対象の要件
- 複数のフォルダに存在する、複数のExcelブックの内容を集約したい
- それらのブックの集約対象は全て同じ名前、同じ列名の「テーブル」を持っている
適用対象外
- フォルダ内によけいなフォルダやファイルがある
紹介するクエリの中でフィルタリングすれば簡単だが割愛する。 - ファイル名の一部に区分が書いてあるので値として使用したい
抽出に正規表現必須とか言わなければ比較的容易だが割愛する。 - 「テーブル」でなくただの範囲
参考になる記事 [Power Queryで複数のExcelブックの共通しない名称のシートを読み込む - Qiita] (https://qiita.com/y_ohira/items/698e97ea09fc24644289#%E6%89%8B%E9%A0%8622%E3%82%B7%E3%83%BC%E3%83%88%E5%90%8D%E3%81%8C%E7%95%B0%E3%81%AA%E3%82%8B%E3%82%B7%E3%83%BC%E3%83%88%E3%82%82%E8%AA%AD%E3%81%BF%E8%BE%BC%E3%82%80%E3%82%88%E3%81%86%E3%81%AB%E8%A8%AD%E5%AE%9A%E3%81%99%E3%82%8B) がある。流用すれば複数のフォルダに対応できそう。 - ただの範囲だし、開始位置も終了位置もわからないし、範囲外に不要な文字列がある
VBAの出番と思われる。フォーマットが整ってはいるが残念ながらExcel方眼紙なブックは大量に存在するので Power Query で捌けないか興味はある。
