はじめに
AWS Glue の Visual ETL 機能を使用すると、コードをほとんど書かずにデータ連携パイプラインを構築できます。本記事では、Snowflake から Amazon Redshift Serverless へのデータ連携を Visual ETL で実装する方法を紹介します。
Snowflake の検証は、クレジットカード登録不要の無料トライアル (30日間) を活用しています。
Snowflake の Free Trial アカウント作成
Snowflake の Free Trial アカウントを作成します。Enterprise Edition を選択します。

すると、すぐに Snowflake にログインができました。
Projects - Worksheets から適当なサンプルデータを Snowflake に入れます。
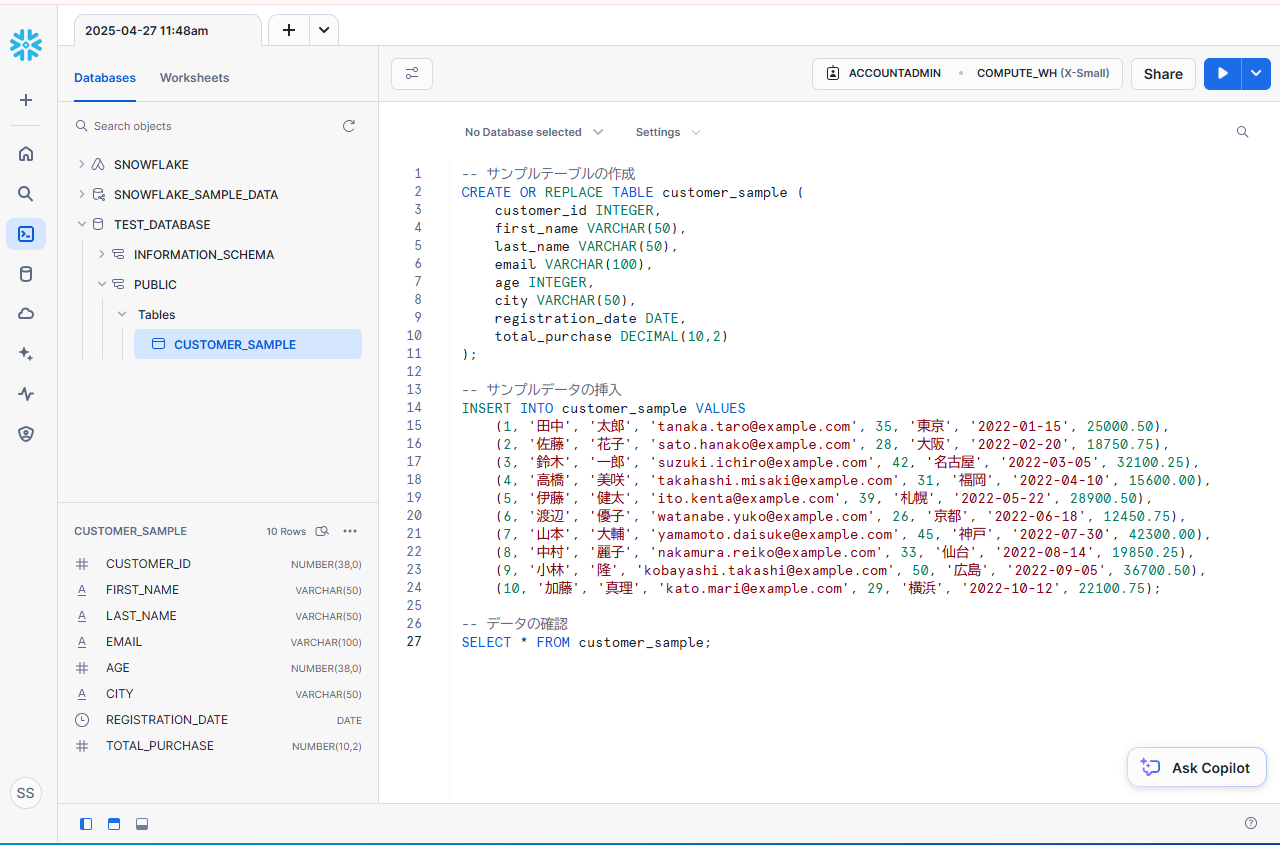
データを入れる : TEST_DATABASE
-- サンプルテーブルの作成
CREATE OR REPLACE TABLE customer_sample (
customer_id INTEGER,
first_name VARCHAR(50),
last_name VARCHAR(50),
email VARCHAR(100),
age INTEGER,
city VARCHAR(50),
registration_date DATE,
total_purchase DECIMAL(10,2)
);
-- サンプルデータの挿入
INSERT INTO customer_sample VALUES
(1, '田中', '太郎', 'tanaka.taro@example.com', 35, '東京', '2022-01-15', 25000.50),
(2, '佐藤', '花子', 'sato.hanako@example.com', 28, '大阪', '2022-02-20', 18750.75),
(3, '鈴木', '一郎', 'suzuki.ichiro@example.com', 42, '名古屋', '2022-03-05', 32100.25),
(4, '高橋', '美咲', 'takahashi.misaki@example.com', 31, '福岡', '2022-04-10', 15600.00),
(5, '伊藤', '健太', 'ito.kenta@example.com', 39, '札幌', '2022-05-22', 28900.50),
(6, '渡辺', '優子', 'watanabe.yuko@example.com', 26, '京都', '2022-06-18', 12450.75),
