はじめに
本記事ではVertexAI Pipelinesで用いる基本的なコンポーネントの書き方について紹介します。
そもそものVeretexAI Pipelinesについての説明や、コンポーネントの作成から実行までの流れについては、以下の記事を先にお読みください。
本記事は以下の記事を前提にお話しますので、VeretexAI Pipelinesが全く初めての方には強く推奨します。
VertexAI Pipelines 入門編その0 Hello World
注意事項
記載されているコードは、2021年11月現在、以下のライブラリでのバージョンで実行が確認されたものです。
kfp==1.8.9
google-cloud-aiplatform==1.7.1
バージョンの互換性によってはエラーとなったり想定外の挙動となる可能性があります。
様々なコンポーネントの書き方
先述の記事で紹介したものは、シンプルなコンポーネントとパイプラインでした。ここからはもう少し実用的なコンポーネントの説明をしていきます。
シンプルな出力を行うコンポーネント
出力が文字もしくは数値である場合のコンポーネントです。
通常の関数のようにreturnで出力でOKです。
ただし、出力において型宣言を行う必要があります。
from kfp.v2.dsl import component
@component(base_image="python:3.7")
def generate_name_op(first_name:str, last_name:str) -> str:
return f"{first_name} {last_name}"
パイプラインでの使用方法
パイプラインで上述のコンポーネントを用いる場合は以下のように書きます。
コンポーネントから出力された値を受け入れる別のコンポーネントも併せて書いています。
注意が必要なのが、パイプライン上でのコンポーネント出力の扱い方です。
今回のケースは単純に1つの値をreturnしているので、コンポーネントからの出力変数(out_1)には、outputというアトリビュートに出力値を持つclassが格納されます。
このoutputに出力値が格納されていますので、これを別コンポーネントに連携します。
from kfp import dsl
from kfp.v2.dsl import component
# 文字列の出力を受け入れるコンポーネント
@component(base_image="python:3.7")
def display_str_op(var: str):
print(var)
pass
@dsl.pipeline(
name="tutorial-pipeline"
)
def tutorial_pipeline():
out_1 = generate_name_op("バーテックス","太郎")
display_str_op(out_1.output) # .outputを忘れずに、、、
pass
パイプラインのコンパイルと実行は別記事で解説しているので、そちらをご確認ください。
VertexAI Pipelines 入門編その0 Hello World
実行すると以下のようなパイプライン画面をVeretexAI Pipelines上で見ることができます。
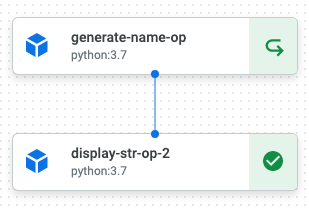
ライブラリを使用するコンポーネント
ライブラリをコンポーネント内で使用したい場合についてです。
通常のpythonでの感覚とは異なるので要注意です。
ライブラリをimportするのはグローバル領域ではなく、関数の内部で行う必要があります。これは、コンポーネント1つに対してVertexAIがサーバを割り当て、関数の内部のみが実行されるためです。(コンパイルされたパイプラインのjsonファイルを見ると、関数の内部に書かれたコードだけが記述されていることがわかります。)
外部ライブラリ(pip installが必要なもの)を使用したい場合には、@componentやcreate_component_from_func_v2の引数packages_to_installに使用するパッケージを配列で指定します。
バージョンも指定したい場合は、requirement.txtの記述方法と同様に、パッケージ名==バージョンなどと記述します。
from kfp.v2.dsl import component
@component(base_image="python:3.7")
def generate_current_datetime_op() -> str:
import datetime
return datetime.datetime.now().isoformat()
@component(base_image="python:3.7",packages_to_install=["pandas==1.3.4"])
def count_iris_data_op() -> int:
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/mwaskom/seaborn-data/master/iris.csv')
return df.shape[0]
パイプラインでの使用方法は上述した「パイプラインでの使用方法」と同様です。
listやdictの入出力を行うコンポーネント
dict、list、pandas.DataFrameなどの出力をしたい場合は通常のreturnではうまく機能しません。
コンポーネント間でのデータ連携はサーバ間での連携とほぼ同義であるため、シンプルな値以外は直接連携できないからです。
出力するときは、listなら",".joinやなどで文字列として出力しておき、別コンポーネントの入力として扱う場合は、この文字列を引数として受け入れた後に、split(",")でparseしてあげると良いでしょう。
dictの場合は、出力の際はjson.dumps、入力ではjson.loadsによるパースが良いでしょう。(listもこの方法で良いかもしれません)
from kfp.v2.dsl import component
