yolov9で物体検出(静止画、動画、自作データ)を追加しました(2024/06/28)
Windows で GoogleColab を使うやり方になってます
yoloで物体検出ができることを知り、yolov5を使って静止画、動画、リアルタイム、自作データ等で物体検知をやってみた
※素人のため詳しい説明は別のサイトでご確認ください。
参考にしたサイトはこちらです
GoogleColabではなく、Localにインストールしています。
ubuntu20.04にAnacondaの仮想環境を作って検出しました。
ここでは
- 仮想環境を作る
- yolov5をインストール
- gitで用意されてる検知内容や画像ですぐ物体検知してみる
- 自分が持ってる画像や動画をいれて物体検知してみる
- 検知する内容を好きな項目で作成して画像を検知してみる
- リアルタイムで物体検知してみる
の順番で記載しています
1.仮想環境を作る
仮想環境を構築するためにAnacondaをいれます
(いろんなものがインストールされるので仮想環境を作り、まとめて入れた方が良いらしいので・・。)
Anacondaのダウンロード
- 上記サイトにアクセスし、一番下にスクロールしダウンロードしたいインストーラーを選択します。
(私はLinuxの64-Bit (x86) Installer (659 MB)をダウンロードしました。)
ファイルはDownloadsフォルダに保存されます。
Anacondaのインストール
ダウンロードしたインストールファイルを実行します
Downloadsフォルダにディレクトリを移動します。
アプリ一覧よりターミナルを開いて入力してください
cd Downloads
実行します
bash Anaconda3-2022.05-Linux-x86_64.sh
Please,press ENTER to continue
>>>
と表示されたらENTERキー
--more--
ENTERキーを押し続ける
Do you accept the license terms?[yes|no]
[no]>>>
yes
[/home/あなたのPCの名前/anaconda3]>>>
と表示されたら保存場所を指定できます。
