はじめに
学習後の境界値を可視化します。
以下のような図です。

入力の次元が2次元の場合は、このように境界を可視化できます。
今回は、TensorFlow の多層パーセプトロンを例に可視化してみたいと思います。
目次
1.学習用データ
2.モデル(多層パーセプトロン)
3.可視化の方針
4.meshgrid
5.等高線プロット
6.全コード
履歴
1.学習用データ
今回利用するデータは、scikit-learn の dataset にある三日月型のデータセットを利用します。
2次元のデータですので、平面で図示できます。
from sklearn import datasets
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
'''
三日月データを生成する
'''
N = 300 # データ数を指定する
X, y = datasets.make_moons(N, noise=0.2)
Y = y.reshape(N, 1)
# トレーニングデータとテストデータに分ける
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, train_size=0.8)
'''
データプロット
'''
plt.figure(figsize=(10, 6))
plt.ylim([-1,1.5])
plt.xlim([-1.5,2.5])
plt.scatter(X[y==1][:,0], X[y==1][:,1], s=10, marker='.')
plt.scatter(X[y==0][:,0], X[y==0][:,1], s=10, marker='^')
plt.show()

このデータを使って学習し、境界線を引いてみます。
2.モデル(多層パーセプトロン)
学習は TensorFlow (1.x) の多層パーセプトロンでやってみます。
モデルは一例ですので、境界値を引くためのモデルは何でもかまいません。
隠れ層を1つにした。3層パーセプトロンのコードは以下です。
class ThreelayerPerceptron(object):
'''
初期化
'''
def __init__(self, n_in, n_hidden, n_out):
self.n_in = n_in
self.n_hidden = n_hidden
self.n_out = n_out
self.weights = []
self.biases = []
self._x = None
self._y = None
self._t = None,
self._sess = None
self._history = {
'accuracy': [],
'loss': []
}
'''
重み
'''
def weight_variable(self, shape):
initial = tf.truncated_normal(shape, stddev=0.01)
return tf.Variable(initial)
'''
バイアス
'''
def bias_variable(self, shape):
initial = tf.zeros(shape)
return tf.Variable(initial)
'''
モデル定義(3層パーセプトロン)
'''
def inference(self, x):
# 入力層 - 隠れ層
self.weights.append(self.weight_variable([self.n_in, self.n_hidden]))
self.biases.append(self.bias_variable([self.n_hidden]))
h = tf.nn.sigmoid(tf.matmul(x, self.weights[-1]) + self.biases[-1])
# 隠れ層 - 出力層
self.weights.append(self.weight_variable([self.n_hidden, self.n_out]))
self.biases.append(self.bias_variable([self.n_out]))
y = tf.nn.sigmoid(tf.matmul(h, self.weights[-1]) + self.biases[-1])
return y
'''
損失関数
'''
def loss(self, y, t):
cross_entropy = tf.reduce_mean(-tf.reduce_sum(t * tf.log(y) + (1 - t) * tf.log(1 - y)))
return cross_entropy
'''
最適化アルゴリズム
'''
def training(self, loss):
optimizer = tf.train.GradientDescentOptimizer(0.05)
train_step = optimizer.minimize(loss)
return train_step
'''
正解率
'''
def accuracy(self, y, t):
correct_prediction = tf.equal(tf.cast(tf.greater(y, 0.5),tf.float32), t)
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
return accuracy
'''
予測
'''
def prediction(self, y):
return tf.cast(tf.greater(y, 0.5),tf.float32)
'''
学習
'''
def fit(self, X_train, Y_train,
nb_epoch=100, batch_size=100, p_keep=0.5,
verbose=1):
x = tf.placeholder(tf.float32, shape=[None, self.n_in])
t = tf.placeholder(tf.float32, shape=[None, self.n_out])
self._x = x
self._t = t
y = self.inference(x)
loss = self.loss(y, t)
train_step = self.training(loss)
accuracy = self.accuracy(y, t)
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
self._y = y
self._sess = sess
N_train = len(X_train)
n_batches = N_train // batch_size
for epoch in range(nb_epoch):
X_, Y_ = shuffle(X_train, Y_train)
for i in range(n_batches):
start = i * batch_size
end = start + batch_size
