ここではyolov9を使い、静止画、動画、自作データの物体検出方法を記述しています。
windows11 で Google Colab を利用しました。(初心者向け)
(リアルタイム検出はGoogle Colabではできないです)
物体検出イメージ
こんな感じの物体認識を自分のPCで簡単にやってみたい

動画も
Google ColabでYolov9を体験してみる
普段使っているWindowsのPCでGoogle Colabを使いました。
(めちゃくちゃ初心者向けです)
Google Colabを開く
(Google Colabを使用したことがある方は読み飛ばしてください)
Google Colabを使用したことがない方は順番に操作してください。
-
google colab と検索すると

-
google colaboratory を選択し、
ノートブックを新規作成をクリックする
新規にノートブックが開き、カーソルの位置にプログラムを入力していきます。 -
GPUで処理をすると早いので、まずはランタイムのタイプを変更します。
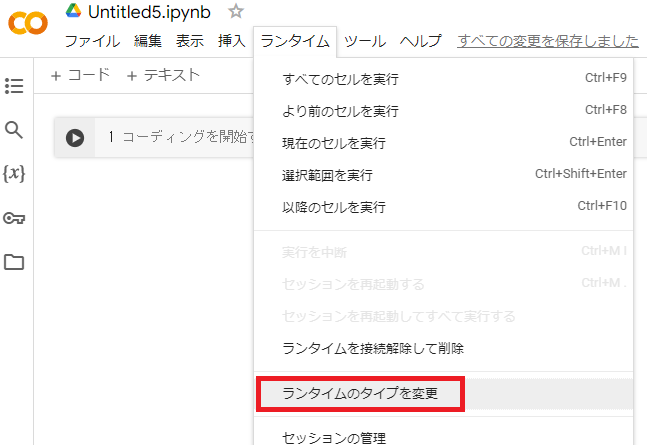
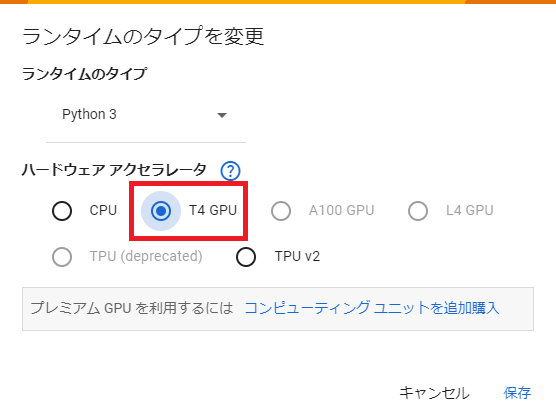
ドライブをマウントする
ご自分のgoogledriveにデータをダウンロードするため、アクセスできるようにしておきます。
カーソルの位置に以下を入力します。
from google.colab import drive
drive.mount('/content/drive')
%cd ./drive/MyDrive
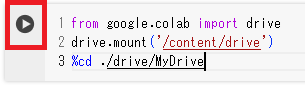
入力したプログラムを実行するには実行ボタンをクリックします
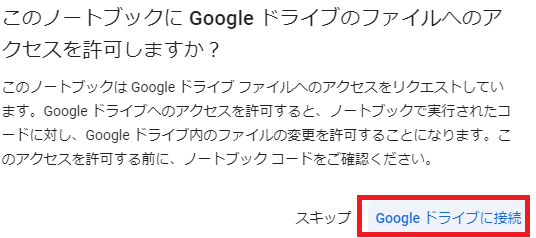
アクセスを許可するのでgoogleドライブに接続をクリック
・使用するGoogleアカウントを選択します。
・Google Drive for desktopにログインするので次へをクリック
・追加アクセスを求めていますと表示されたら続行をクリック
googleドライブ上のMyDriveがマウントされます。
・フォルダアイコンをクリックするとMyDriveフォルダを確認できます。


次のプログラムを入力するので+コードをクリックします。
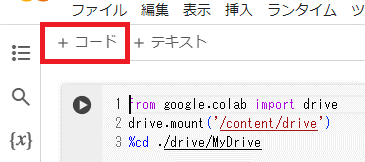
yolov9をダウンロード
先ほどマウントしたMyDriveにyolov9をダウンロードして、
yolov9フォルダにディレクトリを移動します。
!git clone https://github.com/WongKinYiu/yolov9
%cd yolov9
※yolov9のフォルダができてますので確認してみてください。
+コードをクリックして入力画面を追加してください。
weightsフォルダを作成し、学習済みのモデルをダウンロードします。
!mkdir -p weights
!wget -P weights -q https://github.com/WongKinYiu/yolov9/releases/download/v0.1/yolov9-c.pt
!wget -P weights -q https://github.com/WongKinYiu/yolov9/releases/download/v0.1/yolov9-e.pt
!wget -P weights -q https://github.com/WongKinYiu/yolov9/releases/download/v0.1/gelan-c.pt
!wget -P weights -q https://github.com/WongKinYiu/yolov9/releases/download/v0.1/gelan-e.pt
検出
yolov9/data/images/フォルダにサンプル画像 horses.jpg があります。
これを使って検出してみます。
!python detect.py --weights weights/yolov9-c.pt --conf 0.1 --source data/images/horses.jpg --device 0
次のようなエラーが出ると思いますが、yolov9/utils/general.py を開いて 903 行を prediction = prediction[0][1]`に変更してください。
どうやらweightsにyolov9-c.ptまたはyolov9-e.ptを使用した場合はうまくいかないので変更するようです。