特に指定がなければENTERキー
by running conda init?[yes|no]
[no]>>>
yes
これでインストールできました。
仮想環境の作成
yolov5という名前の仮想環境をhomeディレクトリ直下に作成したいと思います
Anaconda3をインストールするとターミナル画面の先頭(左端)に(base)が表示されます。
※表示されていない場合は、一度ターミナルを閉じて、再度開いてみてください。
仮想環境作成と同時にpythonも仮想環境内に入れます
conda create -n yolov5 python=3.9
Proceed([y]/n)?
yを入力しENTER
作成した仮想環境に入ります
conda activate yolov5
先頭に(yolov5)が表示されていればOKです
2.yolov5をインストール
homeの直下にyolov5を作成したいのでディレクトリの階層を1つ戻り、
githubよりyolov5をダウンロードします
cd ..
git clone https://github.com/ultralytics/yolov5
homeの直下にyolov5フォルダが作成されます。
(お試し検出用のサンプル画像ファイルなどが入っています。)
yolov5実行に必要なものをインストールします
cd yolov5
pip install -r requirements.txt
3.物体検知
gitで用意されてる検知内容やサンプル画像ですぐ物体検知してみる
ダウンロードしたyolov5フォルダに入っているサンプル画像(bus.jpg zidane.jpg)で物体検知
python detect.py --source data/images/ --conf 0.5 --weights yolov5s.pt
--source → 画像の場所(複数ファイルがあったのでフォルダを指定しましたが、ファイル名でもOK)
--conf → 指定した数字以上の確立のものを表示(数字が低ければ、低い確率のものまで表示されます)
--weights → 学習済モデルの重みファイルを指定(検出精度n→x 精度:低→高 速度:速→遅 )
yolov5n.pt
yolov5s.pt
