はじめに
初めてKaggle(カグル)のコンペに参加してみたお話です。
前回の「KaggleのTitanicで相関関係を確認する」では、相関関係を調べて、Pclass(チケットクラス)、Sex(性別)、Fare(運賃)の3つの入力データを採用することにしました。
今回はいくつかのモデルを試してみたいと思います。
目次
1.結果
2.利用するモデルについて
3.モデルの評価方法
4.モデルを試す
5.パラメータチューニング
6.Kaggleに提出する
7.まとめ
履歴
1.結果
結果から言うと、スコアが少しあがり「0.77511」になりました。
上位58%(2019/12/29現在)という結果です。
再提出までの流れを見ていきたいと思います。
2.利用するモデルについて
前回は、scikit-learnのアルゴリズムシートに従って「Linear SVC」を利用しました。
自分が機械学習を最初に学んだこの本では、クラス分類問題について、scikit-learnの以下のモデルを取り上げています。
・sklearn.svm.LinearSVC
・sklearn.svm.SVC
・sklearn.ensemble.RandomForestClassifier
・sklearn.linear_model.LogisticRegression
・sklearn.linear_model.SGDClassifier
今回は、上記のモデルを試してみたいと思います。
3.モデルの評価方法
モデルの評価は以下の手順になります。
1.トレーニングデータを使って学習する
2.テストデータを使って、予測する
3.予測した結果が正しいか確認する
KaggleのTitanicでは、トレーニングデータ [train.csv](結果が分かるデータ)とテストデータ [test.csv](結果が分からないデータ)があります。
2の「予測する」と、3の「確認する」をtest.csv を使うと毎回commitして提出しないと結果が分からないため非効率です。
結果が分かっているトレーニングデータ [train.csv]を、トレーニングデータ用データとテスト用データに分けることで効率的に評価することができます。
scikit-learnには、トレーニングデータとテストデータに分割する関数「train_test_split」が用意されています。
from sklearn.model_selection import train_test_split
######################################
# トレーニングデータとテストデータを分ける
# Split training data and test data
######################################
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=1, shuffle=True)
以下のようなイメージです。
test_size=0.3だと、トレーニングデータとテストデータを「7:3」で分割します。
〇分割前のデータ
| y | x | |||
| Survived | Pclass | Sex | Fare | |
| 1 | 0 | 3 | male | 7.25 |
| 2 | 1 | 1 | female | 71.2833 |
| 3 | 1 | 3 | female | 7.925 |
| 4 | 1 | 1 | female | 53.1 |
| 5 | 0 | 3 | male | 8.05 |
| 6 | 0 | 3 | male | 8.4583 |
| 7 | 0 | 1 | male | 51.8625 |
| 8 | 0 | 3 | male | 21.075 |
| 9 | 1 | 3 | female | 11.1333 |
| 10 | 1 | 2 | female | 30.0708 |
〇分割後のトレーニングデータ
| y_train | x_train | |||
| Survived | Pclass | Sex | Fare | |
| 1 | 0 | 3 | male | 7.25 |
| 2 | 1 | 1 | female | 71.2833 |
| 4 | 1 | 1 | female | 53.1 |
| 5 | 0 | 3 | male | 8.05 |
| 6 | 0 | 3 | male | 8.4583 |
| 8 | 0 | 3 | male | 21.075 |
| 10 | 1 | 2 | female | 30.0708 |
〇分割後のテストデータ
| y_test | x_test | |||
| Survived | Pclass | Sex | Fare | |
| 3 | 1 | 3 | female | 7.925 |
| 7 | 0 | 1 | male | 51.8625 |
| 9 | 1 | 3 | female | 11.1333 |
続いて、学習と予測です。
scikit-learnのモデルには、学習するためのメソッド「fit」と、予測を評価するためのメソッド「score」が提供されています。
「fit」と「score」です。
from sklearn.svm import LinearSVC
model = LinearSVC(random_state=1)
######################################
# 学習する
# training
######################################
model.fit(x_train, y_train)
######################################
# 予測した結果を評価する
# Evaluate predicted results
######################################
score = model.score(x_test, y_test)
「fit」は学習です。
「score」は「x_test」で結果を予測し、その結果と「y_test」と突き合わせて正解率を返します。
上記の場合、score は「0.753731343283582」になります。
75%の正解率という結果です。
4.モデルを試す
いろいろなモデルを試し、scoreを比較することで、モデルの性能を評価できます。
