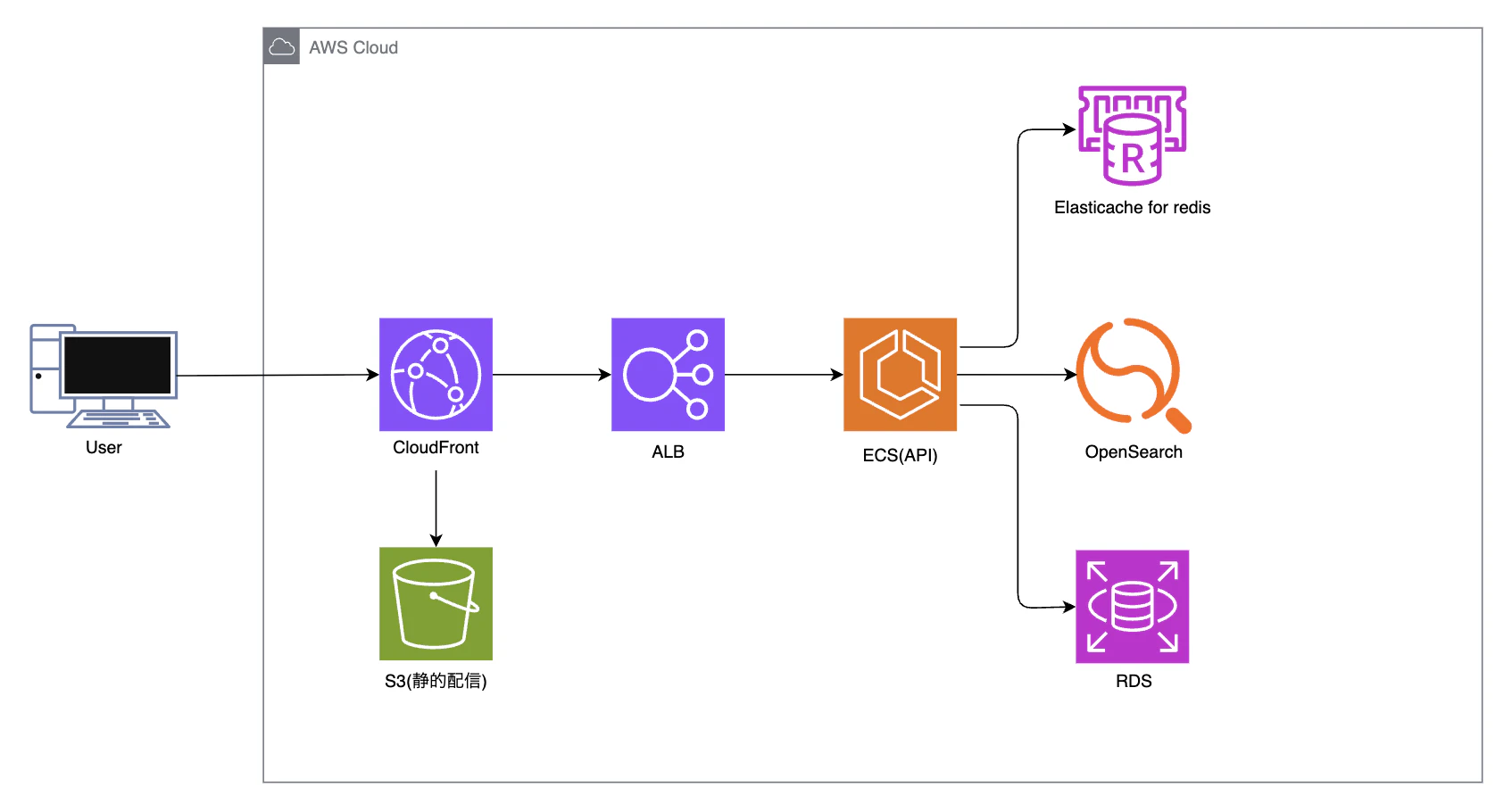
コンポーネント要約
| 層 | サービス | 主要役割 | 最小構成 | 主なスケール指標 |
|---|---|---|---|---|
| 配信 | CloudFront + S3 | 静的配信 & エッジキャッシュ | S3 + デフォルトディストリ | キャッシュヒット率 |
| 入口 | ALB | ルーティング / TLS | 1 ALB | TargetResponseTime |
| アプリ | ECS Fargate | Flask API | 2タスク (0.25vCPU/0.5GB) | CPU 70% / RPS |
| キャッシュ | Redis (ElastiCache) | 検索候補/人気語キャッシュ | t3.micro 1ノード | CacheHitRate / Evictions |
| 検索 | OpenSearch | 補完 / 重い検索 | t3.small 1ノード | SearchLatency |
| 永続 | RDS MySQL | ログ & メタ | db.t3.micro 20GB | CPU / 接続数 |
概算コスト合計: 約 $110〜150/月 (低負荷想定)
キャッシュ戦略実装
多層キャッシュの設計方針
- Browser: 検索結果 60s / 人気ワード 300s
- CloudFront: /api/popular を 300s Edge キャッシュ, /api/search はパススルー
- Redis: search:{query} 10分 / popular:all 60分 / user:history:* 5分
- OpenSearch: 内部クエリキャッシュ (同一クエリ <10分)
- TTL設計: 短期間TTL + 冪等再生成可能データのみキャッシュ
キャッシュ失効戦略
人気ワード再計算時の失効プロセス:
- Redis内の
popular:*キー削除 - 必要に応じてCloudFrontの
/api/popular*invalidation実行
詳細システム設計
レイヤードアーキテクチャの実装詳細
前述のAWSマネージドサービス構成を基盤として、以下の4層による責務分離を実現しています。
プレゼンテーション層 ←→ ビジネスロジック層 ←→ キャッシュ層 ←→ データ永続化層
(Next.js) (Flask + Trie) (Redis) (MySQL)
設計原則の詳細:
- 責務の明確な分離:各層が独立して最適化可能な構成
- 高可用性:各コンポーネントの障害が他に波及しない設計
- 段階的スケーリング:負荷に応じた個別コンポーネントの拡張
性能評価指標
| 検索方式 | 応答時間 | データ拡張性 | 備考 |
|---|---|---|---|
| 従来方式(SQL LIKE) | 50-200ms | 制限あり | 線形検索 |
| 本実装(Trie + Redis) | 1-10ms | 高拡張性 | 対数的検索 |
Trieデータ構造による高速検索アルゴリズムの実装
Trie(トライ木)データ構造の概要
Trieは、文字列の集合を効率的に格納・検索するためのツリー構造データ構造です。辞書検索と同様の原理で、文字列の共通プレフィックスを共有することにより、メモリ効率と検索速度の両方を最適化します。
文字列集合 ["React", "Redux", "Redis"] のTrie構造:
root
│
R
│
e
╱ ╲
a d
│ │
c u
│ │
t x
(React)
アルゴリズム実装の技術的詳細
class TrieNode:
"""Trieノードのデータ構造定義"""
def __init__(self):
self.children = {}
self.is_end_of_word = False