sess.run(train_step, feed_dict={
x: X_[start:end],
t: Y_[start:end]
})
loss_ = loss.eval(session=sess, feed_dict={
x: X_train,
t: Y_train
})
accuracy_ = accuracy.eval(session=sess, feed_dict={
x: X_train,
t: Y_train
})
self._history['loss'].append(loss_)
self._history['accuracy'].append(accuracy_)
if verbose:
print('epoch:', epoch,
' loss:', loss_,
' accuracy:', accuracy_)
return self._history
def evaluate(self, X_test, Y_test):
accuracy = self.accuracy(self._y, self._t)
return accuracy.eval(session=self._sess, feed_dict={
self._x: X_test,
self._t: Y_test
})
def predict(self, X_test):
prediction = self.prediction(self._y)
return prediction.eval(session=self._sess, feed_dict={
self._x: X_test
})
3.可視化の方針
境界値の可視化は、格子点ごとに学習結果をプロットすることで行います。
以下の黒い格子点をテストデータとみなし、結果を予測します。

仮に、青線が境界値だった場合、
・青線より上の格子点は結果が「0」
・青線より下の格子点は結果が「1」
というような結果が得られます。
この結果を後述する「等高線プロット」で色分けします。
4.meshgrid
格子点は numpy.meshgrid を使います。
例えば、以下のようにすると、5 × 5 のリストが取得できます。
x, y = np.meshgrid(np.arange( 0, 10, 2),
np.arange( 1, 6, 1))
x
y
array([[0, 2, 4, 6, 8],
[0, 2, 4, 6, 8],
[0, 2, 4, 6, 8],
[0, 2, 4, 6, 8],
[0, 2, 4, 6, 8]])
array([[1, 1, 1, 1, 1],
[2, 2, 2, 2, 2],
[3, 3, 3, 3, 3],
[4, 4, 4, 4, 4],
[5, 5, 5, 5, 5]])
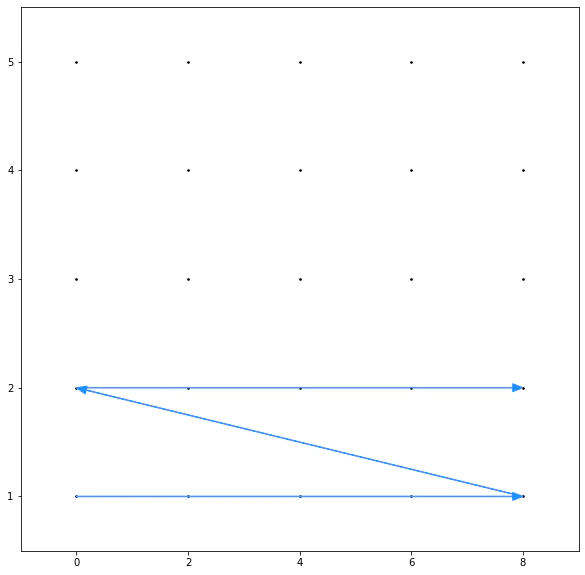
これを x軸、y軸に指定することで、下図のような格子点の配列になります。
配列(grids)の 0 から順に、格子点の矢印の順番になります。
grids = np.array([x.ravel(), y.ravel()]).T
5.等高線プロット
境界値は matplotlib の contourf で線を引きます。
第1引数にX軸、第2引数にY軸、第3引数に高さを設定します。
高さは、今回のケースでは2値分類の予測結果なので、「0」「1」のどちらかです。
from matplotlib.colors import ListedColormap
cmap = ListedColormap( ( "mistyrose","lightcyan") )
plt.contourf(x, y, pred, cmap=cmap)
格子点の予測を pred とすると、このコードで下図のような境界線を引くことができます。
6.全コード
モデルによる学習を含めた、境界線プロットの全コードは以下です。
import numpy as np
import tensorflow as tf
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.utils import shuffle
import matplotlib.pyplot as plt
np.random.seed(0)
tf.set_random_seed(0)
class ThreelayerPerceptron(object):
'''
初期化
'''
def __init__(self, n_in, n_hidden, n_out):
self.n_in = n_in
self.n_hidden = n_hidden
self.n_out = n_out
self.weights = []
self.biases = []
self._x = None
self._y = None
self._t = None,
self._sess = None
self._history = {
'accuracy': [],
'loss': []
}
'''
重み
'''
def weight_variable(self, shape):
initial = tf.truncated_normal(shape, stddev=0.01)
return tf.Variable(initial)
'''
バイアス
'''
def bias_variable(self, shape):
initial = tf.zeros(shape)
return tf.Variable(initial)
'''
モデル定義(3層パーセプトロン)
'''
def inference(self, x):
# 入力層 - 隠れ層
self.weights.append(self.weight_variable([self.n_in, self.n_hidden]))
self.biases.append(self.bias_variable([self.n_hidden]))
h = tf.nn.sigmoid(tf.matmul(x, self.weights[-1]) + self.biases[-1])
# 隠れ層 - 出力層
self.weights.append(self.weight_variable([self.n_hidden, self.n_out]))
self.biases.append(self.bias_variable([self.n_out]))
y = tf.nn.sigmoid(tf.matmul(h, self.weights[-1]) + self.biases[-1])
return y
'''
損失関数
'''
def loss(self, y, t):
cross_entropy = tf.reduce_mean(-tf.reduce_sum(t * tf.log(y) + (1 - t) * tf.log(1 - y)))
return cross_entropy
'''
最適化アルゴリズム
'''
def training(self, loss):
