前回は環境構築を行いました。
今回はScrapyの基礎を勉強します。
注意事項
この投稿は単純な勉強の記録です。私はWeb Scrapingに経験がないですから、間違ったことをやる可能性も高いと思います。その時はコメントで教えていただけると幸いです。そして、この投稿の内容はScrapyの公式ホームページを参考にしています。
今回の流れ
- Scrapyプロジェクトの作成
- ウェブサイトからデータ抽出のためのspider作成
- spiderを利用しデータ抽出
1. Scrapyプロジェクトの作成
Scrapyフレームワークを使用するには、まずScrapyのプロジェクトを作成する必要があります。好みのフォルダーで下記のコマンドを入力します。
docker/app$ scrapy startproject tutorial
うまくできた場合、下記のように表示されます
New Scrapy project 'tutorial', using template directory '/usr/local/lib/python3.6/dist-packages/scrapy/templates/project', created in:
/app/tutorial
You can start your first spider with:
cd tutorial
scrapy genspider example example.com
作成されたプロジェクトの構成は下記の通りです
|-- scrapy.cfg # configファイル
`-- tutorial # プロジェクトのpythonモジュール。
|-- __init__.py
|-- __pycache__
|-- items.py
|-- middlewares.py
|-- pipelines.py
|-- settings.py
`-- spiders # 作成したspiderを入れるフォルダー
|-- __init__.py
`-- __pycache__
4 directories, 7 files
これでScrapyのプロジェクトを作成しました。
2. ウェブサイトからデータ抽出のためのspider作成
spiderはウェブサイトをどう探索するかを決めるclassになります。これにはcrawl(リンクを追う)ことやデータ抽出のことも含まれます。つまり、spiderは私たちの代わりにウェブサイトからデータを持ってくれるclassってことです。
Scrapyではspiderを簡単に作成することができます。今回は公式ホームページのチュートリアルで使っているQuatesサイト (http://quotes.toscrape.com/) を探索するspiderを作成します。
Scrapyのプロジェクトのroot directoryにて下記を入力します。
docker/app/tutorial$ scrapy genspider quotes quotes.toscrape.com
実行結果は下記の通りです。
Created spider 'quotes' using template 'basic' in module:
tutorial.spiders.quotes
そうすると、tutorial/spiderのフォルダーにquotes.pyが作成されていることが分かります。中身を見ると下記の通りです。各項目の説明はコメントに書いています。
# -*- coding: utf-8 -*-
import scrapy
class QuotesSpider(scrapy.Spider):
# spiderの名前。必ずユニークな必要がある
name = 'quotes'
# 探索するドメイン
allowed_domains = ['quotes.toscrape.com']
# spiderが探索するURL
start_urls = ['http://quotes.toscrape.com/']
def parse(self, response):
"""
各requestに対するreponseを処理する。
"""
pass
このspiderのparseメソッドを書きます。
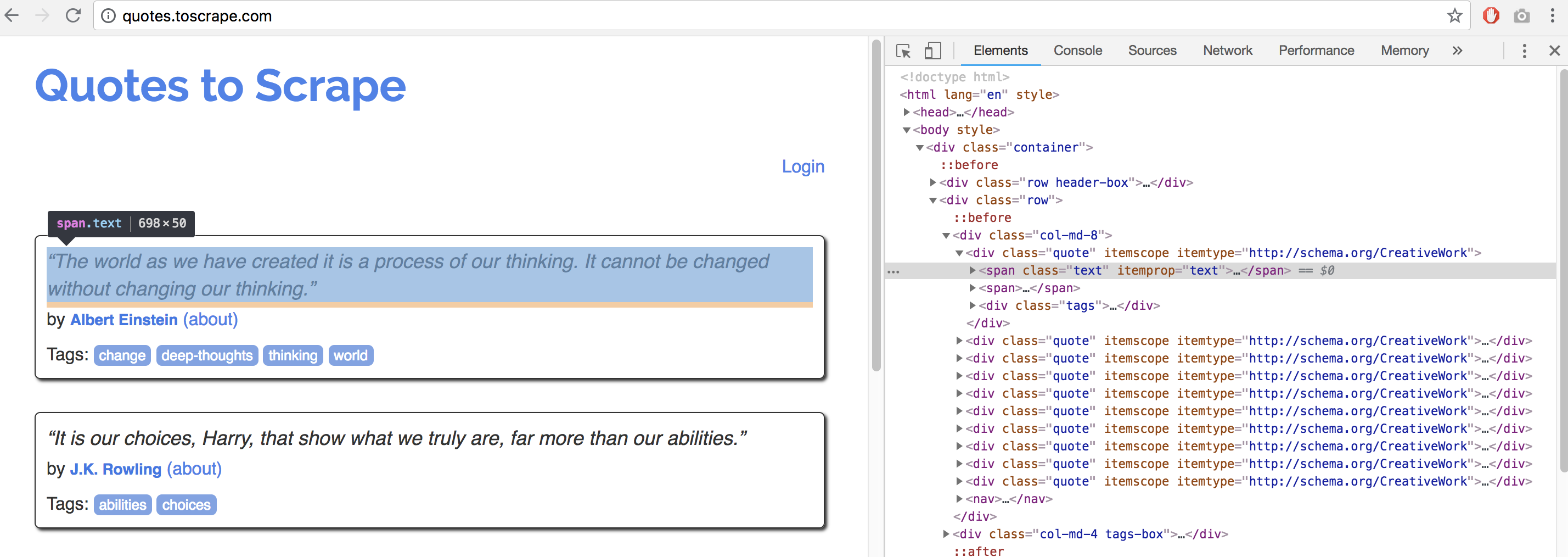
ウェブページを見ると、div の class "quote"の中の、 span class "text" に欲しい名言が書かれていることが分かります。
<div class="quote" itemscope="" itemtype="http://schema.org/CreativeWork">
<span class="text" itemprop="text">
....
</span>
....
</div>
この情報を取得する方法として、css方とXPath方がありますが、XPathの方がもっと強力なので私はXPathを使います。簡単に名言だけを抽出するコードは下記の通りです。
# -*- coding: utf-8 -*-
import scrapy
class QuotesSpider(scrapy.Spider):
name = 'quotes'
allowed_domains = ['quotes.toscrape.com']
start_urls = ['http://quotes.toscrape.com/']
def parse(self, response):
quotes = response.xpath("//div[@class='quote']/span[@class='text']/text()").extract()
yield {'quotes': quotes}
XPathについては次回に解説します。これでspiderの準備ができました。
3. spiderを利用しデータ抽出
今回は簡単なコマンドラインでの抽出を行います。
docker/app/tutorial$ scrapy crawl quotes
そうするとちゃんと名言を取得できることが分かります。
{
'quotes': ['“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”',
'“It is our choices, Harry, that show what we truly are, far more than our abilities.”',
'“There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.”',
'“The person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably stupid.”',
"“Imperfection is beauty, madness is genius and it's better to be absolutely ridiculous than absolutely boring.”",
'“Try not to become a man of success. Rather become a man of value.”',
'“It is better to be hated for what you are than to be loved for what you are not.”',
"“I have not failed. I've just found 10,000 ways that won't work.”",
"“A woman is like a tea bag; you never know how strong it is until it's in hot water.”",
'“A day without sunshine is like, you know, night.”']
}
最後に
今回は簡単なScrapyの基礎を勉強しました。次回はもう少し複雑なspiderを作ってみたいと思います。