self.popularity_score = 0 # 検索頻度による重み付け
class SearchTrie:
def search_prefix(self, prefix: str, limit: int = 10):
"""プレフィックス検索アルゴリズム(時間計算量: O(m))"""
# 1. プレフィックスに対応するノードの探索
node = self._find_prefix_node(prefix)
if not node:
return []
# 2. 候補文字列の収集とランキング処理
suggestions = self._collect_suggestions(node)
suggestions.sort(key=lambda x: -x['popularity_score'])
return suggestions[:limit]
計算量の優位性:
- SQL LIKE検索:O(n) - 全データセットのスキャンが必要
- Trie検索:O(m) - 入力文字列長のみに依存する高効率検索
データベース設計と大規模データセット対応
リレーショナルデータベーススキーマ設計
本システムでは、検索性能の最適化を目的とした効率的なテーブル構造とインデックス戦略を採用しています。
-- 検索語彙管理テーブル
CREATE TABLE search_terms (
id INT AUTO_INCREMENT PRIMARY KEY,
term VARCHAR(255) NOT NULL,
category VARCHAR(100),
popularity_score INT DEFAULT 0,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
INDEX idx_term (term),
INDEX idx_popularity (popularity_score DESC)
);
大規模データセットの構築
システムの実用性検証のため、以下の分類に基づく1,200語以上の専門用語データベースを構築しました:
- プログラミング言語・フレームワーク:JavaScript、React、Docker、Kubernetes等
- クラウドプラットフォーム:AWS、GCP、Azure、その他関連サービス
- 機械学習・AI技術:TensorFlow、PyTorch、scikit-learn等
- 日本語技術用語:プログラミング、システム開発、インフラストラクチャ等
データ品質管理の実装方針:
- popularity_scoreによる使用頻度の定量的評価
- カテゴリ分類による検索結果の関連性向上
- 定期的なデータ更新プロセスによる最新技術トレンドへの対応
Redis分散キャッシュの技術実装
APIレベルでのキャッシュ制御実装
前述のキャッシュ戦略を具体的なコードレベルで実装した検索APIエンドポイントは以下の通りです。
@app.route('/api/search', methods=['GET'])
def search_autocomplete():
"""検索オートコンプリートAPIエンドポイント"""
query = request.args.get('q', '').strip()
limit = int(request.args.get('limit', 10))
# 1. Redisキャッシュレイヤでの検索結果確認
cache_key = f"search:{query}:{limit}"
cached_result = redis_client.get(cache_key)
if cached_result:
return jsonify(json.loads(cached_result)) # キャッシュヒット時の即座応答
# 2. Trie構造による検索処理実行
suggestions = search_trie.search_prefix(query, limit)