# listを文字列として出力するコンポーネント
@component(base_image="python:3.7")
def generate_list_op() -> str:
l = ["a","b","c"]
return ",".join(l)
# dictを文字列として出力するコンポーネント
@component(base_image="python:3.7")
def generate_dict_op() -> str:
import json
d = dict(
a = 1,
b = 2
)
return json.dumps(d)
# listを文字列として受け入れるコンポーネント
@component(base_image="python:3.7")
def display_list_op(list_string : str):
print(list_string.split(","))
pass
# dictを文字列として受け入れるコンポーネント
@component(base_image="python:3.7")
def display_dict_op(json_dumps_string : str):
import json
print(json.loads(json_dumps_string))
pass
パイプラインでの使用方法は上述した「パイプラインでの使用方法」と同様です。
boolを扱う場合
boolはコンポーネント間の入出力として使用する場合は正しく連携されるのですが、パイプライン上から直接コンポーネントの引数にboolを挿入するとintに変換されてしまうようです。
なので、boolを扱いたい場合は、intで0,1表現したほうが無難です。
DataFrameなどの文字列にしにくいデータの入出力
pandas.DataFrameなど、文字列にしにくい、もしくはjson.dumpsが面倒である(datetime等がある)場合は、Artifactを使用します。
コンポーネント化したい関数の引数でOutput[*]と型指定すると、Artifactと呼ばれる出力専用の変数として利用できます。このArtifactはpathというアトリビュートを持ち、これにはファイルの保存パスが自動的に挿入されます。このpathはさもローカルパスかのように扱えます。その後VertexAI PipelinesはファイルをGCSの適切な場所に保存してくれます。
Output[*]の*には以下のクラスが指定できます。
-
Dataset: データファイルを保存したい場合に指定します -
Model: モデルファイルに対して使用します -
Metrics: 評価指標などを表示したいときに使用します-
Metricsは.log_metricという関数を持ちます。 - 第一引数に指標名(日本語可)、第二引数に指標値を入れることで、VertexAI Pipelinesの実行画面に表示されます。
-
Outputは複数記述可能です。
この出力を別コンポーネントで用いる場合は、Input[*]を使用します。
from kfp.v2.dsl import component
from kfp.v2.dsl import Output, Input, Dataset, Metrics
# Output[Dataset]とOutput[Metrics]を出力するコンポーネント
@component(base_image="python:3.7",packages_to_install=["pandas==1.3.4"])
def generate_dataset_op(
output_dataset: Output[Dataset],
output_metrics: Output[Metrics],
head : int = 5
):
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/mwaskom/seaborn-data/master/iris.csv')
df = df.head(head)
# ローカルファイルとして保存するようにファイル保存ができる。
df.to_pickle(output_dataset.path)
# 指標の表示
output_metrics.log_metric("shape",df.shape)
pass
# Datasetを受け入れるコンポーネント
@component(base_image="python:3.7",packages_to_install=["pandas==1.3.4"])
def display_dataset_op(dataset : Input[Dataset]):
import pandas as pd
print(pd.read_pickle(dataset.path))
pass
パイプラインでの使用方法(複雑・複数の出力を扱う)
上述した「パイプラインでの使用方法」と異なり、こちらは出力値の扱い方が若干違います。
出力変数(out_1)には、outputではなくoutputsというアトリビュートをもつclassが格納されます。
このoutputsはキーにそれぞれの出力名、値にその出力値を持つdictです。
出力名は、今回のケースではgenerate_dataset_opの引数として設定した名前output_datasetやoutput_metricsを用います。
from kfp import dsl
@dsl.pipeline(
name="tutorial-pipeline"
)
def tutorial_pipeline():
out_1 = generate_dataset_op()
display_dataset_op(out_1.outputs["output_dataset"]) # outputsの中のキー(出力変数名)を指定する
pass
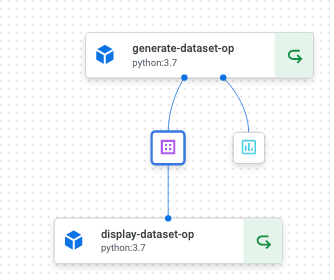
実行すると以下のようなパイプラインが表示されます。
画面内の紫のアイコンがDataset、青のアイコンがMetricsです。
Datasetアイコンをクリックすると、画面右側に情報が表示されます。
