概要
本記事は Zipfian distribution からのサンプルを近似分布を使って高速に得る方法についてまとめます。
データベースシステムの基本的な性能評価において、YCSB1 という Key-value store ベンチマークおよびその亜種がよく使われます。ワークロードの実行において、ベンチマーク実行の最小単位であるオペレーションは、特定の分布に従って Key を選択し、該当する Key を持つ Record にアクセスします。
YCSB 論文の中では複数の分布が登場しますが、実際によく使われるのが Uniform distribution (一様分布) と Zipfian distribution (Zipf 分布) です。Uniform distribution は疑似乱数を使って簡単にサンプルが取得できますが、Zipfian distribution は愚直にサンプルを得ようとすると、索引構造とその検索、例えばソート済み配列とバイナリサーチ、が必要となってしまいます。そこで、近似で構わないので高速な手法が欲しくなるというわけです。
Zipf 分布
Zipfian distribution (Zipf 分布、ジップ分布) は、George Kingsley Zipf さんの名前 Zipf から名前をとった Zipf's law (Zipf 法則)に基いた分布です。Zipf は英語圏では「ジフ」に近い音で呼ばれることが多いようですが、日本後だとジップと読むことが多いようです。
Zipf の法則は、$k$ 番目に出現頻度が多い要素の出現頻度は、1 番目のそれに対して $1/k$ となる性質を持ちます。よくわからんという方は、Wikipedia (日本語: ジップの法則、英語: Zipf's law) などを見てください。
Zipf 分布 $\textrm{zipf}(\theta, N)$ は、$[1, N]$ の範囲の自然数に$x$ に対して、その出現確率が $\frac{1}{Cx^{\theta}}$ となるような確率分布です。ただし、$\theta \ge 0$ は Skew (偏り) を表すパラメータで、$C=\sum_{x=1}^{N}{1/x^{\theta}}$ は正規化定数です。$\theta=1$ のときは Zipf 法則そのものですね。$\theta=0$ のときは、一様分布となります。$\theta$ が大きいほど偏りが大きくなります。
Zipf 分布からのサンプリングとその問題
Zipf 分布は離散分布なので、愚直に計算してサンプルを得ようとすると、$\sum$ の計算が必要です。これを毎回計算しなおすのは性能の観点からありえないので、例えば累積分布関数(Cumulative distribution function, CDF)を表す配列を作って $[0, 1)$ の一様分布 ($\textrm{randf}$ と書きます) からのサンプル $u$ を使ってバイナリサーチを行い、配列のインデクスを Zipf 分布からのサンプルとして得ます。この操作は、$u$ に CDF の逆関数を適用して $x$ を得る操作に相当します。結果として $x \sim \textrm{zipf}(\theta, N) - 1$ となります。プログラムで扱いやすいよう、$[1, N]$ ではなく 1 ズレた $[0, N)$ の出力を想定しています。以下、C/C++ を想定したサンプルコードです。
// 0 <= theta (double), 0 < nr (size_t).
// Preparing cdf table.
double cdf[nr + 1];
double zetan = 0.0;
for (size_t i = 0; i < nr; i++) {
zetan += pow(i + 1, -theta);
cdf[i] = zetan;
}
for (size_t i = 0; i < nr; i++) {
cdf[i] /= zetan; // normalization
}
cdf[nr] = 1.0; // sentinel.
// Get a sample from the zipf distribution.
double u = randf(); // a sample from uniform random distribution in [0, 1).
size_t x = lower_bound(cdf, nr, u); // a sample from the zipf distribution in [0, nr).
