はじめまして。
本業はアスキーアート (以下AA) 職人のOsciiArtといいます (本業ではない)。
AlphaGo対イ・セドルの対局を見て、「僕もディープラーニングで神AA職人を倒したい!」と思い、pythonをインストールしてちょうど一年の成果を書いていきます。
コードはこちらにアップしてあります。
https://github.com/OsciiArt/DeepAA
ここで扱うアスキーアートとは
ここで扱うAAとは、
こういうの……↓

ではなく、こういうの……↓
でもなく、こういうの……↓
ともちょっと違って、こういうの……↓

ではもちろんなく、こういうのです。↓

このような、線画を文字を作って再現した「トレースAA」と呼ばれるタイプのAAをここでは扱います。
詳細はwikipediaの「アスキーアート」のページの「プロポーショナルフォント」の項を参照してください。
wikipedia:アスキーアート - プロポーショナルフォント
フォント等の条件は2ちゃんねるの仕様である、
- MS Pゴシック
- サイズ16ピクセル
- 行間2ピクセル
が広く採用されています。
アスキーアートの良し悪し
誤解が多いのですが前提としてAAは基本的に手書きです。
(誤解の一例:Yahoo知恵袋:AAアスキーアートを2ちゃんねるで見るんですが、どうやって作るんですか?)
自動でAAを作るソフトはいくつか存在していますが人間の手書きには遠く及ばないのが現状です。
AAの良し悪しを判断する時に注意しなければならないのはサイズです。際限なく大きく作れば1文字で1ピクセルを表して完全に元画像を再現できます (ソフトでも)。そうではなく1文字でより多くの線を表現しサイズを小さく収めているAAが良いAAです。
つまり、AAの良し悪しは
元画像の再現度 ÷ サイズ
と定義できます。
学習データ
ディープラーニングの学習には元画像とAAのペアが大量に必要となります。しかし、AAは基本的に元画像とペアで発表されることはありません。そのため、データ収集は困難です。また、AAは元画像の線を大きくデフォルメするケースが多く、仮にペアが得られても学習は困難であると予想されます。
そこで今回は、AAから元画像らしきものを生成して学習データとしました。この辺のアプローチはシモセラ・エドガーらの研究 (ラフスケッチの自動線画化)を参考にしました。
手順
- AAを画像化します。

2. これでは実際の線画とはかけ離れているので、シモセラ・エドガーらのウェブサービスラフスケッチの自動線画化で画像を線画っぽくします。