yolov5m.pt
yolov5l.pt
yolov5x.pt
結果はyolov5/runs/detect/exp に保存されます。
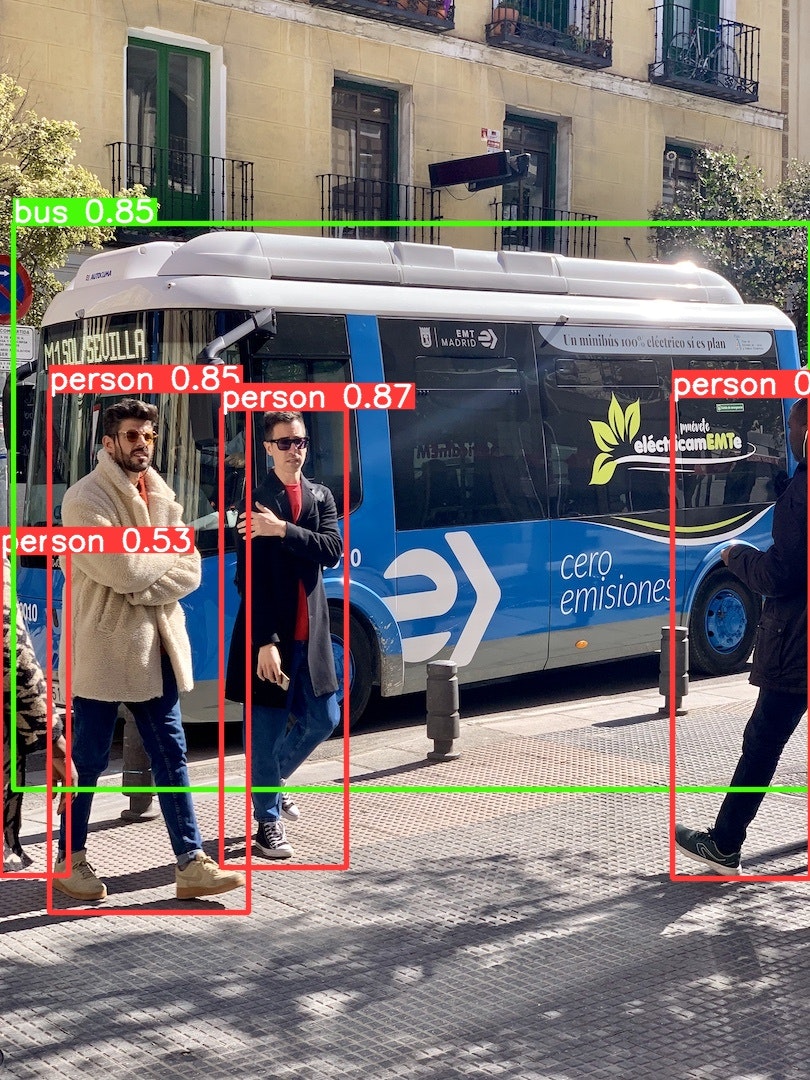 |
 |
|---|
person、tie、bus などが検出されています。
これらの項目は既に学習済みのため、検出が可能になっています。
学習済の項目は以下になります(80項目)
'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard', 'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone', 'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush'
4.自分が持ってる画像や動画をいれて物体検知してみる
自分のPCにある.jpgや.png、.mp4のファイルを学習済みの80項目で検出してみます
画像を用意し、home/yolov5/data/images/の中に入れます。
物体検出します
python detect.py --source data/images/あなたが入れたファイル名.jpg --conf 0.5 --weights yolov5s.pt
結果はyolov5/runs/detect/exp2 に保存されます。(expの後ろは連番になります)
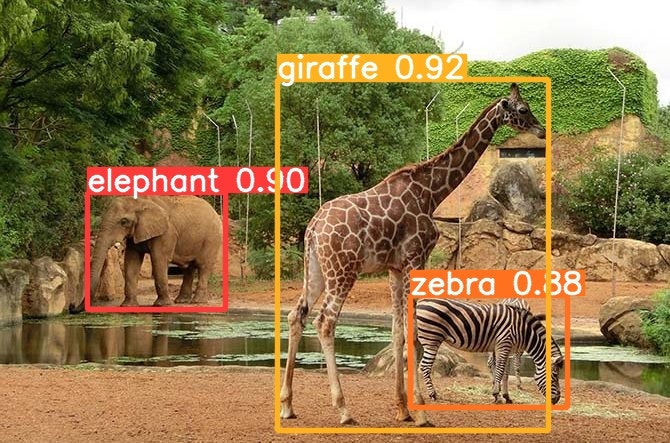
動画を入れた場合はこちら
python detect.py --source data/images/あなたが入れたファイル名.mp4 --conf 0.5 --weights yolov5l.pt
5.検知する内容を好きな項目で作成して画像を検知してみる
自分の好きな項目で検知するには、アノテーション(ラベル付け)と学習をさせることが必要です
アノテーション(ラベル付け)
アノテーションツールとしてlabelImgをインストールします。
pip install labelImg
labelImgを起動します
labelImg