(7, '山本', '大輔', 'yamamoto.daisuke@example.com', 45, '神戸', '2022-07-30', 42300.00),
(8, '中村', '麗子', 'nakamura.reiko@example.com', 33, '仙台', '2022-08-14', 19850.25),
(9, '小林', '隆', 'kobayashi.takashi@example.com', 50, '広島', '2022-09-05', 36700.50),
(10, '加藤', '真理', 'kato.mari@example.com', 29, '横浜', '2022-10-12', 22100.75);
-- データの確認
SELECT * FROM customer_sample;
Redshift Serverless
Redshift Serverless を適当に作成したあと、Query editor を開いて、テーブルを作成します。
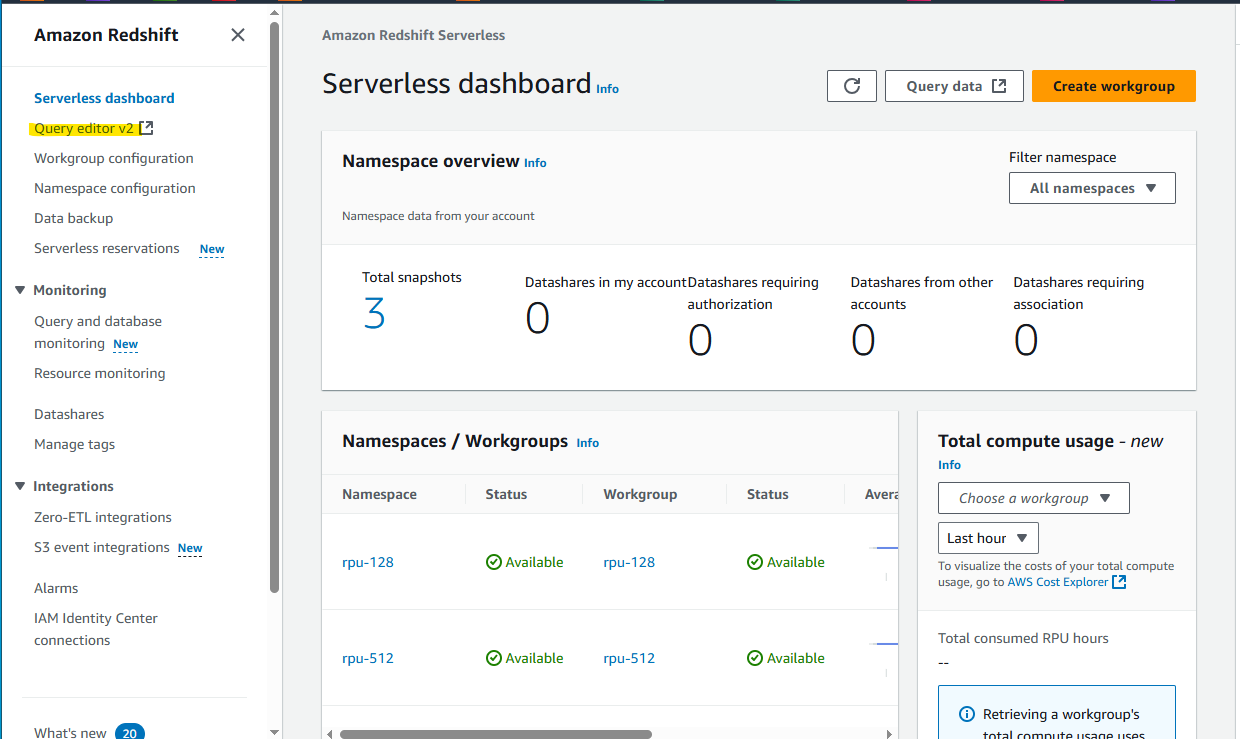
以下のテーブルを作成します。
CREATE TABLE IF NOT EXISTS dev.public.customer_sample (
customer_id INTEGER,
first_name VARCHAR(50),
last_name VARCHAR(50),
email VARCHAR(100),
age INTEGER,
city VARCHAR(50),
registration_date DATE,
total_purchase DECIMAL(10,2)
);
Glue : Snowflake Connection
AWS Glue で Snowflake Connection を作成していきます。Snowflake に接続するための文字列を AWS Secrets Manager に保存します。
Store a new secret を押します。
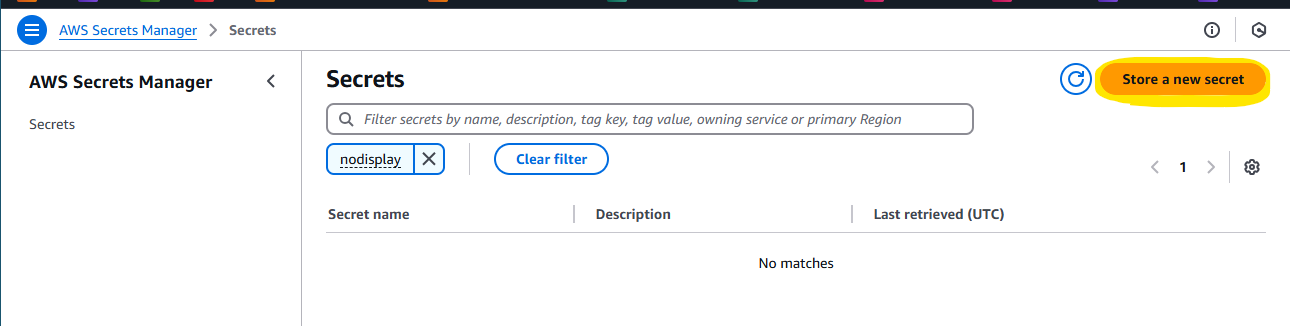
以下に、Snowflake 接続用の Username を Password を入れます。
AWS Glue の画面に変更して、Create Connection を押します。
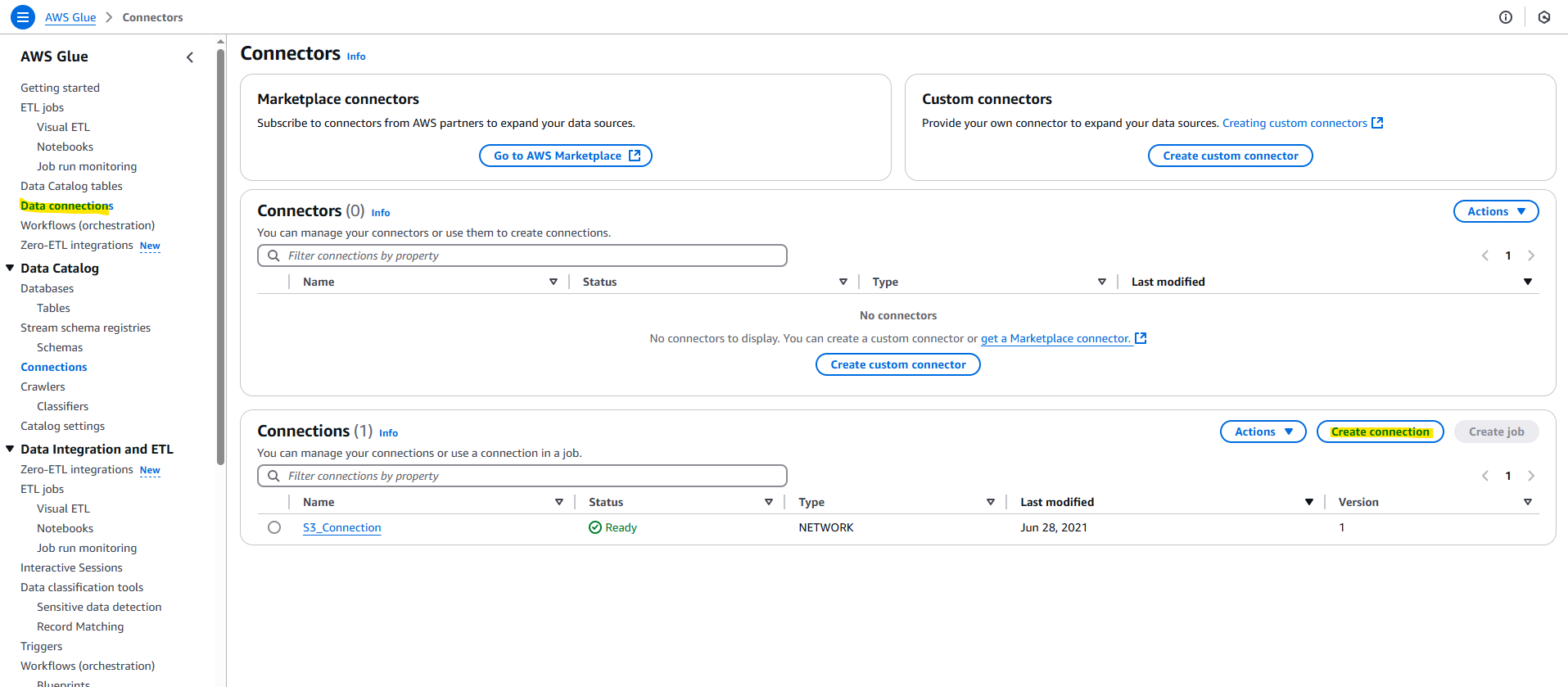
Snowflake を選択します。
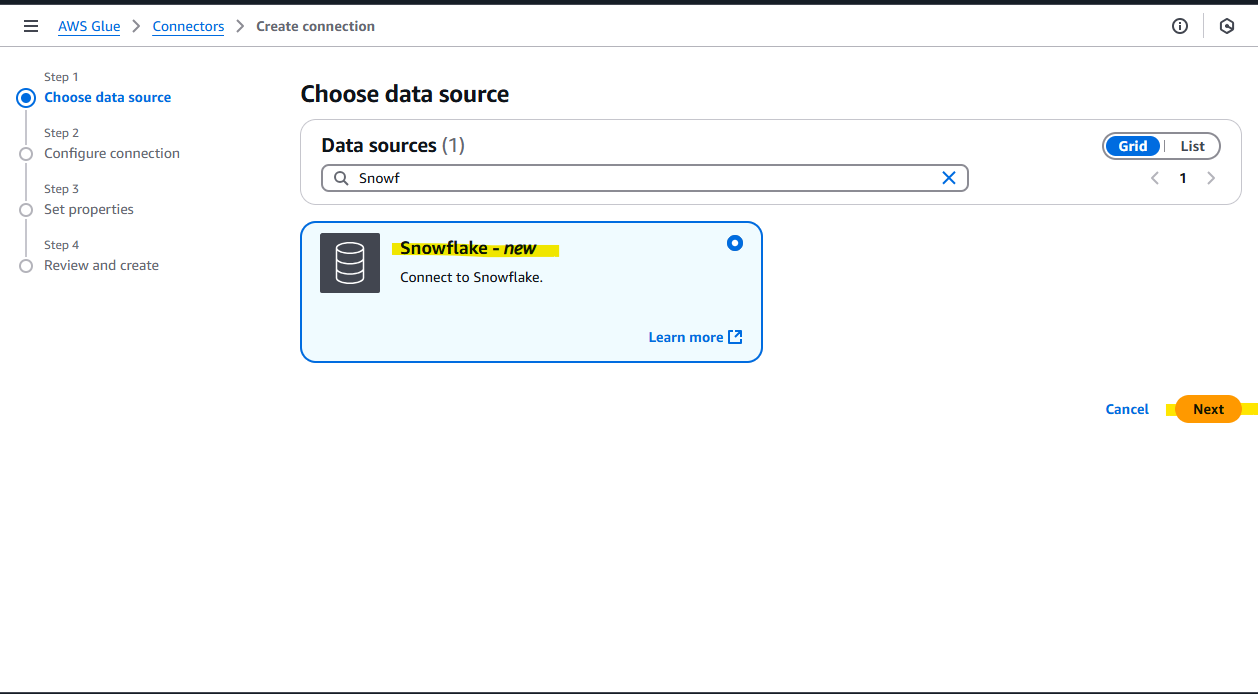
設定をするために、Snowflake の画面上で、Account/Server URL を確認します。
- Host : 確認した
Account/Server URLを入力 - Port : 443 を入力
