はじめに
初めまして、人工知能を学んでいる大学4年生です。
初めてのQiita投稿です。よろしくお願いします。
本記事の内容
タイトルの通り逆強化学習でATARIに挑戦するための準備を行いたいと思います。
具体的には
- Windows上でのATARIの環境構築
- データセット「The Atari Grand Challenge Dataset」の準備
- Behavior Cloning の実装
を行いたいと思います。
一つ目に関してはネット上に多くの記事がありましたが、少し詰まったので備忘録的に残しておきます。
動作環境
本記事における動作環境です。
- Windows 10 HOME
- anaconda 4.2.0
- Python 3.5.5
- Keras 2.1.6
- tensorflow-gpu 1.8.0
- gym 0.10.5
※ 詳しい動作環境は、githubでご覧ください.
逆強化学習とは
通常の強化学習では、エージェントが環境から報酬を受け取り、その報酬を最大化するように学習することによって、最適な行動ルールを学習します。
しかし、このような報酬の設計が困難である場合があります。
そのような場合に、上手な行動をするエキスパートの行動系列から報酬関数を推定する手法を逆強化学習といいます。
逆強化学習に関してはこちらのスライドが大変わかりやすいです。
TensorFlowで逆強化学習
https://www.slideshare.net/ohtaman/tensor-flow-63359654
ATARIの環境構築
こちらの記事の通りにすれば、OpenAIGymでのATARI環境が構築できます。
OpenAI Baselinesをwindows(winpython)で試す。
https://qiita.com/tmizu23/items/ff1d5c89bc99292410c0
Bash on Ubuntu on Windowsを使う方法もありますが、その場合は GPU が使用できなくなってしまうので注意が必要です。
手順を要約すると
- makeを使えるようにする
- pipでATARIをインストール
です。
makeを使えるようにする
先ほどの記事では msys2 をインストールしていました。
それでも問題ありませんが make さえ使えればいいので Make for Windows をインストールする方が簡単だと思います。
こちらの記事の通りにすれば、make が使えるようになります。
Windowsでmakeコマンドを使う
https://qiita.com/tokikaze0604/items/e13c04192762f8d4ec85
コマンドプロンプトの再起動は忘れないようにしましょう。
pipでATARIをインストール
まず、pip で gym をインストールします。
pip install gym
この時点では、まだATARIはインストールされていません。
続いて、pip で gym[atari] をインストールします。以下のコマンドを実行してください。
pip install -U git+https://github.com/Kojoley/atari-py.git
これでATARIの環境が構築できました。
※注意
pip install gym[atari]
としてしまうと、
Failed building wheel for atari-py
とエラーになります。(記事はちゃんと読まないとダメですね…)
動画保存
