はじめに
この記事は JustSytems Advent Calendar の 7 日目です。
以前にQiita:Teamで社内向けに書いた記事を手直ししたものになります。
当社で利用しているRDBMSの多くがPostgreSQLです。ということで、この記事もPostgreSQLを対象に書いています。
この記事の対象読者
この記事の対象読者として想定しているのは、
- RDBMS を利用したアプリケーション を開発しているアプリケーションエンジニア
- 特に、基本的なSQLは書けるが苦手意識を持っている、あるいはDB層は完全にORMに任せてしまっていてよくわからない
- わからないとまで言わないが、性能に関して特段に意識したことはない。
というような方です。バリバリのDBAのみなさまからはマサカリをいただきたいですがどうぞお手柔らかにお願いします。
以下、特に断りのない場合にはPostgreSQL(の比較的新しいバージョン。9.0以降~くらい)のことだとおもってお読みいただけたらと思います。
その他のDBMSや、古いPostgreSQLについては、まだよく知らないので…… ![]()
実行計画とは
「実行計画」の話をする前に、まず検索質問(SQL文)がどのように処理されるのかの概要を知る必要があります。
(人生は終わりのないyak shavingなのです)
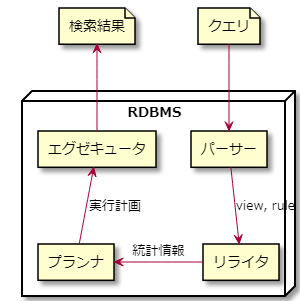
RDBMSの検索のしくみ。
私たちが書いたSQLのクエリを、RDBMSが解釈して検索結果を得るまでに、一般的には以下の様な手順を経ます。
- クエリをパーサーが読み取る(構文解析)
- リライタがView,Ruleなどを適用し、クエリを書き換える
- プランナ(オプティマイザとも)が統計情報を利用して、どの様な手順でデータを抽出するかという手順を組み上げる。→これが実行計画!
- 実行計画に基づいて、実際にデータを抽出する。
通常、ある問い合わせについて、同じ結果を出すための方法は複数存在しています。
プランナは、統計情報や経験的な計算式に基づいてコスト計算を行い、最もコストが小さい実行計画を選択します。
改めて、実行計画とは
宣言的な命令であるところのSQL文を、実際の処理手順に変換したものが「実行計画」です。
宣言的な命令?
SQLは宣言的な言語とか、宣言型の言語などと言われる場面があります。
どういうことかというと、「ある出力を得るにあたって、それを作成する方法ではなく、出力の性質を記述する」ような言語である。ということです。
これは、「ある出力を得るに当たって、それを生成する方法を記述する」という手続き型言語と比較されていわれることです。
SELECT name FROM users WHERE "部署" = '開発部' AND "年齢" < 35
なら
「usersというテーブル から 、"部署" カラムが 開発部 であり "年齢" カラムの値が35 未満である レコードについて、name列の内容を選択せよ」
という命令であり、 出力の性質を記述 しています。
これを手続き的に記述するとき、以下のどのように書いても得られる結果は同じです。
(特定の言語を想定しない擬似コードです)
foreach (u in users) {
if (u.部署 == "開発部"){
if(u.年齢 < 35){
print u.name ;
}
}
}
foreach (u in users) {
if(u.年齢 < 35){
if (u.部署 == "開発部"){
print u.name ;
}
}
}
foreach (u in users) {
if (u.部署 == "開発部" && u.年齢 < 35){
print u.name ;
}
}
このように、得られる手続きの中からより効率のよさそうなもの(見積もったコストが小さいもの)が「実行計画」として選択されます。
実行計画を出力する方法
実行計画を出力するためには、EXPLAIN コマンドを使います。
ざっくりと言えば、EXPLAIN を 実行計画を出力させたいSQL文の前に書いて実行すればOKです。
こんな感じの出力になります。
=> EXPLAIN SELECT 1;
QUERY PLAN
------------------------------------------
Result (cost=0.00..0.01 rows=1 width=0)
実行計画の構造
実行計画は、処理を行う手順を木構造にして表します。
PostgreSQLで、EXPLAIN をしたときに表示されるテキスト形式の実行計画では、
1行目に最上位のノードが現れ、順に「->」の記号とインデントによって複数のノードが現れます。
同じ階層のノードは、同じインデントにそろえられます。
=> EXPLAIN (ANALYZE, COSTS OFF) SELECT * FROM course_results cr JOIN users USING(user_id) LIMIT 1;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------------------
Limit (actual time=7.623..7.624 rows=1 loops=1)
-> Nested Loop (actual time=7.620..7.620 rows=1 loops=1)
-> Seq Scan on users (actual time=0.009..0.021 rows=8 loops=1)
-> Index Scan using course_results_user_id_idx on course_results cr (actual time=0.946..0.946 rows=0 loops=8)
Index Cond: (user_id = users.user_id)
Planning time: 10.693 ms
Execution time: 7.692 ms
(7 rows)
ここで、木構造なので「ノード」という単語が突然出てきてしまったのですが、この「ノード」が処理の種類を表すキーワードなのです。
よくでるキーワード と、非常にざっくりとした説明を以下に記載します。
| スキャン系 キーワード | 概要 |
|---|---|
| Seq Scan | テーブル全体を順番に調べてみるというもの。大きなテーブルでこれが出てたら要注意 |
| Index Scan | インデックスを使って、テーブルを順次調べてみるというもの。 原則としては速い。ただし、インデックスとテーブルを両方チェックするので場合によってはコストが高くなる |