- AWS Secret : 上の手順で作成した Secrets Manager の Store 名を入力
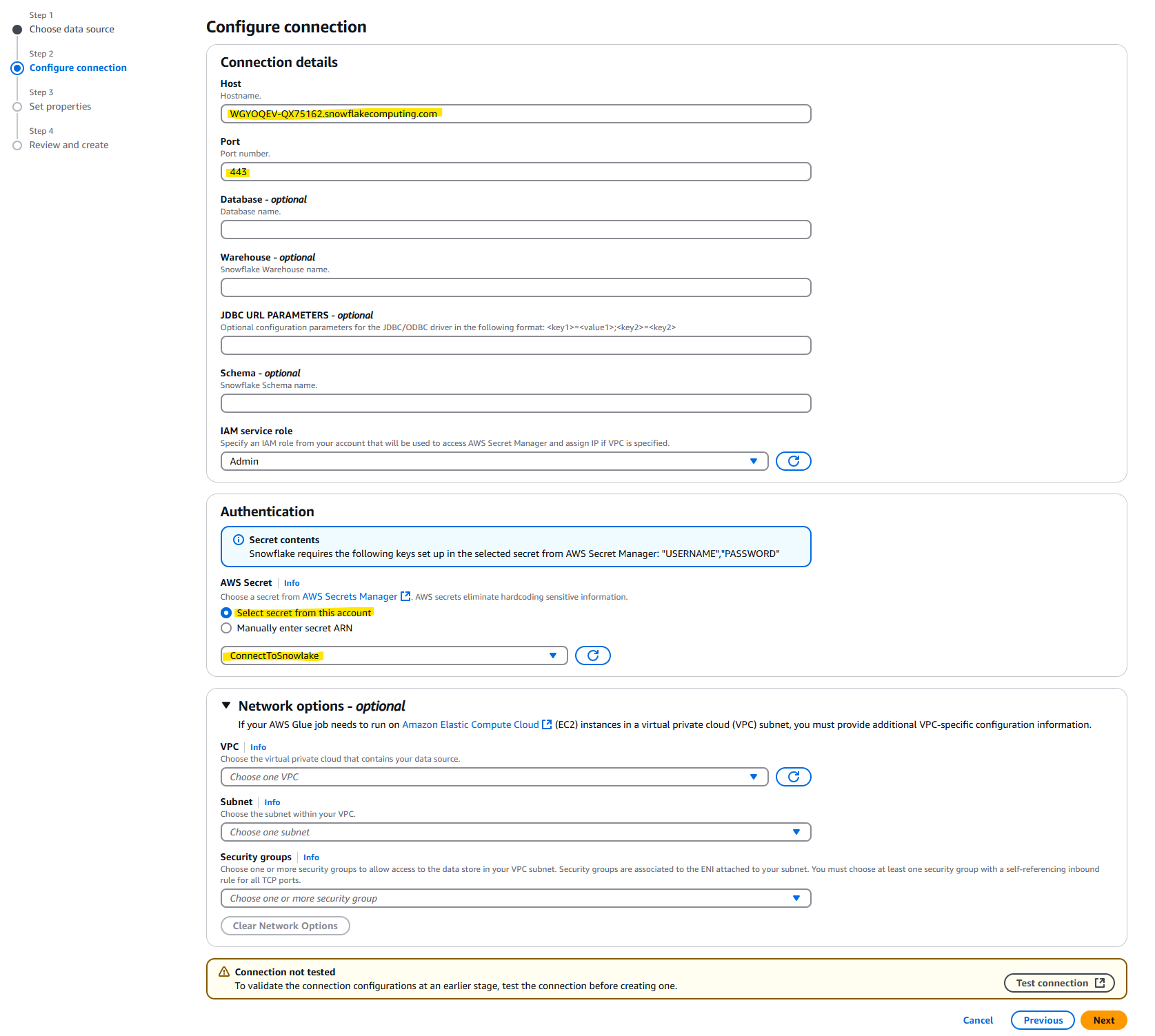
Test connection を押します。

Success と表示されれば OK です。

Glue : Redshift Serverless 用 JDBC Conenction
Glue から Redshift Serverless に接続するために、Redshift Serverless の Workgroup configration から JDBC URL をメモします。
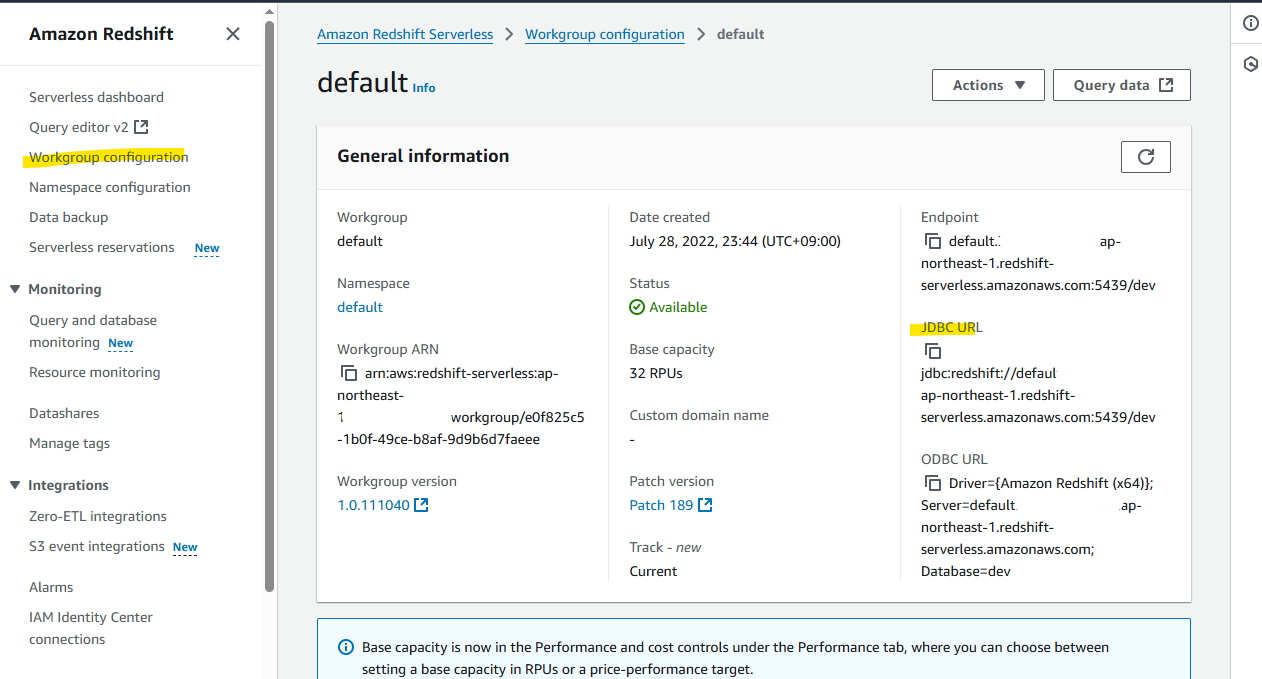
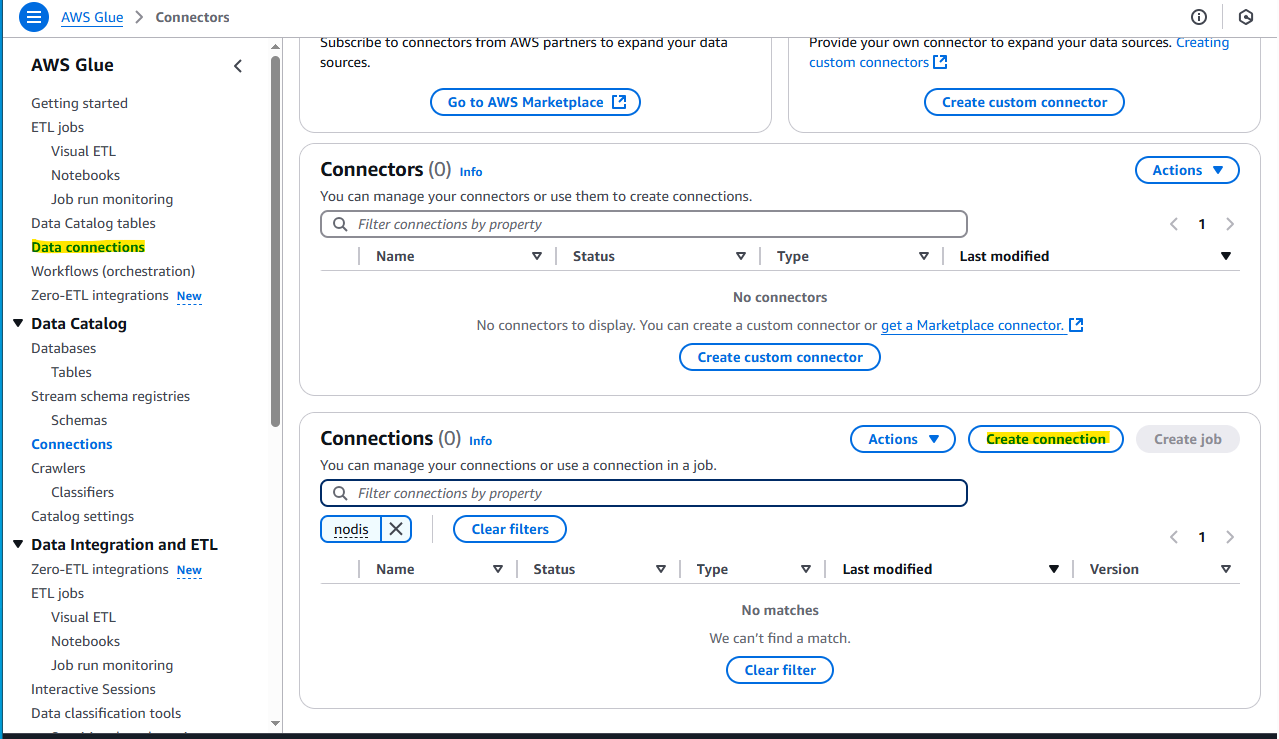
AWS Glue の画面に戻り、Create connection を選択します。
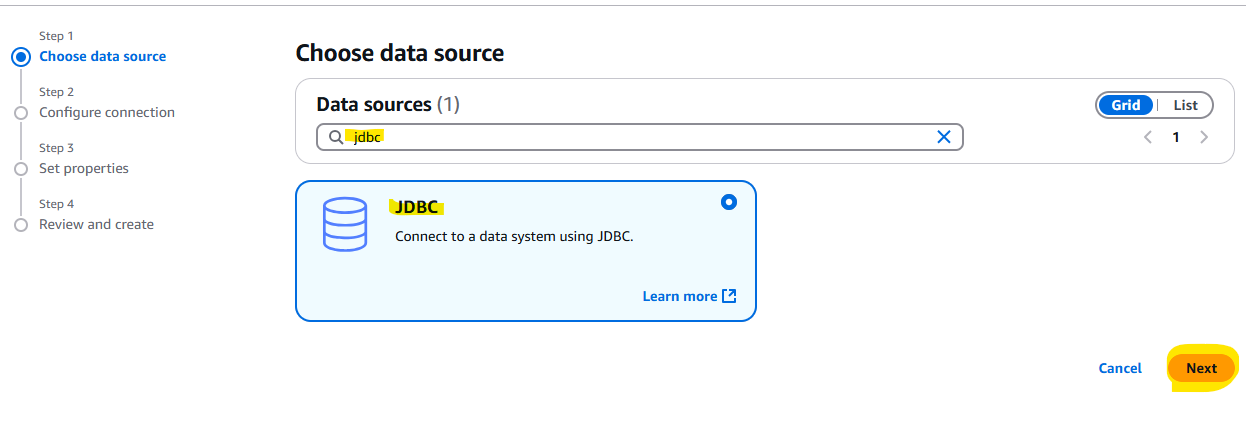
JDBC を選択します。
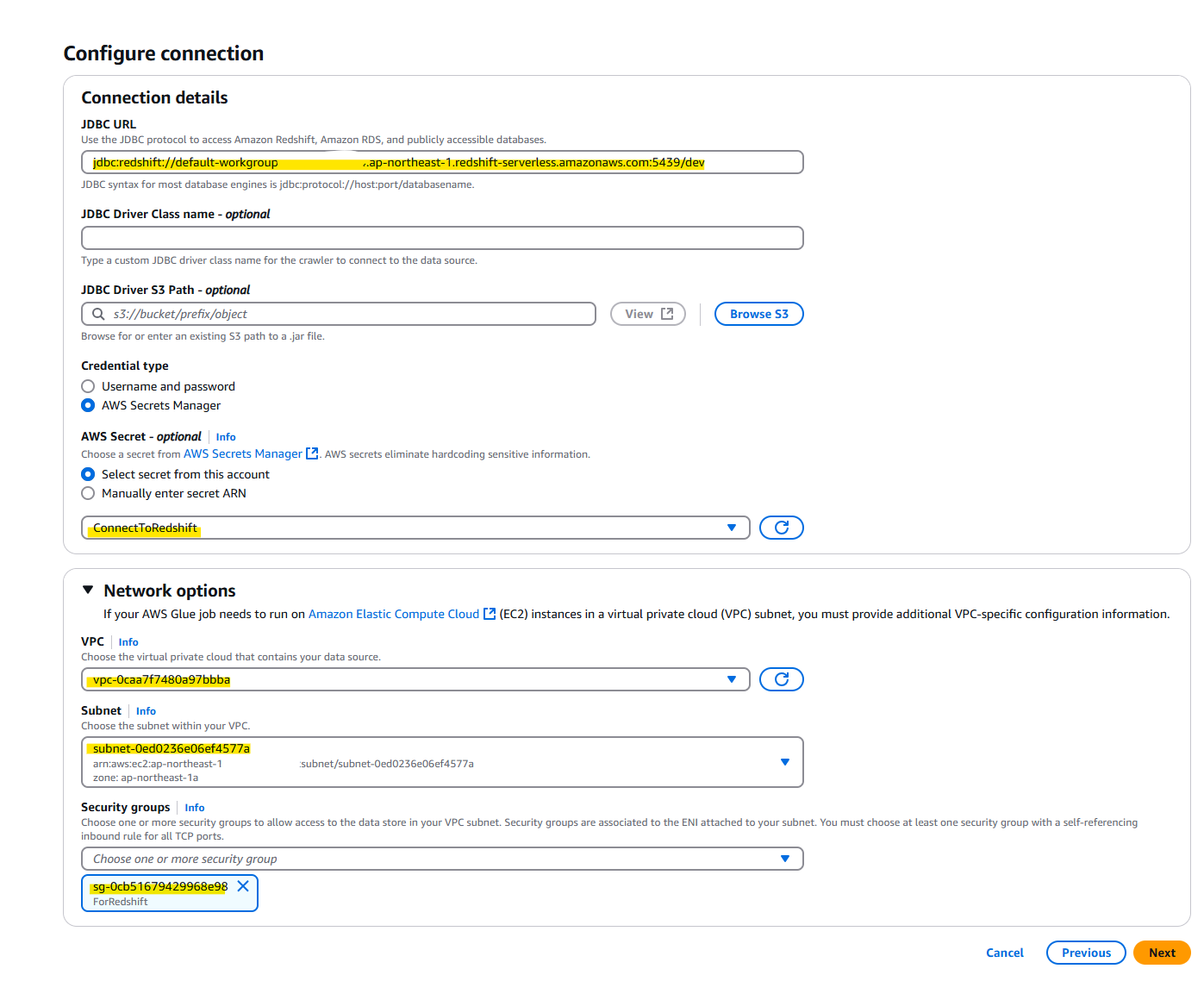
- JDBC URL : 上記の手順で調べた文字列を指定
- AWS Secret : Redshift Severless の接続用 Username と Password を Store したものを指定。作成していない場合は、Username and password から指定可能
- Network options : Redshift Serverless を動かしている VPC や Subnet や Security Group を指定
Glue : Visual ETL
ここまで準備が出来たので、AWS Glue の Visual ETL を作成します。
Data source を Snowflake を指定します。Enter a custom query から、独自の Custom SQL を指定可能です。
SELECT * FROM public.customer_sample WHERE registration_date >= '2022-05-01';
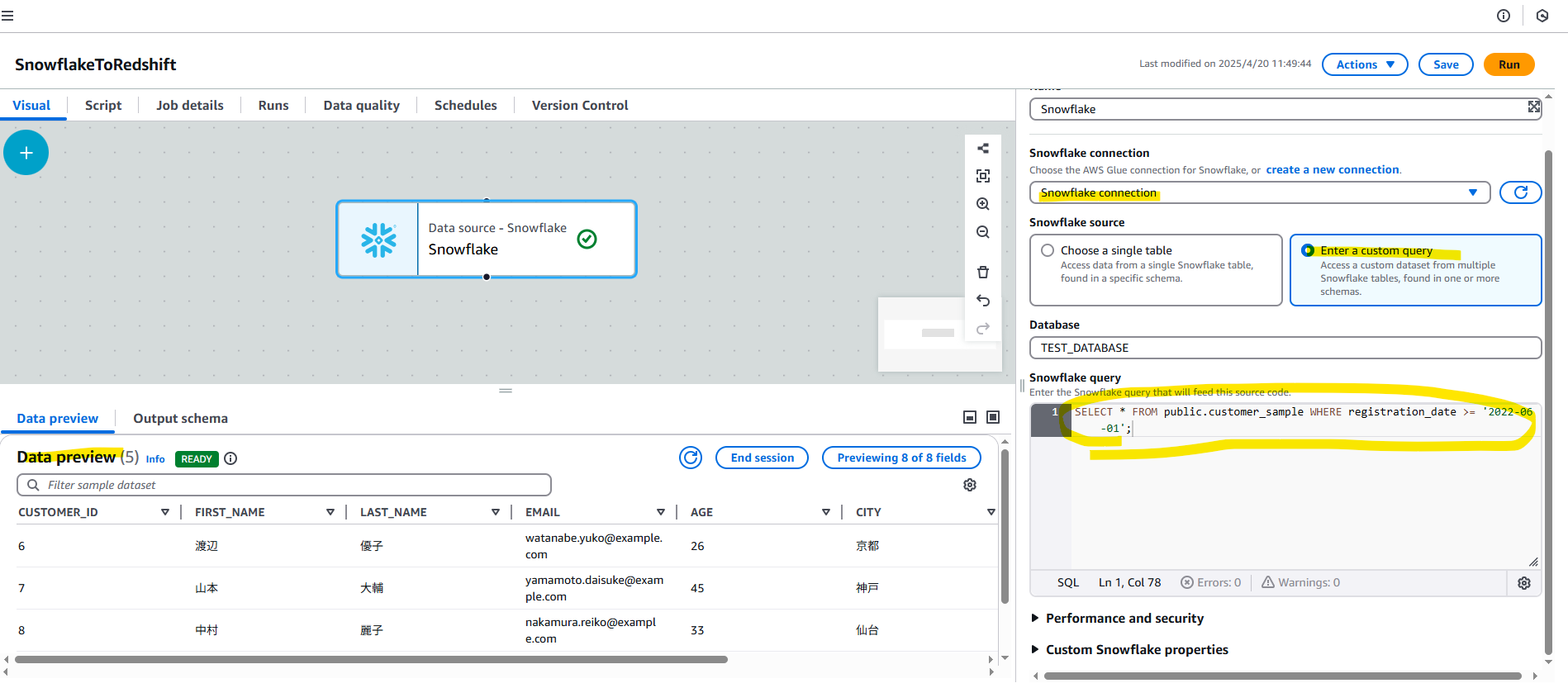
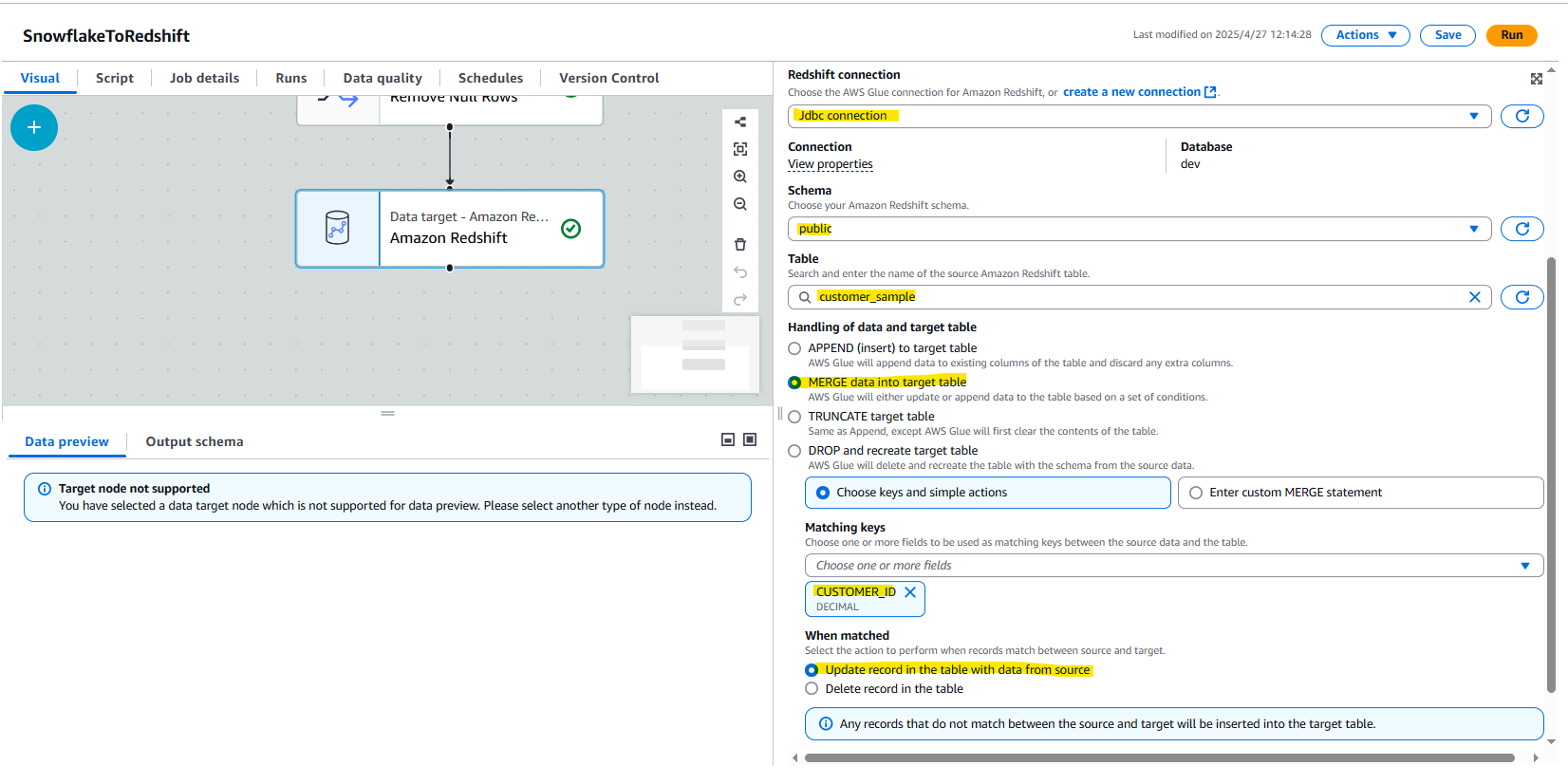
Target に Redshift Serverless を選択します。
- JDBC Connection を利用
- アクションは、以下の 4 つとなる。今回は MERGE を選択します。
- APPEND (insert) to target table
AWS Glueは既存のテーブルの列にデータを追加し、余分な列は破棄します。- APPEND は、単純に追記する。すでに Redshift 上に同じデータが存在していても、気にせず重複して追記をする。
