動作環境
- 今回 lightGBMを利用するので、記事作成時点(2020年11月)で最新RuntimeのDatabricks 7.4MLを利用しています
追加の外部ライブラリをインストールしたい場合
- クラスターの
Librariesタブからインストールすることが可能です(7.4MLは既にlightGBMがインストール済み)
MLflow Trackingでモデルの評価をする
- irisデータセットをlightGBMで学習させてみる。Databricksクラスターを起動後、Notebook上で以下のサンプルコードを実行してみます
- 以下では、自動トラッキングの有効化(
mlflow.lightgbm.autolog())をしているため、自動的にパラメータとメトリックがトラッキングされます。
- 以下では、自動トラッキングの有効化(
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, log_loss
import lightgbm as lgb
import mlflow
import mlflow.lightgbm
def train(learning_rate, colsample_bytree, subsample):
# データ準備
iris = datasets.load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# lightgbmの形式にする
train_set = lgb.Dataset(X_train, label=y_train)
# 自動トラッキング
mlflow.lightgbm.autolog()
with mlflow.start_run():
# モデルを学習する
params = {
"objective": "multiclass",
"num_class": 3,
"learning_rate": learning_rate,
"metric": "multi_logloss",
"colsample_bytree": colsample_bytree,
"subsample": subsample,
"seed": 42,
}
model = lgb.train(
params, train_set, num_boost_round=10, valid_sets=[train_set], valid_names=["train"]
)
# モデルの評価
y_proba = model.predict(X_test)
y_pred = y_proba.argmax(axis=1)
loss = log_loss(y_test, y_proba)
acc = accuracy_score(y_test, y_pred)
# log metrics
mlflow.log_metrics({"log_loss": loss, "accuracy": acc})
- 何回かパラメータを変更して実行してみます
train(0.1, 1.0, 1.0)
train(0.2, 0.8, 0.9)
train(0.4, 0.7, 0.8)
-
Notebookの右上の ①
Experimentアイコンをクリックすると実験結果②が表示されます
