はじめに
Amazon Aurora には、Global Databse 機能があり、複数のリージョンにまたがったレプリケーションを簡単に構成する機能があります。通常、Amazon Aurora では、1 つのリージョン間で Multi-AZ を構成する機能があります。Multi-AZ 構成は、高可用性なデータベースが簡単に作れる機能となっており、Global Database より先に Multi-AZ 構成を検討するのがお勧めです。単一のリージョンでは、どうしても難しくて、なおかつリアルタイムなレプリケーションが必要なときに、Global Database の利用を検討しましょう。マルチリージョン構成はシステム全体で考慮しなければならないポイントがあり、通常は Multi-AZ 構成のほうがシンプルでおすすめです。
と前置きを置きつつ、Global Database の機能をきちんと触ったことが無かったので、Amazon Aurora Lab for MySQL というサイトにあるハンズオンを触ってみます。これを検証しながら、わかった点を整理していきます。興味があればぜひ触ってみてください。
構成図
次の構成図のように、Tokyo Region と Osaka Region 間で、Global Database を構成していきます。

東京側 : Aurora Aurora Cluster の作成
まず、東京側で通常の Aurora Cluster を作成していきます。Create database を押します。
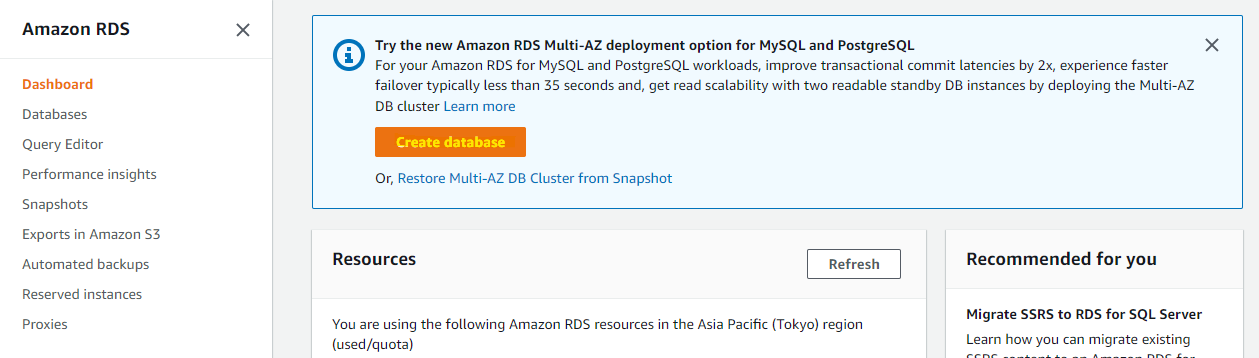
Global Database を利用するときには、特定のバージョンを利用する必要があります。サポートされていないバージョンをフィルターしながら、Aurora のバージョンを指定します。

Cluster 名などを指定します。

Multi-AZ を有効化します。

Create Database を押します

東京側で、通常の Aurora Cluster が作成されました。
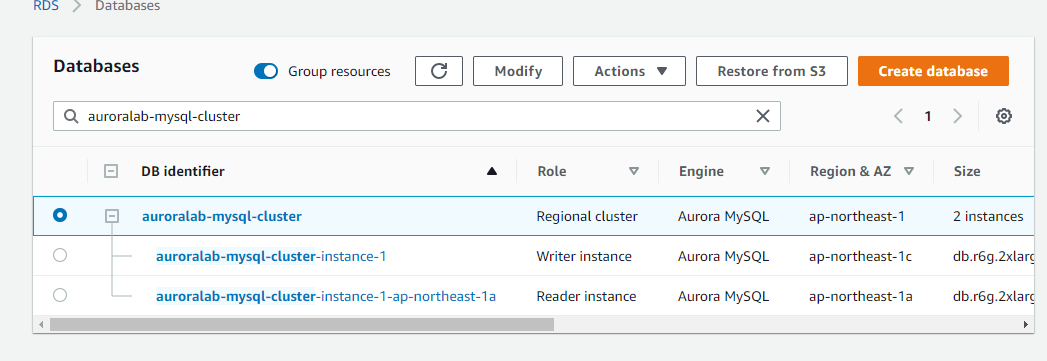
東京側 : Aurora global cluster の作成
東京側の画面を操作して、大阪も含めた Global Cluster を作成していきます。Actions から、Add AWS Regions を選択します。