gym で動画を保存するには FFmpeg が必要なので
こちらからダウンロードしてインストールしてください。
こちらの記事に詳しい手順が解説されていました
ffmpegのインストール
http://simple.hatenablog.jp/entry/DTV/ffmpeg-Installation
The Atari Grand Challenge Dataset
The Atari Grand Challenge Datasetは、ATARIゲームのうち5つのゲームの状態(画像)と対応する行動のデータセットです。
こちらの本家サイトのエミュレータによって、プレイデータを収集したそうです。
2018年8月現在、このデータセットは v2 でした。
含まれているゲームは
- Space Invaders
- Q*bert
- Ms. Pacman
- Video Pinball
- Montezuma's Revenge
です。
論文はこちらです。
The Atari Grand Challenge Dataset
https://arxiv.org/pdf/1705.10998.pdf
データセットのダウンロード
こちらのページの一段落目の download からダウンロードできます。
特定のゲームのデータだけをダウンロードしたい場合は、こちらのGitHubか先ほどのページの二段落目の here からダウンロードできます。(ただし、こちらのデータセットはどうやら v1 のようです。)
データセット全体で25GByte以上あるため、ダウンロードにかなりの時間を要するので注意してください。
このデータセットはtarとgzで圧縮されているので、7-Zipなどを用いて解凍してください。この解凍にもかなりの時間を要するので頑張ってください。解凍後のデータセットは90GByte近くあるため、解凍場所はきっちり指定しましょう。
データセットの概要
データセットの内容は下の表のようになっています。

論文に記載されている v1 よりもエピソード数が増加しています。しかし、ベストスコアがなぜか下がっていました。
スコアの分布はそれぞれ下の表のようになっていました。
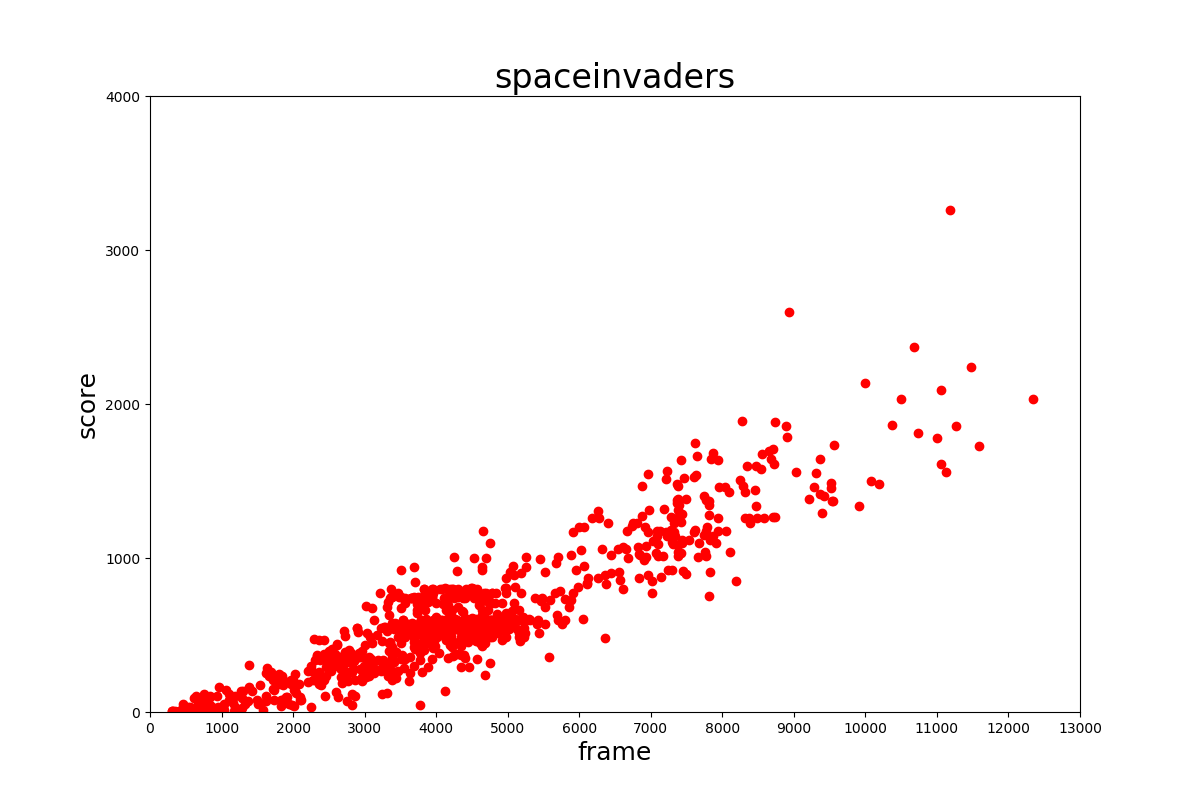
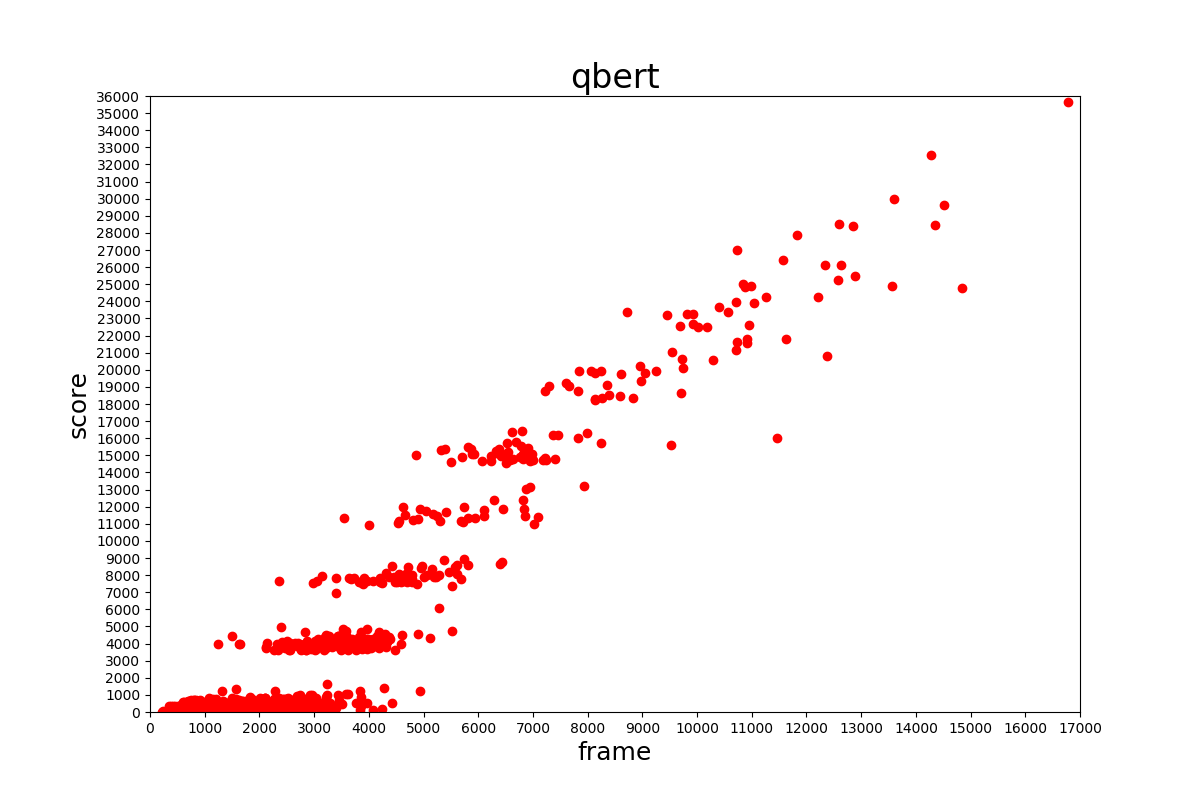
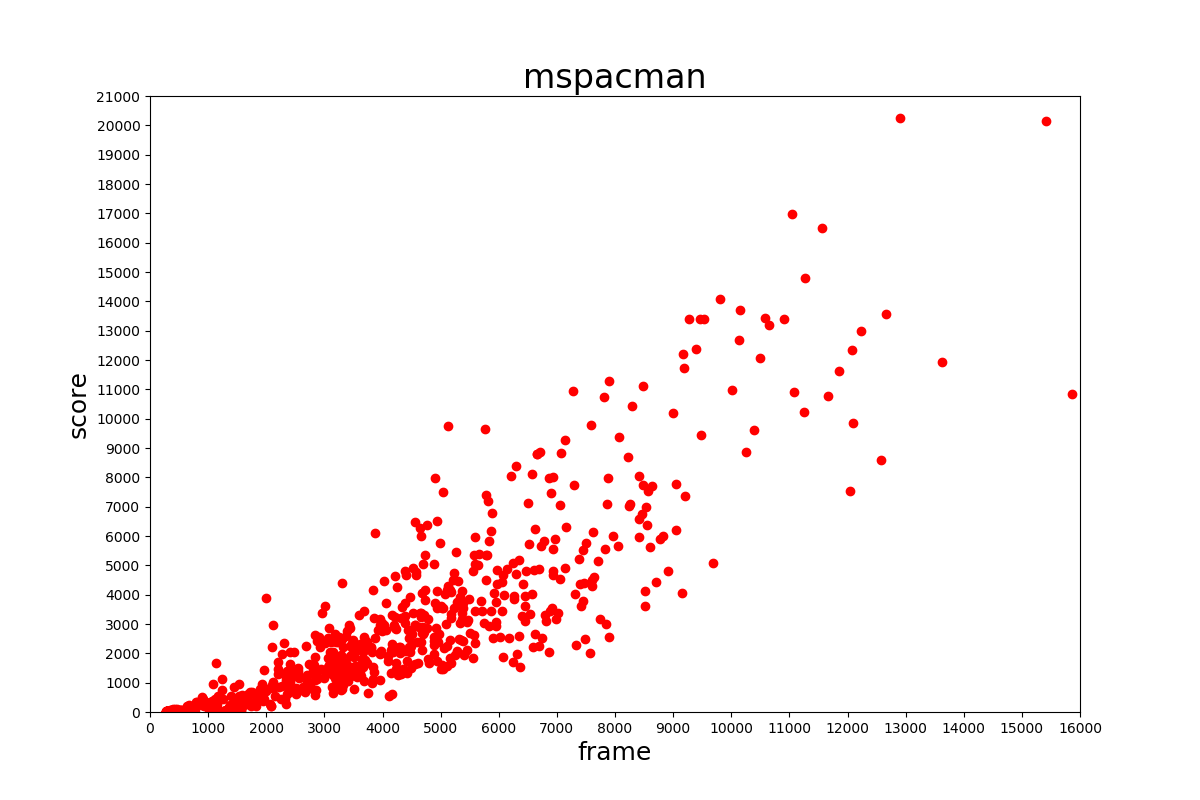
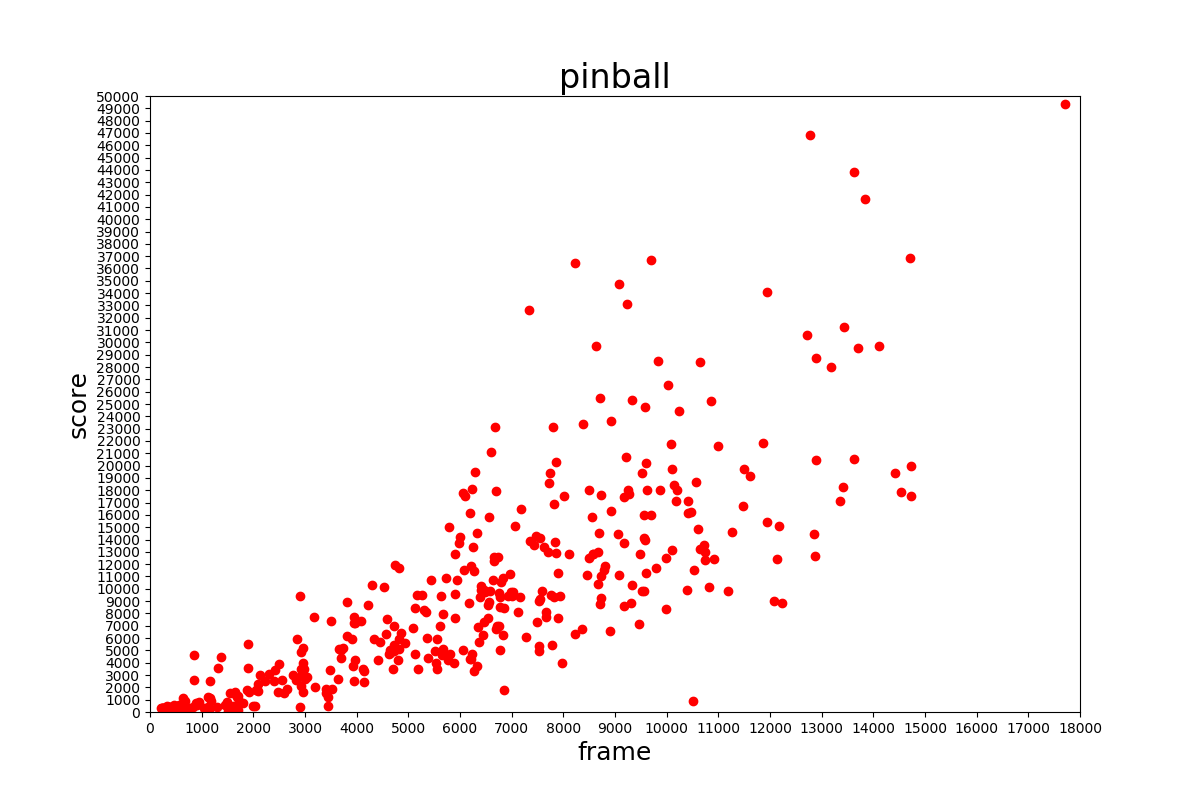
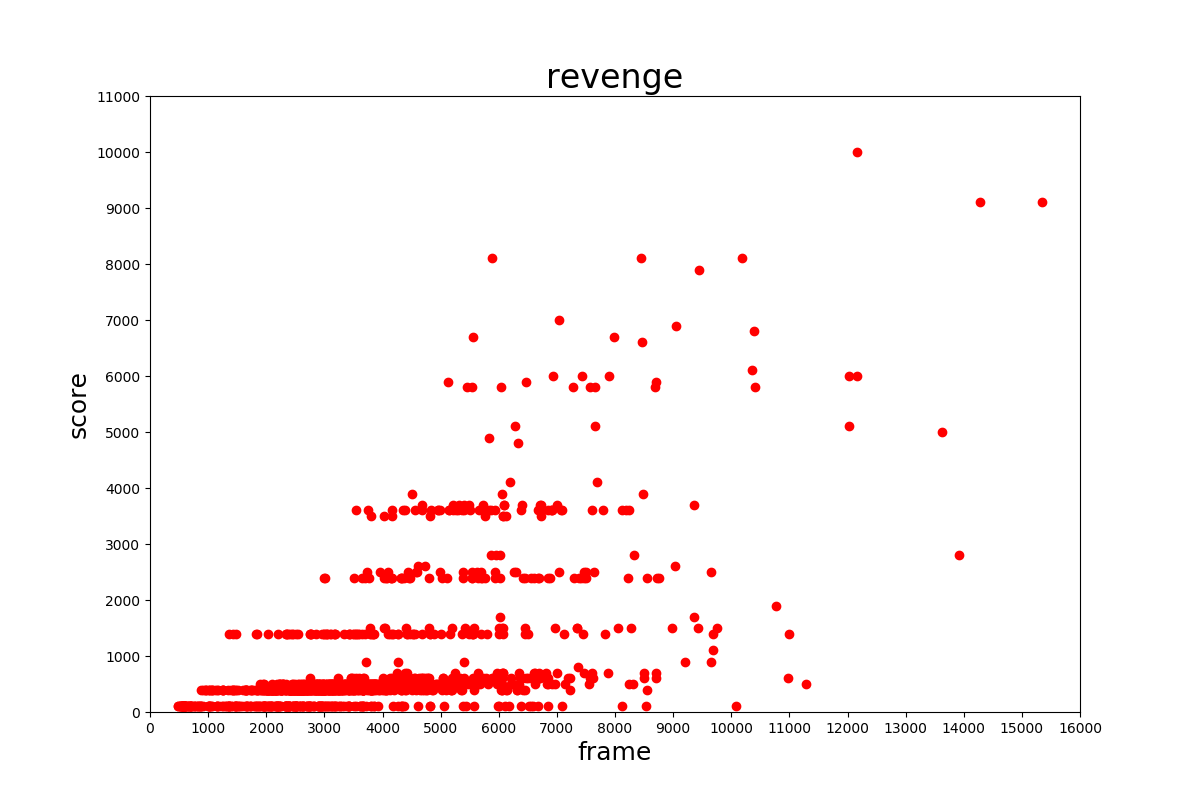
おそらくネット上のエミュレータで収集しているためだと考えられますが、低い得点が多いように見られます。このデータセットを学習に用いる場合はスコアの高いものだけ用いるようにする必要があるでしょう。
データセットの構成
ディレクトリ構成
解凍後のディレクトリ構成は以下のようになっています。
/atari_v2_release/
├── screens
│ ├── mspacman
│ ├── pinball
│ ├── qbert
│ ├── revenge
│ └── spaceinvader
└── trajectories
├── mspacman
├── pinball
├── qbert
├── revenge
└── spaceinvader
