Recurrent convolutional neural network for object recognition (RCNN) の解説になります。2015年の論文で少し古いですが、この論文を引用する論文が最近もあるので調べることになりました。グーグルでRCNNを検索するとObject Detectionの Region-based cnn が検索されますが、それとは別物なので注意してください。
RCNNの概要
RCNNではCNNにRNNの概念を適用したモデルになります。そのため、Recurrent Convolutional Layer(RCL) と言う新しい概念を提案しています。下記の図は左側がRCLで、右側はRCLを使った全体的なモデル図になります。
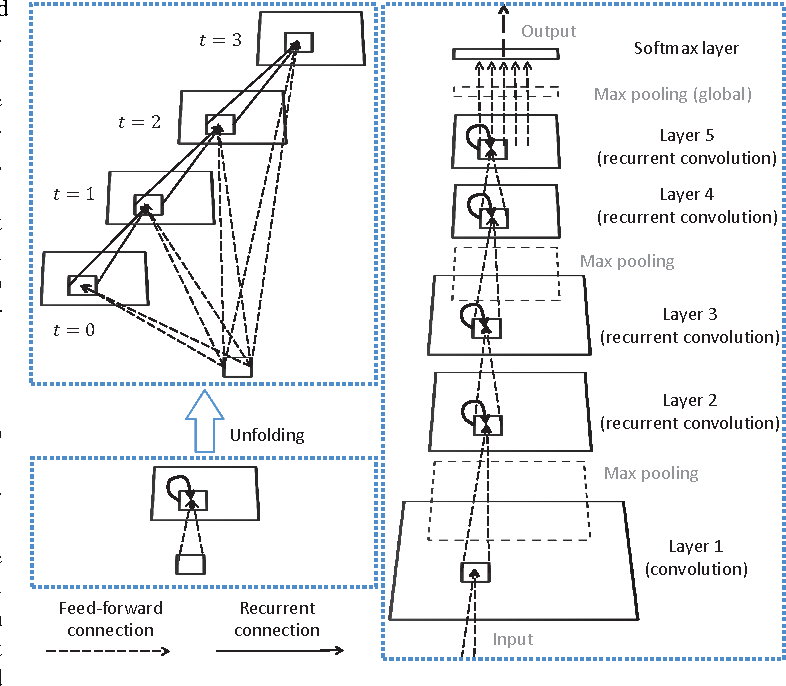
[左:RCL; 右:全体モデル]
ご覧の通り、右側の図の recurrent convolution layer(RCL) を普通の convolutional layer に変えると、普通のCNNになることが分かります。普通のCNNとの違いは、convolutional layer に RNNの recurrent を表す矢印が付いていることだけです。つまり、RCNNは convolutional layer を recurrent convolutional layer に変えただけなので、RCLだけを理解すると RCNN は全部理解できたとも言えると思います。(モデルの全体アーキテクチャは厳密に検討してないと論文で明らかにしていますので、全体アーキテクチャはそこまで重要ではないと思われます)
RCLの概要
Convolutional Layer に recurrent の概念を適用するために、RNNで使われる timestep と state を再定義し使ったのが RCL になります。Object Recognitionには一枚の画像がinputになり、時系列ではないので、RNNの概念をCNNにそもまま適用するのは難しいです。どうRCLがRNNの概念を使っているかを説明するために、RNNと比較をしたいと思います。
RNNの概要
下記の図はRNNの簡略図になります。
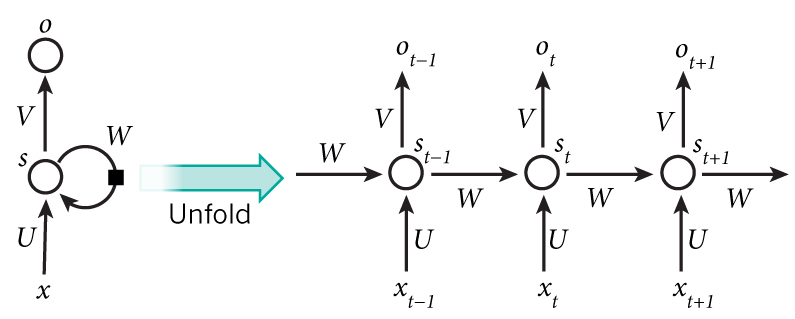
[一般的なRNNの図]
上記の図を数式で表すと下記のようになります。
s_t = g(U*x_t + W*s_{t-1} + b_s) \\
o_t = g(V*s_t + b_o)
ここで st は state で、bs と b0 はバイアス、g は tanh のような activation関数になります。この図で分かるように、 xt を計算するために st-1 を通じて過去のデータの xt-1 を参考にしていることが分かります。
RCLとRNNの違い
上記のRNNの図をRCLに変えるとこのようになります。説明のために timestep は3に限定しました。
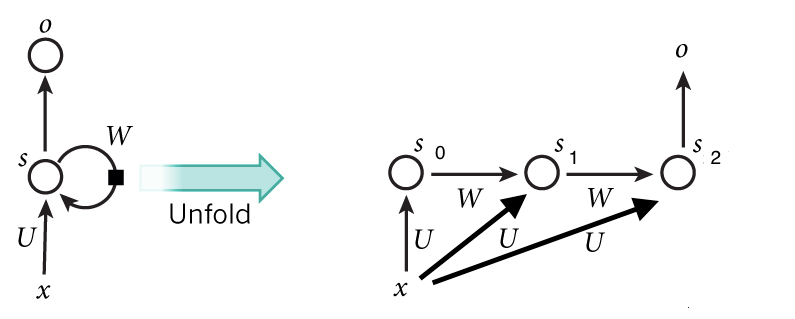
まず違うのは
- t=0 の時の initial state がないこと。RNNの場合はinitial state を設定しますが、RCLの場合は t=0 は単純な feed forward の CNN になります。
- input が timestep ごとに変わらず同じ x であること。
- U と W が Convolution であること。 (RNNはfully connected layer)
- アウトプットの o は最後の state そのものになること (Vが削除された)
数式にまとめると下記の通りです。
s_0 = g(U◎x + b_s) \\
s_t = g(U◎x + W◎s_{t-1} + b_s); \quad t \geq 1\\
o = s_T
元論文の g は relu と local response normalization(LRN) の組み合わせになりますが、最近の論文を見ると LRN の代わりに batch normalization を使っている論文が多いので g は relu(bn(o)) だと想定します。◎は convolution を意味します。bs はバイアスですが、バイアスを付けない論文もたまに見ますね。
