はじめに
機械学習をノーコード・ローコードで実装できるAutoMLサービスが台頭してからしばらく経ちますが、データの前処理や予測後の補正、モデルパフォーマンスの定点観測、再学習などの機械学習システムの運用(MLOps)は、昨今のAutoMLサービスだけでは不十分な点も多いと思います。
また、AutoMLを使わずにPythonで独自の機械学習モデルの開発を行ってきた方にとって、自分の書いたコードをシステム上で安定稼働させるのはなかなかにしんどいのではないでしょうか。これは、データサイエンス(実験と検証)フェーズからMLエンジニアリング(システム構築と運用)フェーズに移行する際の大きなハードルとなっているかと思います。
そんな課題を解決してくれるのがVertexAI Pipelinesです。
ざっくりいうとKubeflowがサーバレス環境で実行できるサービスです。Google CloudのサービスであるVeretexAIの1機能です。
VertexAI PipelinesというよりKubeflowの概念となりますが、以下のような流れでパイプラインを開発・実行します。
- コンポーネントと呼ばれる処理の塊をPythonの関数のように定義する。
- コンポーネントを組み合わせて一連の処理を行うパイプラインを定義する。(こちらも関数のように定義する。以下パイプライン関数と呼ぶ。)
- このパイプライン関数をコンパイルしてテンプレートファイル(.json)を作成する。
- テンプレートファイルを指定して、ジョブを実行する。
本記事では、これら一連の作業をHello Worldパイプラインを例にしてご紹介します。
コンポーネントやパイプラインの説明は別記事にしますので、そちらをご確認ください。
VertexAI Pipelinesの特徴
- コンポーネントに対してそれぞれにサーバが割り当てられる。
- コンポーネント間のデータ連携はサーバ間の連携とほぼ同義。
- サーバに対して割り当てるスペック(CPUやメモリ)が指定できるので、重たい処理を行うコンポーネントには高メモリを割り当てて、軽いコンポーネントには低スペックを割り当てるなど、コストの最適化が図りやすい。
- サーバが立ち上がるのに2分ほどかかるので、サッと分析してすぐに結果がほしい時などのサンドボックス的な使い方には不向き。 (その時はおとなしくノートブックを使いましょう。)
- Pythonであれば殆どの処理は問題なく動く。
- MLに限らず様々なワークフローが実行可能です。例えば、自動化したいデータ処理や分析、ETLなんかもやろうと思えばできます。もちろん、その場合はData FusionやWorkflowsを使ったほうが良いじゃんという話もありますが...
Hello World なパイプラインを書いてみる
前置きが長くなりましたが、実際にコードを書いていこうと思います。
まずは最もシンプルなパイプラインを書いてみます。
注意事項
以下2021年11月現在でのコードを記載します。
バージョン違いによる互換性によってはエラーとなったり想定外の挙動となる可能性があります。
必要なライブラリをインストールする
pip install kfp==1.8.9 google-cloud-aiplatform==1.7.1
コンポーネントを作成する
関数をコンポーネント化する方法はいくつか存在しますが、本記事では以下の2通りを試してみます。
* デコレータ@component
* create_component_from_func_v2
@component
修飾対象となっている関数をコンポーネント化します。
非修飾関数の引数は型指定を行ってください。
from kfp.v2.dsl import component
@component(base_image="python:3.7")
def say_hello_op(message:str):
print(f"Hi. {message}")
create_component_from_func_v2
コンポーネント化する関数に対して単体テストをしたい場合や、ノートブックなどで個別利用をしたい場合に使用することが多いです。
第一引数にはコンポーネント化したい関数を指定し、他の引数は@componentと同じです。
from kfp.components import create_component_from_func_v2
def say_hello(message:str):
print(f"Hi. {message}")
say_hello_op = create_component_from_func_v2(
say_hello,
base_image="python:3.7")
注意点
kfpのバージョンが1.9以上だと使用できなくなるようです。コンポーネント化を実行すると以下のような警告が出ます。
FutureWarning: create_component_from_func_v2() has been deprecated and will be removed in KFP v1.9. Please use kfp.v2.components.create_component_from_func() instead.