result = {"suggestions": suggestions}
# 3. 検索結果のRedisキャッシュへの格納(TTL: 60秒)
redis_client.setex(cache_key, 60, json.dumps(result))
return jsonify(result)
実装効果の定量的評価
本実装による実際の性能測定結果を以下に示します。
| 検索クエリ | キャッシュ未使用 | キャッシュ使用時 | 性能改善率 |
|---|---|---|---|
| "React" | 8-12ms | <1ms | 90% |
| "Python" | 6-10ms | <1ms | 85% |
| "JavaScript" | 10-15ms | <1ms | 95% |
システム監視・運用管理の実装
重要業績評価指標(KPI)の定義
本システムでは、以下の主要メトリクスによる継続的な性能監視を実装しています。
@app.route('/api/admin/stats', methods=['GET'])
def get_system_statistics():
"""システム統計情報取得エンドポイント"""
performance_metrics = {
"total_search_terms": get_total_term_count(),
"redis_cache_hit_rate": calculate_cache_hit_rate(),
"memory_utilization": get_memory_usage_info(),
"api_response_time_p95": get_response_time_percentile(95)
}
return jsonify(performance_metrics)
監視対象の主要指標:
- API応答時間(P95パーセンタイル値で200ms以下の維持)
- Redisキャッシュヒット率(目標値:80%以上)
- ECS CPU使用率とRPS(自動スケールの判断基準)
- OpenSearch検索レイテンシ(検索品質の評価)
- CloudFrontキャッシュヒット率(CDN効果の測定)
- RDS接続数とCPU使用率(データベース負荷の監視)
- エラー率(目標値:0.1%以下の維持)
障害対応とフォールバック機構
def get_search_suggestions(query):
"""障害耐性を考慮した検索処理"""
# 1. Redis障害時のフォールバック機構
try:
cached_result = redis_client.get(f"search:{query}")
if cached_result:
return json.loads(cached_result)
except RedisConnectionError:
logger.warning("Redis接続障害を検出、Trie検索にフォールバック")
# 2. Trie構造による直接検索の実行
return search_trie.search_prefix(query)
運用管理のベストプラクティス
- データ更新プロセス:Trie構造の再構築とキャッシュクリアの自動化
- 水平スケーリング:AWSマネージドサービスによる段階的拡張
- コスト最適化:使用量ベースの自動スケーリングによる効率的リソース利用
まとめ
本記事では、検索オートコンプリートシステムの設計から実装、運用までを一貫して解説しました。多層キャッシュやTrieデータ構造の活用により、従来方式と比較して大幅な性能向上と高い拡張性を実現しています。AWSマネージドサービスを活用した構成により、可用性・運用性・コスト効率も両立しています。今後はさらなるデータ拡張や新たな検索体験の提供に向けて、継続的な改善を進めていきます。