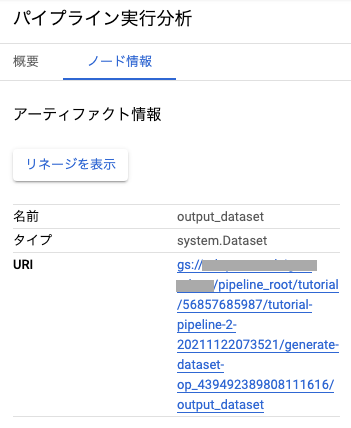
上記のURIにdf.to_pikcleされたpickleファイルが保存されています。
2021年11月現在では拡張子が付与されていないので違和感があるかもですが、ファイルとしては問題なく機能します。
Metricsはこのような情報が表示されます。
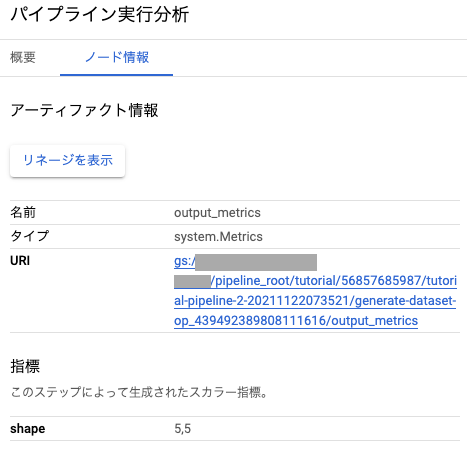
「指標」にlog_metricで指定した値が表示されています。
Output以外の方法で複数の値を出力する
NamedTupleによってシンプルな値を複数の出力に配置することができます。
from kfp.v2.dsl import component
from typing import NamedTuple
@component(base_image="python:3.7")
def generate_multiple_out_op(
in_a : str,
in_b : str,
) -> NamedTuple(
"Outputs",
[
("out_a", str),
("out_b", str),
]
):
out_a = in_a + "_out_a"
out_b = in_b + "_out_b"
return (out_a,out_b)
パイプラインでの使用方法(複雑・複数の出力を扱う)
こちらも先程と同様に、出力変数(out_1)にはoutputsというアトリビュートをもつclassが格納されます。
出力名は、今回のケースではgenerate_multiple_out_opのNamedTupleで設定した名前out_aやout_bです。
以下の例のdisplay_str_opは、こちらから流用しています。
from kfp import dsl
@dsl.pipeline(
name="tutorial-pipeline"
)
def tutorial_pipeline():
out_1 = generate_multiple_out_op(
in_a = "a",
in_b = "b"
)
display_str_op(out_1.outputs["out_a"])
display_str_op(out_1.outputs["out_b"])
pass
全体のコード
ここまで紹介してきたコンポーネントをまとめ、コンパイルから実行までを記述したコードをご共有します。
from kfp import dsl
from kfp.v2 import compiler
from kfp.v2.dsl import Output, Input, Dataset, Metrics
import google.cloud.aiplatform as aip
from typing import NamedTuple
# コンポーネントの作成
# シンプルな文字列を返すコンポーネント
@component(base_image="python:3.7")
def generate_name_op(first_name:str, last_name:str) -> str:
return f"{first_name} {last_name}"
# ライブラリを使用するコンポーネント
@component(base_image="python:3.7")
def generate_current_datetime_op() -> str:
import datetime
return datetime.datetime.now().isoformat()
# 外部ライブラリを使用するコンポーネント
@component(base_image="python:3.7",packages_to_install=["pandas==1.3.4"])
def count_iris_data_op() -> int:
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/mwaskom/seaborn-data/master/iris.csv')
return df.shape[0]
# listを文字列として出力するコンポーネント
@component(base_image="python:3.7")
def generate_list_op() -> str:
l = ["a","b","c"]
return ",".join(l)
# dictを文字列として出力するコンポーネント
@component(base_image="python:3.7")
def generate_dict_op() -> str:
import json
d = dict(
a = 1,
b = 2
)
return json.dumps(d)
# Output[Dataset]とOutput[Metrics]を出力するコンポーネント
@component(base_image="python:3.7",packages_to_install=["pandas==1.3.4"])
def generate_dataset_op(
output_dataset: Output[Dataset],
output_metrics: Output[Metrics],
head : int = 5
):
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/mwaskom/seaborn-data/master/iris.csv')
df = df.head(head)
# ローカルファイルとして保存するようにファイル保存ができる。
df.to_pickle(output_dataset.path)
# 指標の表示
output_metrics.log_metric("shape",df.shape)
pass
@component(base_image="python:3.7")
def generate_multiple_out_op(
in_a : str,
in_b : str,
) -> NamedTuple(
"Outputs",
[
("out_a", str),