対抗側のリージョンについての設定です。名前や Region や、Instance Type の選択をします。
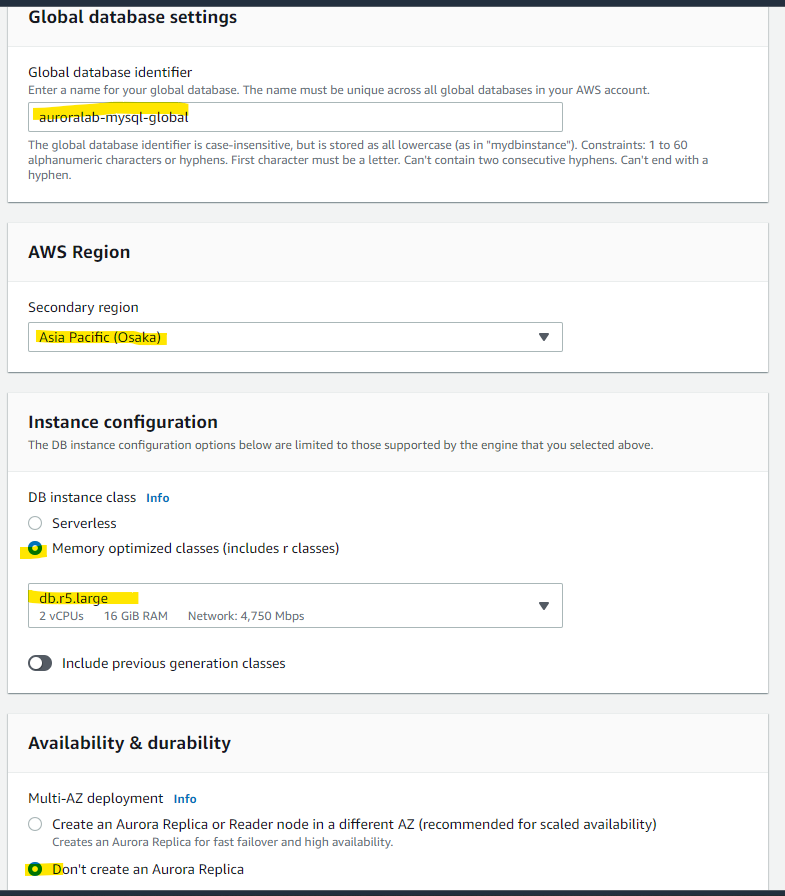
大阪側の VPC 等を指定します。
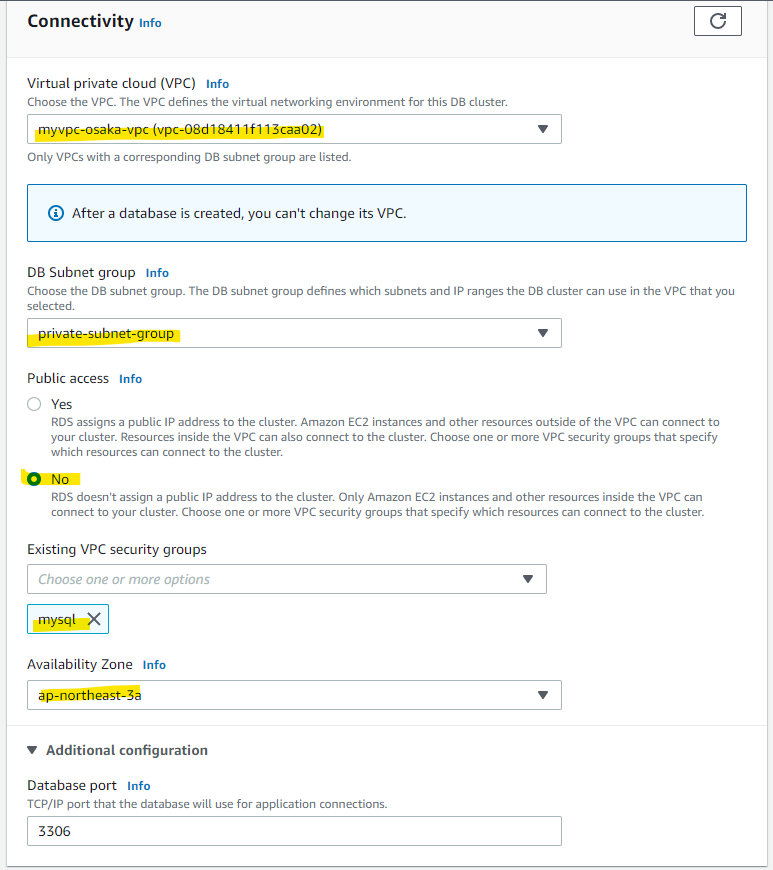
write forwarding の機能を有効化します。詳細は後で取り上げます。
Add region を押します。

Global Database が作成できました。
- Tokyo の画面の中に、大阪の Cluster も一緒に表示されていることがわかる。
- Secondary 側は、Reader Endpoint のみ作成される。Writer は作成されない。