3. 画像を64 x 64 ピクセルで切り出し、中央の16 x 16の領域に対応する文字を正解ラベルとします。
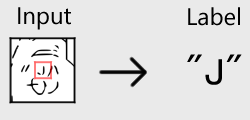
4. このような処理を約200個のAAに対して行い、学習データとしました。
学習
フレームワークはKeras (バックエンド: TensorFlow) を用いました。
ネットワークにはクラス分類を行う標準的な畳み込みニューラルネットワークを用いました。以下にコードを示します。
def DeepAA(num_label=615, drop_out=0.5, weight_decay=0.001, input_shape = [64, 64]):
"""
Build Deep Neural Network.
:param num_label: int, number of classes, equal to candidates of characters
:param drop_out: float
:param weight_decay: float
:return:
"""
reg = l2(weight_decay)
imageInput = Input(shape=input_shape)
x = Reshape([input_shape[0], input_shape[1], 1])(imageInput)
x = GaussianNoise(0.1)(x)
x = Convolution2D(16, 3, 3, border_mode='same', W_regularizer=reg, b_regularizer=reg, init=normal)(x)
x = BatchNormalization(axis=-3)(x)
x = Activation('relu')(x)
x = MaxPooling2D(pool_size=(2, 2), border_mode='same')(x)
x = Dropout(drop_out)(x)
x = Convolution2D(32, 3, 3, border_mode='same', W_regularizer=reg, b_regularizer=reg, init=normal)(x)
x = BatchNormalization(axis=-3)(x)
x = Activation('relu')(x)
x = MaxPooling2D(pool_size=(2, 2), border_mode='same')(x)
