はじめに
前回の記事 では、Amazon Neptune を構築して SPARQL でクエリーをしてみました。今回の記事では、インターネットに公開されている RDF データを Neptune クラスタにインポートする手順を確認していきましょう。
Amazon Neptune には Loader コマンドが用意されており、S3 Bucket に格納されたデータを Neptune にインポートできます。概要図はこんな感じです。
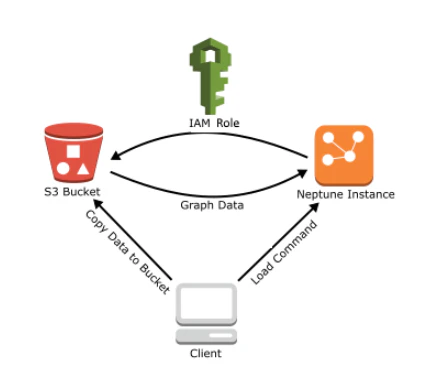
URL : https://docs.aws.amazon.com/ja_jp/neptune/latest/userguide/bulk-load.html
対応しているファイルは、次の4つの形式です。
- N -Triples (
ntriples) from the specification at https://www.w3.org/TR/n-triples/ - N-Quads (
nquads) from the specification at https://www.w3.org/TR/n-quads/ - RDF/XML (
rdfxml) from the specification at https://www.w3.org/TR/rdf-syntax-grammar/ - Turtle (
turtle) from the specification at https://www.w3.org/TR/turtle/
また、エンコードは UTF8 となっていることが必要です。詳細は次の Document に書かれています。
URL : https://docs.aws.amazon.com/ja_jp/neptune/latest/userguide/bulk-load-tutorial-format-rdf.html
それでは、データのインポートしていきましょう。
RDF ファイルをダウンロードして S3 に格納