- MERGE data into target table
AWS Glueは条件のセットに基づいて、テーブルにデータを更新または追加します。 - TRUNCATE target table
Appendと同様ですが、AWS Glueはまずテーブルの内容をクリアします。 - DROP and recreate target table
AWS Glueはテーブルを削除し、ソースデータからのスキーマでテーブルを再作成します。
- APPEND (insert) to target table
上記の設定をしたときに、Visual ETL の裏側で自動作成される PySpark のコードを確認できます。
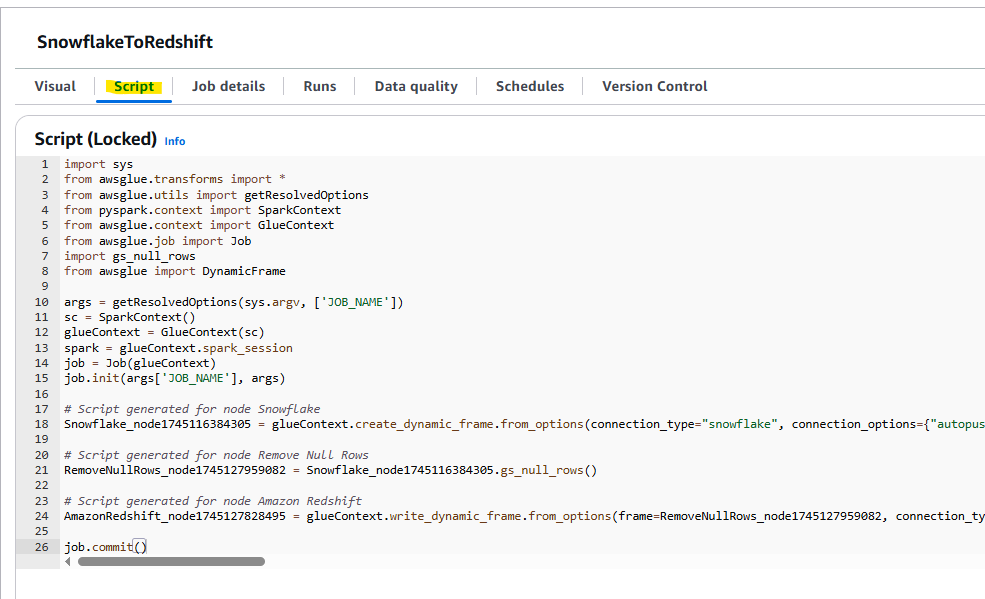
以下のコードが見えます。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
import gs_null_rows
from awsglue import DynamicFrame
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
# Script generated for node Snowflake
Snowflake_node1745116384305 = glueContext.create_dynamic_frame.from_options(connection_type="snowflake", connection_options={"autopushdown": "on", "dbtable": "CUSTOMER_SAMPLE", "connectionName": "Snowflake connection", "sfDatabase": "TEST_DATABASE", "sfSchema": "PUBLIC"}, transformation_ctx="Snowflake_node1745116384305")
# Script generated for node Remove Null Rows
RemoveNullRows_node1745127959082 = Snowflake_node1745116384305.gs_null_rows()
# Script generated for node Amazon Redshift
AmazonRedshift_node1745127828495 = glueContext.write_dynamic_frame.from_options(frame=RemoveNullRows_node1745127959082, connection_type="redshift", connection_options={"postactions": "BEGIN; MERGE