("out_b", str),
]
):
out_a = in_a + "_out_a"
out_b = in_b + "_out_b"
return (out_a,out_b)
# 文字列を受け入れるコンポーネント
@component(base_image="python:3.7")
def display_str_op(var: str):
print(var)
pass
# intを受け入れるコンポーネント
@component(base_image="python:3.7")
def display_int_op(var: int):
print(var)
pass
# listを文字列として受け入れるコンポーネント
@component(base_image="python:3.7")
def display_list_op(list_string : str):
print(list_string.split(","))
pass
# dictを文字列として受け入れるコンポーネント
@component(base_image="python:3.7")
def display_dict_op(json_dumps_string : str):
import json
print(json.loads(json_dumps_string))
pass
# Datasetを受け入れるコンポーネント
@component(base_image="python:3.7",packages_to_install=["pandas==1.3.4"])
def display_dataset_op(dataset : Input[Dataset]):
import pandas as pd
print(pd.read_pickle(dataset.path))
pass
# パイプラインを作成
@dsl.pipeline(
name="tutorial-pipeline"
)
def tutorial_pipeline():
out_1 = generate_name_op("バーテックス","太郎")
display_str_op(out_1.output)
out_2 = generate_current_datetime_op()
display_str_op(out_2.output) # .outputを忘れずに...
out_3 = count_iris_data_op()
display_int_op(out_3.output)
out_4 = generate_list_op()
display_list_op(out_4.output)
out_5 = generate_dict_op()
display_dict_op(out_5.output)
out_6 = generate_dataset_op()
display_dataset_op(out_6.outputs["output_dataset"]) # outputsの中のキー(出力変数名)を指定する
out_7 = generate_multiple_out_op(
in_a = "a",
in_b = "b"
)
display_str_op(out_7.outputs["out_a"])
display_str_op(out_7.outputs["out_b"])
pass
# コンパイル
compiler.Compiler().compile(
pipeline_func = tutorial_pipeline,
package_path = "任意のパス",
)
# パイプラインの実行
aip.init(
project="任意のプロジェクトID",
location="us-central1"
)
aip.PipelineJob(
display_name = "tutorial pipeline",
template_path = "コンパイル時に指定したpackage_path",
pipeline_root = f"gs://任意のバケット/path/to/xxxx",
).submit()
キャッシュ問題
パイプラインを2回以上実行すると、ステータスアイコンが異なるコンポーネントが出てきます。
例えば、generate_current_datetime_opでの例を見てみます。
最初の実行では以下のような表示になるはずです。

もう一度実行すると、表示が若干異なります。
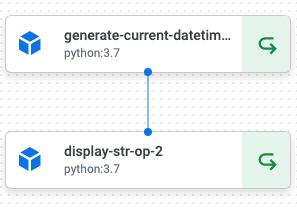
このU字のような矢印マークはキャッシュされたコンポーネントを表します。
コンポーネント内部のコードが同じで、かつ引数も同じである場合はインスタンスを立ち上げることなく即座に出力を返します(コンポーネント内部のログも再現されます)。
インスタンスの立ち上げ時間の短縮やコスト削減に寄与するので便利なのですが、毎回出力値が変わるようなコンポーネントでは注意が必要です。
generate_current_datetime_opは現在時刻を出力するコンポーネントですので、これがキャッシュされていると初回実行時の時刻が常に出力されてしまいますので、想定とは異なる挙動となってしまいます。
キャッシュを無効化したい場合は、全体のコードで記述したPipelineJobの引数にenable_caching=Falseを入れて実行します。
aip.PipelineJob(
enable_caching=False,
... # 先述と同様の引数を入れる
).submit()
ただし、これだとほか全てのコンポーネントのキャッシュも無効化されてしまいます。一部のコンポーネントのみキャッシュを無効化したい場合は、実行のたびに毎回値が変わるような引数を受け入れるコンポーネントを作成するなどの対策が必要です。
さいごに
本記事ではコンポーネントについて一通りご説明しました。
上記を応用すれば、データの前処理や機械学習モデルの作成、予測、評価、再学習が可能になるかと思います。
一方で、パイプラインにも色んな機能がありますのでご興味がある方は引き続き以下の記事をご覧ください。
VertexAI Pipelines 入門編その2 パイプラインを理解する