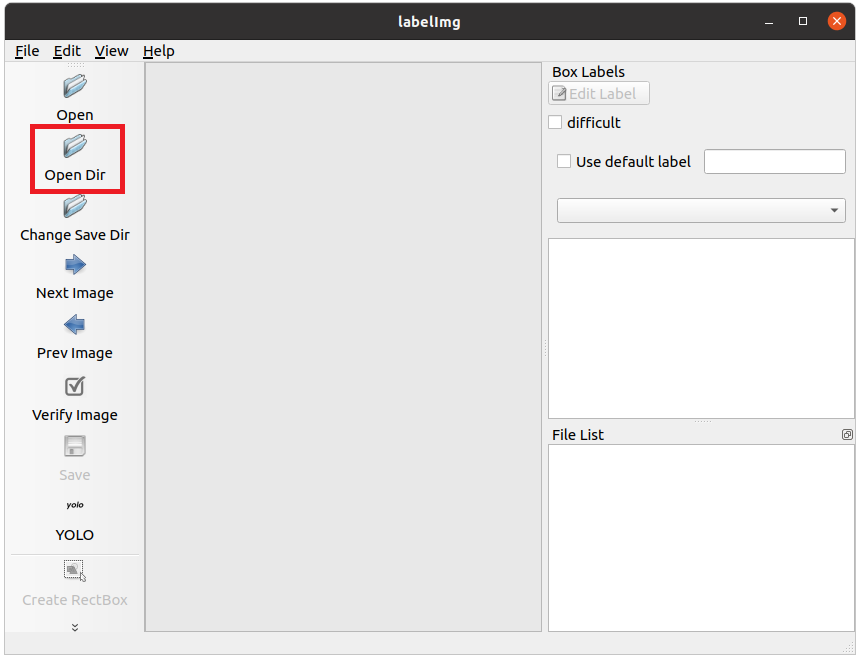
起動したら、Open Dirより画像が入っているフォルダを選択します。(ファイルの場合はOpenで)
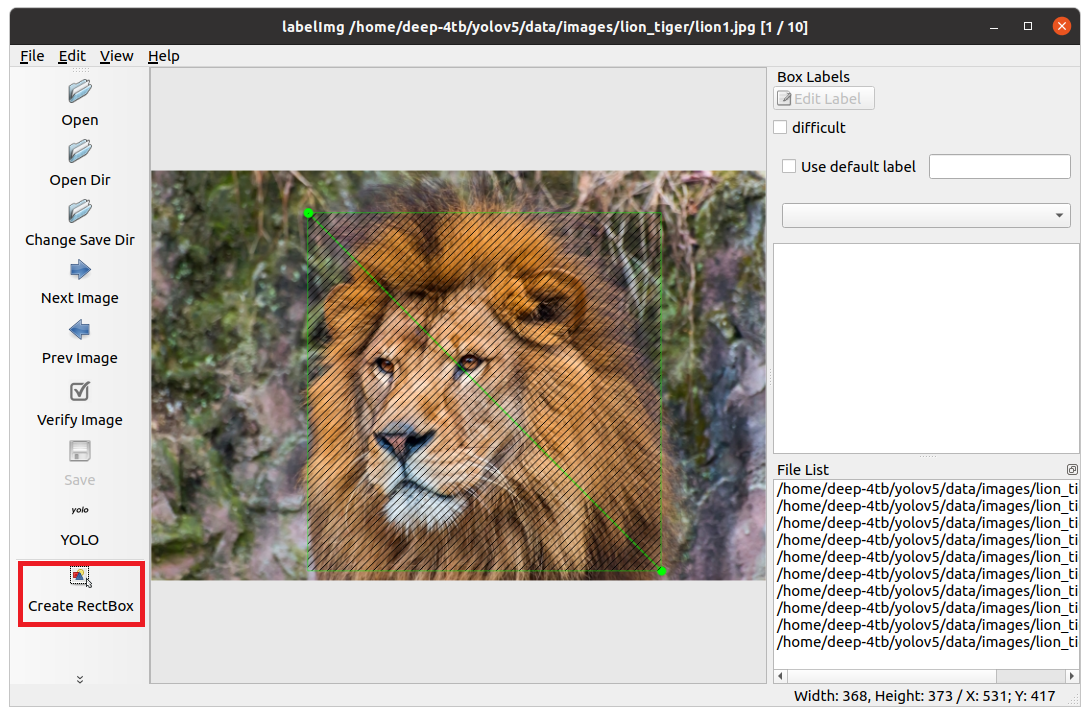
画像が表示されたらCreate RectBoxをクリックし、ラベルをつけたい部分を四角く囲みます。
ラベルの名前を入力しOKをクリック
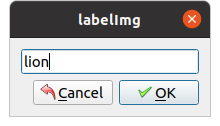
保存の形式を選択します。
YOLO形式で保存しますので、YOLOを選択し、SAVEボタンで保存します。
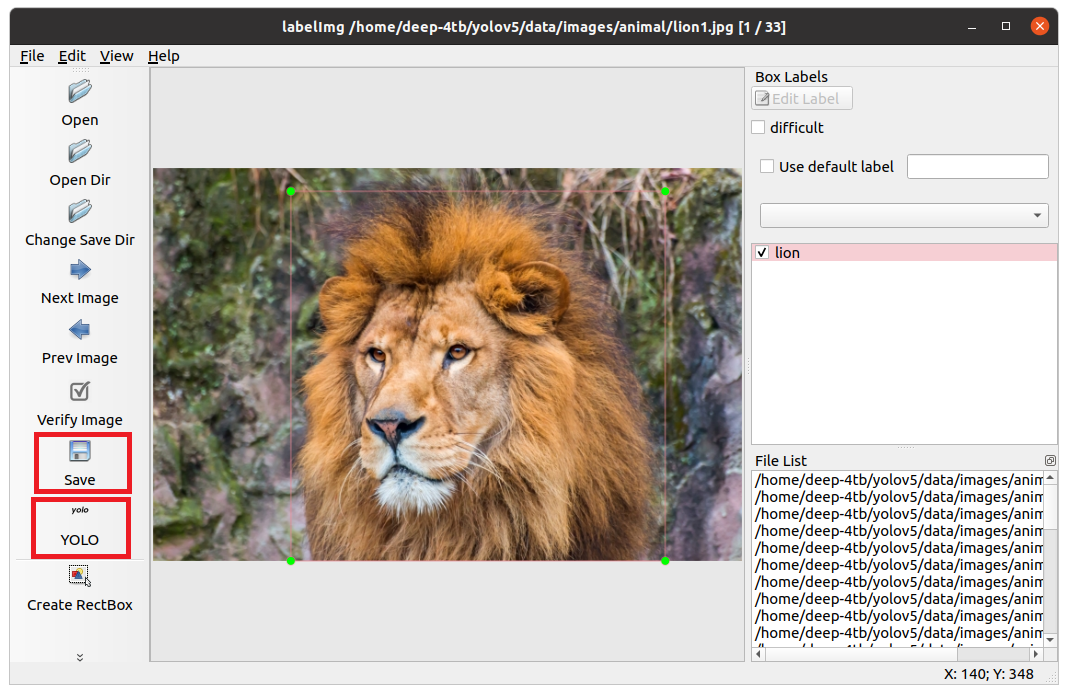
同じ名前でYOLO形式で保存してください。
保存が完了すると、フォルダ内に画像と同じ名前の.txtファイルが保存されています。
この.txtにはラベリングの座標が書かれています。
また、Classes.txtというファイルができますが、ここにはラベルの名前が入力されています。
Next Imageをクリックして、他の画像も同様にラベリングをします。
トレーニング
すべての画像にラベルを付けることができたらyolov5に学習させるためにラベルデータを移します
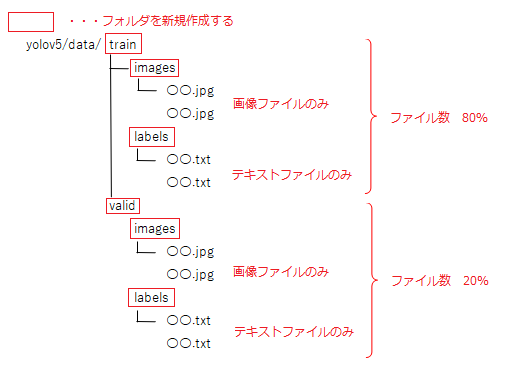
ラベルを付けたファイルを8:2の割合にわけます
trainフォルダ・・・学習用のデータを入れる 8割
validフォルダ・・・検証用のデータを入れる 2割
※trainフォルダ:labelsフォルダ は 8:2 の割合くらいでいれると良いそうです。
また、それぞれのフォルダ内で画像データとテキストデータに分けて入れます。
以下の図を参照
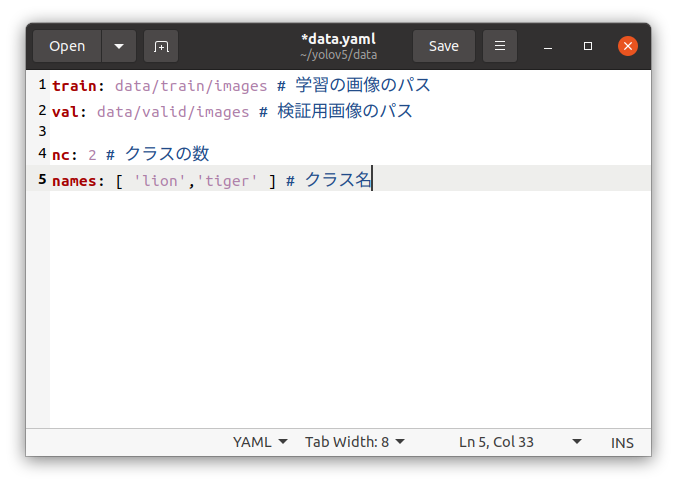
学習に必要な項目を記述した.yamlファイルを作成します。
テキストエディタを開き、
train:学習用の画像フォルダの場所
val: 検証用の画像フォルダの場所
nc : ラベルの項目数
names: ラベルの名前
を入力し、yolov5/data/ の中に data.yaml の名前で保存します。
