はじめに
微分可能レンダラーという研究があります。これは画像の描画過程を微分可能に近似することで、レンダラーへの入力(3次元モデルやカメラ姿勢など)とその出力(画像)の関係をディープラーニングで扱うことが出来るようになるというものです。
この考え方をアスキーアートに適用してみたところ、教師なし学習による精密なアスキーアート生成が可能となりました。
*趣味の活動ですので内容の正確さには期待しないでください。
背景
ディープラーニングでアスキーアートの自動生成を扱った研究として、2017年のDeepAA(日本語解説記事)があります。これはテキストとその描画結果である画像のデータを用意したうえで、逆向きの変換を一文字ずつ教師あり学習させるというものです。
この方法はそれなりの精度が出ているのですが、一文字ずつ学習している構成であることから精密な線の位置合わせができないという問題があります。また、正解データとしてテキストデータを必要とすることから学習データの確保が難しく、応用の拡がりが限定されます。
学習データの確保問題については、ペアデータを必要としないcycleGAN等が使えそうにも思えるのですが、そうではありません。アスキーアートっぽい画像への変換までは出来ても、それをテキストに戻すことが容易ではないからです(等幅フォントであればそれなりに上手く行くかもしれませんが、プロポーショナルフォントでは位置ずれが起こるため難しいです)。
今回実装した微分可能レンダラーを用いると、アスキーアートの描画過程も含めて学習することができるので、位置合わせの精度が改善します。
また、学習データにテキストデータが不要となるため、アスキーアートではない線画データのみでの学習が可能となります。写真からの直接変換への拡張も考えることができます。
ちなみに、オープンアクセスでないため読んでいないのですが、ASCII Art Synthesis from Natural Photographs
は写真からの直接変換をやっています。
コード
コードはこちらにありますので細かい点はそちらを参照してください。
レンダラーの実装
レンダラーに関するコードはlayers.pyにあります。
文字を左から順に描画していく過程を考えます。
プロポーショナルフォントの利用を想定していますので、今置いた文字の種類によって次に文字を置くことができる位置が変わります。モデルから文字を出力する場合、softmaxで出力する構成をとることが多いと思いますが、これは離散値のone-hotではないため、次に文字を置くことができる位置を確実に決められないという問題が発生します。
そこで、こちらの研究で提案されているgumbel-softmaxまたはstraight-through-gumbel-softmaxという手法を採用します。これによりone-hot変数を離散値として扱いつつも微分を近似計算することが可能になります。