次の URL で公開されている RDF データセットをダウンロードします。
curl -O http://rdf.geospecies.org/geospecies.rdf.gz
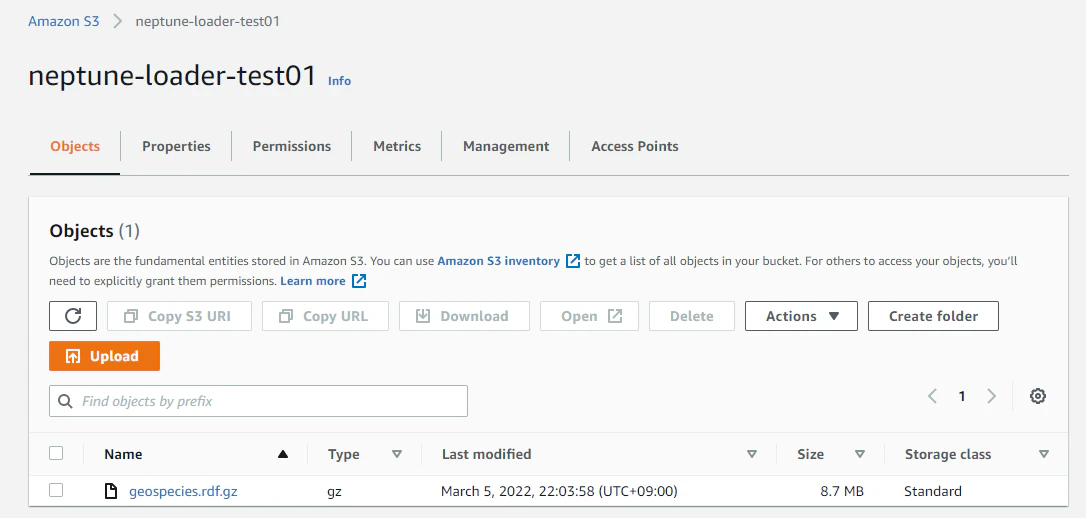
S3 Bucket を適当に作成して、ダウンロードしてきたファイルを格納しました。
IAM Role の作成
Neptune が S3 にアクセスするための IAM Role を作成していきます。Create Role を押します。
Custom Trust Policy を選択して、ポリシーに次の文字列を入れます
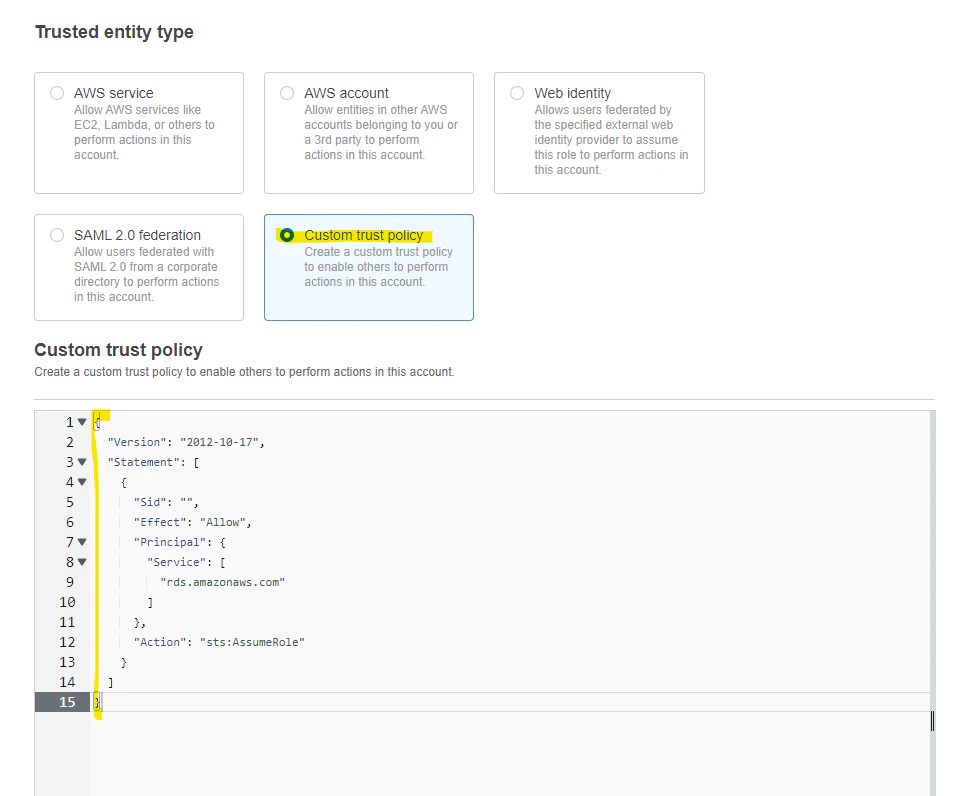
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "",
"Effect": "Allow",
"Principal": {
"Service": [
"rds.amazonaws.com"
]
},
"Action": "sts:AssumeRole"
}
]
}
AmazonS3ReadOnlyAccess を選択して Next を押します
Role 名などを入力します
Create を押します
作成されました
Neptune に IAM Role を紐づける
Neptune クラスタを選択して、Manage IAM roles を選択します。
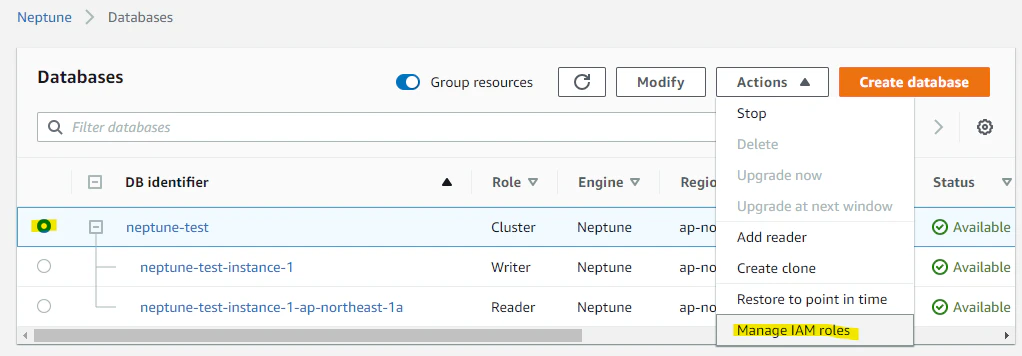
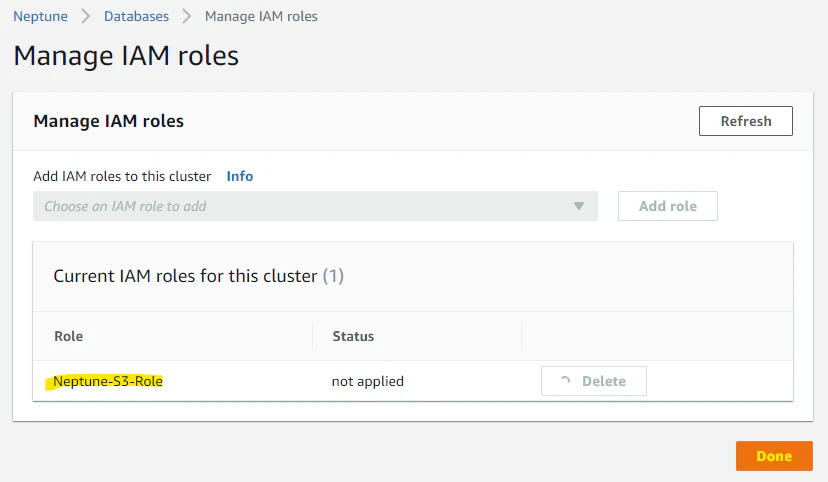
作成した IAM Role を選択して、Done を押します。
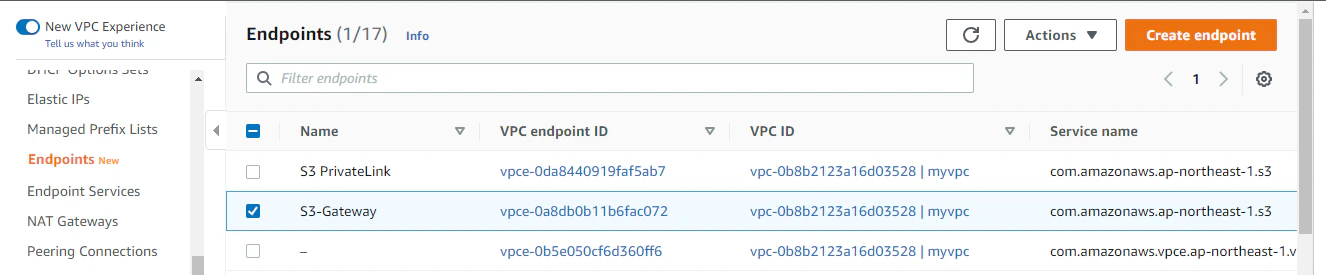
S3 Endpoint(Gateway型) を作成
Neptune が S3 にアクセスするために、S3 Endpoint Gateway が必要です。記事の環境では既に設定済みなので、詳細な手順は省略します。