うまくいくと、結果がruns/detect/exp・・・ に保存されます。

好きな画像を入れて検出してみましょう
先ほどのサンプル画像 horse.jpgと同じ場所、yolov9/data/images/ フォルダ内に 好きな画像ファイルを入れて、実行します。
!python detect.py --weights weights/yolov9-c.pt --conf 0.1 --source data/images/入れたファイル名.jpg --device 0
ex.

ここで検出される項目は学習済モデルをもとにしています。(以下参考)

動画で確認してみましょう
好きな動画を yolov9/data/images/ フォルダ内に入れて実行してみてください。
!python detect.py --weights weights/yolov9-c.pt --conf 0.1 --source data/images/入れたファイル名.mp4 --device 0
自作データを使って検出
「学習済モデルの中に検出したい項目がない」時や「自作の画像」は学習をさせるところから行います。
ex.項目にlionやtigerがないため不正確 → 新たに学習させて正確に検出


データの準備
まずは、学習させたいデータ(jpgなどの画像)を準備します。(私はお試しでlion25枚tiger25枚用意しました)
ラベルをつける(アノテーション)
画像認識させるためには「どの部分」を「どんな名前」で認識させるかを登録します。
ラベル付けをするソフトはいろいろありますが、私は labelImg を使いました。
- pythonが必要なので pythonのインストール をします
- windowsマークより[コマンドプロンプト」または「windows powershell]を起動
- コマンドプロンプトの場合は次に
pythonと入力し実行する - labelImgのインストール
pip install labelImgと入力し実行する - labelImgの起動
labelImgと入力し実行する
アノテーションのやり方は 「yolov5で物体検出(静止画、動画、自作データ、リアルタイム)」のアノテーション(ラベル付け)をご覧ください。
もし、labelImg操作中で、落ちることがあればこちらを参考にしてください。(私は落ちました)
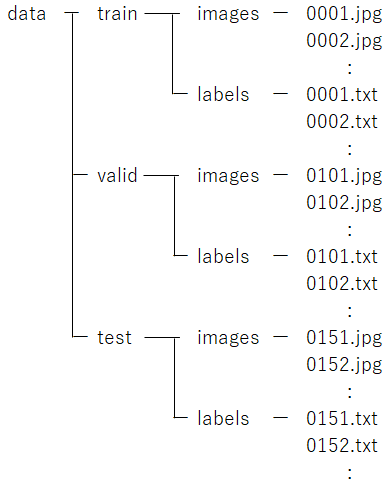
自作データの保存
こんな感じのフォルダを作成し、ラベル付けしたjpgとtxtファイルを保存しておきます。
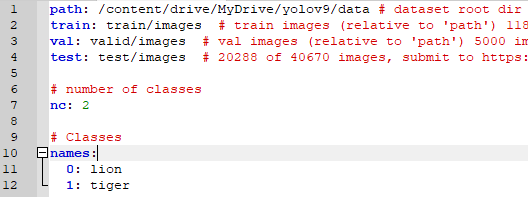
data.yamlの作成
学習に必要な項目を記述したdata.yamlファイルを作成します。
ex. lionとtigerのラベリングをした場合
新規作成するので、テキストエディタを開き、
path: データセットの場所
train: 学習用の画像フォルダの場所(path:からの相対)
valid: 検証用の画像フォルダの場所(path:からの相対)
test: テスト用の画像フォルダの場所(path:からの相対)
nc : ラベルの項目数
names: ラベルの名前
を入力し、yolov9/data/ の中に data.yaml の名前で保存します。
学習を実行する
少ない学習回数 epochs 25 くらいでやってみる
!python train.py \
--batch 16 --epochs 25 --img 640 --device 0 --min-items 0 --close-mosaic 15 \
--data /content/drive/MyDrive/yolov9/data/data.yaml \
--weights /content/drive/MyDrive/yolov9/weights/gelan-c.pt \
--cfg models/detect/gelan-c.yaml \
--hyp hyp.scratch-high.yaml
学習結果はruns/train/exp に保存されます。
学習した結果をもとに物体検出してみる
weightsを学習したファイルに変えます。(runs/train/exp/weights/best.pt)
weightsをyolov9-c.ptから変更した場合はyolov9/utils/general.py を開いて 903 行をprediction = prediction[0]に戻してください。
以下を実行します
!python detect.py --weights runs/train/exp/weights/best.pt --conf 0.1 --source data/images/物体検出したいファイル.jpg --device 0
結果は runs/detect/exp・・・ です。