Osaka Region 側の RDS 画面を見ると、こちらも Tokyo と Osaka の両方のクラスターが表示される。

Primary 側のクラスターには、Writer と Reader の Endpoint が作成されている

Secondary 側は、Writer Endpoint は作成されない。

それぞれのリージョンで接続
東京側
東京側にある EC2 インスタンスを使って、mysql コマンドで接続をしていきます。
mysql \
-u administrator \
-h auroralab-mysql-cluster.cluster-chuxmuzmrpgx.ap-northeast-1.rds.amazonaws.com \
-p
接続例
> mysql -u administrator -h auroralab-mysql-cluster.cluster-chuxmuzmrpgx.ap-northeast-1.rds.amazonaws.com -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 123
Server version: 8.0.23 Source distribution
Copyright (c) 2000, 2021, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql>
100 万行のデータを生成してみます。
CREATE DATABASE test;
USE test;
DROP TABLE IF EXISTS gdbtest1;
DROP PROCEDURE IF EXISTS InsertRand;
CREATE TABLE gdbtest1 (
pk INT NOT NULL AUTO_INCREMENT,
gen_number INT NOT NULL,
PRIMARY KEY (pk)
);
delimiter //
CREATE PROCEDURE InsertRand(IN NumRows INT, IN MinVal INT, IN MaxVal INT)
BEGIN
DECLARE i INT;
SET i = 1;
START TRANSACTION;
WHILE i <= NumRows DO
INSERT INTO gdbtest1 (gen_number) VALUES (MinVal + CEIL(RAND() * (MaxVal - MinVal)));
SET i = i + 1;
END WHILE;
COMMIT;
END;
//
delimiter ;
CALL InsertRand(1000000, 1357, 9753);
データの確認
SELECT count(pk), sum(gen_number), md5(avg(gen_number)) FROM gdbtest1;
実行例
mysql> SELECT count(pk), sum(gen_number), md5(avg(gen_number)) FROM gdbtest1;
+-----------+-----------------+----------------------------------+
| count(pk) | sum(gen_number) | md5(avg(gen_number)) |
+-----------+-----------------+----------------------------------+
| 1000000 | 5555616794 | 068436e9d9c7e47d44c38c5a97d77794 |
+-----------+-----------------+----------------------------------+
1 row in set (1.20 sec)
大阪側
東京で生成したデータが大阪側に反映されているか確認します。
大阪側の Endpoint に接続します。
mysql \
-u administrator \
-h auroralab-mysql-secondary.cluster-ro-cz7qyris6ivy.ap-northeast-3.rds.amazonaws.com \
-p
実行例
[ec2-user@ip-10-1-10-45 ~]$ mysql \
> -u administrator \
> -h auroralab-mysql-secondary.cluster-ro-cz7qyris6ivy.ap-northeast-3.rds.amazonaws.com \
> -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 67
Server version: 8.0.23 Source distribution
Copyright (c) 2000, 2022, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql>
USE test;
実行例です。東京で生成したデータが大阪側にも反映されています。
mysql> SELECT count(pk), sum(gen_number), md5(avg(gen_number)) FROM gdbtest1;
+-----------+-----------------+----------------------------------+
| count(pk) | sum(gen_number) | md5(avg(gen_number)) |
+-----------+-----------------+----------------------------------+
| 1000000 | 5555616794 | 068436e9d9c7e47d44c38c5a97d77794 |
+-----------+-----------------+----------------------------------+
1 row in set (1.20 sec)
Global Database のモニタリング
Global Dabase で気にした方が良いメトリクスについて触れていきます。Global Database は、非同期なレプリケーションなので、タイムラグが気になります。通常の利用の範囲では、十分高速に動作しますが、データの更新料によってはレプリケーションラグが無視できなくなるかもしれません。
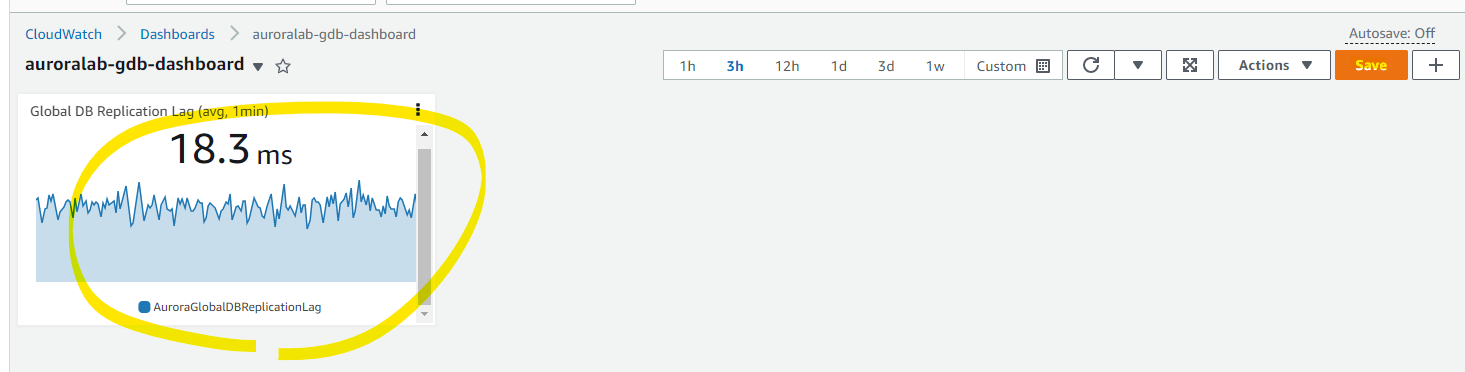
Secondary 側のメトリクスに、レプリケーションラグが確認可能がのものがあります。