学習させるのでtrain.pyを実行します。
python train.py --data data/data.yaml --weights yolov5s.pt --epochs 200
--data ← .yamlの場所
--weigths ← 学習の精度
--epochs ← 学習を繰り返す回数(指定しなければ300)
学習が終わると結果がruns/train/exp/に保存されます。
保存された自作の学習済データruns/train/exp/weights/best.ptを使って物体検知をします
yorov5/data/imagesに検知したい画像ファイルを入れましょう
物体検知(detect.py)を実行します
python detect.py --source data/images/〇〇.jpg --weights runs/train/exp/weights/best.pt
--source ← 物体検知をしたい画像ファイル
--weights ← 自作の学習済データ
自分の作った名前でラベリングされています

リアルタイムで物体検知してみる
カメラの映像を通してリアルタイムに物体検知をしてみます
学習データはダウンロードしたyolov5に入っている80項目のデータ内容を使ってみます。
webカメラを接続
内臓されてるPCはそのままでOK、映るか確認してみてください
私はなかったので、webカメラを取り付け、カメラアプリ(cheese)で確認しました。
リアルタイム検知実行
※カメラアプリは閉じておいてから実行しないとエラーになります!
python detect.py --source 0 --weights yolov5m.pt
--source 0 ←webカメラの場合
実行すると、カメラアプリが起動して映った映像に対して次々に物体検知します。
・自分のデータで学習させるには100枚以上のいろんな画像があるとうまく検出されるようです。
(ちなみに私は35枚の画像で学習しましたのであやしいところもありました・・・)
・Anacondaではなくminicondaでも十分動きました。
・初めはgoogleColabでやってましたが、リアルタイムはLocalでないと出来ないため、切り替えました。