はじめに
この投稿はアイスタイル アイスタイル Advent Calendar 2017の6日目の記事です。
どぉ~もみなさん、おはこんばんにちは!
飲み会が近づくと体調が悪くなる
と定評(?)の@sugat1679です。
アイスタイルでDBA業務をし始めて2年目。だいぶ板についてきました。
忘年会シーズンになりましたね。皆さん、体調にはお気をつけくださいね!(ゴホッゴホッ
そこで、いろいろなDBを触ってきた私の今までの経験から、これからのデータベースサーバーを取り巻く環境で
こんな構成が取れたら良いのでは?という話から、現在注目しているMariaDBについて、
ストレージエンジンにフォーカスを当ててお話していきます。
目指したい、理想のデータベース構成
今まで見てきたデータベースの中で、「これはすごい!」と衝撃を受けたのは、
Microsoft社のSQL Serverの機能である「AlwaysOn 可用性グループ」というものでした。
それぞれのサーバーでデータを同期しつつ、それぞれが独立していて利用できる。
尚且つ、スケールアウトも簡単。
昨今のデータベース事情を見ていくと、「このサーバーなら絶対に落ちない」というような構成よりも、
柔軟に拡大・縮小でき、かつ任意のデータを同期させるような構成が取れたら一番良いなと感じています。
なので、私の考えている理想のデータベース構成となるポイントは以下の3つです。
・スケールアウトが容易にできる
→一時的な負荷増大や、場合によってはDRとして使えるような
・データの同期が簡単
→どのデータベースが持つレプリケーション機能も一長一短で、いろんなエラーに苦しめられます
・運用のコストが低い
→どの企業のDBAさんも人数が少ない会社が多いと思います。少ない人数で運用していく中で
複雑な機能は使いたくないし、緊急事態で自分が動けないときに別の人でも初動対応できるようなものがいいです。
今回のブログのタイトルにもある、AmazonさんのRedShiftやAuroraといったデータベースは
まさにその理想を実現する形じゃないかと考えています。
私もいちエンジニアなんですね。これらを見た時に、「これを自分で実現するならどうやったらできるのか?」って
思ってしまったんです。思ってしまったならしょうがない!やってみよう!と。
先日、私が毎年参加している「db tech showcase」という
カンファレンスにて、こんなセッションを聞いてきました。
「MariaDB 10.3から利用できるSpider関連の性能向上機能・便利機能ほか 」
https://www.slideshare.net/Kentoku/mariadb-103spider
また、関連している情報を調べていくと、こんな記事を見つけたのです。
「OSSのカラム型DBはここまで進化! インサイトテクノロジー・小幡一郎氏」
http://ascii.jp/elem/000/001/511/1511229/index-2.html
この記事を見たときに思いました。
このストレージエンジンを使えば理想のデータベース構成に近づけるのでは と。
そんな構成が実現できないか、を日々研究している毎日です。
MariaDBのストレージエンジンについて
ご存じの方も多いですが、MySQLのフォークから生まれたMariaDBは、「ストレージエンジン」と言って
データベースのエンジン部分をプラグイン形式で使い分けることができます。
・InnoDB…一番メジャーなストレージエンジン。トランザクションをサポート
・CONNECT…異なるRDBMS(Oracleとか、SQLServerとか)にも接続できるストレージエンジン
・SPIDER…シャーディング(分割)やフェデレーション(外部接続)を実現
・ColumnStore…カラム型(列志向型)データベースエンジン
これらを組み合わせることで、理想としている構成が組めないか考えました。
そこで私が注目したのが、SPIDERとConnect、ColumnStoreのストレージエンジンの組み合わせです。
今回はこれらのうち、「SPIDER」ストレージエンジンについてご紹介します。
ストレージエンジン「SPIDER」について
SPIDERと呼ばれるストレージエンジンは、記事にかかれている通り、シャーディングとフェデレーションを提供する
ストレージエンジンです。
このストレージエンジンの詳細については、私が説明するよりもこちらのSlideShareが詳しく書かれているので