設定する内容
- VPC Endpoint の S3 用のものを作成
- Route Table に反映
Neptune に Loader でインポートする
S3 Bucket にアップロードした RDF データセットを、インポートしていきましょう。Neptune クラスタと同じ VPC に居る EC2 インスタンスで、以下のコマンドを実行します。
curl -X POST \
-H 'Content-Type: application/json' \
https://neptune-test.cluster-chuxmuzmrpgx.ap-northeast-1.neptune.amazonaws.com:8182/loader -d '
{
"source" : "s3://neptune-loader-test01/geospecies.rdf.gz",
"format" : "rdfxml",
"iamRoleArn" : "arn:aws:iam::xxxxxxxxxxxx:role/Neptune-S3-Role",
"region" : "ap-northeast-1",
"failOnError" : "FALSE",
"parallelism" : "HIGH"
}'
実行例
- Status : 200 がレスポンスとして帰ってくる
{
"status" : "200 OK",
"payload" : {
"loadId" : "2943d79e-dfba-4aa4-8ab7-4c2e21029234"
}
}
進行状況の確認
curl -G 'https://neptune-test.cluster-chuxmuzmrpgx.ap-northeast-1.neptune.amazonaws.com:8182/loader/2943d79e-dfba-4aa4-8ab7-4c2e21029234'
実行例 : ロード中の状態です。status が LOAD_IN_PROGRESSとなっています