x = Dropout(drop_out)(x)
x = Convolution2D(64, 3, 3, border_mode='same', W_regularizer=reg, b_regularizer=reg, init=normal)(x)
x = BatchNormalization(axis=-3)(x)
x = Activation('relu')(x)
x = MaxPooling2D(pool_size=(2, 2), border_mode='same')(x)
x = Dropout(drop_out)(x)
x = Convolution2D(128, 3, 3, border_mode='same', W_regularizer=reg, b_regularizer=reg, init=normal)(x)
x = BatchNormalization(axis=-3)(x)
x = Activation('relu')(x)
x = MaxPooling2D(pool_size=(2, 2), border_mode='same')(x)
x = Flatten()(x)
x = Dropout(drop_out)(x)
y = Dense(num_label, activation='softmax')(x)
model = Model(input=imageInput, output=y)
return model
学習条件
- データ数: 484654
- バッチサイズ: 128
- 学習回数: 20,000 バッチ
- 損失関数: cross entropy
- 最適化関数: Adam
上記設定でGPUなしのマシンで2日程度学習させました。
結果
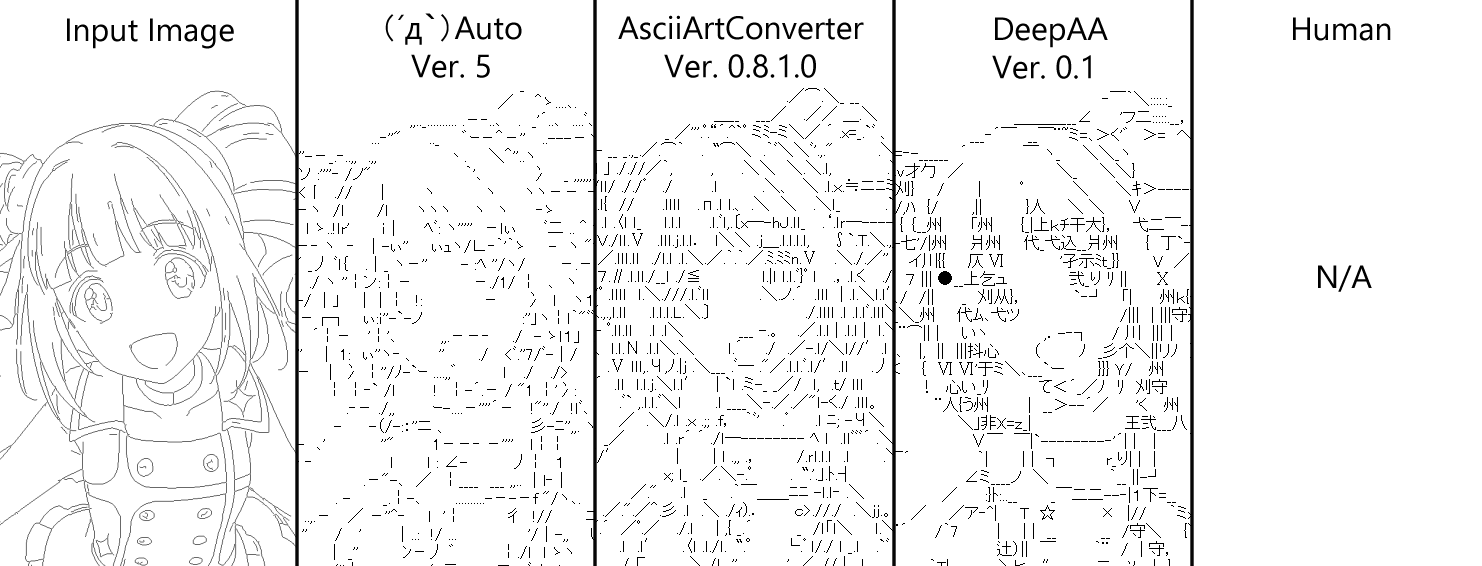
いくつかの他のAA自動作成ソフトとの比較を示します↓
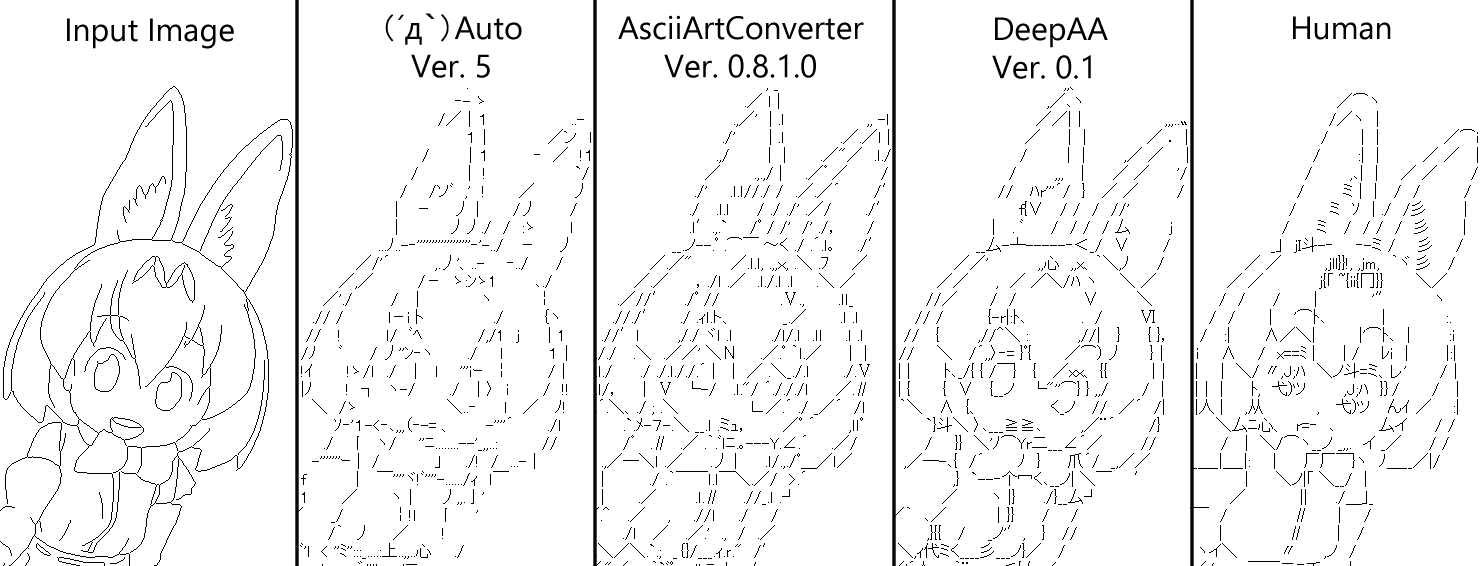
- Input Image: 元画像
- (´д`)Auto: 作成者 - kuronowish氏, 入手先 - (´д`)Editさいたま営業所の避難所
- AsciiArtConverter: 作成者 - うりゅP氏, 入手先 - test
- DeepAA: 本記事の提案手法 (以下DeepAA)
- Human: 手書きAA
サイズ設定は手書き時に選択されたもので統一しています。変換はいずれのソフトも初期設定です。