説明については割愛させていただきます。
参考URL:
「Spiderストレージエンジンのご紹介」スパイラルアーム合同会社 斯波建徳様
https://www.slideshare.net/Kentoku/spider-70345615
今回はこんな構成を組んでみました。
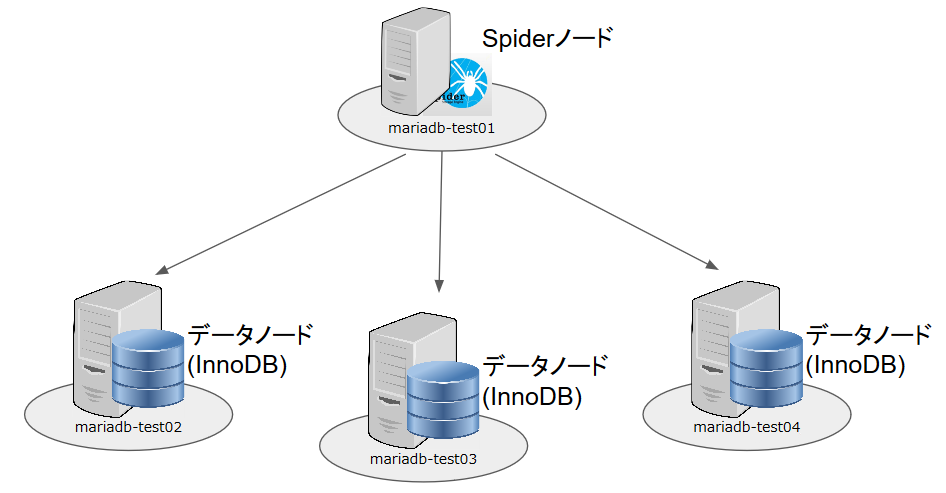
SPIDERストレージエンジンで実現できるのは、「シャーディング(レコードの分散)」と、「H/A(高可用性)」、「フェデレーション(外部サーバのテーブルを接続)」です。
SPIDERストレージエンジン機能その1「シャーディング」
試しに、この構成でシャーディングを実現させてみます。
(予め、create server文を使ってデータノード用のサーバーは登録済みとします)
Spiderノードで以下のSQLを実行します:
create table products_partition
(
id int AUTO_INCREMENT NOT NULL,
name varchar(255) not null,
price int(11) not null default 0,
created_at datetime not null,
updated_at datetime,
primary key (id)
) ENGINE = SPIDER default character set = utf8mb4
partition by hash (id) (
partition p1 comment 'server "mariadbtest02", table "products_partition"',
partition p2 comment 'server "mariadbtest03", table "products_partition"',
partition p3 comment 'server "mariadbtest04", table "products_partition"'
);
ENGINE = SPIDER という句が書かれているのがわかります。
また、partition by 句の中に comment としてどのサーバのどのテーブルに振り分けるか、を定義するのが特徴となっています。
次に、データノード(3台すべて)で以下のSQLを実行します:
create table products_partition
(
id int AUTO_INCREMENT NOT NULL,
name varchar(255) not null,
price int(11) not null default 0,
created_at datetime not null,
updated_at datetime,
primary key (id)
) ENGINE = InnoDB default character set = utf8mb4;
こちらは、普通のcreate table文ですね。
ここまでで準備は完了です。
試しにSpiderノードに接続して、データを登録していきます。
insert into products_partition(name, price, created_at) values ('えだまめあられ', 108, NOW());
insert into products_partition(name, price, created_at) values ('マイクポップコーン', 216, NOW());
insert into products_partition(name, price, created_at) values ('ルマンド', 324, NOW());
insert into products_partition(name, price, created_at) values ('エリーゼ', 324, NOW());
insert into products_partition(name, price, created_at) values ('カントリーマアム', 324, NOW());
insert into products_partition(name, price, created_at) values ('いちごビスケット', 216, NOW());