INTO public.customer_sample USING public.customer_sample_temp_xk4c59 ON customer_sample.CUSTOMER_ID = customer_sample_temp_xk4c59.CUSTOMER_ID WHEN MATCHED THEN UPDATE SET CUSTOMER_ID = customer_sample_temp_xk4c59.CUSTOMER_ID, FIRST_NAME = customer_sample_temp_xk4c59.FIRST_NAME, LAST_NAME = customer_sample_temp_xk4c59.LAST_NAME, EMAIL = customer_sample_temp_xk4c59.EMAIL, AGE = customer_sample_temp_xk4c59.AGE, CITY = customer_sample_temp_xk4c59.CITY, REGISTRATION_DATE = customer_sample_temp_xk4c59.REGISTRATION_DATE, TOTAL_PURCHASE = customer_sample_temp_xk4c59.TOTAL_PURCHASE WHEN NOT MATCHED THEN INSERT VALUES (customer_sample_temp_xk4c59.CUSTOMER_ID, customer_sample_temp_xk4c59.FIRST_NAME, customer_sample_temp_xk4c59.LAST_NAME, customer_sample_temp_xk4c59.EMAIL, customer_sample_temp_xk4c59.AGE, customer_sample_temp_xk4c59.CITY, customer_sample_temp_xk4c59.REGISTRATION_DATE, customer_sample_temp_xk4c59.TOTAL_PURCHASE); DROP TABLE public.customer_sample_temp_xk4c59; END;", "redshiftTmpDir": "s3://aws-glue-assets-xxxxxxxxxxxx-ap-northeast-1/temporary/", "useConnectionProperties": "true", "dbtable": "public.customer_sample_temp_xk4c59", "connectionName": "Jdbc