return x;
コード中の theta は $\theta$、nr は $N$、zetan は $C$ (正規化定数) です。この方法を本記事では Naivezipf と呼ぶことにします。浮動小数点の誤差に伴う問題が起きない程度の $\theta, N$ であれば、これでほぼ正確な Zipf 分布からのサンプリングができます。しかし、性能の視点からは問題があります。CDF を作るのは事前準備だから致し方ないとしても、CDF の探索は問題です。CDF が double 配列として、$8N$ bytes のメモリが必要となります。私が良く使う実験だと比較的小さくても $N=10^6$ なので、約 8MB です。サイズだけ見れば、現代のコンピュータで扱うにはむしろ小さいと思いがちですが、zipf 分布をサンプリングするためだけに、CPU キャッシュにこの 8MB が居座ることが性能面で問題です。CPU キャッシュは年々増えているとはいえ、AMD Zen4 コア (Ryzen 9 7950X など) の L1D キャッシュは 32KB、L2 キャッシュは 1MB しかありません。この方法で zipf サンプリングした場合、性能測定におけるオーバーヘッドが無視できるものかどうか疑問があります(実際オーバーヘッドを測定して定量的に議論すべきなんでしょうけれど、サボっています)。また、$N$ が大きい場合は、バイナリサーチのコストも問題になります。
Fastzipf
そこで、DBMS の神 Jim Gray2 らの論文3 で近似アルゴリズムが提案されています。元々は The Art of Computer Programming4 で近似アルゴリズムが紹介されていたようですが、その方法は間違っていると指摘し、代わりのアルゴリズムを提示しています。以下に、論文中の疑似コードの Typo を直して整理したアルゴリズムを示します。
// 0 <= theta < 1, 2 < nr
// Preparing CDF (only for x = 0 and 1)
double cdf[2];
double zetan = 0.0;
for (size_t i = 0; i < nr; i++) {
zetan += pow(i + 1, -theta);
if (i < 2) cdf[i] = zetan;
}
for (size_t i = 0; i < nr; i++) cdf[i] /= zetan;
double alpha = theta - 1.0;
double eta = (1.0 - pow(2.0 / (double)nr, -alpha)) / (1.0 - cdr[1] / zetan);
// Get a sample from the zipf distribution
double u = randf();
for (size_t i = 0; i < 2; i++) {
if (u < cdf[i]) return i;
}
size_t x = (size_t)((double)nr * pow(eta * (u - 1.0) + 1.0, -1.0 / alpha));
return x;
正規化定数 $C$ (zetan) を計算するところは同じですが、CDF は $x=0, 1$ (0-origin であることに注意) 用にしか保持しません。$x \ge 2$ については、近似式を使います。$\alpha$ (alpha) と $\eta$ (eta) を使っています。数式で書くと、$\alpha = \theta - 1$、$\eta = \frac{1 - (2/N)^{1 - \theta}}{1 - cdr[1] / C}$、$x = N (\eta (u - 1) + 1)^{-1 / \alpha}$ となります。$u$ は $\textrm{randf}$ からサンプリングした値、$x$ の式の右辺は CDF の逆関数($\textrm{CDF}^{-1}(u)$)相当です。式の具体的な中身を完璧に解釈することは私にはできませんが、いくつかの性質を確認することはできます。$\theta=0$、$N=1000$ のとき、$\eta \approx 1$、$x \approx Nu$ となり、$[0, N)$ の一様分布になります。指数の底の部分はうまく繋ぎ目が作れるように工夫されたものと捉えてよいと思います。Zipf 分布は両対数グラフで右肩下がりの直線の形を取りますが、その直線の傾きを決めているのが、$\alpha$ です。論文内では $0 \le \theta < 1$ と定義されていますので、そのとき $-1 \le \alpha < 0$ となり、$1 \le -\frac{1}{\alpha} < \infty$ となります。$\theta = 1$ のとき $- \frac{1}{\alpha}$ は不定となり、計算ができません。$1 < \theta$ の領域は論文では想定されていないようですが、Fastzipf の計算自体は可能で、それっぽい値が出ます。このとき、$0 < \alpha < \infty$、$-\infty < -\frac{1}{\alpha} < 0$ です。
私はこのアルゴリズムを数年間使っていたのですが、$0 \le \theta < 1$ という制限が不満だったのと、近似式が何を意味しているのかよく分からないままなのがモヤモヤしていました。