文字の配置を決定するレイヤーは、ある位置の文字の出力確率を入力とし、次の文字を出せる位置を状態として持ちながら、サンプリングを行い文字を配置していくことを、左から右に向かってループすることで実現できます。
このレイヤーの微分は左方向に逆伝搬しますが、そのままだと長距離に渡って伝搬しすぎてしまうため、学習が困難になります。この問題には、逆伝搬時に微分を減衰させることにより対処しています(ここはもう少し上手い取扱いができるかもしれません)。
文字の適切な位置さえ決まってしまえば、文字の描画自体はフォントの画像を重みとしたTransposed Convolutionで表現できます。
今回はDeepAAで提供されているテンプレートをそのまま利用しました。
レンダラーに関する予備実験:スペース調整
予備実験に関するコードはexperiment_spacing.pyにあります。
アスキーアート職人たちは、狙った位置に線を書くために、半角スペース・全角スペース・ピリオドを組み合わせてスペース調整をするそうですが、これを学習できるかどうか実験してみます。
利用する文字は半角スペース・全角スペース・ピリオド・縦線の4種類とし、適切な位置に縦線を引くことを目標とします。
日本のアスキーアートの標準フォントと思われる12ポイントMSPゴシックでは、半角スペースは5ピクセル、全角スペースは11ピクセル、ピリオドは3ピクセルですので、目標とする合計スペースが3ピクセル、5ピクセル、あるいは8ピクセル以上であれば、この3種類の組み合わせでスペースを調整できることになります。
予備実験では、8ピクセル〜38ピクセルの位置に縦線を描画したものを目標画像とし、損失関数は単純にMSE損失、学習する変数は各文字のone-hot表現に対応するロジット値としました。
その他のパラメータ等はコードを参照してください。
予備実験の結果と考察
| 目標画像 | 出力画像 | サンプル平均 |
|---|---|---|
 |
 |
 |
全パターンで、線を正しい位置に描画することが学習出来ました。
ピリオドができるだけ出ないことが望ましいのですが、それもある程度学習できているように見えます。
ピリオドが2個以上になっている行を詳しく見てみましょう。
- 9ピクセル(ピリオド3個)
- 12ピクセル(ピリオド4個)
- 17ピクセル(ピリオド2個)
- 28ピクセル(ピリオド2個)
