はじめに
この投稿はアイスタイル アイスタイル Advent Calendar 2017の25日目(最後!)の記事です。
どぉ~もみなさん、おはこんばんにちは!
I wish you a Merry Christmas♪
みなさん、クリスマスはいかがお過ごしですか?
大切な人と、家族と、友達と…。
様々なクリスマスがあると思います!
え?僕ですか?
楽しいひと時を過ごしましたよ!
Maria(DB)と…。
寂しくなんか…ないもん…(震え声
さて、今回は前回の続きとなります。
MariaDBのSPIDERストレージエンジンのフェデレーションの紹介とSPIDERノードの冗長化に関する検証を行っていきたいと思います!
おさらい(目指している環境)
今、僕が実現させていきたいと目指している環境の縮図はこちらです。
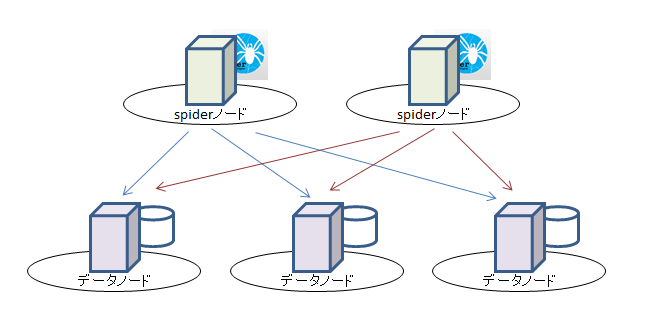
最近特に聞く話で「マイクロサービス化」というテーマがあります。
サービス単位でアプリケーション、DBのサーバを纏め、サービス同士が密結合しないような構成にしよう、というものです。
そうした場合、DB側で発生するものはというと、別のサーバにあるDBのテーブルを参照したいという要求を解決しなくてはならない事が多いと思います。
この問題を実現するために、レプリケーションを使って別サーバとデータを同期させて…なんていう対応はよくあると思います。
でもこれには、データ量が増えていく&レプリケーションさせたいテーブルが増えていくと、
今度はレプリケーションに負荷がかかることでデータの同期遅延が発生し、
結局は解決できなくなって有耶無耶に…なんて話になりがちです。
「これ、ちょっとレプ(リケーション)してくんない?」とさらっと言われて「そんなに簡単に言うなよ…」と暗黒面に落ちそうになったことは数え切れないです。
そこで、レプリケーションと違う形で他のDBを簡単に参照し、尚且つSQLで表結合できるようなものってないのかな?と探していたところに出会ったのが、
このMariaDBのストレージエンジン「SPIDER」だった、というお話ですね。
今描いている理想図を実現するために必要なことで、まだわかっていないことがありました。
- フェデレーションってどうやってやるんだっけ?
- バックアップってどうなるの?
- SPIDERノードってどうやって冗長化させるの?
【検証その1】フェデレーションってどうやってやるんだっけ?
フェデレーションは、外部のDBサーバのテーブルをあたかも自分のところにいるかのような事ができる機能です。
所轄「リンクテーブル」といったところでしょうか。
まずはSPIDERノードのDBに対して、create server文を実行し、サーバーを登録しておきます。
create server mariadbdata01 foreign data wrapper mysql options (user 'spider', password 'XXXXX', host '192.168.110.133', port 3306);
create server mariadbdata02 foreign data wrapper mysql options (user 'spider', password 'XXXXX', host '192.168.110.134', port 3306);
create server mariadbdata03 foreign data wrapper mysql options (user 'spider', password 'XXXXX', host '192.168.110.135', port 3306);
この状態で、データノード03(↑の例でいうとmariadbdata03)上に通常のInnoDBベースのテーブルを作成し、データを登録します。
use example;
create table depts(
dept_id int primary key,
dept_name varchar(32)
) engine = InnoDB;
insert into depts(dept_id,dept_name) values(1,'営業部');
insert into depts(dept_id,dept_name) values(2,'経理部');
insert into depts(dept_id,dept_name) values(3,'技術部');
insert into depts(dept_id,dept_name) values(4,'法務部');
よくある部署テーブルです。
そして、SPIDERノードのサーバー上に通常のInnoDBベースのテーブルを作成します。
use example;
create table employees(
id int primary key auto_increment,
dept_id int,
name varchar(32)
) engine = InnoDB;
insert into employees(dept_id,name) values(1,'田中');
insert into employees(dept_id,name) values(2,'玉木');
insert into employees(dept_id,name) values(3,'鈴木');
insert into employees(dept_id,name) values(3,'山本');
insert into employees(dept_id,name) values(2,'斉藤');
insert into employees(dept_id,name) values(1,'佐藤');
insert into employees(dept_id,name) values(1,'小澤');
insert into employees(dept_id,name) values(2,'関野');
insert into employees(dept_id,name) values(0,'中村');
よくある社員テーブルですね。
この状態では、部署テーブルは別サーバー上にあるため、表結合することはできません。
そこで、SPIDERエンジンのフェデレーションを使って、テーブルを作成します。
create table depts(
dept_id int primary key,
dept_name varchar(32)
) engine = SPIDER comment='wrapper "mysql", srv "mariadbdata03"';
こうすることで、データノード03上のテーブルを参照する準備ができました。
それでは、実際に部署テーブルと社員テーブルを結合してみましょう。
select a.name
, b.dept_name
from employees a
left join depts b
on a.dept_id = b.dept_id
;
+--------+-----------+
| name | dept_name |
+--------+-----------+
| 田中 | 営業部 |
| 玉木 | 経理部 |
| 鈴木 | 技術部 |
| 山本 | 技術部 |
| 斉藤 | 経理部 |
| 佐藤 | 営業部 |
| 小澤 | 営業部 |
| 関野 | 経理部 |
| 中村 | NULL |
+--------+-----------+
9 rows in set (0.02 sec)
特殊なSQLを書く必要なく素直に結合することができました。
現状この機能はMariaDB、MySQL、Oracleで利用可能とのことです。
SPIDERの機能を使うと、データの分散と集約が簡単に実装できることがわかりました。
【検証その2】バックアップってどうするの?