これを使って、独自の CloudWatch Dashboard を作成してみましょう。CloudWatch Dashboard の画面に移動して、Create dashboard を押します。

適当に名前を指定します。

Number を指定します。

RDS のメトリクス配下で、「Lag」というキーワードで検索し、DBClusterIdentifier を選択します。

AuroraGlobalDBReplicationRag を選択して、タイトルの編集ボタンを押し、Global DB Replication Lag (avg, 1min) というタイトルを付けます。

Graphed metrics タブを選択し、1分ごとの Average に変更して、Create widget を押します

ダッシュボードが作られたので、Save を押します。
更に変更するため、View/edit source を押します。

以下の JSON を入力します。Region や Cluster 名などの変更があれば、この JSON の中身を変更します。
{
"widgets": [
{
"type": "metric",
"x": 0,
"y": 3,
"width": 24,
"height": 6,
"properties": {
"metrics": [
[ "AWS/RDS", "AuroraGlobalDBReplicationLag", "DBClusterIdentifier", "auroralab-mysql-secondary" ],
[ "...", { "stat": "Maximum" } ]
],
"view": "timeSeries",
"stacked": false,
"region": "ap-northeast-3",
"title": "Global DB Replication Lag (max vs. avg, 1min)",
"stat": "Average",
"period": 60
}
},
{
"type": "metric",
"x": 0,
"y": 0,
"width": 9,
"height": 3,
"properties": {
"metrics": [
[ "AWS/RDS", "AuroraGlobalDBReplicationLag", "DBClusterIdentifier", "auroralab-mysql-secondary" ]
],
"view": "singleValue",
"region": "ap-northeast-3",
"title": "Global DB Replication Lag (avg, 1min)",
"stat": "Average",
"period": 60
}
},
{
"type": "metric",
"x": 9,
"y": 0,
"width": 15,
"height": 3,
"properties": {
"metrics": [
[ "AWS/RDS", "AuroraGlobalDBReplicatedWriteIO", "DBClusterIdentifier", "auroralab-mysql-secondary", { "label": "Global DB Replicated Write IOs" } ],
[ ".", "AuroraGlobalDBDataTransferBytes", ".", ".", { "label": "Global DB DataTransfer Bytes" } ]
],
"view": "singleValue",
"region": "ap-northeast-3",
"stat": "Sum",
"period": 86400,
"title": "Billable Replication Metrics (aggregate, last 24 hr)"
}
}
]
}
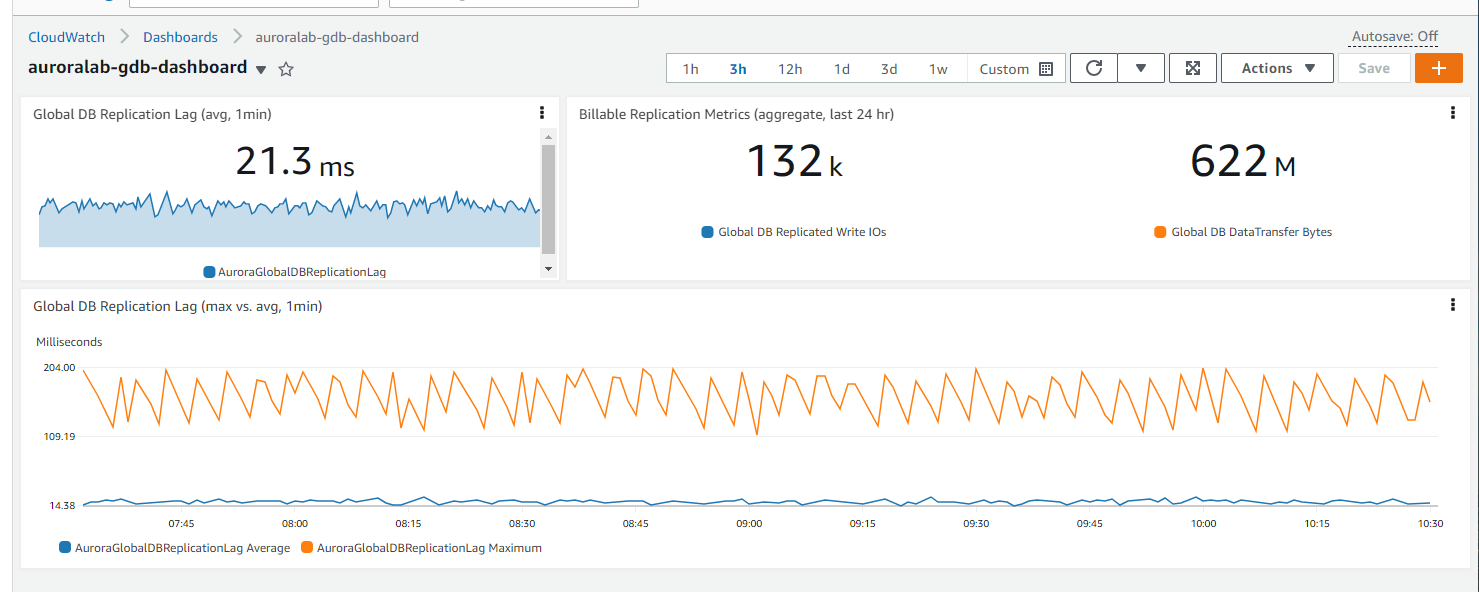
こんな見た目になりました。このように、レプリケーションラグをモニタリングしていくよいでしょう。
Write Forwarding 機能の利用
Secondary Cluster 側は、通常読み込み処理のみできます。Write Forwarding 機能を有効化することで、Secondary Cluster の Endpoint で書き込み処理をしたときに、Primary Cluster 側に転送することができます。Write Forwarding 機能を試してみましょう。
東京側
動作確認をするために、テーブルを作成します。
DROP SCHEMA IF EXISTS `mybank`;
CREATE SCHEMA `mybank`;
USE `mybank`;
CREATE TABLE `accounts` (
`account_number` VARCHAR(12) NOT NULL,
`customer_id` BIGINT NOT NULL,
`customer_name` VARCHAR(50) NOT NULL,
`total_balance` DECIMAL(16,2) NOT NULL DEFAULT 0.00,