screens フォルダ内のそれぞれのフォルダには episode ごとのフォルダが入っており、その中にはフレーム番号がつけられた画像ファイルが入っています。trajectories フォルダ内には episode ごとの txt ファイルが入っています。
データフォーマット
trajectories フォルダ内の txt ファイルのフォーマットは csv 形式であり。以下のようになっています。
frame,reward,score,terminal,action
一行目はおそらくデータベースで割り振られたIDであり、関係ないので無視してかまわないでしょう。(何のためにあるのか分からないです…)
csv の要素はそれぞれ
- frame はフレーム番号
- reward はそのフレームで得られた報酬
- score はそのフレームでの得点
- terminal は終了状態なら1それ以外なら0
- action はそのフレームの行動
です。
学習に用いるのは frame と action のみです。
screenはどのゲームであっても 160x210 の png ファイルです。

actionのエンコード
このデータセットの action のエンコードは
| name | action |
|---|---|
| NOOP | 0 |
| FIRE | 1 |
| UP | 2 |
| RIGHT | 3 |
| LEFT | 4 |
| DOWN | 5 |
| UPRIGHT | 6 |
| UPLEFT | 7 |
| DOWNRIGHT | 8 |
| DOWNLEFT | 9 |
| UPFIRE | 10 |
| RIGHTFIRE | 11 |
| LEFTFIRE | 12 |
| DOWNFIRE | 13 |
| UPRIGHTFIRE | 14 |
| UPLEFTFIRE | 15 |
| DOWNRIGHTFIRE | 16 |
| DOWNLEFTFIRE | 17 |
となっています。
すでにお気づきの方も多いと思いますが、OpenAIGym の action のエンコードと一致していません。
例えば Ms. Pacman のエンコードは
| name | action |
|---|---|
| NOOP | 0 |
| UP | 1 |
| RIGHT | 2 |
| LEFT | 3 |
| DOWN | 4 |
| UPRIGHT | 5 |
| UPLEFT | 6 |
| DOWNRIGHT | 7 |
| DOWNLEFT | 8 |
となっています。
actionのエンコードは下のコードを実行すると
import gym
env = gym.make('MsPacman-v0')
print(env.env.get_action_meanings())
['NOOP', 'UP', 'RIGHT', 'LEFT', 'DOWN', 'UPRIGHT', 'UPLEFT', 'DOWNRIGHT', 'DOWNLEFT']
のように取得できます。
さらに、Ms. Pacman のデータセット全体のactionの回数は以下の表のようになっています。
| name | action_count |
|---|---|
| NOOP | 1430493 |
| FIRE | 2595 |
| UP | 300404 |
| RIGHT | 380917 |
| LEFT | 379688 |
| DOWN | 269034 |
| UPRIGHT | 14160 |
| UPLEFT | 13151 |
| DOWNRIGHT | 12775 |