ひとまず、SPIDERストレージエンジンで作成したテーブルを含むデータベースを普通にバックアップしてみましょう。
mysqldump -uroot -p -A > spider_all_db.sql
more spider_all_db.sql
--
-- Table structure for table `depts`
--
DROP TABLE IF EXISTS `depts`;
/*!40101 SET @saved_cs_client = @@character_set_client */;
/*!40101 SET character_set_client = utf8 */;
CREATE TABLE `depts` (
`dept_id` int(11) NOT NULL,
`dept_name` varchar(32) DEFAULT NULL,
PRIMARY KEY (`dept_id`)
) ENGINE=SPIDER DEFAULT CHARSET=utf8 COMMENT='wrapper "mysql", srv "mariadbdata03"';
/*!40101 SET character_set_client = @saved_cs_client */;
--
-- Table structure for table `employees`
--
DROP TABLE IF EXISTS `employees`;
/*!40101 SET @saved_cs_client = @@character_set_client */;
/*!40101 SET character_set_client = utf8 */;
CREATE TABLE `employees` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`dept_id` int(11) DEFAULT NULL,
`name` varchar(32) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8;
/*!40101 SET character_set_client = @saved_cs_client */;
--
-- Dumping data for table `employees`
--
LOCK TABLES `employees` WRITE;
/*!40000 ALTER TABLE `employees` DISABLE KEYS */;
INSERT INTO `employees` VALUES (1,1,'田中'),(2,2,'玉木'),(3,3,'鈴木'),(4,3,'山本'),(5,2,'斉藤'),(6,1,'佐藤'),(7,1,'小澤'),(8,2,'関野'),(9,0,'中村');
/*!40000 ALTER TABLE `employees` ENABLE KEYS */;
UNLOCK TABLES;
DROP TABLE IF EXISTS `products_partition`;
/*!40101 SET @saved_cs_client = @@character_set_client */;
/*!40101 SET character_set_client = utf8 */;
CREATE TABLE `products_partition` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL,
`price` int(11) NOT NULL DEFAULT 0,
`created_at` datetime NOT NULL,
`updated_at` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=SPIDER AUTO_INCREMENT=12 DEFAULT CHARSET=utf8mb4
PARTITION BY HASH (`id`)
(PARTITION `p1` COMMENT = 'server "mariadbtest02", table "products_partition"' ENGINE = SPIDER,
PARTITION `p2` COMMENT = 'server "mariadbtest03", table "products_partition"' ENGINE = SPIDER,
PARTITION `p3` COMMENT = 'server "mariadbtest04", table "products_partition"' ENGINE = SPIDER);
どうやら、InnoDBで作られたテーブルも、SPIDERエンジンで作られたテーブルも作られたようです。
【検証その3】SPIDERノードってどうやって冗長化させるの?
それではこのダンプしたSQLを使って、新しくSPIDERノードのサーバを立て、インポートしてみます。
[user@mariadb-spider02 ~]$ mysql -uroot -p < spider_all_db.sql
Enter password:
ERROR 1477 (HY000) at line 33: The foreign server name you are trying to reference does not exist. Data source error: mariadbdata03
mariadbdata03 がいないよ、と怒られました。
中身を見ていくと、mysqlシステムテーブル内のデータは最後に登録されるようなので、そこでエラーになっているようです。
どうやら試行錯誤する必要がありそうです。
検証結果まとめ
今回の検証結果です。
- 【検証その1】フェデレーションってどうやってやるんだっけ?
- create server文で予めサーバを登録しておくことで、create table 文のコメントに `wrapper` で指定してあげることで簡単に外部のサーバーのテーブルを登録することができ、 尚且つ自身のテーブルであるかのように結合することができました。
- 【検証その2】バックアップってどうするの?
- 特に特殊な操作も必要なく、mysqldumpコマンドでバックアップすることが可能である事がわかりました。
- 【検証その3】SPIDERノードってどうやって冗長化させるの?
- 単純にmysqldumpコマンドでバックアップしたテーブルをインポートするだけではエラーになるため、何か他の作業が必要そうであることがわかりました。
最後に
今回ご紹介したSPIDERストレージエンジンのフェデレーションだけでなく、MariaDBにはConnectというストレージエンジンが存在していて、
これを利用するとODBC経由で別のRDBMSも接続することが可能になる事まではわかっています。
なので、これらの機能を使うことで、マイクロサービス化したサービスのDBサーバや、まだサービス移行途中の旧システムのDBなどもMariaDB経由で参照することができます。
こうすることで、アプリケーション側が「どのDBに接続すればどのデータが見れる」ということを意識せずにデータを利用する環境が整い、
またサーバーの負荷状況に合わせてスケールアウトも容易にできるのではないでしょうか。
まだ私自身、DBAとしてもまだまだなので、来年はもっとデータベースのことを検証し、知見を高め、
アイスタイルには優秀なDBAがいる。だから良いサービスが提供できる
と周囲のエンジニアの皆さんから評価していただけるようなDBAを目指していきたいと思います!
最後まで読んでくださり、ありがとうございました!
それでは、また来年!
皆さんにとって良いクリスマスでありますように…
We wish you a Merry Christmas♪
良いお年を~!!