`opened_date` DATE NOT NULL,
`closed_date` DATE DEFAULT NULL,
`account_type` ENUM('Checking','Savings') NOT NULL DEFAULT 'Checking',
`account_status` ENUM('Pending','Active','Delinquent','Closed') NOT NULL DEFAULT 'Pending',
PRIMARY KEY (`account_number`),
KEY `customer_account` (`customer_id`, `account_number`)
);
CREATE TABLE `transactions` (
`trx_id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`account_number` VARCHAR(12) NOT NULL,
`trx_tstamp` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
`trx_medium` ENUM('Cash', 'Check', 'ACH', 'Swift', 'Initial') NOT NULL,
`trx_type` ENUM('Deposit', 'Withdrawal') NOT NULL,
`trx_amount` DECIMAL(16,2) NOT NULL DEFAULT 0.00,
PRIMARY KEY (`trx_id`),
KEY `account_trx_type` (`account_number`, `trx_type`)
);
大阪側
大阪側に接続したら、以下のコマンドを実行して Write Forwarding 機能を有効にします。この例では、EVENTUAL 一貫性レベルを使用しています。詳細は、「検証を通じてわかったこと」に整理しています。
USE mybank;
SET aurora_replica_read_consistency = 'EVENTUAL';
Secondary Cluster 側で INSERT をします。
INSERT INTO `accounts` VALUES
('012948503534', 1, 'John Doe', 1000.00, '2020-01-15', NULL, 'Checking', 'Active'),
('468956765097', 1, 'John Doe', 10000.00, '2020-06-12', NULL, 'Savings', 'Active');
INSERT INTO `transactions` (`account_number`, `trx_medium`, `trx_type`, `trx_amount`) VALUES
('012948503534', 'Initial', 'Deposit', 1500.00),
('012948503534', 'ACH', 'Withdrawal', 500.00),
('468956765097', 'Initial', 'Deposit', 25.00),
('468956765097', 'Cash', 'Deposit', 9975.00);
INSERT INTO `accounts` VALUES
('012948503535', 1, 'John Doe', 1000.00, '2020-01-15', NULL, 'Checking', 'Active');
実行例です。想定通り INSERT 処理が成功します。
mysql> INSERT INTO `accounts` VALUES
-> ('012948503534', 1, 'John Doe', 1000.00, '2020-01-15', NULL, 'Checking', 'Active'),
-> ('468956765097', 1, 'John Doe', 10000.00, '2020-06-12', NULL, 'Savings', 'Active');
Query OK, 2 rows affected (0.01 sec)
Records: 2 Duplicates: 0 Warnings: 0
mysql> INSERT INTO `transactions` (`account_number`, `trx_medium`, `trx_type`, `trx_amount`) VALUES
-> ('012948503534', 'Initial', 'Deposit', 1500.00),
-> ('012948503534', 'ACH', 'Withdrawal', 500.00),
-> ('468956765097', 'Initial', 'Deposit', 25.00),
-> ('468956765097', 'Cash', 'Deposit', 9975.00);
Query OK, 4 rows affected (0.02 sec)
Records: 4 Duplicates: 0 Warnings: 0