| Index Only Scan | インデックスのみを順次調べてみるというもの。とても速いけど、使える場面は限られる。PostgreSQL 9.2 以降が必要 |
| Bitmap Scan | インデックスからビットマップを作って、テーブルをスキャンする。ビットマップを作る時間的・空間的なオーバーヘッドがある |
| 結合系 キーワード | 概要 |
|---|---|
| Nested Loop | 結合する外側テーブルの各行について、内側テーブルのすべての行を評価する結合 ON句をちゃんと書かないと中間表が大きくなりとても時間がかかるので注意 |
| Hash Join | 内側テーブルのハッシュを作り、ハッシュに基づいて外側テーブルを評価する方法。ハッシュを作るオーバーヘッドとか、ハッシュを作っても、外側テーブルとかけ算すると十分に大きくなるような場合に注意 |
| Merge Join | 結合条件でソートされたテーブルを順に評価する方法。ソートのオーバーヘッドがかかる |
他にも、ソートとか集計とか、いろいろあるのですが今回はこのくらいにしておきたいと思います。
(初心者のための)実践!EXPLAIN
EXPLAIN 最初の一歩として 、以下の事を心がけましょう。
-
SELECT文以外の実行計画を読もうとしない1 -
EXPLAINは 必ずEXPLAIN ANALYZEの形で使う。2- もっといえば、
EXPLAIN (COSTS OFF, ANALYZE)の形で使うとよりよいかも - (つまり、SELECT文のみというのは、何も考えずに
ANALYZEをつけるということにするためにつけた縛りです。)3
- もっといえば、
=> EXPLAIN (COSTS OFF, ANALYZE) SELECT 1;
QUERY PLAN
--------------------------------------------------
Result (actual time=0.002..0.003 rows=1 loops=1)
Total runtime: 0.092 ms
発行したクエリに対して、どんな処理をして、最終的にどれだけ時間がかかったのかを出力してくれます。
どこに注目する?
※以下では、Webアプリケーションの中のクエリとして使う場合を想定したタイムスケールで所要時間の評価をします。
アドホックな分析クエリなど、タイムスケールが異なるべき要件のときには、適切に読み替える必要があります。
1. Total runtime
なにはなくとも総実行時間です。どんな実行計画であろうが、数msとか十数msとかで終わっているならムリに改善することはないでしょう(※もちろん要件次第で閾値は変わります) し、普通の方法で改善の余地があるかすら怪しいです。少なくとも、本稿の対象読者はひとまず考えない方が良いでしょう。
2. actual time
ツリーの各ノードに (actual time=0.xxx..0.xxx) という出力がありますが、これが、このノードを処理するのにかかった時間です。
左側の数字が、最初の1行目を得るまでにかかった時間、右側の数字が最後の行を得るまでにかかった時間、というふうに読みます。単位はms(ミリ秒)です。
多くの場合、2つ目の数字と1つ目の数字の差分が大きいものが「時間がかかっている処理」のノードです。対象の行数や、行われている処理の内容、INDEXが使われているか、をチェックしましょう。
終わりに。
ものすごくおおざっぱに、実行計画への入門の入門くらいの内容を書いてみました。
アプリケーションエンジニアにデータベースを理解していただくための一助となれば幸いです。
参考文献
補遺、あるいはなぜこの記事を書いたか。
世の中にSQLの実行計画について解説したサイトや書籍は数あれど
(というほど多くもないような気がしますが ![]() )
)
そのほとんどがデータベースの運用・管理を行うエンジニアに向けて書かれています。
そこでは、統計情報の見方や使われ方、VACUUMやANALYZEのタイミングや頻度、そしてときには統計情報の強制的な書き換えといった、
「最適な実行計画が出てこない(こともある)前提で、どんなときには実行計画を制御しなければいけないか、そして実行計画を制御するにはどうするか。」という観点のものがほとんどです。
しかし、その前の段階には「最近のオプティマイザは、一般のプログラマよりも賢いので」という観点で、そもそも自分がおかしなクエリを書いて(またはORMが出力して)いないか、とか、必要なINDEXが付いているのか、使われているのか、ということを純粋に確認するために実行計画を読んでみる、という要求があるはずです。
「SQLアンチパターン」の「インデックスショットガン」の章から引用
「それは問題じゃない」DBA は笑いながら言いました。「君はアプリケーションを知っているだろう? そこがポイントだ。私たちは、アプリケーションについてはよくわからないからね。私の部下の1 人に、君が適切なツールを使えるように準備させる。そうすれば、ボトルネックを修正できるはずだ。君には、ちょっとしたメンタリングが必要なだけなんだ」
の通り、データをどのカラムの値で検索して、どのカラムの値で並べ替えるのか、というのはDBAではなくアプリケーションエンジニアが知っている(はずな)のです。
したがって、データベースを使うアプリケーションエンジニアは、SQLの実行計画を読めるようになることが求められているはずです。
ということで、そういう観点で実行計画について書いてみようという試みでした。
-
アプリケーションコードとして組み入れるかは別として、特別対応等で、複雑な
INSERT/UPDATE/DELETEを 書く場面も出てくるでしょうし、そういう場合のパフォーマンスが気になることも出てくるでしょうが、まずは一旦忘れましょう。 ↩ -
プランナの動きと統計情報を見ながら
ANALYZE(これはVACUUM / ANALYZEの方)したり、大きく外している統計情報を発見して自分で書き換えたり、という運用を行う上級DBAではなく、プランナは完全なブラックボックスとして、とりあえずSQLのパフォーマンスを測定したいアプリケーションエンジニアが対象ですので、コストベースの実行計画のことは忘れてもらうのが良いでしょう。 ↩ -
ご承知の通り、
ANALYZEオプションをつけると入力のクエリを実際に実行して、その処理時間を結果に含めてくれます。つまり、INSERT/UPDATE/DELETEをEXPLAIN ANALYZEに続けて書くと変更が実施されてしまいます。 ↩