| DOWNLEFT | 12612 |
| UPFIRE | 2977 |
| RIGHTFIRE | 3811 |
| LEFTFIRE | 3109 |
| DOWNFIRE | 2587 |
| UPRIGHTFIRE | 289 |
| UPLEFTFIRE | 0 |
| DOWNRIGHTFIRE | 356 |
| DOWNLEFTFIRE | 110 |
この表を見ればわかるように、データセットにはゲーム側に存在しないactionが含まれています。
これに気を付けないと正しく学習できない、もしくはエラーになる可能性があります(というかなりました)。
※注意
score の値はゲーム画面に表示されていた値と 1 ずれていることがありました(エミュレータのバグ?)。
最終フレームであっても terminal は 1 になっていませんでした(この要素いらないのでは…?)。
データセットの読み込み
scoreでソート
先ほど述べた通り、このデータセットを用いる時には、score の高いものだけを選んで使う方が良いと考えられるので、最終フレームの scoreで trajectories のファイルをソートしました。
最終フレームのスコアを読み込むにはtrajectoriesの最終行だけ読めばいいので、
traj_score = []
for traj in os.listdir(path + '/trajectories/' + GAME_NAME):
f = open(path + '/trajectories/' + GAME_NAME + '/' + traj, 'r')
end_data = f.readlines()[-1].split(",")
#[フォルダ名, 最終スコア]
traj_score.append([os.path.splitext(traj)[0], int(end_data[2])])
f.close()
# スコアでソート
traj_score = sorted(traj_score, key=lambda x:x[1], reverse=True)
として、scoreで降順にソートすればいいでしょう。
pathはデータセットのフォルダのパス、GAME_NAMEはゲームのフォルダ名です。
trajectories読み込み
trajectories フォルダの txt ファイルは csv 形式なので pandas 等を使って簡単に読み込むことができます。
先ほどscoreで降順に並び替えたので、データセットの使用する割合を p に格納して
for traj_num, _ in traj_score[:int(len(traj_score)*p)]:
print("Now Loading : %s" % traj_num)
# データロード
df = pd.read_csv(path + '/trajectories/' + GAME_NAME + '/' + traj_num + '.txt', skiprows=1)
としました。先ほど説明した通り、一行目は無視しています。
screens読み込み
screensのフォルダ名とtrajectoriesのファイル名が対応しており、画像名はフレーム番号なので先ほど読み込んだデータフレームを使えばいいのですが、少し問題が生じました。
私のPCのメモリは 16GB なのですが、生の画像データをすべて読み込んでから処理を行おうとするとメモリリークが発生し、処理速度が著しく低下してしまいました。