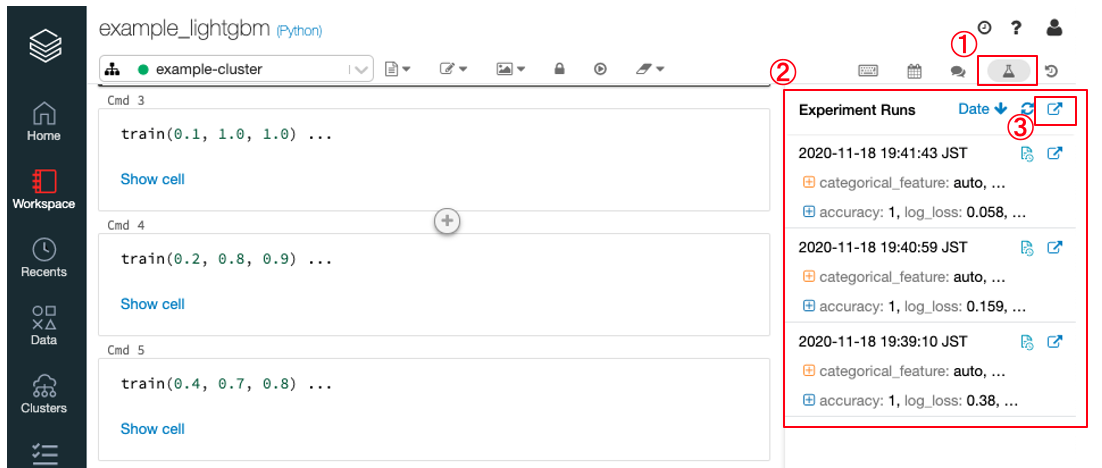
-
③のボタンをクリックすると実験結果一覧画面が表示されます
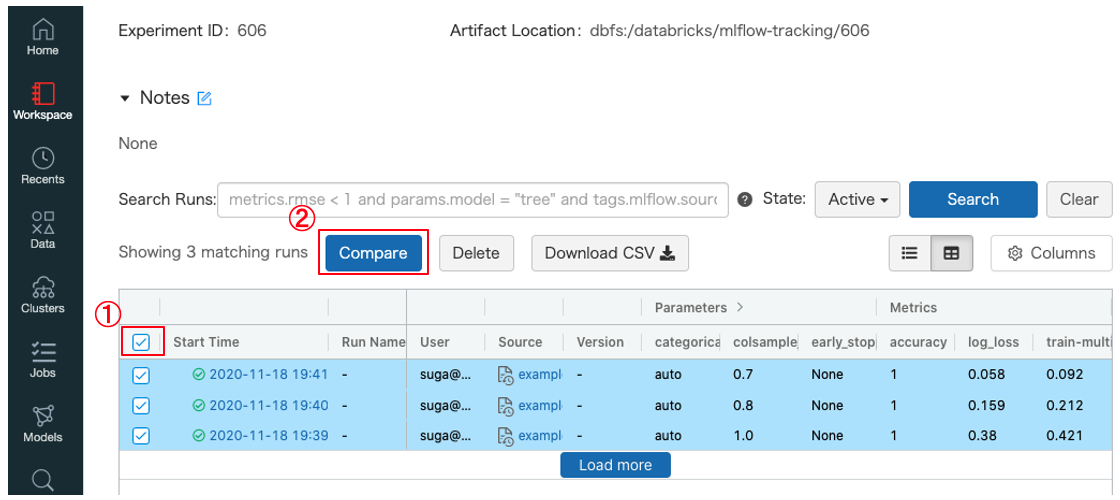
-
実験結果を全選択①して、
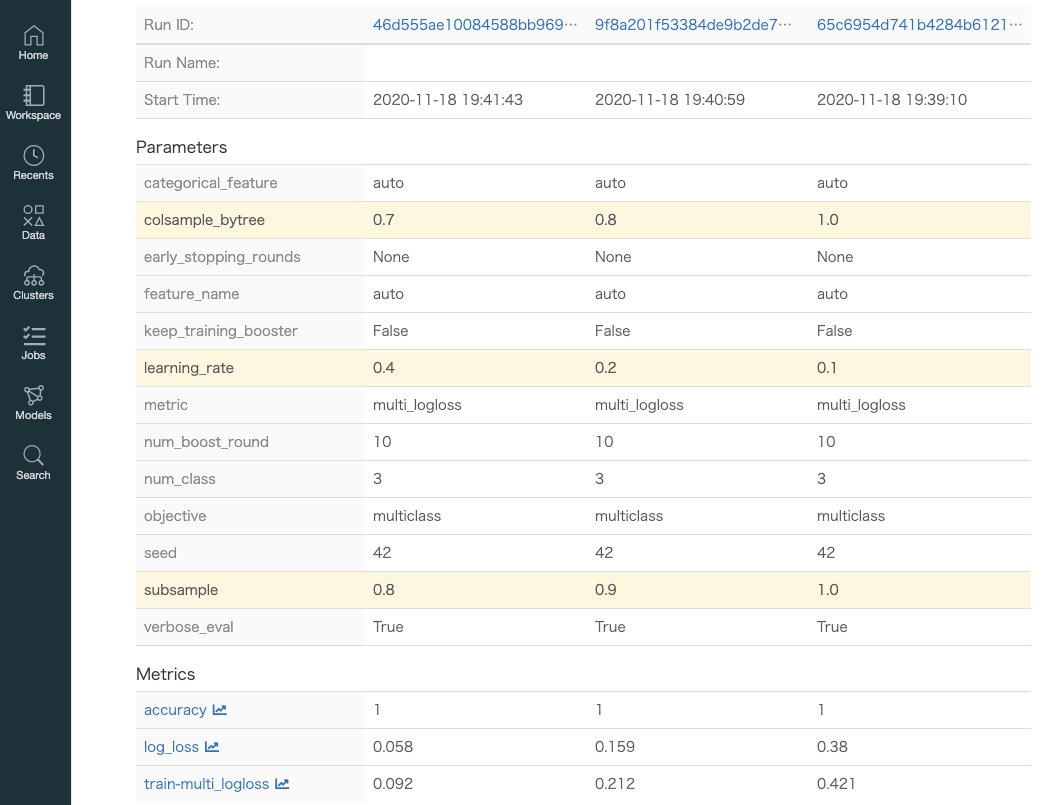
Compare②ボタンを押下すると実験結果の比較画面が表示されます(パラメータの差分と評価指標が一覧で比較することができる)
Model Registryにモデルを登録する
- MLflow Model Registry on Databricksは、モデルのバージョン、ステージ遷移(ステージングから本番への移行)、モデルの説明等をDatabricksのファイルシステム上で管理するモデルレジストリです
- 先ほどのモデル評価結果の比較画面のRunIDをクリックしてモデル詳細画面を表示します
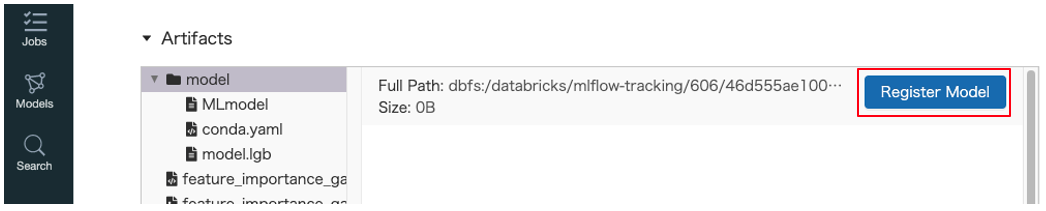
-
Artifactsの中のRegister ModelボタンをクリックすることでModel Registryへ登録するこができます
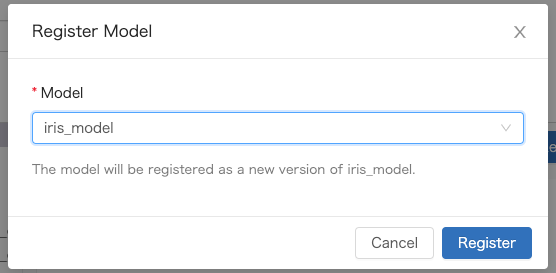
- 既存のモデル名を指定(version up)もしくは新規モデル名を入力します
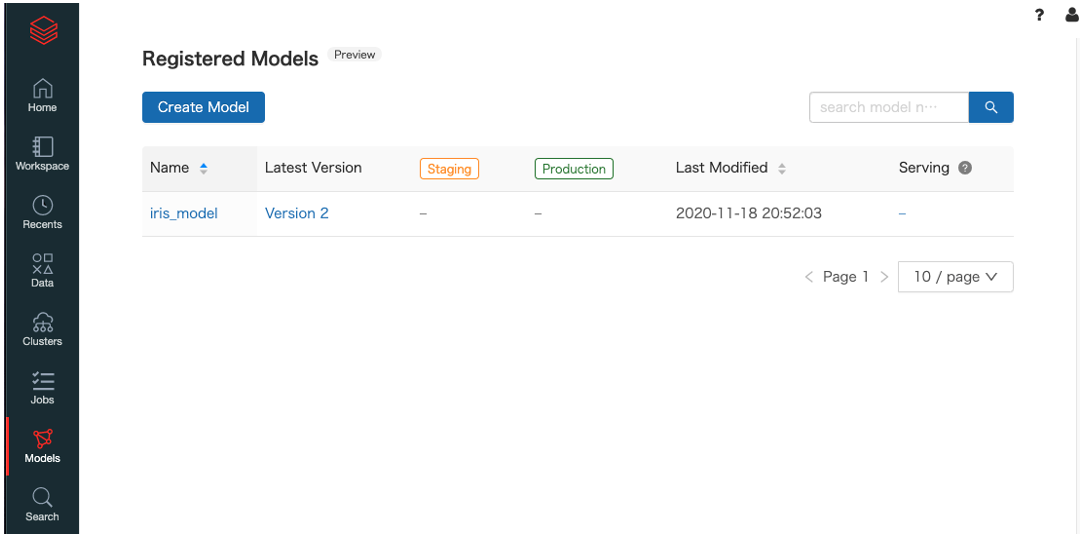
- 登録されたモデルは
Modelsタブから確認することができます
Model Servingを利用して推論APIを立ち上げる