一定時間後、データがちゃんと反映されています。レプリケーションラグの扱う方法がいくつかあります。「検証を通じてわかったこと」に整理したので、こちらも見てみてください。
mysql> SELECT * FROM accounts;
+----------------+-------------+---------------+---------------+-------------+-------------+--------------+----------------+
| account_number | customer_id | customer_name | total_balance | opened_date | closed_date | account_type | account_status |
+----------------+-------------+---------------+---------------+-------------+-------------+--------------+----------------+
| 012948503534 | 1 | John Doe | 1000.00 | 2020-01-15 | NULL | Checking | Active |
| 468956765097 | 1 | John Doe | 10000.00 | 2020-06-12 | NULL | Savings | Active |
+----------------+-------------+---------------+---------------+-------------+-------------+--------------+----------------+
2 rows in set (0.00 sec)
mysql> SELECT * FROM transactions;
+--------+----------------+---------------------+------------+------------+------------+
| trx_id | account_number | trx_tstamp | trx_medium | trx_type | trx_amount |
+--------+----------------+---------------------+------------+------------+------------+
| 5 | 012948503534 | 2023-01-01 11:11:12 | Initial | Deposit | 1500.00 |
| 6 | 012948503534 | 2023-01-01 11:11:12 | ACH | Withdrawal | 500.00 |
| 7 | 468956765097 | 2023-01-01 11:11:12 | Initial | Deposit | 25.00 |
| 8 | 468956765097 | 2023-01-01 11:11:12 | Cash | Deposit | 9975.00 |
+--------+----------------+---------------------+------------+------------+------------+
4 rows in set (0.00 sec)
Recover from an Unplanned Primary DB Cluster Failure
東京リージョンが全部使えなくなったときに、大阪リージョンを昇格する方法を整理します。
東京側
以下のテーブルを作成します。
USE mybank;
DROP TABLE IF EXISTS failovertest1;
CREATE TABLE failovertest1 (
pk INT NOT NULL AUTO_INCREMENT,
gen_number INT NOT NULL,
some_text VARCHAR(100),
input_dt DATETIME,
PRIMARY KEY (pk)
);
INSERT INTO failovertest1 (gen_number, some_text, input_dt)
VALUES (100,"region-1-input",now());
COMMIT;
SELECT * FROM failovertest1;
データの中身です。
mysql> SELECT * FROM failovertest1;
+----+------------+----------------+---------------------+
| pk | gen_number | some_text | input_dt |
+----+------------+----------------+---------------------+
| 1 | 100 | region-1-input | 2023-01-01 12:03:04 |
+----+------------+----------------+---------------------+
1 row in set (0.00 sec)
大阪側
Osaka 側で、切り離し作業を行います。