なので、読みこむ段階で学習のための前処理を行うことで、データサイズを小さくしました。
前処理
前処理はこちらのサイトを参考にして行いました。
DQNをKerasとTensorFlowとOpenAI Gymで実装する
http://elix-tech.github.io/ja/2016/06/29/dqn-ja.html
行った前処理は
- 84x84 にリサイズ
- グレースケールに変換
- 4フレームを結合
です。
1と2は計算コストとメモリ削減のための前処理です。
3を行う理由はATARIにはスプライト数の上限があり、偶数フレームか奇数フレームのどちらかにしか出現しないオブジェクトがあるからです。
コードは以下になりました。
def preprocess(status, tof=True, tol=True):
"""状態の前処理"""
def _preprocess(observation):
"""画像への前処理"""
# 画像化
img = Image.fromarray(observation)
# サイズを入力サイズへ
img = img.resize(INPUT_SHAPE)
# グレースケールに
img = img.convert('L')
# 配列に追加
return np.array(img)
# 状態は4つで1状態
assert len(status) == FRAME_SIZE
state = np.empty((*INPUT_SHAPE, FRAME_SIZE), 'int8')
for i, s in enumerate(status):
# 配列に追加
state[:, :, i] = _preprocess(s)
if tof:
# 画素値を0~1に正規化
state = state.astype('float32') / 255.0
if tol:
state = state.tolist()
return state
最終的なコード
前処理も含めた最終的な読み込みのコードです。
結合したフレームに対応するactionは結合したフレームの内で一番最後のフレームのactionとしました。
# 軌道ごとに記録する配列
status_ary = []
action_ary = []
for traj_num, _ in traj_score[:int(len(traj_score)*p)]:
print("Now Loading : %s" % traj_num)
# データロード
df = pd.read_csv(path + '/trajectories/' + GAME_NAME + '/' +traj_num + '.txt', skiprows=1)
traj_list = [np.array(Image.open(path + '/screens/' + GAME_NAME + '/' + traj_num + '/' +img_file + '.png', 'r'))
for img_file in tqdm(df['frame'].astype('str').values.tolist())]
act_list = df['action'].astype('int8').values.tolist()
# 前処理
print("Now Preprocess : %s" % traj_num)
status = np.concatenate([preprocess(traj_list[i:i+frame_size], frame_size, False, False)[np.newaxis, :, :, :]