どのソフトも設定をいろいろ試行錯誤してよくしていくものなので初期設定ではやや横並びです。線が込み入った部分にピタリとハマる文字を選択する能力は提案手法がやや優れているように思います。
比較をもう一点↓
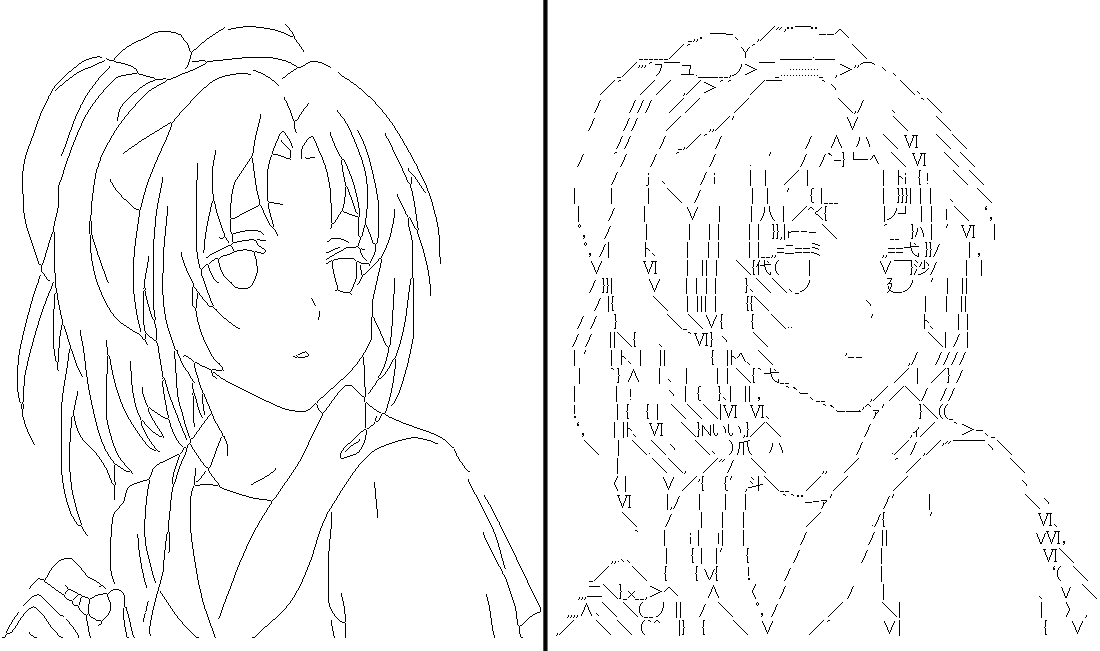
こちらは提案手法で上手く出力されたサイズで統一しています。よってかなりひいき目の比較になります。
しかしながら、DeepAAは特に目の作り方がかなり上手く、人間に勝るとも劣らない文字選択が出来ていると思います。
以下何点か作例を貼っていきます。
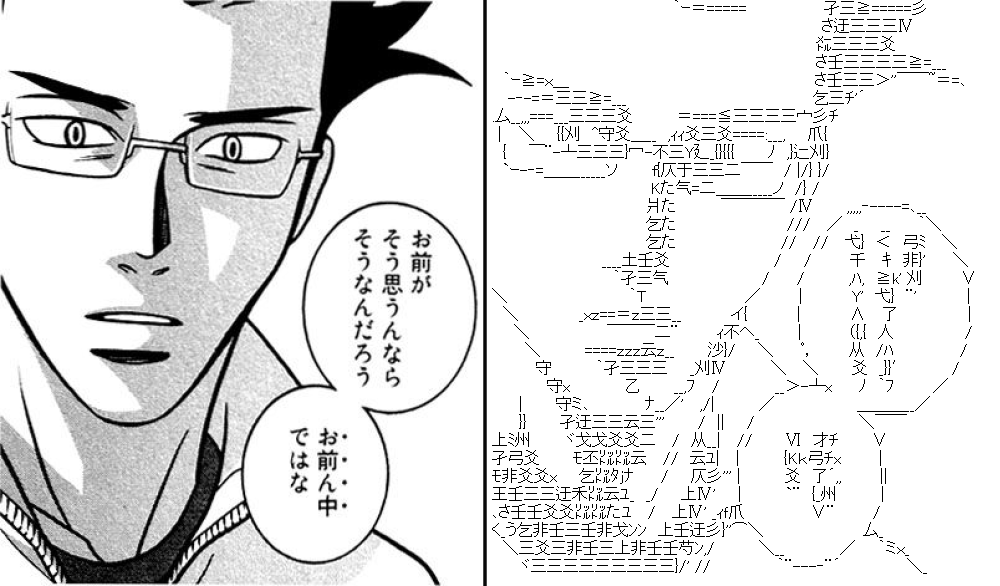
経験則的には線画は細線化した方が良い結果が得られやすいです。

あえて細線化せずベタもそのまま出力しても面白い結果が出ます。
いかがでしょうか。
課題
既存の自動AA作成ソフト以上の精度は得られたのではないかと思いますが、まだまだ手書きAAの精度には程遠い結果となりました。以下改善のための課題を記していきます。
ズレ
現状、手書きに比べてDeepAAの最大の弱点はズレだと思います。文字の幅が一定である等幅フォントと異なり、ここでは文字の幅が文字ごとに異なるプロポーショナルフォントを扱っています。等幅フォントの場合、画像のどこに文字を当てはめるかは一意的に決まりますが、プロポーショナルフォントでは文字の組み合わせによって位置を調整することができます。
例えば↓の例では、DeepAAの線は青く囲んだ部分ではガタガタですが、人が手直しすれば右のようにキレイにそろえることができます。(全角スペース (幅 11 ピクセル), 半角スペース (幅 5 ピクセル), ピリオド (幅 3 ピクセル) の組み合わせによって調整する。)
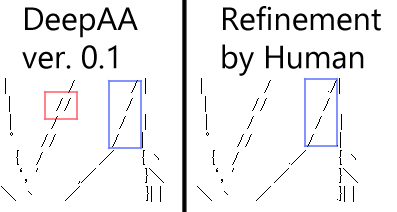
また、赤く囲んだ部分では「/」が 2 回当てはめられていますが、明らかに正解は 2 つの「/」の間の位置に 1 つ「/」を当てはめることです。
この問題は、学習データの段階で「どこ」に文字を当てはめるかは決まった上で、「なに」の文字を当てはめるかだけを学習させていることにあります。しかし、「どこ」を学習させるにはどうすればいいのか正直思いつきません。
線画化
AA画像の線画化にウェブサービスを使っているためデータ数を稼ぐときのネックになっているので代替案を考えたいところです。
学習回数
これまでCPUだけで学習させていたのですが、最近GPU環境を整えたのでより多くの回数を、より複雑なモデルで学習させるのも試したいです。