9、12、17ピクセルは、少し考えるとピリオドは必要最小限の個数であることがわかるので、これは問題ありません。28ピクセルについては、本当は(5, 5, 5, 5, 5, 3)のようにピリオド1個で表現できるはずですが、学習結果はピリオド2個になってしまっています。これは組み合わせとしては(11, 11, 3, 3)になります。学習過程では半角スペースよりも全角スペースのほうが、より損失を下げる傾向があるはずですので、全角スペースを用いるパターンが先に学習されてしまったものと思われます。詳細は省きますが、ピリオド1個の行でも不要なピリオドが出現している行がいくつかあります。
なお、学習過程を見ていると9, 12ピクセルは学習の進みが悪かったです。ピリオドを選ぶことは損失を上げる方向になりますので、それを乗り越える必要がある事がその原因と思われます。
画像から文字候補の変換モデル
画像から文字候補の変換モデルは、入力が画像で出力が文字候補の確率とします。典型的な2次元CNNを使いましたが、出力形状は縦方向が行単位、横方向がピクセル単位となりますので、ストライドとdilationを適当に組み合わせて受容野が正方形になるようにしています。
モデル構成については十分な検討をしていませんので、まだ改善できると思います。現状は過学習予防の観点で小さめの受容野になるようなモデルとしていますが、文字の位置調整の精度改善を考えるなら、特に右方向の受容野を大きめに取ることが重要になってくるはずです。
利用する文字のセットは、DeepAAの学習データで出現回数が多いものから順に324個を選びました(教師なし学習といいつつ一部教師データを利用していますが、限定的な利用なので目を瞑ってください…)。
損失関数
損失関数は形状に関わる部分と再構成に関わる部分の2つの項で構成しました。
形状に関わる部分としては、スタイル変換などでよく用いられているVGG19のcontent lossを利用しました。
VGGへの入力はRGBの3チャンネルである一方、アスキーアートの描画結果は白黒の1チャンネルですので、チャンネル数を合わせる必要があります。また、スケーリングや前処理(ぼかし等)にも選択の余地があります。今回はこれらの部分の最適化はせず、白地に黒線になるように白黒反転だけ行ったうえで、それを単に並べてチャンネル数を合わせました。
VGGのどの層を使うかについては、OpenAI Microscopeを参考にしました。曲率に対応するニューロンがconv3_1で出現しはじめるのでこれを使いました。ちなみにより低層の特徴を使うと線の位置精度は良くなりますが、点線が出やすくなる傾向があります。
再構成に関わる部分としては、正解線と予測線が近くにあることを要求するJaccard係数に類似した項を追加しました。この項によって空白や余分な線が出過ぎるのを軽減することができます。
実験
上記のモデルと損失関数を使い、線画からアスキーアートの生成を学習させました。
学習データには、Photo Sketchingで提供されている5000枚の線画データを利用しました。
結果
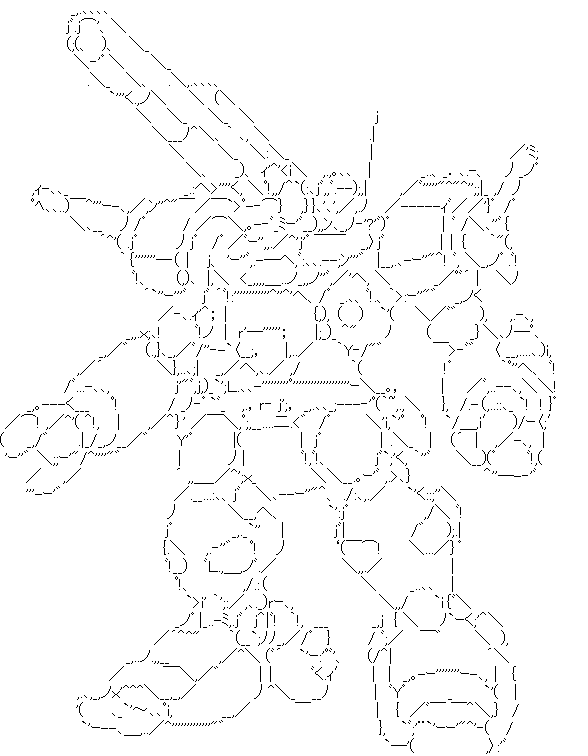