$1 < \theta$ でそれっぽい値が出ることは最近まで試そうともしていませんでした……
Bounded Pareto distribution を用いた近似
モヤモヤをなんとかしたくて、近似に使えそうな分布を探していました。その中に Pareto 分布というものがありました。詳細はここでは語りませんが、Pareto 分布を自分ではうまく Zipf 分布近似に利用することができませんでした。数年前の話です。最近になって、Bounded Pareto distribution (訳は有界パレート分布でよいんでしょうか?) というものを知りました。Wikipedia (Pareto distribution) にも載っています。これは利用できるんじゃないかということで試行錯誤してみたところ、うまくいったのでこの記事を書くところまで状況が進展しました。
有界パレート分布は、$\alpha > 0$、$0 < L < H$ である実数 $\alpha$、$L$、$H$ に対して、確率密度関数が $\frac{\alpha L^{\alpha} x^{-\alpha - 1}}{1 - (L/H)^{\alpha}}$、CDF の逆関数が $(\frac{uL^{\alpha}+(1-u)H^{\alpha}}{L^{\alpha}H^{\alpha}})^{-1/\alpha}$、ただし $u \sim \textrm{randf}$ 、であるような連続分布です。重要な性質は、定義域が有界であること、そして、両対数グラフにおける右肩下がりの直線となり、傾きが Fastzipf と同じ形 $-\frac{1}{\alpha}$ をしていることです。(本記事では、Fastzipf の方の変数を、Bounded Pareto distribution に合わせて記述しました)。つまり、$\alpha = \theta - 1$ とすれば、傾きを揃えることができます。$0 < \alpha$ の定義域では、$1 < \theta$ しか扱えません。幸いなことに、Fastzipf のときと同様に、$-1 \le \alpha < 0$ でも $\textrm{CDF}^{-1}$ の値は計算でき、Zipf 分布の近似として良い値が得られます。このとき、$0 \le \theta < 1$ となります。$\theta = 0$ のときは、$\alpha = -1$ で、$\textrm{CDF}^{-1}(u) = (1-u)L + uH = L + (H - L)u$ となります。つまり、$u \sim \textrm{randf}$ に対して $[L,H)$ の一様分布となり、期待通りの挙動を示します。
あとは、Fastzipf のときと同様に、$x$ が小さい領域はテーブルを使って、残りは有界パレート分布を使って、Zipf 分布からのサンプリングを近似できます。例えば $x < 8$ でテーブルを使うことにしたならば、$L=8$、$H=N-0.001$ などと置くとよいでしょう。($-0.001$ は、$[0, N)$ が欲しいところで $N$ がサンプリングされてしまうことを防ぐためのものです)。注意点として、$u \sim \textrm{randf}$ でサンプリングして、$u < t$ のときにテーブルを使った場合、有界パレート分布を使うために残っている領域は $[t, 1)$ となります($t$ はテーブル内の最大値)。しかし、CDF の逆関数は $[0, 1)$ を入力として期待しているので、適切に領域を引き伸ばす必要があります。具体的には、$u2 = (u - t) / (1 - t)$ という計算をして、$u2$ を CDF 逆関数の入力にします。すると、$[8, N)$ の範囲内の出力が得られるので、それを整数に変換して返すだけです。以下にアルゴリズムを示します。icdf は $\textrm{CDF}^{-1}$ のことです。準備のところは Fastzipf とだいたい同じなので、省略します。
// Prepare cdf table for x = 0, 1, ..., L - 1.
// Prepare icdf(u) function. u is in [0, 1), icdf(u) is in [L, nr).
// Get a sample from the zipf distribution
double u = randf();
for (size_t i = 0; i < L; i++) {
if (u < cdf[i]) return i;
}
double t = cdf[L - 1];
double u2 = (u - t) / (1.0 - t); // [t, 1) --> [0, 1).
size_t x = (size_t)icdf(u2); // [L, nr).
return x;
有界パレート分布を使っても、$\theta = 1$ の場合は扱えないという問題は残ります。
θ=1 の場合の近似
$\theta =1$は、一番基本的な Zipf 分布です。そこで、対応する近似関数は自分で作れるのでは?と考え、やってみたらできました。