「2.利用するモデルについて」のモデルを試してみます。
全体的なコードは以下です。
import numpy
import pandas
# train.csvを読み込む
# Load train.csv
df = pandas.read_csv('/kaggle/input/titanic/train.csv')
##############################
# データ前処理
# 必要な項目を抽出する
# Data preprocessing
# Extract necessary items
##############################
# 'Survived', 'Pclass', 'Sex', 'Fare'を抽出する
# Extract 'Survived', 'Pclass', 'Age', 'Fare'
df = df[['Survived', 'Pclass', 'Sex', 'Fare']]
##############################
# データ前処理
# ラベル(名称)を数値化する
# Data preprocessing
# Digitize labels
##############################
from sklearn.preprocessing import LabelEncoder
# 性別をLabelEncoderを利用して数値化する
# Digitize gender using LabelEncoder
encoder_sex = LabelEncoder()
df['Sex'] = encoder_sex.fit_transform(df['Sex'].values)
##############################
# データ前処理
# 数値を標準化する
# Data preprocessing
# Standardize numbers
##############################
from sklearn.preprocessing import StandardScaler
# 標準化
# Standardize numbers
standard = StandardScaler()
df_std = pandas.DataFrame(standard.fit_transform(df[['Pclass', 'Fare']]), columns=['Pclass', 'Fare'])
# Fare を標準化
# Standardize Fare
df['Pclass'] = df_std['Pclass']
df['Fare'] = df_std['Fare']
from sklearn.model_selection import train_test_split
x = df.drop(columns='Survived')
y = df[['Survived']]
#######################################
# トレーニングデータとテストデータを分ける
# Split training data and test data
#######################################
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=1, shuffle=True)
y_train = numpy.ravel(y_train)
y_test = numpy.ravel(y_test)
#######################################
# モデルを評価する
# Evaluate the model
#######################################
from sklearn.svm import LinearSVC
model = LinearSVC(random_state=1)
model.fit(x_train, y_train)
score = model.score(x_test, y_test)
score
「モデル評価」のモデルの定義部分を差し替えれば、いろいろなモデルで評価できます。
「2.利用するモデルについて」に記述したモデルを試してみます。
結果は以下になりました。
| モデル | score |
|---|---|
| sklearn.svm.LinearSVC | 0.753 |
| sklearn.svm.SVC | 0.783 |
| sklearn.ensemble.RandomForestClassifier | 0.805 |
| sklearn.linear_model.LogisticRegression | 0.753 |
| sklearn.linear_model.SGDClassifier | 0.753 |
ランダムフォレストが一番良いという結果になりました。
次は、ランダムフォレストモデルのパラメータを調整してみます。
5.パラメータチューニング
パラメータの調整は scikit-learn にある グリッドサーチ(GridSearchCV)を利用します。
グリッドサーチは、指定されたパラメータを全パターンで評価し、最適なパラメータの組み合わせを突き止めてくれます。
ただし、全パターンを評価するため、パラメータを増やすほど処理に時間がかかります。
ランダムフォレストのドキュメントを確認し、以下のパラメータを調整することににします。
| パラメータ | パターン |
|---|---|
| criterion | gini / entropy |
| n_estimators | 25 / 100 / 500 / 1000 / 2000 |
| min_samples_split | 0.5 / 2 / 4 / 10 |
| min_samples_leaf | 1 / 2 / 4 / 10 |
| bootstrap | Ture / False |
「モデル評価」を以下の「グリッドサーチ」に入れ替えることで、グリッドサーチを実行できます。
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
###############################################