connection", "preactions": "CREATE TABLE IF NOT EXISTS public.customer_sample (CUSTOMER_ID DECIMAL, FIRST_NAME VARCHAR, LAST_NAME VARCHAR, EMAIL VARCHAR, AGE DECIMAL, CITY VARCHAR, REGISTRATION_DATE DATE, TOTAL_PURCHASE DECIMAL); DROP TABLE IF EXISTS public.customer_sample_temp_xk4c59; CREATE TABLE public.customer_sample_temp_xk4c59 (CUSTOMER_ID DECIMAL, FIRST_NAME VARCHAR, LAST_NAME VARCHAR, EMAIL VARCHAR, AGE DECIMAL, CITY VARCHAR, REGISTRATION_DATE DATE, TOTAL_PURCHASE DECIMAL);"}, transformation_ctx="AmazonRedshift_node1745127828495")
job.commit()
「Script generated for node Amazon Redshift」の箇所を見やすく整形します。
connection_options = {
# 前処理アクション
"preactions": """
CREATE TABLE IF NOT EXISTS public.customer_sample (
CUSTOMER_ID DECIMAL,
FIRST_NAME VARCHAR,
LAST_NAME VARCHAR,
EMAIL VARCHAR,
AGE DECIMAL,
CITY VARCHAR,
REGISTRATION_DATE DATE,
TOTAL_PURCHASE DECIMAL
);
DROP TABLE IF EXISTS public.customer_sample_temp_xk4c59;
CREATE TABLE public.customer_sample_temp_xk4c59 (
CUSTOMER_ID DECIMAL,
FIRST_NAME VARCHAR,
LAST_NAME VARCHAR,
EMAIL VARCHAR,
AGE DECIMAL,
CITY VARCHAR,
REGISTRATION_DATE DATE,
TOTAL_PURCHASE DECIMAL
);
""",
# 後処理アクション
"postactions": """
BEGIN;
MERGE INTO public.customer_sample