対応する連続確率密度関数は、$\frac{1}{Cx}$ です。元々の定義域は $0 < x$ (負の値は今は考えない)であるため、有界パレート分布のときと同様に $[L, H)$ の範囲で扱いたいです。そこで、確率密度関数を $[L, x]$ の範囲で積分したものを累積分布関数 CDF とし、$\textrm{CDF}(H) = 1$ となるように $C$ を定めることで、$\textrm{CDF}^{-1}$ が入力 $[0, 1)$ に対して $[L, H)$ の値を取るように調整します。すると、$\textrm{CDF}(x) = \int_{L}^{x}{\frac{1}{Cx'}dx'}= \frac{1}{C}(\ln x - \ln L)$。$\textrm{CDF}(H) = \frac{1}{C}(\ln H - \ln L) = 1$ より、$C = \ln H - \ln L$。$\textrm{CDF}^{-1}(u) = Le^{Cu} = Le^{(\ln H - \ln L)u} = L(\frac{H}{L})^u = L^{1-u}H^{u}$。有界パレート分布の $\textrm{CDF}^{-1}$ は、$u$ が底に含まれていたのに対し、ここでは指数に含まれていますね。$\alpha \rightarrow 0$ の極限で有界パレート分布はこれに収束してくれます(後述)。
あとは、$x$ が小さい領域はテーブルを使い、残った $[t, 1)$ の領域を $[0, 1)$ に引き伸ばして、$\textrm{CDF}^{-1}$ に食わせてやれば、$\textrm{zipf}(\theta=1, N)$ からのサンプリングを近似できます。
$0 \le \theta < 1$ および $1 < \theta$ は有界パレート分布を使った近似を、$\theta = 1$ のときは、この近似を用いることで、$0 \le \theta$ の Zipf 分布からのサンプリングを近似できます。この方法を、Fastzipf2 と呼ぶことにします。
評価
Naive な Zipf 分布生成アルゴリズム(Naivezipf)、Jim Gray らの Fastzipf、そして、今回提案する Fastzipf2 を比較します。
まず、どのくらい正確にサンプリングできているかを見てみましょう。
$\theta$ を複数用意して、$N=1000$ について、実際にサンプリングを $10^6$ 回実行し、$x$ 軸はサンプリングされた値を、$y$ 軸には各値が得られた確率(回数 / $10^6$) を両対数グラフとしてプロットします。ただし、$[0, N)$ だと $0$ のプロットができなくて困るので、$x$ 軸は +1 した値を、$10^6$ 回の試行の中で一回もその値が得られなかった場合のことを想定して、$y$ 軸は +0.000001 した値をプロットしています。Fastzipf について、2 つ注意点があります。(1) $\theta=1$ の分布は計算できないので除外しています。(2) $\theta > 1$ についても元々の論文では定義域に入っていませんが、一応計算はできるので、プロットしました。Fastzipf2 については、テーブル引きは $x < 8$ に対して行いました。
順に Naivezipf、Fastzipf、Fastzipf2 のグラフを表示しました。


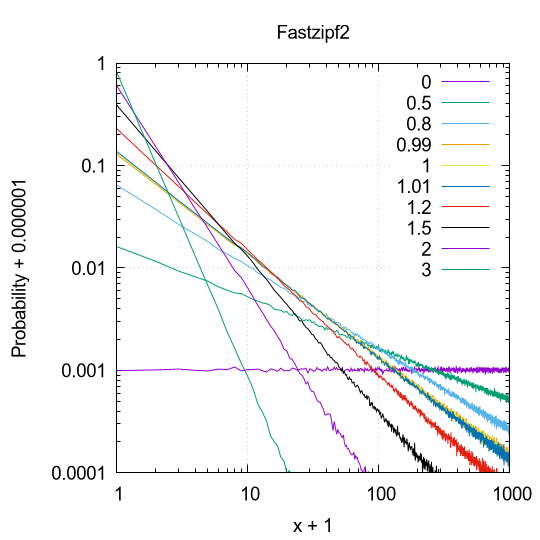
正確性についての定量評価は今のところ行っていませんが、Fastzipf で $\theta > 1$ の領域で Naivezipf とのズレが若干気になるくらいです。もちろん、近似なので厳密には一致しません。Fastzipf は $x < 2$ について、Fastzipf2 は $x < 8$ についてテーブルを引いているので、その区間については完全一致する(サンプリング数を増やしていけば同じ値に収束する)ことに注意してください。
次に簡単な性能測定を行いました。
Ryzen 9 5950X を用いて、サンプリング 1 回あたりにかかる平均レイテンシを測定しました。$x \sim \textrm{randf}$ のサンプリング用の疑似乱数生成には、xoroshiro128+5 を使っています (uint64_t の値を生成して、UINT64_MAX で割っているだけです)。CDF の計算などの事前準備にかかるコストは測定に含みません。
$N=10^3$ のとき
| $\theta=0$ | $\theta=0.5$ | $\theta=1$ | |
|---|---|---|---|
| Naivezipf | 43.0ns | 39.5ns | 28.9ns |
| Fastzipf | 13.2ns | 12.9ns | --- |
| Fastzipf2 | 17.8ns | 17.6ns | 8.7ns |
$N=10^6$ のとき
| $\theta=0$ | $\theta=0.5$ | $\theta=1$ | |
|---|---|---|---|
| Naivezipf | 132.0ns | 125.0ns | 65.2ns |
| Fastzipf | 13.3ns | 13.0ns | --- |
| Fastzipf2 | 17.2ns | 18.0ns | 8.3ns |