for i in tqdm(range(len(traj_list) // frame_size))], axis=0)
action = [act_trans_list[act_list[i+(frame_size-1)]] for i in tqdm(range(len(traj_list) // frame_size))]
status_ary.append(status)
action_ary.append(np.array(action))
#メモリ対策
del traj_list
del act_list
del status
del action
軌道ごとに読み込みlistに格納していますが、画像をlistで格納するとメモリリークを起こしたので、データサイズを比較的小さくできるint8型のnumpyで格納するようにしています。del でメモリ開放していますが気休め程度だと思います。
tqdmはプログレスバーを出力するためのパッケージです。
そして、最後に以下のコードによってすべてのepisodesの軌道を結合し、float32型に変換した上で正規化します。
# numpy展開
print("Now Concatenate")
status = np.concatenate(status_ary, axis=0)
del status_ary
action = np.concatenate(action_ary, axis=0)
del action_ary
# 状態正規化
status = status.astype('float32') / 255.0
print("End Concatenate")
これで、データセットの読み込みができました。
Behavior Cloning
データセットの有効性を確認するために、このデータセットを用いて学習を行いました。
実装の容易さから、デモンストレーションのデータのstateを入力、actionを出力として教師あり学習を行う、Behavior Cloningを実装しました。
Atari環境
今回扱うゲームは「Q*bert」にしました。(特に理由はありません)
Q*bert の action のエンコードは
| name | action |
|---|---|
| NOOP | 0 |
| FIRE | 1 |
| UP | 2 |
| RIGHT | 3 |
| LEFT | 4 |
| DOWN | 5 |
でした。
環境の名前について
OpenAIGym においてAtari環境を利用する場合、同じゲームに異なる名前の環境が存在します。
基本的には {}NoFrameskip-v4 という名前になっている環境を使うべきだそうです。
そうしないと
- 環境側でフレームスキップが発生する
- 行動の繰り返しが行われる
らしいです。
こちらの記事に詳しい解説がありました
OpenAI Gym の Atari Environment の命名規則と罠について
https://qiita.com/keisuke-nakata/items/141fc53f419b102d942c
モデル
モデルの構造は以下のようにしました。
| Layer | Filter size | Num Filters | Stride | Activation |
|---|---|---|---|---|
| Conv2D | 8x8 | 64 | 4x4 | ReLU |