USING public.customer_sample_temp_xk4c59
ON customer_sample.CUSTOMER_ID = customer_sample_temp_xk4c59.CUSTOMER_ID
WHEN MATCHED THEN UPDATE SET
CUSTOMER_ID = customer_sample_temp_xk4c59.CUSTOMER_ID,
FIRST_NAME = customer_sample_temp_xk4c59.FIRST_NAME,
LAST_NAME = customer_sample_temp_xk4c59.LAST_NAME,
EMAIL = customer_sample_temp_xk4c59.EMAIL,
AGE = customer_sample_temp_xk4c59.AGE,
CITY = customer_sample_temp_xk4c59.CITY,
REGISTRATION_DATE = customer_sample_temp_xk4c59.REGISTRATION_DATE,
TOTAL_PURCHASE = customer_sample_temp_xk4c59.TOTAL_PURCHASE
WHEN NOT MATCHED THEN INSERT VALUES (
customer_sample_temp_xk4c59.CUSTOMER_ID,
customer_sample_temp_xk4c59.FIRST_NAME,
customer_sample_temp_xk4c59.LAST_NAME,
customer_sample_temp_xk4c59.EMAIL,
customer_sample_temp_xk4c59.AGE,
customer_sample_temp_xk4c59.CITY,
customer_sample_temp_xk4c59.REGISTRATION_DATE,
customer_sample_temp_xk4c59.TOTAL_PURCHASE
);
DROP TABLE public.customer_sample_temp_xk4c59;
END;
""",
# S3の一時ディレクトリ
"redshiftTmpDir": "s3://aws-glue-assets-xxxxxxxxxxxx-ap-northeast-1/temporary/",
# 接続プロパティを使用
"useConnectionProperties": "true",
# 対象テーブル(一時テーブル)
"dbtable": "public.customer_sample_temp_xk4c59",
# 使用する接続名
"connectionName": "Jdbc connection"
}