-
MLflow Model Servingは モデルレジストリのモデルに対して有効にすると固有の単一ノードクラスタを自動的に作成されて、RESTエンドポイントとして利用することができます。モデルレジストリのバージョンとステージに基づいて自動的にデプロイされます
Modelのステージを変更する
-
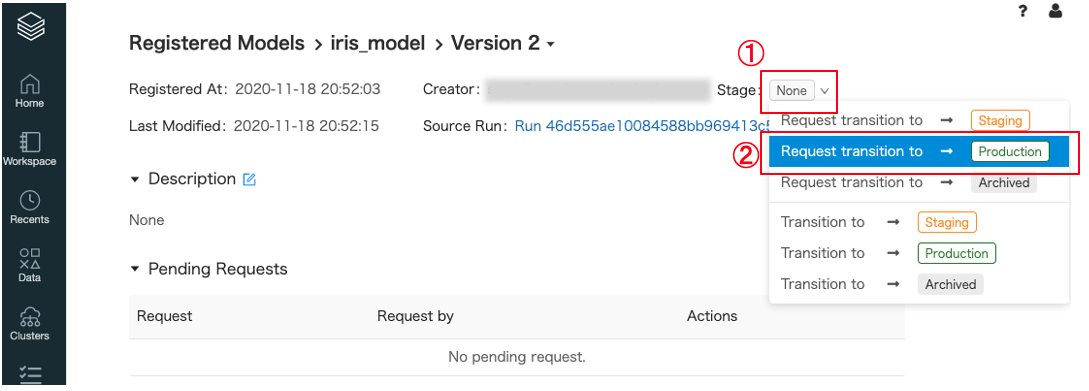
今回登録したモデルは
version 2、ステージはNoneとなっています。これからステージをProductionへ変更する要求をします -
モデルレジストリ画面から
version 2のモデル詳細画面に遷移してStage: None①をクリックして、Request transition to -> Production②をクリックします
-
別のユーザーのモデル詳細画面ではステージ変更要求が表示されています
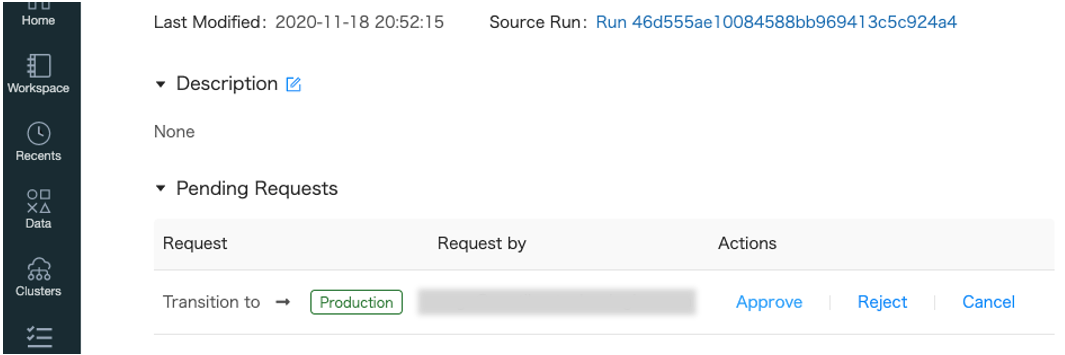
-
承認するとステージを変更することができます
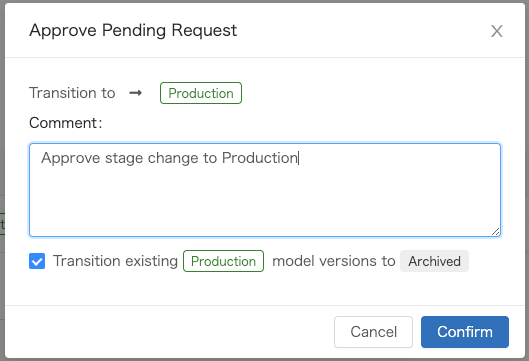
Model Servingを有効にする
-
モデルレジストリのモデル詳細画面の
ServingタブからEnable Servingボタンをクリックすることで有効化することができます
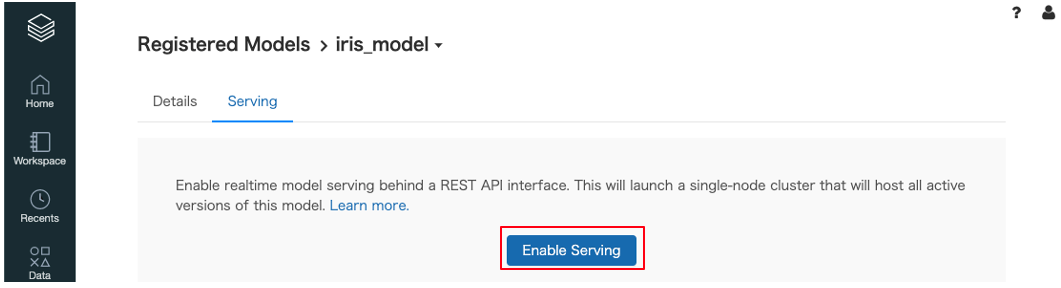
-
しばらくするとモデルバージョン、ステージ毎にRESTエンドポイントが起動されたことを確認できます