Remove and Promote を行います。この操作の結果、Primary Cluster からのレプリケーションが解除されることになります。また、Secondary 側の MySQL コネクションは切断されます。
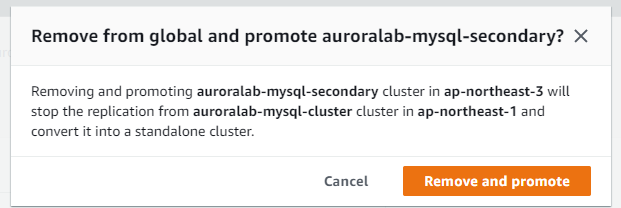
ステーたるが Promoting になります
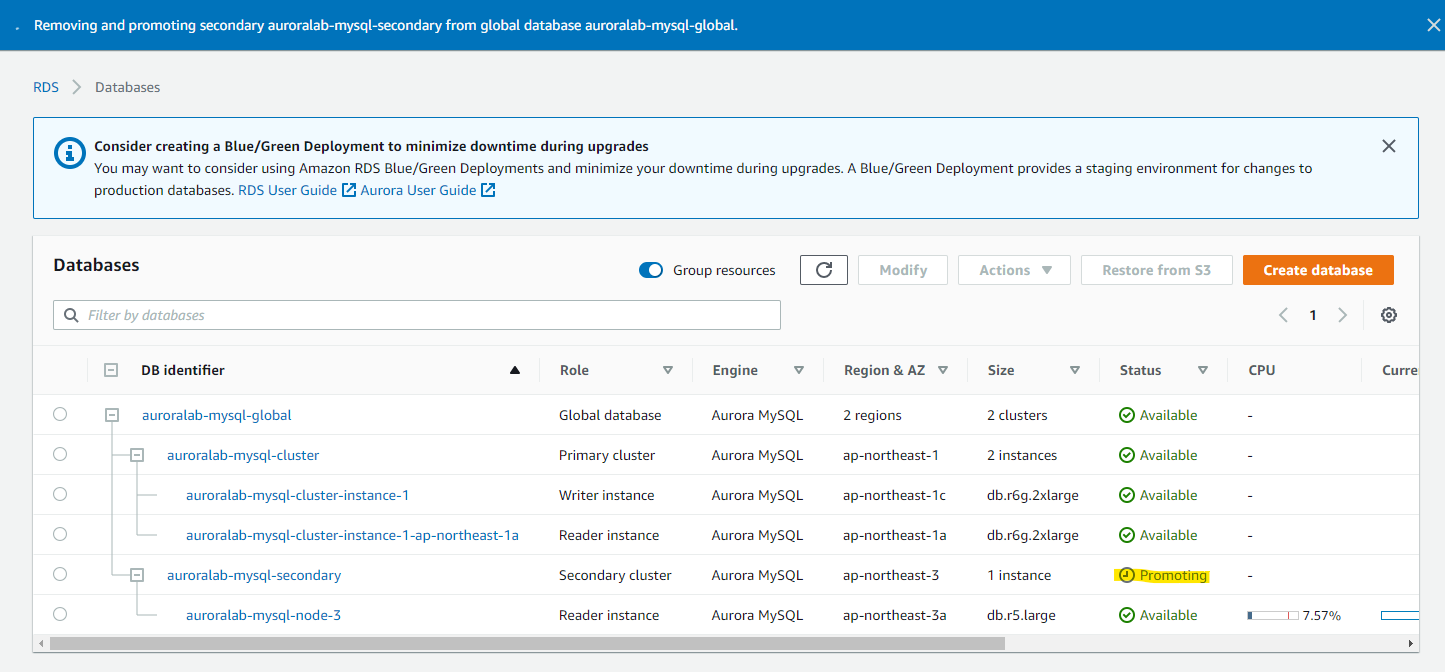
通常 1 分ほどで Promoting が完了します。Secondary Cluster から Regional Cluster に変わり、Reader Instance から Writer Instance に変わりました。
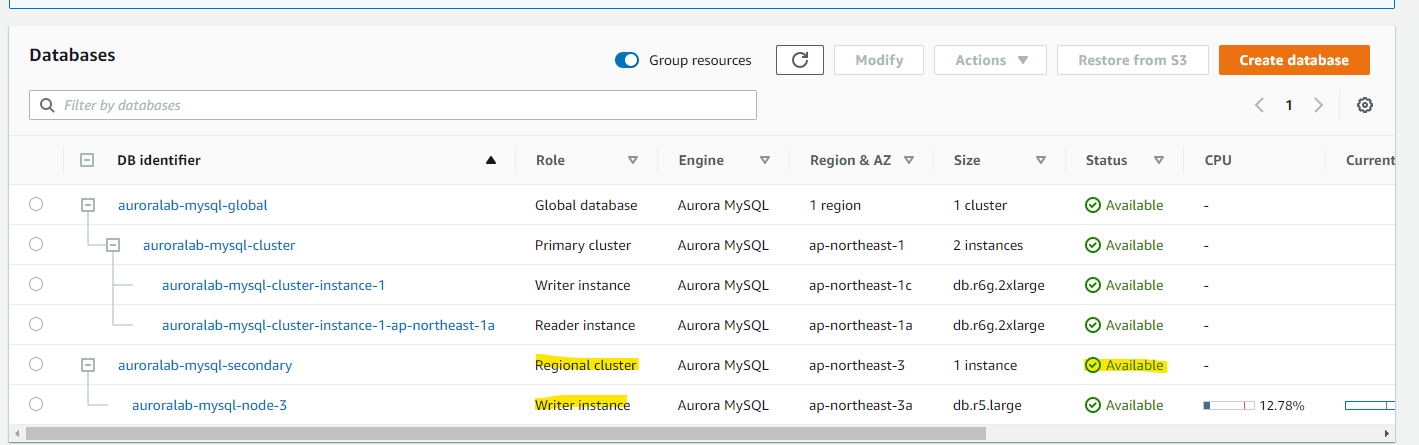
Writer Endpoint が inactive から Available に切り替わっています