Redshift にデータを入れる (MERGE) している箇所について、重要な内容をピックアップします。
-
Glue の内部処理:
- glueContext.write_dynamic_frame.from_options() メソッドを呼び出すと、Glue は内部的にデータを指定された dbtable(この場合は一時テーブル public.customer_sample_temp_xk4c59)に挿入します。
-
実行順序:
- まず preactions で定義された SQL が実行され、テーブル構造が準備されます
- 次に Glue が自動的に DynamicFrame のデータを一時テーブルに挿入します(これは内部で COPY コマンドや JDBC バッチ挿入などを使用)
- 最後に postactions で定義された SQL が実行され、MERGE 操作などが行われます
-
データ転送の仕組み:
- Glue は redshiftTmpDir で指定された S3 バケットを一時ストレージとして使用
- DynamicFrame のデータを S3 に一時的に書き出し
- Redshift の COPY コマンドを使用して S3 からデータをロード(内部的に実行)
また、Glue Visual ETL では、独自の MERGE コマンドの指定も可能です。
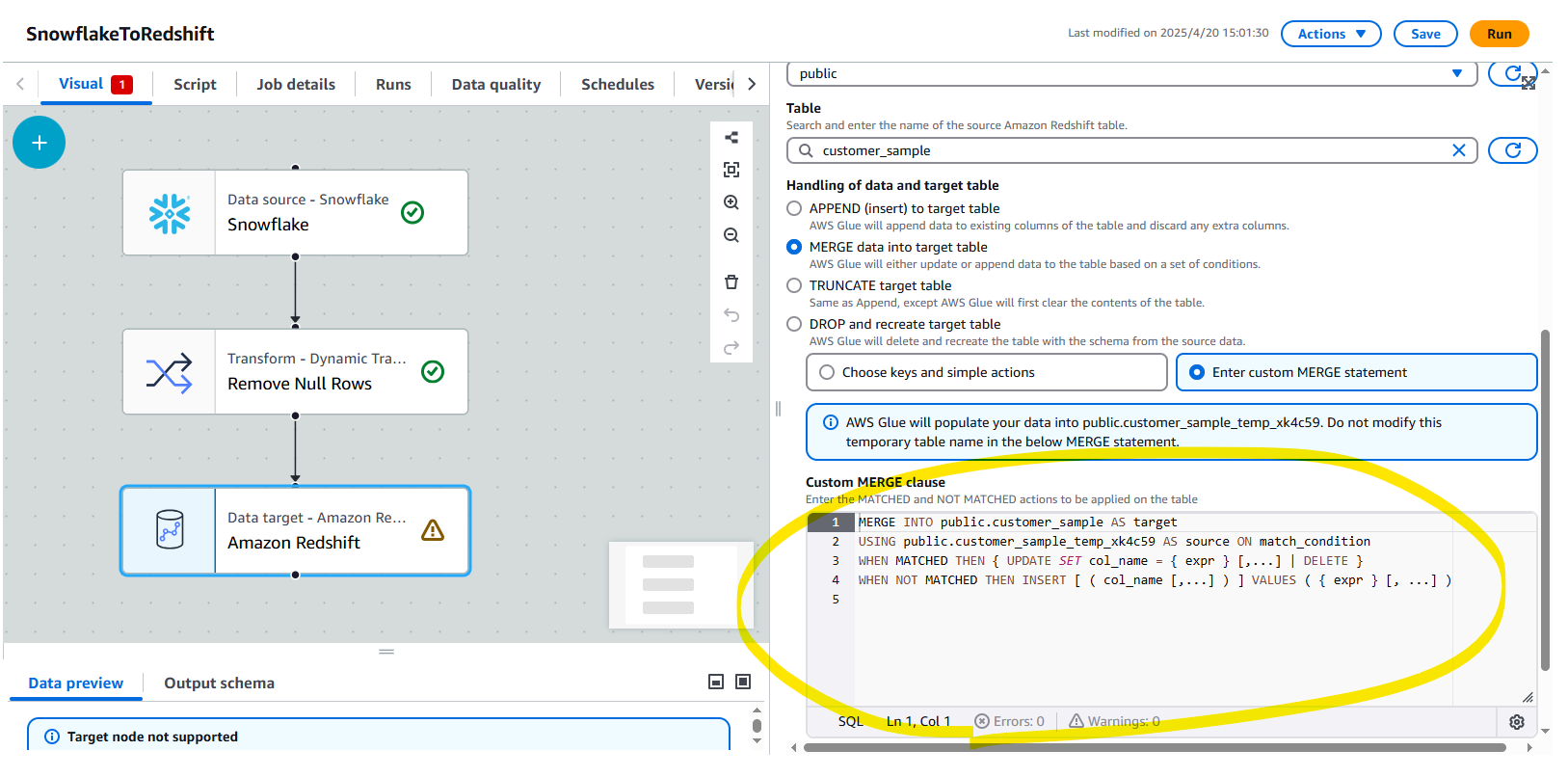
動作確認
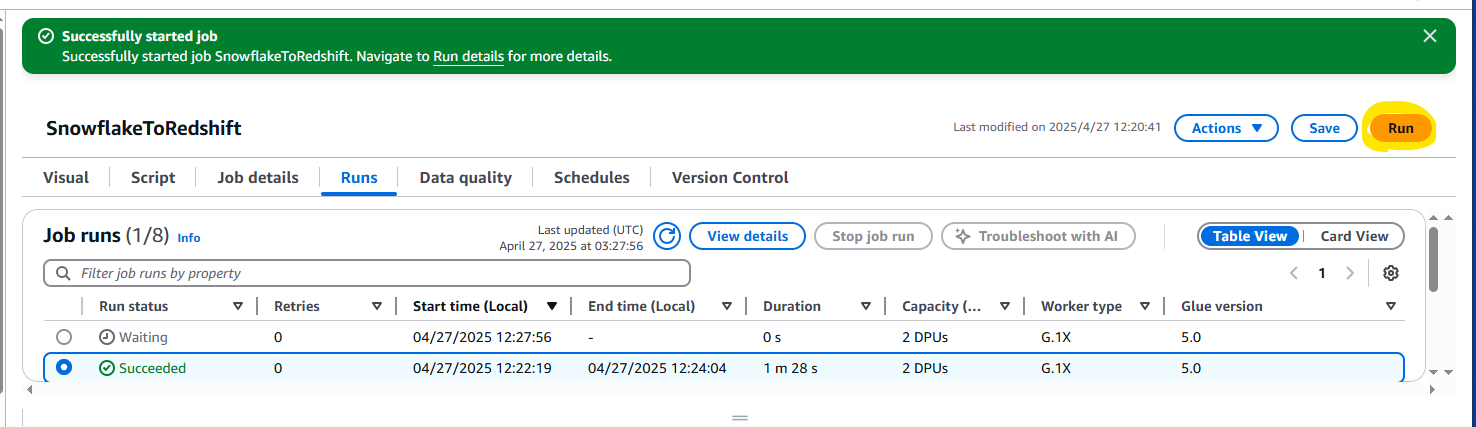
Run を押します。
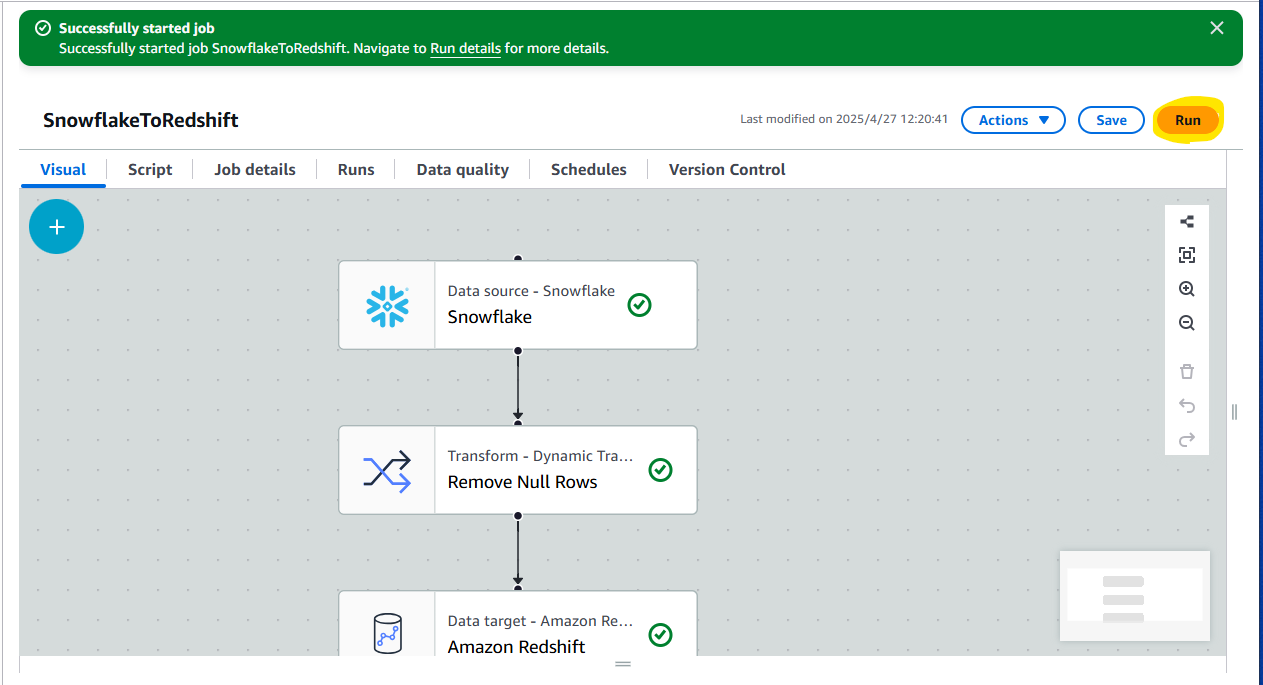
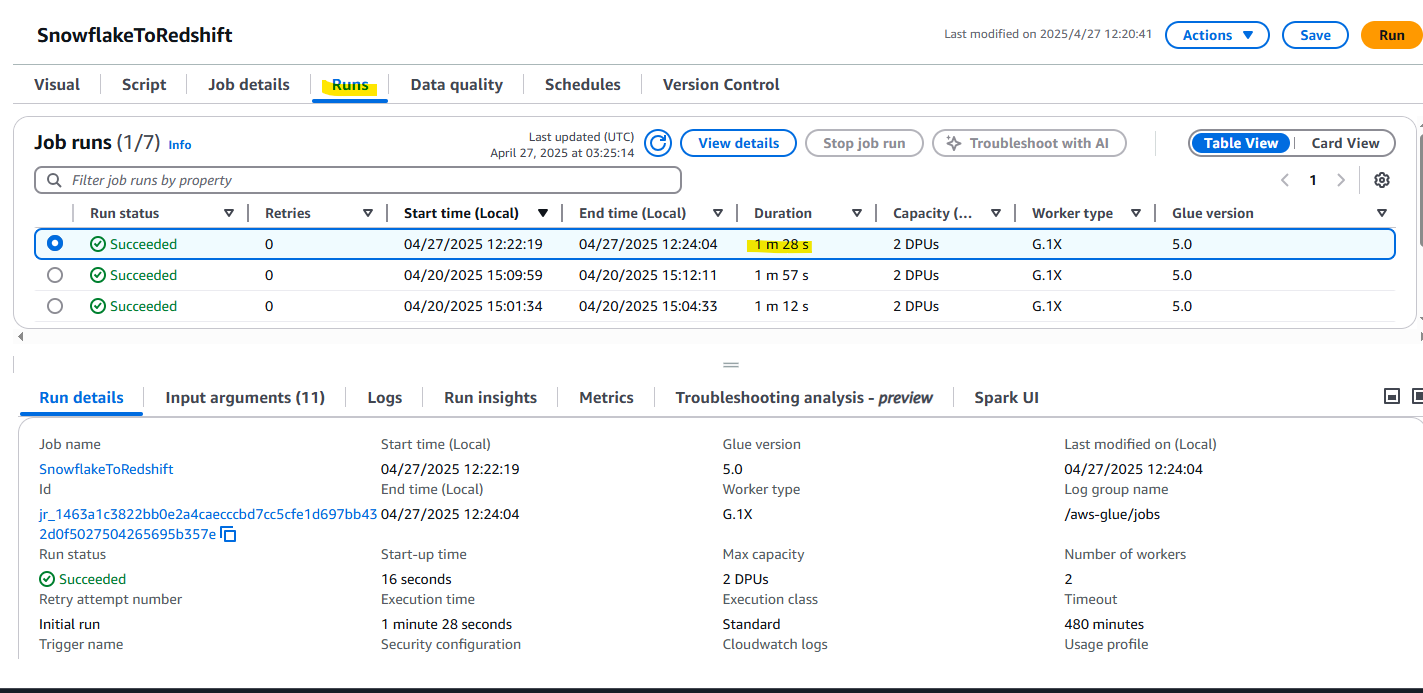
実行履歴を Runs タブから確認でき、1 分 28 秒で Succeeded となっていることがわかります。
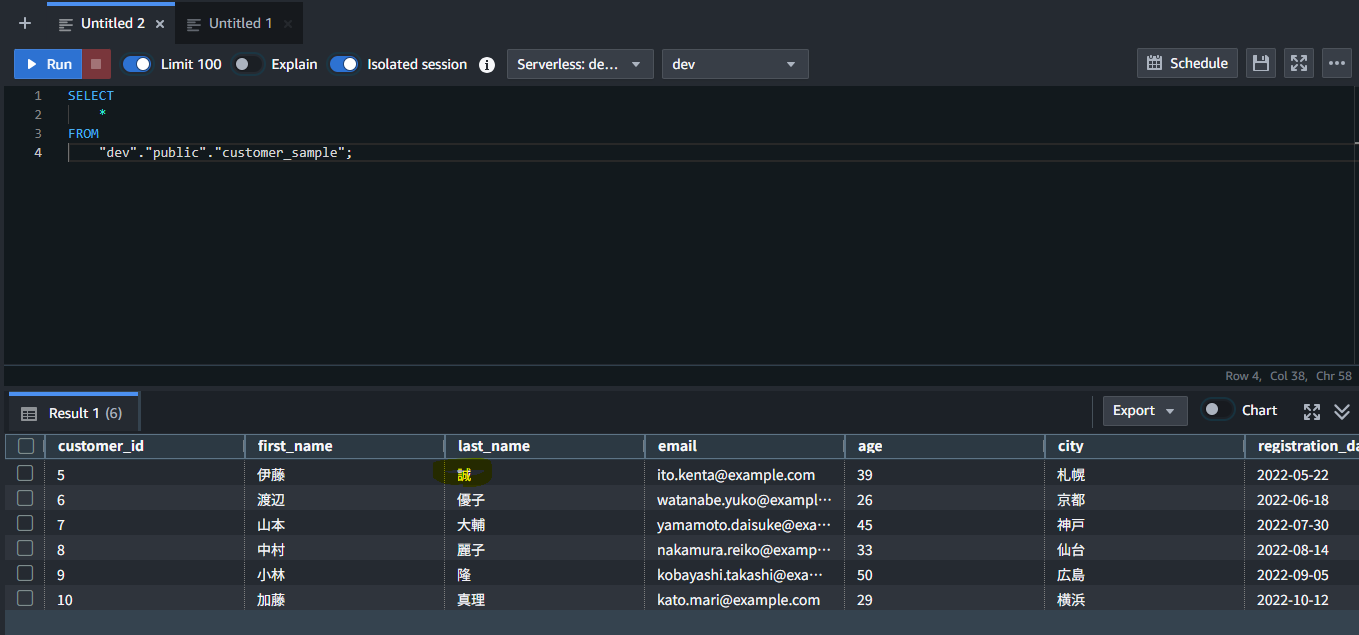
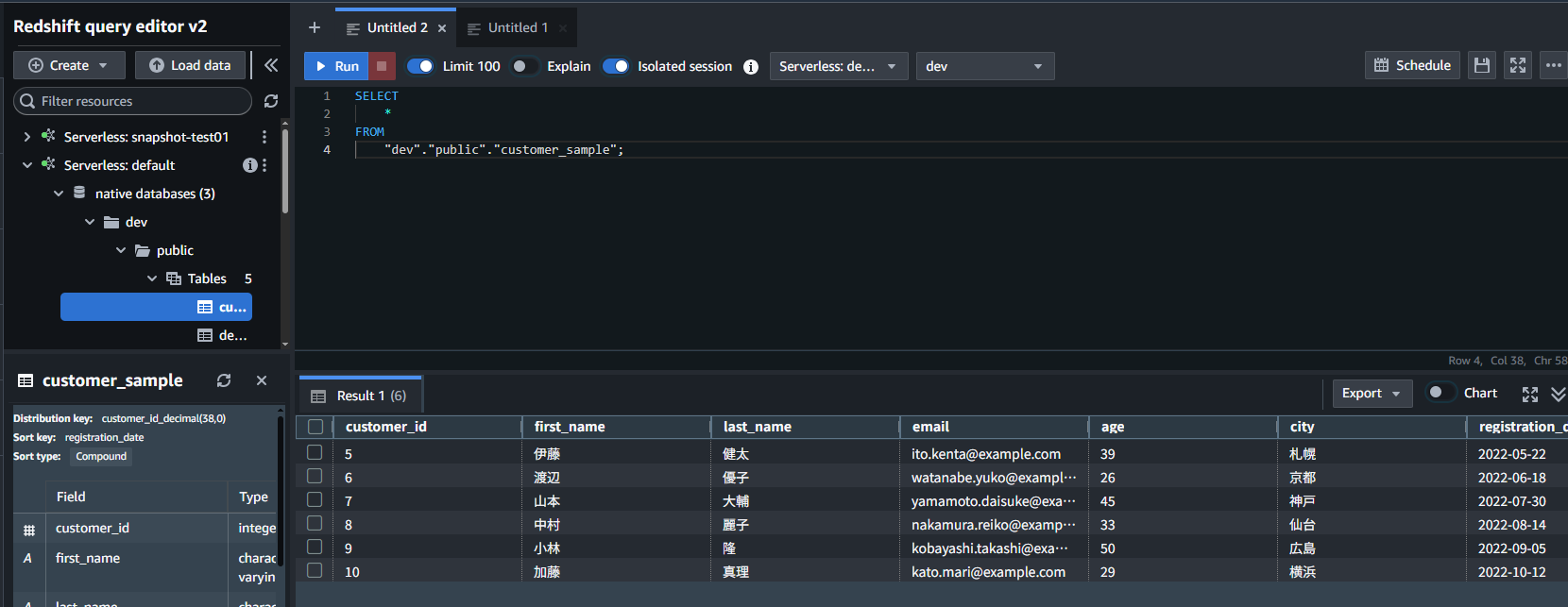
実際に Redshift Serverless で SELECT してみると、Snowflake 上のデータが新規作成されていることがわかります。
Snowflake 上のデータを更新してみましょう。健太から、誠に更新しました。
UPDATE customer_sample
SET first_name = '伊藤', last_name = '誠'
WHERE customer_id = 5;
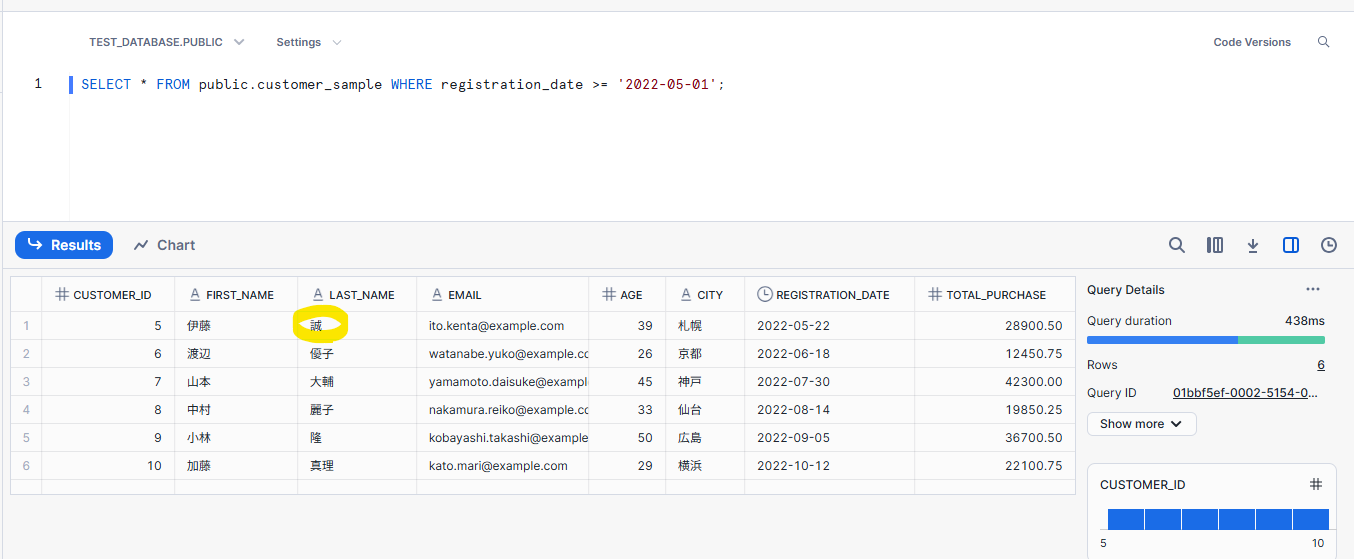
再び Glue を実行します。MERGE コマンドを利用しているので、変更されたところだけ更新されるはずです。
想定通り、Redshift 上で更新されています。