動作環境
- 今回はDatabricks環境上で検証しています。記事作成時点(2020年11月)で最新RuntimeのDatabricks 7.4MLを利用しています
- 7.4MLクラスタの以下ライブラリを利用しています(初期インストール済)
- MLflow 1.11.0
- TensorFlow 2.3.1
- Keras 2.4.0
この記事の内容
- 以下をMLflowでトラッキングする
- MNISTをシンプルな3層レイヤーで学習させる
- MNISTをCNNで学習させる
- 最もAccuracyが高いモデルをModelレジストリに登録する
- ModelをProductionステージへ変更する
- モデルをロードして推論を実行する
MNISTをシンプルな3層レイヤーで学習させる
- 入力層に28×28pixelの手書き文字画像を入力
- 中間層に512個のノードを定義し、活性化関数は
reluを設定 - 出力は10種類(0から9まで)に分類する
- モデルパラメータ、メトリックをMLflowに登録
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
import mlflow
(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()
train_images = train_images.reshape((60000, 28, 28, 1))
test_images = test_images.reshape((10000, 28, 28, 1))
# ピクセルの値を 0~1 の間に正規化
train_images, test_images = train_images / 255.0, test_images / 255.0
with mlflow.start_run(run_name='keras-mnist'):
model = models.Sequential()
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dropout(0.2))
model.add(layers.Dense(10, activation='softmax'))
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
batch_size = 128
epoch = 5
model.fit(train_images, train_labels,
batch_size=batch_size,
epochs=epoch)
mlflow.log_param("batch_size", batch_size)
mlflow.log_param("epoch_num", epoch)
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
mlflow.log_metrics({'loss': test_loss})
mlflow.log_metrics({'accuracy': test_acc})
mlflow.keras.log_model(model, "keras-mnist")
MNISTをCNNで学習させる
- 同じMNISTの分類を畳み込みニューラルネットワーク(CNN)で学習させる
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
import mlflow
(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()
train_images = train_images.reshape((60000, 28, 28, 1))
test_images = test_images.reshape((10000, 28, 28, 1))
train_images, test_images = train_images / 255.0, test_images / 255.0
with mlflow.start_run(run_name='keras-mnist'):
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
epoch = 5
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(train_images, train_labels, epochs=epoch)
mlflow.log_param("epoch_num", epoch)
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
mlflow.log_metrics({'loss': test_loss})
mlflow.log_metrics({'accuracy': test_acc})
mlflow.keras.log_model(model, "keras-mnist")
最もAccuracyが高いモデルをModelレジストリに登録する
- ここまででMLflowトラッキングによりモデルの実験結果が以下のように管理されている
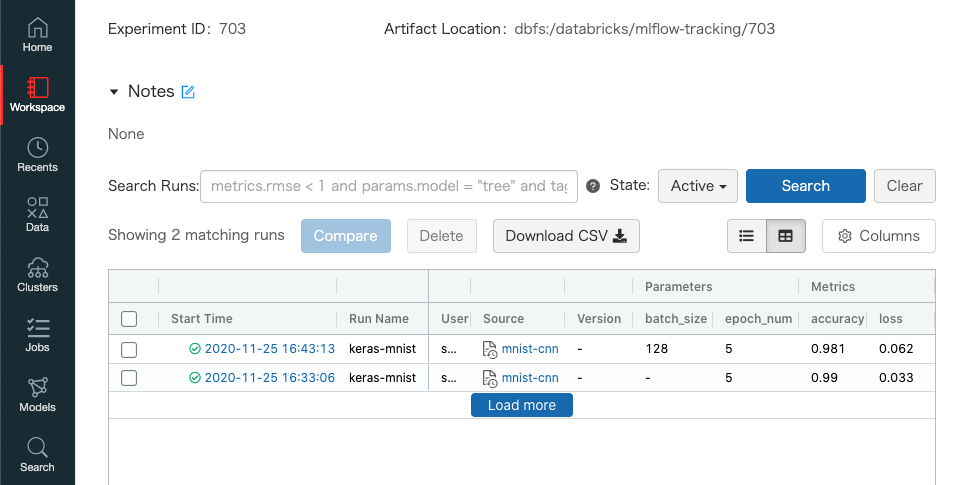
- MLflowのSearch APIでメトリクスのaccuracyが一番高いモデルのrun_idを取得
- 実際にはCNNで学習したモデルのほうが高いaccuracyとなっている
from mlflow.entities import ViewType
run_id = mlflow.search_runs(
filter_string='tags.mlflow.runName = "keras-mnist"',
run_view_type=ViewType.ACTIVE_ONLY,
max_results=1,
order_by=["metrics.accuracy DESC"]).iloc[0].run_id
- 取得したrun_idに紐づくモデルをModel Registryに登録する
model_name = "keras-mnist"
model_version = mlflow.register_model(f"runs:/{run_id}/keras-mnist", model_name)
ModelをProductionステージへ変更する
- 以下のクライアントAPIからモデルを
Productionステージに変更させる- クライアント実行ユーザーの権限でモデルのステージ変更が承認される
from mlflow.tracking import MlflowClient
client = MlflowClient()
client.transition_model_version_stage(
name=model_name,
version=model_version.version,
stage="Production"
)
モデルをロードして推論を実行する
- Model Registryから
Productionステージのモデルを取得して推論を実行する
import mlflow
from tensorflow.keras import datasets
model_name = "keras-mnist"
model = mlflow.keras.load_model(f"models:/{model_name}/production")
(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()
test_images = test_images.reshape((-1, 28, 28, 1))
result = model.predict(test_images[0:10])
print(result.argmax(axis=1))
- テストデータで推論させると以下となっている
[7 2 1 0 4 1 4 9 5 9]
- テストデータのラベルを可視化して確認してみると推論結果と一致した
import matplotlib.pyplot as plt
for i in range(10):
plt.subplot(1, 10, i+1)
plt.imshow(test_images[i].reshape(28,28))

最後に
- 前回のMLflow on Databricksを試してみたではDatabricksのNotebookからのMLflowでの運用方法を紹介しました。今回はAPIを利用した利用イメージを紹介してみました。