- 近年、レコメンド技術等で注目されているFactorization Machinesアルゴリズムをライブラリを使ってささっと試してみる導入記事です。
- 理論的な解説ではなくて動かすための記事です。
- 基本、チュートリアルをなぞって行く+補足です。
参考資料いろいろ
今回fastFMというライブラリを使用しました。またこのライブラリの説明&性能に関してはarXivにて公開されています。
- fastFM
Factorization Machinesの概要や動向を知りたい方はQiita内外に参考記事がありますので一部貼っておきます。また下記の書籍もfastFM扱ってます。
すごく乱暴に言うと、「行列分解を利用してて、スパースなデータに強い、回帰や分類・ランク付けができる」アルゴリズムです。
本編
導入
注意点あり。自身の環境の場合、以下の感じでした。
Python 3.6.10の場合
-
pip install fastFMで導入可能
Python 3.7.6の場合
- pipのインストールではエラーが発生。
- GitHub記載のソースからインストールで動作可能。
なので新しめの環境の方はソースからインストールするか、pyenvなどの複数のpythonを動作させられる環境を構築して3.6系を導入するか、Dockerなどで何かしら3.6な環境作るか、、、といった感じになると思います。
サンプルデータ
Factorization Machines(以下FM)系のサンプルですと、辞書型のものをサンプルデータに使う場合が多いように感じます。
[
{user:A, item:X, ...},
{user:B, item:Y, ...}, ...
]
みたいな。
スパースなデータだと確かにこういうデータを入力にすることが多い気がしますが、今回はシンプルなcsvを想定して扱ってみたいと思います。
カテゴリ,rating,is_A,is_B,is_C,is_X,is_Y,is_Z
A,5,0,0,1,0,1,0
A,1,1,0,0,0,0,1
B,2,0,1,0,0,0,0
B,5,0,0,0,0,1,0
C,1,1,0,0,0,0,1
C,4,0,0,0,0,1,0
...
一番下に全部バージョンを載せておきます。
値は適当に作ったダミーですが、
- カテゴリ情報の入った
カテゴリ列 - 1〜5までの5段階評価が入った
rating列 - フラグ情報が入った
is_?列- 商品を買ったフラグとか、ユーザ属性を示すフラグとかをイメージしていただければ
を想定しています。
処理の流れ確認 with 回帰分析
ライブラリの使い方自体はシンプルで、scikit-learn等を使ったことのある方ならおなじみの感じです。
まずはシンプルな回帰分析のロジックで処理の流れを作ってみます。
詳細は端折りますが、一般的なモデル作成は以下のような流れになると思われます。
- データの読み込み
- 前処理(モデルに合う形式にデータを変換)
- 「学習データ」(、「バリデーションデータ」)、「テストデータ」に分割
- 学習データでモデル作成
- テストデータにモデル適用
- 性能評価指標を定義して評価
今回は ratingを当てる ことをテーマに回帰モデルを作ってみます。
(わかりやすさのため、つどつどimportしてますが、一番上で全部importしちゃっても良いです。)
データ読み込み
import numpy as np
import pandas as pd
# csvデータ読み込み
raw = pd.read_csv('fm_sample.csv')
# ターゲットの列とその他の情報を分けます
target_label = "rating"
data_y = raw[target_label]
data_X = raw.drop(target_label, axis=1)
前処理〜データ分割
# 前処理
## 便利なカテゴリデータ処理ライブラリ、scikit-learnの便利機能をバンバン使います
import category_encoders as ce
## 指定の列をone-hotエンコードします
enc = ce.OneHotEncoder(cols=['カテゴリ'])
X = enc.fit_transform(data_X)
y = data_y
# データ分割
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=810)
モデル作成〜評価
評価はMAE(平均絶対誤差)にしていますが、MSEなどもささっと計算できます。
from sklearn import linear_model
from sklearn.metrics import mean_squared_error, mean_absolute_error
# モデル作成
reg = linear_model.LinearRegression()
reg.fit(X_train, y_train)
# 評価
## 学習データへの当てはまり具合
mean_absolute_error(y_train, reg.predict(X_train))
## テストデータの誤差
mean_absolute_error(y_test, reg.predict(X_test))
こんな流れになるかと思います。
評価部分はもちろん、算出された回帰線引いてみたり、誤差の外れ方見てみたりと本来ならもっとやるんですが、今回は動かすまで。
FMによる回帰
上の流れができれば、あとは計算部分を今回利用するfastFM仕様にしてしまえばもう完成です。1点注意なのは DataFrameをそのままは扱えないのでcsr_matrixを使う というところです。
モデル作成〜評価
from fastFM import als
from scipy.sparse import csr_matrix
# モデル作成
fm = als.FMRegression(n_iter=1000, init_stdev=0.1, rank=8, l2_reg_w=0.5, l2_reg_V=0.5, random_state=810)
fm.fit(csr_matrix(X_train), y_train)