Naivezipf は、$N$ が大きくなるほどに遅くなっているのが分かります。バイナリサーチは $O(\log N)$ の計算コストで済むとはいえ、CDF テーブルを探索するため CPU キャッシュヒット率が下がっているだろうことも影響していると思われます。もちろん現実のワークロードでは、CPU をアプリケーションロジックやデータベースロジックなどで共有するため、CPU キャッシュもまた共有するわけですが、その影響は今回は評価していません。ひとつ言えることは、ここでの評価よりもレイテンシが大きくなってしまうことはあっても逆はないだろうということです。Fastzipf や Fastzipf2 は十分高速だといえるでしょう。Fastzipf2 の $\theta = 1$ におけるレイテンシがとりわけ低いのは、近似関数の計算がより簡単だからだと考えられます。
結論
この記事では Zipf 分布の高速なサンプリング近似の方法について整理しました。Naive な Zipf サンプリングでは性能に満足できず、Fastzipf は高速であるものの、Skew (偏り)パラメータ $\theta$ に制限があり、近似関数の意味がよく分からないという不満があったところ、それを解消する方法を見出すことができました。$\theta = 1$ における場合分けが不要なものがあればよいのになとは思いますが、今のところ思いつきません。
残っている問題としては、zetan (正規化定数 $C$) の計算コストは $N$ に比例するので、あまり大きな $N$ について Zipf 分布からのサンプリングを行うのは事前計算コストが大きく現実的ではないです($N=10^6$ なら一瞬で計算可能、$10^8$ はまあなんとか)。テールの部分は一様分布でごまかすなど、やりようはあるかも知れませんが、テール部分の正確性が重要な用途があるとすれば、そういうわけにもいかないので、用途次第かと思います。
私が最初に Fastzipf の存在を知ってから 10 年くらい経ってしまっているのですが、やっとモヤモヤが解消された気がします。皆さんもどうぞこれを使って High skew な実験用ワークロードをどんどん生成してください。また、もっと良い方法があるかも知れませんので、知っていたら是非教えてください。
付録: 収束性の証明
有界パレート分布の $\textrm{CDF}^{-1}(u)$ は $(\frac{uL^{\alpha}+(1-u)H^{\alpha}}{L^{\alpha}H^{\alpha}})^{-1/\alpha}$ です。これの $\alpha \rightarrow 0$ における極限が $\theta = 1$ 専用の $\textrm{CDF}^{-1}(u)$ である $L^{1-u}H^{u}$ と一致することを示します。
$f(\alpha) = uL^{\alpha}+(1-u)H^{\alpha}$ とおき、$g(\alpha) = f(\alpha)^{-1/\alpha}$ とおくと、有界パレート分布の $\textrm{CDF}^{-1}(u)$ は $LH g(\alpha)$ とかけます。
ここで、$\ln{g(\alpha)}$ の $\alpha \rightarrow 0$ における極限を考えます。
$\ln{g(\alpha)} = -\frac{\ln{f(\alpha)}}{\alpha}$ で、$\alpha = 0$ のときこの分子および分母は 0 なので、ロピタルの定理を適用します。
分母の微分$\alpha'$は 1 なので、分子のみ考えればよいです。
$\lim_{\alpha \to 0} \ln{g(\alpha)} = \lim_{\alpha \to 0} -\frac{\ln{f(\alpha)}}{\alpha}$
$= (-\ln{f(\alpha)})'\vert_{\alpha=0}$
$= (-\frac{1}{f(\alpha)} (uL^{\alpha}\ln{L} + (1-u)H^{\alpha}\ln{H}))\vert_{\alpha=0}$
$= -(u\ln{L} + (1-u)\ln{H})$
$= -\ln{(L^{u}H^{1-u}})$。
この結果を使うと、有界パレート分布の $\textrm{CDF}^{-1}(u)$ の極限は、$\lim_{\alpha \to 0} LHg(\alpha) = \lim_{\alpha \to 0} LHe^{\ln{g(\alpha)}}$
$= LHe^{-\ln{(L^uH^{1-u})}}=LHL^{-u}H^{-(1-u)} = L^{1-u}H^{u}$。
$\theta = 1$ 専用の $\textrm{CDF}^{-1}(u)$ と一致したので、証明できました。
-
Benchmarking cloud serving systems with YCSB. 2010. Paper on ACM DL ↩
-
Jim Gray は Transaction Processing: Concepts and Techniques の著者のひとりです。 ↩
-
Quickly Generating Billion-Record Synthetic Databases. 1994. Papre on ACM DL ↩ ↩2
-
The Art of Computer Programming, Volume 2, Chapter 3, 2nd cd., Addison Wesley, 1981. 文献 3 によると、この本の 398 ページに書かれているそうです。私は未確認。 ↩