kfp>=1.9の場合は、代わりにkfp.v2.components.create_component_from_func()を使いましょう。
パイプラインを作成する
先程作成したコンポーネントを用いて、パイプラインを作成します。
作成にはデコレータ@pipelineを使用します。
from kfp import dsl
@dsl.pipeline(
name="tutorial-pipeline"
)
def tutorial_pipeline():
say_hello_op(message="hoge")
pass
パイプラインをコンパイルする
パイプラインを実行する前に、上記で作成したパイプライン関数をテンプレートとしてjsonファイルにコンパイルします。
from kfp.v2 import compiler
compiler.Compiler().compile(
pipeline_func = tutorial_pipeline,
package_path = "任意のJSONファイル保存先パス",
)
パイプラインを実行する
上記でコンパイルしたテンプレートを実行します。VertexAI Pipelinesで実行するため、ライブラリはGoogle Cloudのもの(google-cloud-aiplatform)を使用します。
import google.cloud.aiplatform as aip
aip.init(
project="任意のGCPプロジェクトID",
location="us-central1" # 任意のリージョンでよいが、2021年11月現在、asia-northeast1(Tokyo)はサポートされていない
)
aip.PipelineJob(
display_name = "任意のパイプライン名",
template_path = "上記でコンパイルしたJSONファイルパス",
pipeline_root = "gs://任意のGCSバケット名/path/to/xxx"
).run()
PipelineJobの引数について
display_name
パイプラインの表示名の名前を指定します。2021年11月現在ではVertexAI Pipelinesのコンソール画面への表示はないようですが、必須の引数なので何かしら値を入れておきます。
template_path
パイプラインをコンパイルするときに指定したjsonファイルのパスを指定します。
pipeline_root
GCSのURIを指定します。指定されたパスにパイプライン実行中の生成物が保存されます。
PipelineJobの実行部分について
run()を実行すると、パイプライン実行が完了するまで待ちます。
submit()を実行すると、ジョブキューだけ投げてプログラム自体は終了します。とりあえずパイプライン処理だけ投げといて、他の作業をしたい場合はこちらを実行するとよいでしょう。
実行後
実行するとVertexAI Pipelinesのコンソールで実行中のパイプラインを確認することができます。今回は非常にシンプルなパイプラインなので数分以内に完了すると思います。
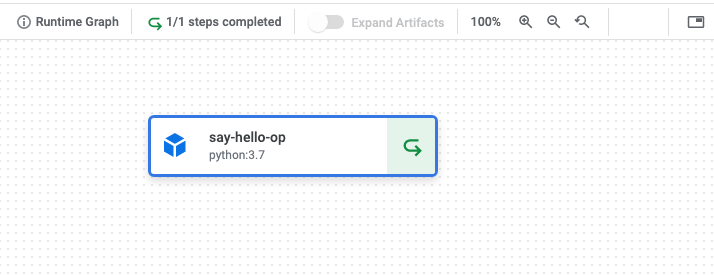
今回は1つのコンポーネント(say_hello_op)が実行されていることが分かります。
コンポーネント内部でのログ(print関数など)は、この画面でコンポーネントをクリックしたときに画面右側に出てくる「ログを表示」ボタンから確認することができます。
全体のコード
補足として、これまでに書いたコードの全体を書いておきます。
これを実行することでパイプラインの作成・コンパイル・実行がされます。
from kfp import dsl
from kfp.v2 import compiler
from kfp.v2.dsl import component
import google.cloud.aiplatform as aip
# コンポーネントの作成
@component(base_image="python:3.7")
def say_hello_op(message:str):
print(f"Hi. {message}",type(message))
# パイプラインの作成
@dsl.pipeline(
name="tutorial-pipeline"
)
def tutorial_pipeline():
say_hello_op(message="hoge")
pass
# コンパイル
compiler.Compiler().compile(
pipeline_func = tutorial_pipeline,
package_path = "任意のJSONファイル保存先パス",
)
# パイプラインの実行
aip.init(
project="任意のGCPプロジェクトID",
location="us-central1"
)
aip.PipelineJob(
display_name = "任意のパイプライン名",
template_path = "上記でコンパイルしたJSONファイルパス",
pipeline_root = "gs://任意のGCSバケット名/path/to/xxx"
).run()
さいごに
VertexAI Pipelinesをとりあえず実行してみるところまでは本記事で紹介しました。
ただし、ここまでは超入門ですので、実際にMLOpsで使える知識としては不十分です。
別記事に続きを書いていますので、そちらをご覧頂ければと思います。