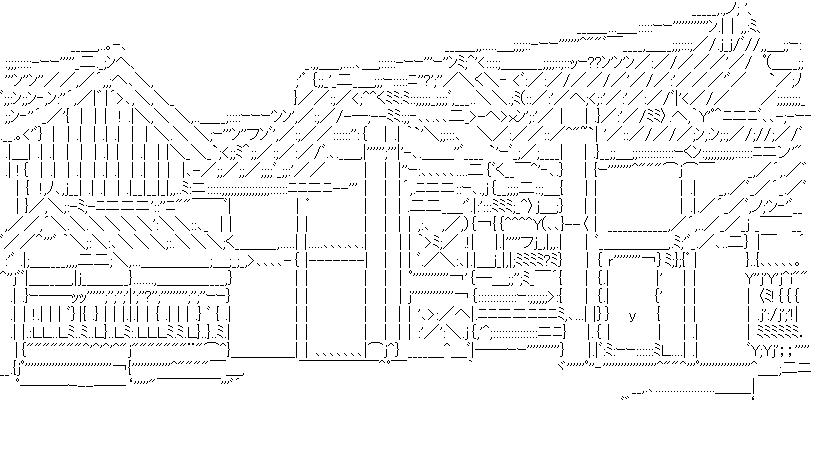
DeepAAのリポジトリより引用した画像を変換したものを何点か掲載します:
(その他の画像はこちらにあります)
| 目標画像 | DeepAA | 本手法 |
|---|---|---|
 |
 |
 |
|
|  |
|  |
| 
|
|  |
| 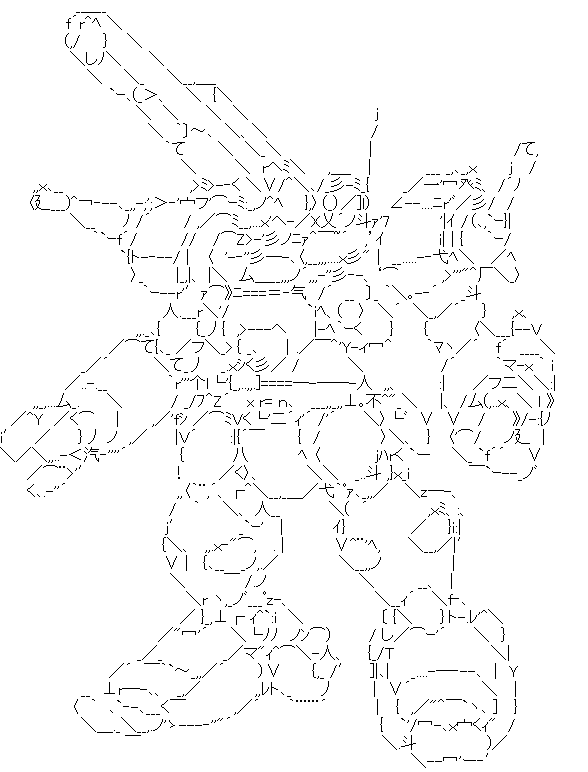 |
| 
|
| 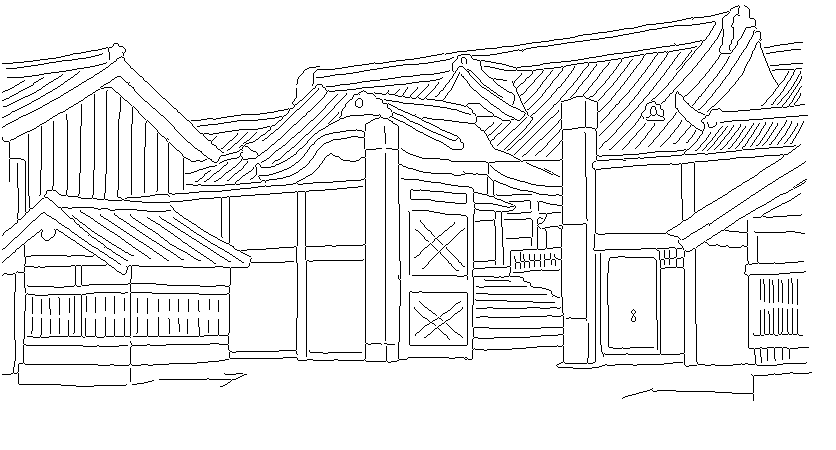 |
| 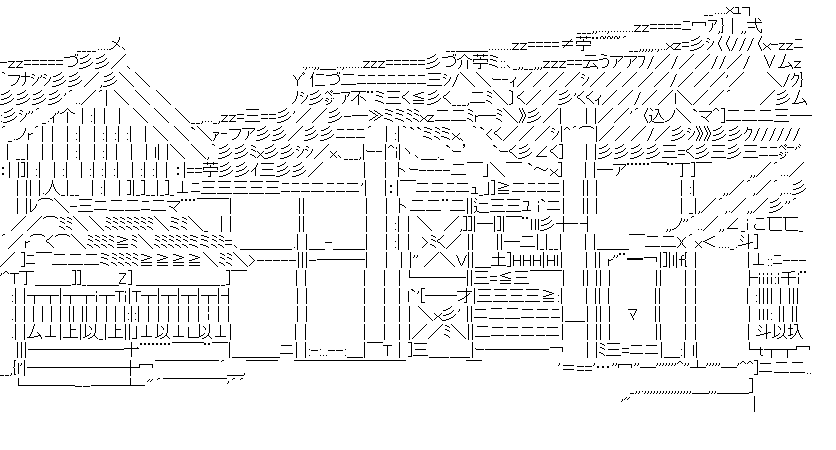 |
| 
|
考察
概ね精度良く変換が出来ているようですが、水平線や線が集まった部分などで、線が消える傾向があります。これは損失関数の加減次第なのですが、簡単に試した範囲では線が消えないようにすることと無駄な線が出ることがトレードオフになっていました。
DeepAAとの比較
DeepAAと比較すると、全体的に線の位置精度は良くなっています。DeepAAのほうが線がはっきりしているので、そちらのほうが好みの人もいるかもしれません。
職人との比較
職人は線を省いたりずらして描いたりすることで、自然な線のつながりを描き出しているようです。今回の手法は変換元画像の線を忠実になぞろうとしてしまうため、点線が出やすい傾向があります。特に目や顔の表情に関わる部分では、まだまだ開きがあると感じます。
また、職人の作品ではトーンを貼っているものもありますが、今回は線画データで学習を行いましたのでこれは出来なくても仕方ないですね。
課題
描画結果はこれまでの自動生成よりも高精度になりましたが、やはり職人と比べるとまだまだな部分があります。
ただ、微分可能レンダラーを使った手法の限界はまだまだ引き出せていないので、データ・モデル・損失関数などの工夫により改良していけるはずです。
微分可能レンダラー以外では特別なことはしていませんので、GAN等への拡張も難しくありません。
今回は文字セットを与えて学習させましたが、文字セットの選択方法も考えたいです。
この方法が確立できれば、別のフォントを利用することが簡単になります。
写真やイラストからの直接変換はまだ試していませんが、多少の変更でできそうです。
ラフスケッチ関連のこちらの研究のようなインタラクティブな編集ツールを作るのも面白そうです。
まとめ
-
アスキーアートの微分可能レンダラーを実装したことで、教師なし学習などの展開が可能となった
-
微分可能レンダラーとcontent lossを組み合わせた教師なし学習により、線画からアスキーアートの精密な変換ができた
-
まだまだ職人には及ばないが、改善の余地はある(モデル・損失関数・学習方法など)