# グリッドサーチで LogisticRegression のパラメータを試す
# Tuning LogisticRegression parameters with grid search
###############################################
pipe_svc = RandomForestClassifier(random_state=1)
param_grid = {'criterion':['gini','entropy'],
'n_estimators':[25, 100, 500, 1000, 2000],
'min_samples_split':[0.5, 2,4,10],
'min_samples_leaf':[1,2,4,10],
'bootstrap':[True, False]
}
grid = GridSearchCV(estimator=RandomForestClassifier(random_state=1), param_grid=param_grid)
grid = grid.fit(x_train, y_train)
print(grid.best_score_)
print(grid.best_params_)
以下の結果になりました。
自分の環境では、グリッドサーチの実行に10分程度かかりました。
0.8105939004815409
{'bootstrap': False, 'criterion': 'entropy', 'min_samples_leaf': 10, 'min_samples_split': 2, 'n_estimators': 100}
6.Kaggleに提出する
グリッドサーチでチューニングしたパラメータを指定し、学習、予測してみましょう。
「トレーニングデータ、テストデータ作成」「グリッドサーチ」のコードを以下に書き換え、学習と予想を行います。
##############################
# モデルの構築
# Model building
##############################
from sklearn.ensemble import RandomForestClassifier
# モデルを生成する
# Generate a model
model = RandomForestClassifier(n_estimators=100, \
criterion='entropy', \
min_samples_split=2, \
min_samples_leaf=10, \
bootstrap=False, \
random_state=1)
##############################
# 学習
# Trainig
##############################
y = numpy.ravel(y)
model.fit(x, y)
# test.csv を変換する
# convert test.csv
##############################
# test.csvを読み込む
# Load test.csv
df_test = pandas.read_csv('/kaggle/input/titanic/test.csv')
# Fare のNanを変換
# Convert Fare Nan to 0
df_test = df_test.fillna({'Fare':0})
# 'PassengerId'を抽出する(結果と結合するため)
# Extract 'PassengerId'(To combine with the result)
df_test_index = df_test[['PassengerId']]
# 'Pclass', 'Sex', 'Fare'を抽出する
# Extract 'Pclass', 'Sex', 'Fare'
df_test = df_test[['Pclass', 'Sex', 'Fare']]
# 標準化
# Standardize
df_test_std = pandas.DataFrame(standard.transform(df_test[['Pclass', 'Fare']]), columns=['Pclass', 'Fare'])
df_test['Pclass'] = df_test_std['Pclass']
df_test['Fare'] = df_test_std['Fare']
# ラベル エンコーディング
# Label Encoding
df_test ['Sex'] = encoder_sex.transform(df_test ['Sex'].values)
##############################
# 結果を予想する
# Predict results
##############################
x_test = df_test.values
y_test = model.predict(x_test)
# PassengerId のDataFrameと結果を結合する
# Combine the data frame of PassengerId and the result
df_output = pandas.concat([df_test_index, pandas.DataFrame(y_test, columns=['Survived'])], axis=1)
# result.csvをカレントディレクトリに書き込む
# Write result.csv to the current directory
df_output.to_csv('result.csv', index=False)
上記をKaggleの環境で記述します。
「Run All」を実行し、result.csvが作成されることを確認します。
「Commit」⇒「Open Version」⇒「Submit to Competition」で提出します。
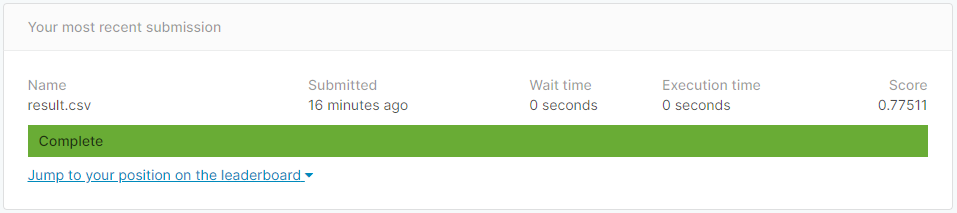
スコアが「0.77511」になりました。
7.まとめ
今回は5種類のモデルを比較し、パラメータチューニングすることでスコアを少し上げることができました。
次回は scikit-learn のいろいろなモデルから、より適したモデルを調べてみたいと思います。
履歴
2019/12/29 初版公開
2020/01/01 次回のリンク追加
2020/01/03 ソースのコメント修正