一般的な convolutional layer と比較をすると下記のような図になります。
左が2層の convolutional layer を重ねたもので、右が2層のRCLを重ねたものになります。
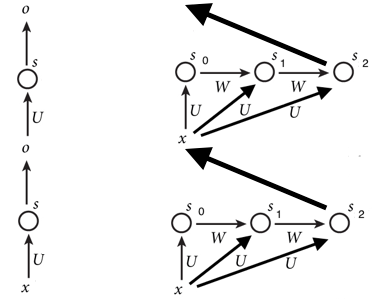
ご覧の通り、一般的なCNNはまっすぐに進むことに比べ、RCLは横にconv layer 層が膨らんでいます。
RNNはhidden layer が state になりますが、RCL は convolution をかけた結果、つまり activation maps が state になります。
なるべくRNNと比較して説明をしたかったですが、逆に分かりづらかったかも知れないですね。
簡単なコード実装
実際のコードを見ると分かりやすいかも知らないので書いて見ました。
まずはRCLを実装。
import tensorflow as tf
def rcl(x, filters, kernel_size, timesteps=4):
"""
RCLの実装。元の論文と少し異なる部分があります。
なるべく数式と同じ形に合わせました。
"""
# 使用するパーツの定義
# Ux(feedforward) はいつも同じなのであらかじめて定義する
U_x = tf.layers.conv2d(inputs=u, filters=filters, kernel_size=kernel_size,
padding="same", name="feedforward")
# Ws(recurrent) の部分。
W = lambda s, reuse: tf.layers.conv2d(inputs=s, filters=filters, kernel_size=kernel_size,
padding="same", reuse=reuse, name="recurrent")
bias = tf.get_variable(name="bias", shape=U_x.get_shape())
activ = lambda z: tf.nn.relu(tf.layers.batch_normalization(z), name="activ")
def rcl_step(state, timestep):
if timestep == 0:
state_new = activ(U_x + bias)
elif timestep == 1:
state_new = activ(U_x + W(state, reuse=False) + bias)
else:
state_new = activ(U_x + W(state, reuse=True) + bias)
return state_new
# 決められたstep数に合わせてRCLをunfold
state_t = None
for t in range(timesteps):
state_new = rcl_step(state_t, t)
state_t = state_new
return state_t
これを元にRCNNを実装すると下記のようになります。
import tensorflow as tf
...
n_filters = 92
x = tf.placeholder
layer1_conv = tf.layers.conv2d(x, filters=n_filters)
layer1_pool = tf.layers.max_pool2d(layer1_conv)
layer2_rcl = rcl(layer1_pool, n_filters, timesteps=4)
layer3_rcl = rcl(layer2_rcl, n_filters, timesteps=4)
layer3_pool = tf.layers.max_pool2d(layer3_rcl)
...
このように convolutional layerの代わりに使えます。
RCNNのアーキテクチャーのモチベーションは論文に簡単に紹介されてますので興味がある方は読んで見てください。時間があれば私が追記するかも知りません。
もし何か間違っているところや分かりづらい部分がありましたらコメントください。
もっと簡単なRCLの実装はここを参照
https://github.com/jacobzweig/Keras-RCNN/blob/master/Keras_RCNN.py