optimizer = tf.train.GradientDescentOptimizer(0.05)
train_step = optimizer.minimize(loss)
return train_step
'''
正解率
'''
def accuracy(self, y, t):
correct_prediction = tf.equal(tf.cast(tf.greater(y, 0.5),tf.float32), t)
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
return accuracy
'''
予測
'''
def prediction(self, y):
return tf.cast(tf.greater(y, 0.5),tf.float32)
'''
学習
'''
def fit(self, X_train, Y_train,
nb_epoch=100, batch_size=100, p_keep=0.5,
verbose=1):
x = tf.placeholder(tf.float32, shape=[None, self.n_in])
t = tf.placeholder(tf.float32, shape=[None, self.n_out])
self._x = x
self._t = t
y = self.inference(x)
loss = self.loss(y, t)
train_step = self.training(loss)
accuracy = self.accuracy(y, t)
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
self._y = y
self._sess = sess
N_train = len(X_train)
n_batches = N_train // batch_size
for epoch in range(nb_epoch):
X_, Y_ = shuffle(X_train, Y_train)
for i in range(n_batches):
start = i * batch_size
end = start + batch_size
sess.run(train_step, feed_dict={
x: X_[start:end],
t: Y_[start:end]
})
loss_ = loss.eval(session=sess, feed_dict={
x: X_train,
t: Y_train
})
accuracy_ = accuracy.eval(session=sess, feed_dict={
x: X_train,
t: Y_train
})
self._history['loss'].append(loss_)
self._history['accuracy'].append(accuracy_)
if verbose:
print('epoch:', epoch,
' loss:', loss_,
' accuracy:', accuracy_)
return self._history
def evaluate(self, X_test, Y_test):
accuracy = self.accuracy(self._y, self._t)
return accuracy.eval(session=self._sess, feed_dict={
self._x: X_test,
self._t: Y_test
})
def predict(self, X_test):
prediction = self.prediction(self._y)
return prediction.eval(session=self._sess, feed_dict={
self._x: X_test
})
'''
三日月データを生成する
'''
N = 300 # 全データ数
X, y = datasets.make_moons(N, noise=0.2)
Y = y.reshape(N, 1)
# トレーニングデータとテストデータに分ける
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, train_size=0.8)
'''
データプロット
'''
plt.figure(figsize=(10, 6))
plt.ylim([-1,1.5])
plt.xlim([-1.5,2.5])
plt.scatter(X[y==1][:,0], X[y==1][:,1], s=10, marker='.')
plt.scatter(X[y==0][:,0], X[y==0][:,1], s=10, marker='^')
plt.show()
'''
モデル設定
'''
model = ThreelayerPerceptron(n_in=len(X[0]),
n_hidden=3,
n_out=len(Y[0]))
'''
モデル学習
'''
history = model.fit(X_train, Y_train,
nb_epoch=400,
batch_size=20,
verbose=1)
'''
予測精度の評価
'''
accuracy = model.evaluate(X_test, Y_test)
print('accuracy: ', accuracy)
'''
グラフを色分けするための格子データを生成する
'''
meshgrids = np.meshgrid(
np.arange( -1.5, 2.6, 0.01 ),
np.arange( -1, 1.6, 0.01 )
)
xx = meshgrids[0]
yy = meshgrids[1]
# 格子点のリストにする
grids = np.array([xx.ravel(), yy.ravel()]).T
'''
格子データの予測結果を取得する
'''
pred = model.predict(grids)
pred = pred.reshape( xx.shape )
'''
データプロット
'''
from matplotlib.colors import ListedColormap
w_[1,1] * v_[1])
plt.figure(figsize=(10, 6))
plt.ylim([-1,1.5])
plt.xlim([-1.5,2.5])
cmap = ListedColormap( ( "mistyrose","lightcyan") )
plt.contourf(xx, yy, pred, cmap=cmap)
plt.scatter(X[y==1][:,0], X[y==1][:,1], s=10, marker='.')
plt.scatter(X[y==0][:,0], X[y==0][:,1], s=10, marker='^')
plt.show()
履歴
2020/03/08 初版公開
2020/03/09 損失関数の定義修正