insert into products_partition(name, price, created_at) values ('ポテトチップス のり塩味', 150, NOW());
insert into products_partition(name, price, created_at) values ('ポテトチップス コンソメ味', 150, NOW());
insert into products_partition(name, price, created_at) values ('ポテトチップス うすしお味', 150, NOW());
insert into products_partition(name, price, created_at) values ('海苔巻きせんべい', 324, NOW());
insert into products_partition(name, price, created_at) values ('ごませんべい', 324, NOW());
すると、
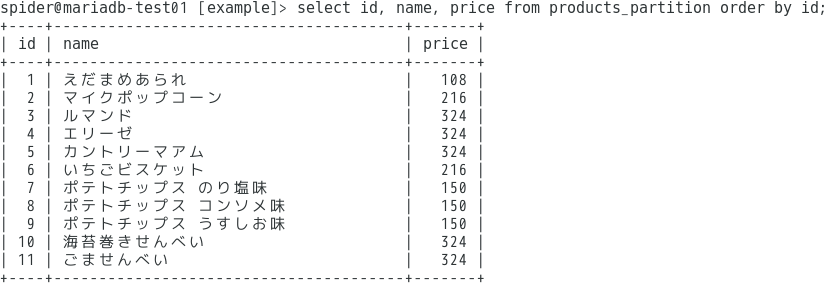
データがキレイに登録されました。
これを各データノードに直接接続してテーブルの中身を見てみると…

ID列をキーにしてレコードが分散されているのがよくわかります。
このように、create tableのcomennt文を使って簡単にデータが分散できるというのがシャーディングです。
SPIDERストレージエンジン機能その2「H/A(高可用性)」
この機能は、簡単に言えば「テーブルの複製を別のサーバーに置く」という機能です。
まずはSpiderノードにてテーブルを作成します:
create table products_ha
(
id int AUTO_INCREMENT NOT NULL,
name varchar(255) not null,
price int(11) not null default 0,
created_at datetime not null,
updated_at datetime,
primary key (id)
) ENGINE = SPIDER default character set = utf8mb4 comment 'table "products_ha", server "mariadbtest02 mariadbtest03"'
;
comment句がちょっと変わりました。
次に、データノードでテーブル作成します。
(こちらは、先ほどと同様にInnoDBで作成する普通のテーブルのため、SQLは割愛します)
そして、データを登録すると…:

キレイに複製されていることがわかります。
ここでちょっと試したいことがあったので、以下のALTER文をSpiderノードにて投げてみました。
alter table products_ha comment 'table "products_ha", server "mariadbtest02 mariadbtest03 mariadbtest04"';
サーバーを追加したらどうなるのかな?という挙動を試したかったのです。
そして、Spiderエンジンの管理用テーブルspider_tablesを見てみると、
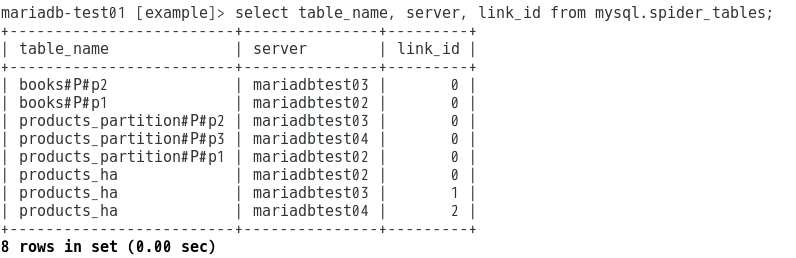
ちゃんと追加されてました。
そして更に、管理コマンドspider_copy_tablesを実行すると…
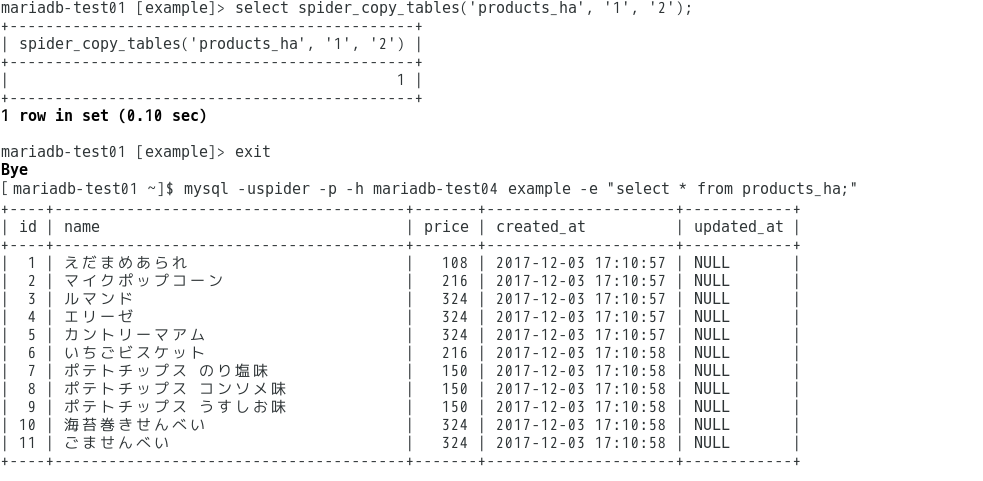
見事に新たなデータノードにコピーが成功しました。
もう少し検証は必要ですが、こういった使い方もできる、というのがわかりました。
テーブル単位でちょっとしたレプリケーション代わりにも使えそうです。
(本当は、監視ノード登録したりとか、いろいろ設定するとサーバーダウンの自動検知とかいろいろやってくれそうです)
まとめ(次回へ続く?)
MariaDBのSpiderエンジンを使うことで、データをテーブル単位・サーバー単位で振り分けられることがわかりました。
次は、ConnectエンジンやSpiderエンジンのフェデレーション機能を使って集約する機能について検証していきます。
明日7日目は、弊社のフロントエンジニア @okadai さんが「不具合解析のための思考プロセス/フレームワーク」
というテーマでお話してくださいます!お楽しみに!