{
"status" : "200 OK",
"payload" : {
"feedCount" : [
{
"LOAD_IN_PROGRESS" : 1
}
],
"overallStatus" : {
"fullUri" : "s3://neptune-loader-test01/geospecies.rdf.gz",
"runNumber" : 1,
"retryNumber" : 0,
"status" : "LOAD_IN_PROGRESS",
"totalTimeSpent" : 130,
"startTime" : 1646489330,
"totalRecords" : 1350000,
"totalDuplicates" : 0,
"parsingErrors" : 0,
"datatypeMismatchErrors" : 0,
"insertErrors" : 0
}
}
}
ロード完了の状態です。status が LOAD_COMPLETED となっています
{
"status" : "200 OK",
"payload" : {
"feedCount" : [
{
"LOAD_COMPLETED" : 1
}
],
"overallStatus" : {
"fullUri" : "s3://neptune-loader-test01/geospecies.rdf.gz",
"runNumber" : 1,
"retryNumber" : 0,
"status" : "LOAD_COMPLETED",
"totalTimeSpent" : 199,
"startTime" : 1646489330,
"totalRecords" : 2201532,
"totalDuplicates" : 0,
"parsingErrors" : 0,
"datatypeMismatchErrors" : 0,
"insertErrors" : 0
}
}
}