| Conv2D | 4x4 | 64 | 2x2 | ReLU |
| Conv2D | 3x3 | 64 | 1x1 | ReLU |
| Dense | 512 | ReLU | ||
| Output | num actions | SoftMax |
学習パラメータなど
学習に用いたパラメータ・学習則は以下の通りです。
- BatchSize 128
- Epoch 20
- Adam
- lr 0.001
- beta_1 0.9
- beta_2 0.999
- epsilon None
- decay 0.0
実験
データセットを使用する割合が1%と5%それぞれにして、学習を行いました。
10%で学習を行おうとしたところ、メモリリークが発生して学習できませんでした。学習を行ったコンピュータのメモリは16GBです。
action の変換は以下の表で行いました。(これでいいかは不明)
| name | action_count |
|---|---|
| NOOP | NOOP |
| FIRE | FIRE |
| UP | UP |
| RIGHT | RIGHT |
| LEFT | LEFT |
| DOWN | DOWN |
| UPRIGHT | UP |
| UPLEFT | UP |
| DOWNRIGHT | RIGHT |
| DOWNLEFT | LEFT |
| UPFIRE | UP |
| RIGHTFIRE | RIGHT |
| LEFTFIRE | LEFT |
| DOWNFIRE | DOWN |
| UPRIGHTFIRE | UP |
| UPLEFTFIRE | UP |
| DOWNRIGHTFIRE | RIGHT |
| DOWNLEFTFIRE | LEFT |
試行ごとのブレが大きかったので、それぞれ3回の実験結果を載せました。
データセット1%利用
学習に用いたデータの分布は以下のようになっていました。

最上位層のみのデータを利用している形になっています。
学習した結果は以下のようになりました。



| 左 | 中 | 右 |
|---|---|---|
| 400 | 0 | 125 |
試行ごとにブレていますが、飛び降りたりせず得点を得ているので、学習はできているように見えます。
データセット5%利用
学習に用いたデータの分布は以下のようになっていました。
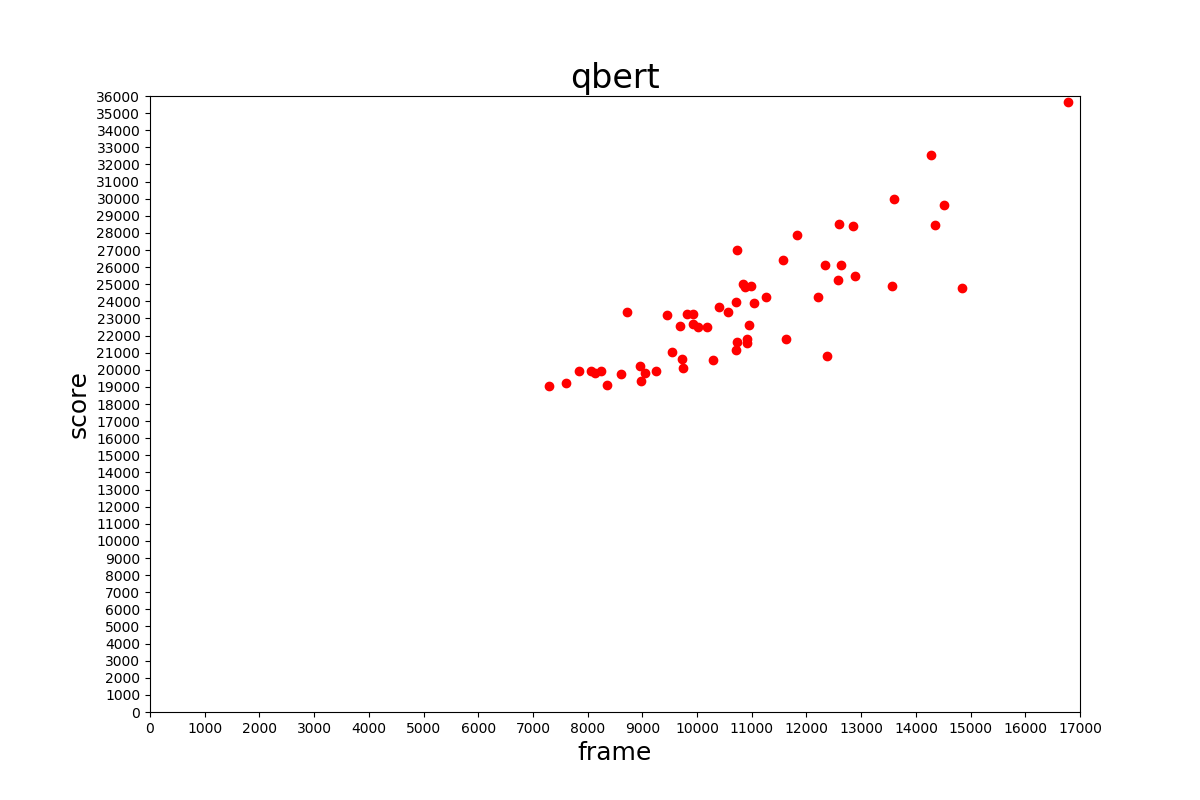
1%の時よりデータ数は増えていますが、比較的得点の低いデータも学習に用いる形になっています。
学習した結果は以下のようになりました。
| |
| |
| |
|
| 左 | 中 | 右 |
|---|---|---|
| 3775 | 0 | 0 |
1%の時と比べて、高い得点を取れている場合もありますが、全く動かない場合も増えてしまいました。
原因
動かなくなってしまう原因を調べるために学習したデータのactionの回数を表にしました。
| NOOP | FIRE | UP | RIGHT | LEFT | DOWN |
|---|---|---|---|---|---|
| 103628 | 4 | 10277 | 14548 | 9227 | 13928 |
この表を見ればすぐ分かるように、何もしない行動である「NOOP」が突出して多いのが動かなくなってしまった原因だと考えられます。
Class Weight 使用