MySQL のセッションが切れているので、Writer Endpoint に接続します。いままでは Reader Endpooint を使っていましたが、ここからは Writer の方に切り替わります。
mysql -u administrator -h auroralab-mysql-secondary.cluster-cz7qyris6ivy.ap-northeast-3.rds.amazonaws.com -p
データの確認です
USE mybank;
データがあります。
mysql> SELECT * from failovertest1;
+----+------------+----------------+---------------------+
| pk | gen_number | some_text | input_dt |
+----+------------+----------------+---------------------+
| 1 | 100 | region-1-input | 2023-01-01 12:03:04 |
+----+------------+----------------+---------------------+
1 row in set (0.00 sec)
Promote したので、Insert が可能となっています。
INSERT INTO failovertest1 (gen_number, some_text, input_dt)
VALUES (200,"region-2-input",now());
データの中身が更新されています。
mysql> SELECT * from failovertest1;
+----+------------+----------------+---------------------+
| pk | gen_number | some_text | input_dt |
+----+------------+----------------+---------------------+
| 1 | 100 | region-1-input | 2023-01-01 12:03:04 |
| 2 | 200 | region-2-input | 2023-01-01 12:56:38 |
+----+------------+----------------+---------------------+
2 rows in set (0.00 sec)
検証を通じてわかったこと
-
Primay Region で書き込みされたデータは、リアルタイムに Secondary 側に反映される。
-
Aurora Global Database のリージョン間レプリケーションは非同期となる。そのためレプリケーション Lag をモニタリングするのが良い。
-
Aurora Global Database のリージョン間フェールオーバーは、自動ではなく手動で行う。
-
Secondary 側は、Reader Endpoint のみ作成される。Writer Endpoint は作成されない。
- Write Forwarding 機能を利用すると、Secondary 側の Reader Endpoint でも書き込み処理の実行が可能 (DML のみ)
-
フェールオーバー (切り離しと Promote) を行うと、Secondary 側が通常の Cluster になり、Writer Endpoint が Available になる
- Secondary 側で動かすアプリケーションは、Writer Endpoint を利用して動かすことが可能。Write Forwarding 機能を使って Secondary 側でアプリケーションを動かしていた場合は、Endpoint の切り替えをする必要がある
- 切り離しと Promote を実施したタイミングで、Secondary 側のインスタンス側はセッションが切れるため、再度接続する必要がある。再接続のタイミングで Writer Endpoint に切り替えるのが良い
-
Primary Region と Secondary Region 間で、VPC Peering などのネットワークリーチャビリティは必要ない。Aurora の裏側で通信されている。
-
レプリケーションラグの情報は、Secondary Region 側のメトリクスにある。独自に CloudWatch Dashboard を作成して確認するのも良い
- Secondary Region のメトリクスを使ったダッシュボードは、Primary Region 側でも表示が可能
-
Write Forwarding 機能は、INSERT, UPDATE, DELETE などの DML で利用可能。CREATE TABLE といった DDL は、Secondary Region では実行できない。その代わり、Primary Region で実行する。
-
Write Forwarding 機能を利用するために、Aurora Cluster の設定を有効にする点に加えて、MySQL Session 上で読み取り整合性レベルの指定が必要。アプリケーション側で MySQL に接続するときにセッション変数を変更するような実装変更が必要になる。
-
以下、EVENTUAL を指定する例
-
SET aurora_replica_read_consistency = 'EVENTUAL';
-
-
Write Forwarding 機能では、読み取り整合性レベルを次の 3 つから指定可能。詳細は Document を参照。
- EVENTUAL : 古いデータが表示されるときがある。Secondary Cluster で書き込んだデータは、Primary Cluster に転送されるが、それが Secondary Cluster にレプリケーションされることを待機しない。待機しないので、レプリケーションが完了するまで、古いデータが表示されることがある。
- SESSION : そのセッションに限定して、レプリケーションされることを待機する。他のセッションやリージョンのレプリケーションは待機しない。そそのセッションに限定したレプリケーションを待機するので、追加の待ち時間が発生する場合がある。
- GLOBAL : すべてのリージョンや他のセッションのデータの更新を待機する。アプリケーションが使っていないセッションやリージョンの更新も待機するので、より追加の待ち時間が発生しやすい。
- https://awsauroralabsmy.com/global/wfwd/#4-test-consistency-modes-with-a-simple-application
- https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/aurora-global-database-write-forwarding.html#aurora-global-database-write-forwarding-isolation
-
EVENTUAL, SESSION, GLOBAL の使い分け例
- EVENTUAL
- 直後の読み取りが不要な場合、または他の手段でカバーできる場合は、EVENTUAL を使用します。これにより、Secondary Region の読み取りが常に高速になり、最終的な一貫性のある整合性を使用できます。
- 一例として、注文処理ワークフローがあります。eコマースのユースケースを考えると、顧客が注文を出すと、アプリケーションは注文確認画面で応答します。このとき、データセットの読み込みに強い一貫性がなくても、データベースへの書き込みが成功したことを確認できれば、通常は十分です。
- 別の例として、ユーザープロファイルの更新ワークフローがあります。ユーザープロファイルサービスがある場合、顧客がプロファイルを更新するとき、変更が保存されたことを確認できれば、通常は十分です。例えば、エンドユーザーがパスワードを更新しても、そのパスワードは表示されません。さらに、ユーザーが新しく設定されたパスワードを使用するためにインターフェイスをナビゲートするのに数秒かかりますが、これはデータベースがその変更の整合性に到達する時間を可能にします。
- SESSION
- セッション読み取り一貫性モードは、直後の読み取り精度が必要で、変更されたデータをアプリケーション側でキャッシュするなど、他の手段では達成できない場合に使用します。
- 金融アプリケーションは、一般的にセッションレベルの読み取り一貫性の良い候補です。ユーザーは、前のトランザクションの結果を基に、複数のトランザクションを実行することがあります。この場合、エンドユーザーは通常、変更要求の結果としてシステムが何らかの作業を行うことを期待しているので、変更の結果、読み取りが比較的遅くなることは、一般的に許容されます。
- GLOBAL
- グローバルに強い読み取り一貫性が必要な場合は、GLOBAL 読み取り一貫性モードを使用します。このモードを使用すると、アプリケーションを簡素化し、一貫性に特化した実装を避けることができますが、データがグローバル一貫性に到達するのを待つ必要があるため、クエリの応答遅延が大きくなり、ほとんどの使用例には適していない可能性があります。
- 取引アプリケーションやオークション・ワークフローでは、すべての参加者が任意の時点のデータの状態を正確に把握できることが機能上重要であり、この一貫性モードは適しています。
- EVENTUAL
参考 URL