Neptune Workbench でクエリー確認
前回の手順で作成した Jupyter Notebook にある Neptune Workbench で SPARQL クエリーでインポートしたデータを確認しましょう。
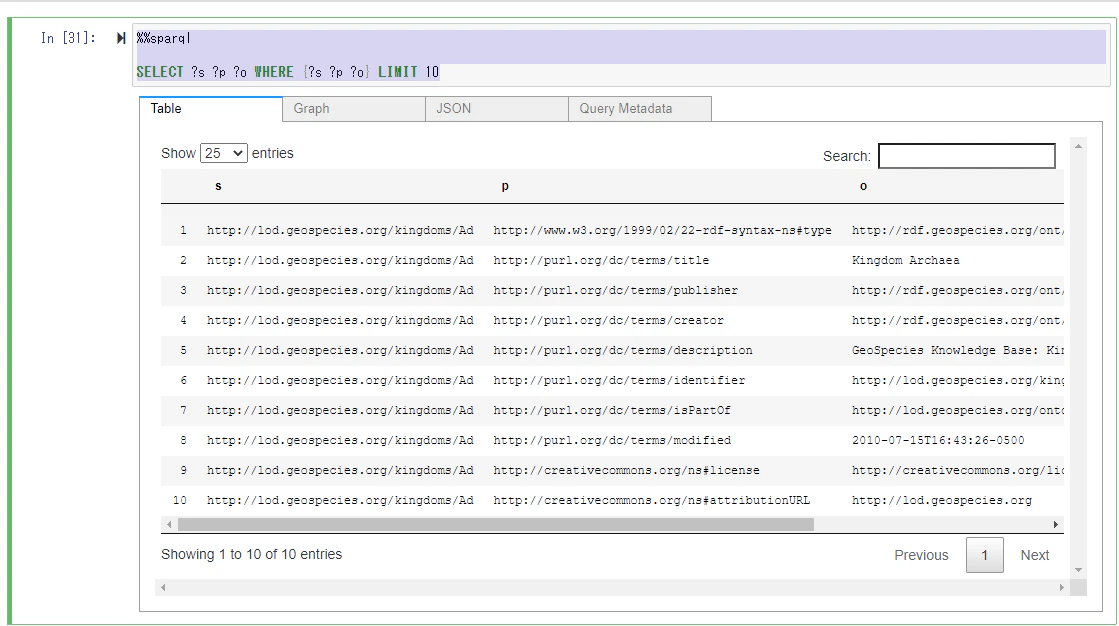
以下のコマンドを実行して、すべてのデータの中から 10 件取得します。
%%sparql
SELECT ?s ?p ?o WHERE {?s ?p ?o} LIMIT 10
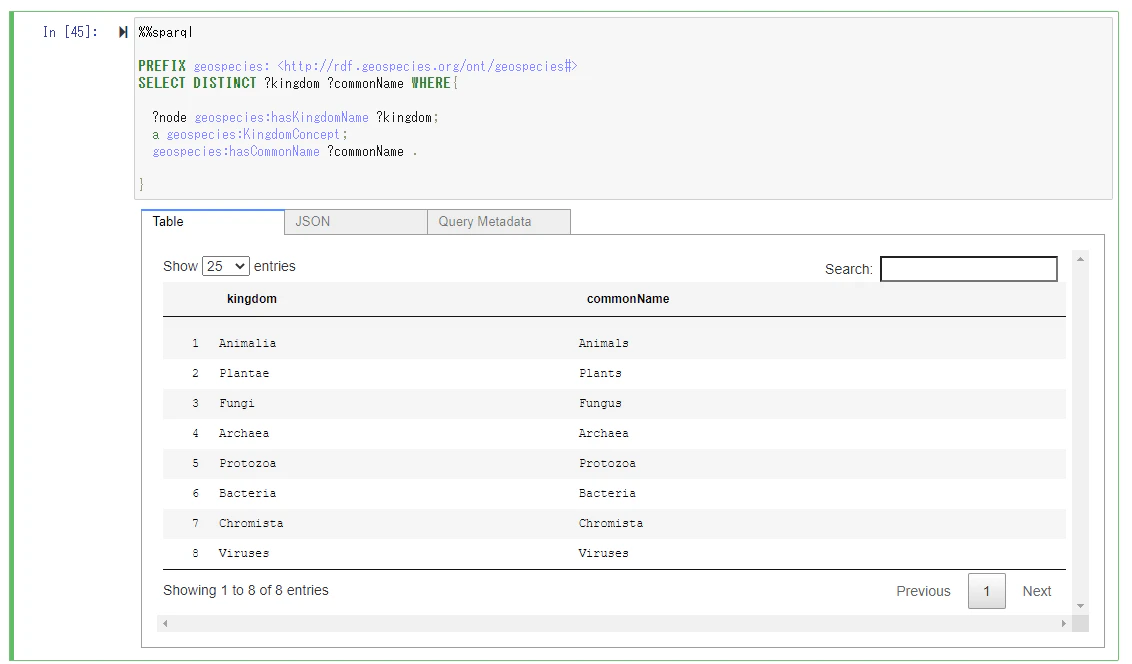
次に以下のクエリーを実行します。(このクエリーの意味が何を指しているのか、調べきれませんでした・・・すいません、時間があれば調べたいと思います)
%%sparql
PREFIX geospecies: <http://rdf.geospecies.org/ont/geospecies#>
SELECT DISTINCT ?kingdom ?commonName WHERE{
?node geospecies:hasKingdomName ?kingdom;
a geospecies:KingdomConcept;
geospecies:hasCommonName ?commonName .
}
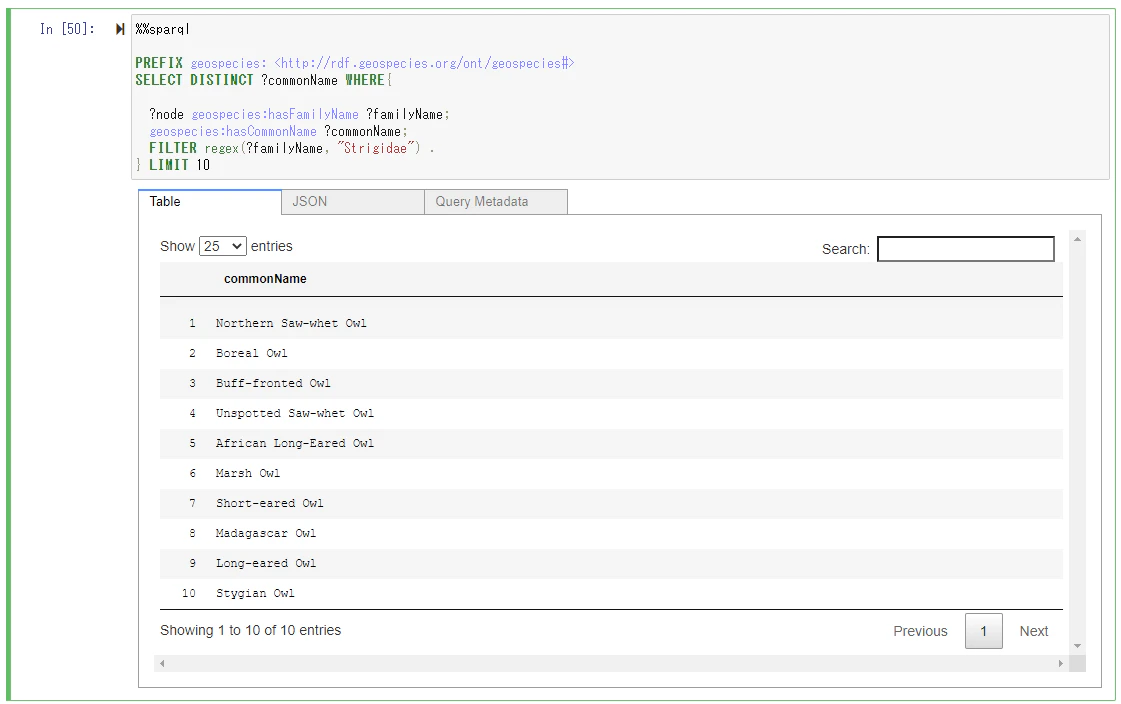
同様に次のクエリーを実行します
%%sparql
PREFIX geospecies: <http://rdf.geospecies.org/ont/geospecies#>
SELECT DISTINCT ?commonName WHERE{
?node geospecies:hasFamilyName ?familyName;
geospecies:hasCommonName ?commonName;
FILTER regex(?familyName, "Strigidae") .
} LIMIT 10
参考URL