偏りのあるデータで学習するためにactionの回数が少ないほど大きな重みをかけるようにしました。
以下のコードでそれぞれの重みを計算しました。
unique, count = np.unique(action, return_counts=True)
weight = np.max(count) / count
weight = dict(zip(unique, weight))
Class_Weightを使って学習した結果は以下のようになりました。



| 左 | 中 | 右 |
|---|---|---|
| 450 | 4275 | 500 |
動かないことはなくなり、ちゃんと学習できているようです。
データセット1%利用(Class_Weight有り)
1%の時でもactionに偏りがあるはずなので調べてみると
| NOOP | FIRE | UP | RIGHT | LEFT | DOWN |
|---|---|---|---|---|---|
| 26454 | 0 | 2820 | 2502 | 1594 | 2989 |
このように大きく偏っていたので先ほどと同様に重みを付けて学習しました。



5%の時と大きな差が無いような結果になりました。
まとめ
使用する割合を増やせば良くなるかと思っていましたが、必ずしもそんなことは無いようです。それよりも試行によるブレの方が大きいように感じました。
やはり単純に教師あり学習をするだけでは、何もないのに動かなくなったり、敵に自分から突っ込んでいってしまったりするようです。
まとめと感想
ここまで読んでいただいた方、本当にありがとうございました。
Qiitaどころか記事を書くのも初めてなのでかなり大変でした。(Markdownとかgifとか)
本当は逆強化学習までやってから1つの記事としてまとめるつもりだったんですが、バグを直したりいろいろしていたら脱線が長くなってしまったので、ここで一度切らせていただきます。
続きは近いうちに投稿できたらと思っています。(実装もまだですが)
この記事が何かしらのお役に立てれば幸いです。
おまけ
ここまで、Qbert を対象に学習を行ってきましたがネット上には、Qbert を対象にした強化学習の記事が無かったのでDQNで Q*bert をやりたいと思います。
と言ってもkeras-rlのexampleにAtariをDQNで解くサンプルがあったので、ほとんどそれを使うだけです。
keras-rl
kerasを用いて、DQNなどの深層強化学習を実装したライブラリです。
本家のGitHubはこちらです。
DQN以外にもDDPGなども使えるそうです。詳しくはこちら。
インストール
pipでインストールするだけです。
pip install keras-rl
動作環境
- keras-rl 0.4.2
他は上と同じです。
ソースコード
ソースコードは一応こちらに上げてあります。
このコードは、こちらにあるkeras-rlのexampleにコメントと動画の保存を追加しただけのものです。
特にソースコードの説明はしません。(するなら記事にします。)
結果
結果は以下のようになりました。

あまり、得点が取れていませんね……
学習に8時間くらいかかっているのですが、まだまだ学習が足りていないのかもしれないです。
Behavior Cloningと比べると機敏に動いている感じがします。Behavior Cloningはやはり多すぎる"NOOP"に学習が引っ張られているのかもしれません。
これで本当に終わりです。ありがとうございました。