# 評価
## 学習データへの当てはまり具合
mean_absolute_error(y_train, fm.predict(csr_matrix(X_train)))
## テストデータの誤差
mean_absolute_error(y_test, fm.predict(csr_matrix(X_test)))
疎行列、csr_matrix
ここでcsr_matrixというものが出てきます。これはスパースなデータを扱うものです。
イメージとしてはシンプルで、DataFrameや通常のmatrixが以下のように2次元データを扱うとすると
array([
[0, 0, 1],
[0, 0, 0],
[0, 3, 0]
])
データが入っている部分だけ扱おうというもの
大きさ:3 x 3
データあるところ:
([0,2]地点に 1)
([2,1]地点に 3)
みたいなイメージです。
いくつか扱い方に種類があり、csr_matrix, coo_matrix, csc_matrix, lil_matrixなどがあり扱い方や処理速度が異なるようですので気になる方は「scipy sparse行列」等で検索ください。
note.nkmk.meさんとか詳しく載っています。
今回覚えておくものとしては
- DataFrameから変換例:
csr_matrix(df) - csr_matrixを行列に変換するtodense例:
csr_matrix(X_train).todense()
ぐらいかなと。
FMによる分類
2値分類もできるのでやってみます。
今回は ratingが4以上か未満かの2クラスを当てる というタスクを行ってみます。
前処理〜データ分割の部分の後にratingが4以上か否かという回答データを作るところを挟んでからモデル作成と評価を実施します。
また、fastFMの分類では 0 or 1 ではなく -1 or 1 で値を作ることに注意です。
from fastFM import sgd
from sklearn.metrics import roc_auc_score
# 前処理続き
## 4以上なら1 それ以外なら-1とする
y_ = np.array([1 if r > 3 else -1 for r in y])
## 学習データ・テストデータ作成
X_train, X_test, y_train, y_test = train_test_split(X, y_, random_state=810)
# モデル作成
fm = sgd.FMClassification(n_iter=5000, init_stdev=0.1, l2_reg_w=0,
l2_reg_V=0, rank=2, step_size=0.1)
fm.fit(csr_matrix(X_train), y_train)
## 2種類の予測値の出し方ができるようです
y_pred = fm.predict(csr_matrix(X_test))
y_pred_proba = fm.predict_proba(csr_matrix(X_test))
# 評価
## AUCの値を評価とした例
roc_auc_score(y_test, y_pred_proba)
ROC曲線を書く
note.nkmk.meさんのページをがっつり参考にさせていただいて、ROC曲線も書いてみます。
fpr, tpr, thresholds = metrics.roc_curve(y_test, y_pred_proba, drop_intermediate=False)
auc = metrics.auc(fpr, tpr)
# ROC曲線をプロット
plt.plot(fpr, tpr, label='ROC curve (area = %.2f)'%auc)
plt.legend()
plt.title('ROC curve')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.grid(True)
plt.show()
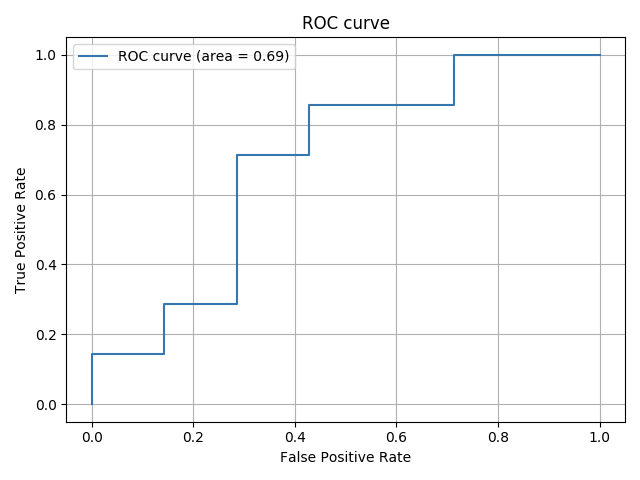
できたー。
他
以下、サンプルデータを貼り付け。
適当に作ったものなので面白いデータでもなんでもないです。動作確認等にどうぞ。
カテゴリ,rating,is_A,is_B,is_C,is_X,is_Y,is_Z
A,5,0,0,1,0,1,0
A,1,1,0,0,0,0,1
A,3,0,0,1,0,1,0
A,2,1,0,0,0,0,1
A,4,0,0,0,0,0,1
A,5,1,0,0,1,1,0
A,1,0,1,0,0,0,1
A,2,0,0,0,0,0,1
B,2,0,1,0,0,0,0
B,5,0,0,0,0,1,0
B,3,1,1,0,0,1,0
B,2,0,0,1,0,0,0
B,1,0,0,0,0,0,1
B,3,0,0,1,0,0,1
B,4,0,1,0,0,0,0
B,1,0,0,0,0,0,1
B,2,0,1,0,0,0,1
C,1,1,0,0,0,0,1
C,4,0,0,0,0,1,0
C,2,1,0,1,0,1,0
C,4,0,0,0,0,0,0
C,5,0,0,1,1,1,0
C,2,0,1,0,0,0,1
C,5,1,0,0,0,1,0
C,3,0,0,1,1,1,0
C,2,0,0,0,0,0,1
C,3,0,0,0,0,1,0
A,2,0,0,0,0,0,1
A,4,1,0,0,0,1,0
A,3,0,0,0,0,0,0
A,1,0,0,0,0,0,1
A,3,1,0,0,0,0,0
A,4,0,0,1,0,1,0
A,5,1,1,0,0,1,0
A,3,1,0,0,1,0,0
B,4,0,0,0,0,1,0
B,1,0,0,0,0,0,1
B,5,0,0,0,0,1,0
B,3,0,0,0,0,0,0
B,1,0,0,0,1,0,1
B,3,0,0,1,0,0,0
B,2,0,1,0,0,0,1
B,5,1,0,0,0,1,0
B,4,0,0,0,1,1,1
C,1,0,0,0,0,0,0
C,2,0,0,0,0,0,1
C,3,0,0,1,0,0,0
C,4,0,1,0,0,1,0
C,1,0,0,1,0,0,1
C,1,0,0,0,0,0,0
C,3,0,0,1,0,0,0
C,3,0,0,1,0,1,0
C,5,0,0,0,1,1,0
C,3,0,0,1,0,1,0