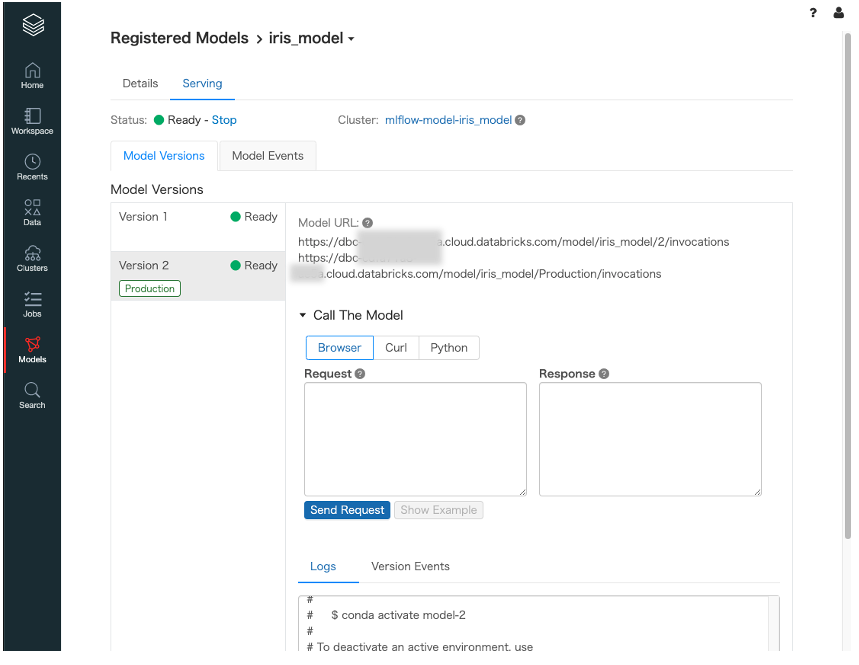
クライアント側からAPIを利用する
-
クライアント側からAPIにアクセスするために、セキュリティトークンを払い出してもらう必要があります
- 管理者アカウントの
User Setting画面からAccess Tokensタブから作成することができます
- 管理者アカウントの
-
curlからAPIを利用してみます
export DATABRICKS_TOKEN={トークン}
cat <<EOF > ./data.json
[
{
"sepal length(cm)": 4.6,
"sepal width(cm)": 3.6,
"petal length(cm)": 1,
"petal width(cm)": 0.2
}
]
EOF
curl \
-u token:$DATABRICKS_TOKEN \
-H "Content-Type: application/json; format=pandas-records" \
-d@data.json \
https://dbc-xxxxxxxxxxxxx.cloud.databricks.com/model/iris_model/Production/invocations
[[0.9877602676352799, 0.006085719008512947, 0.006154013356207185]]
最後に
- 今回はMLflowをDatabricksのNotebook上から利用できる機能について解説をしてみました。まだまだ紹介できていない機能もあるので、次回まとめてみたいと思います。