サンプルの前提
下記のようなブックを複数、複数のフォルダに配置する。
- ブック名: 任意
- シート名: 任意
- テーブル位置: 任意
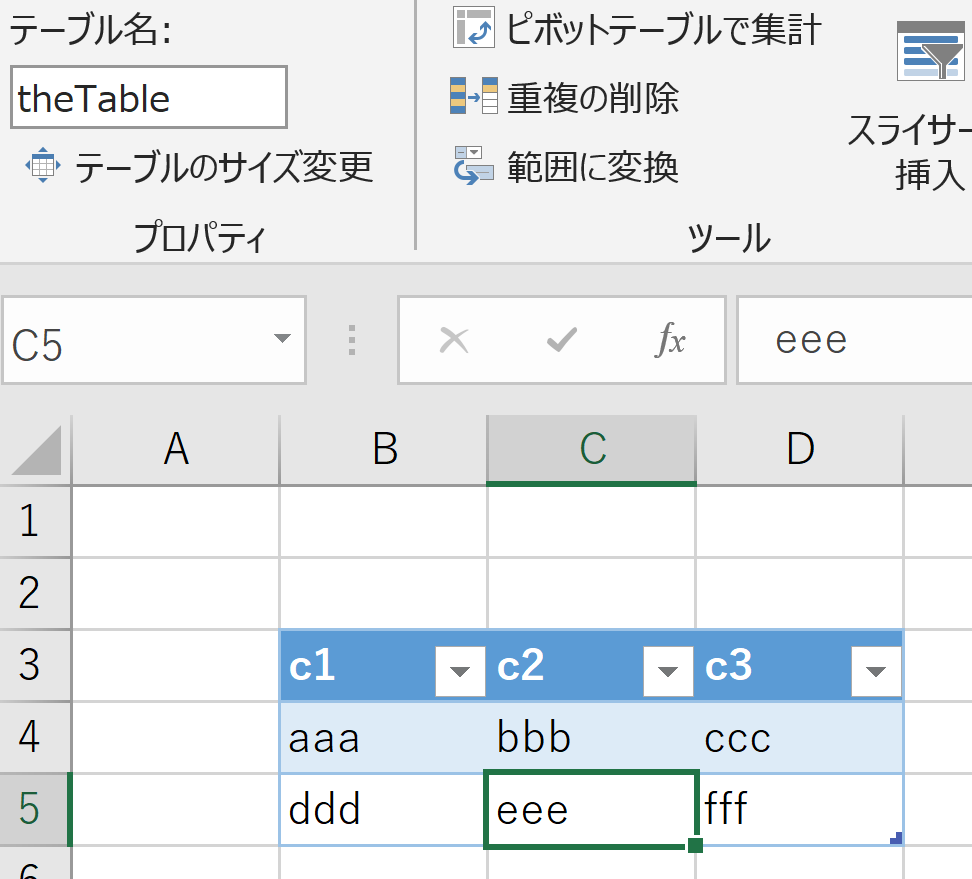
- テーブル名:
theTable - 列名:
c1,c2,c3
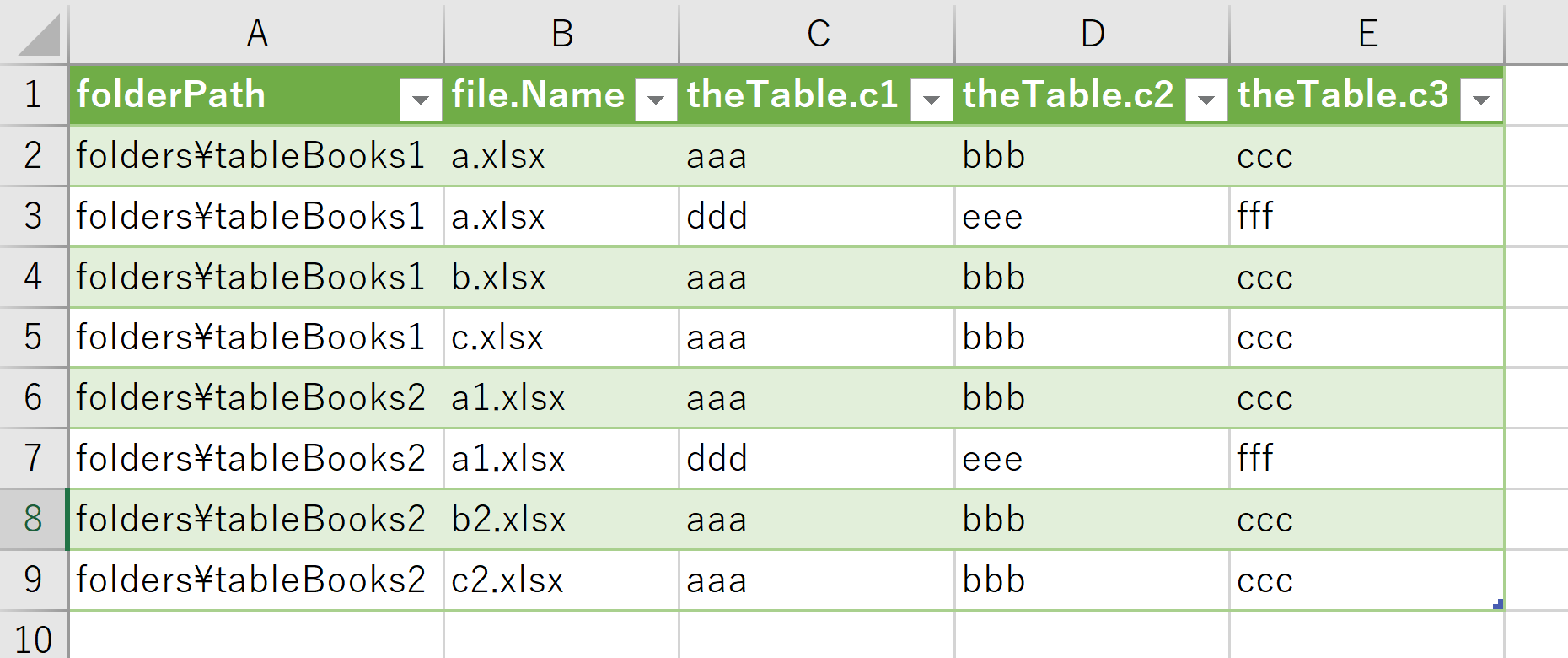
得られる結果
以降、すっとばしの手順とステップバイステップの手順を紹介するが、いずれも下図の結果が得られる。
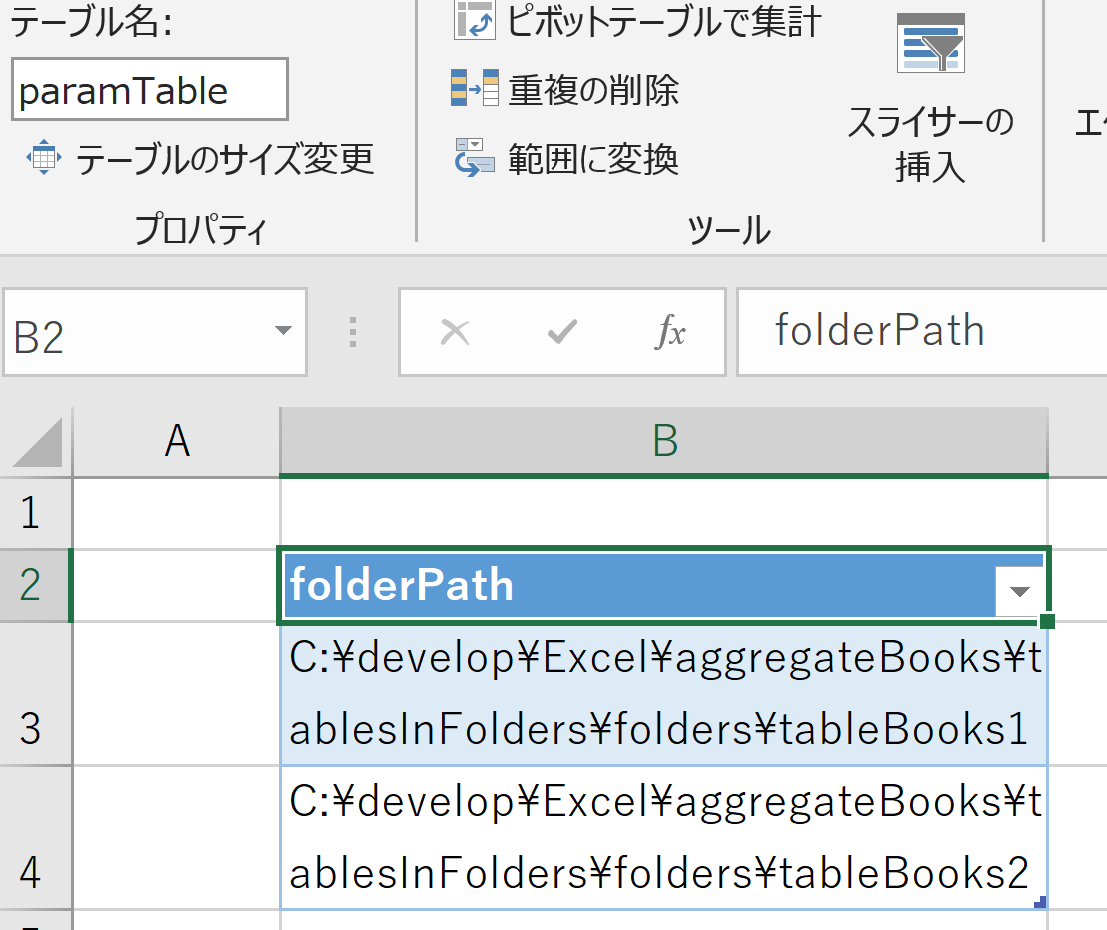
事前準備
集約する前に、集約用ブックに対象のフォルダを記入してテーブル化しておく。
(クエリにこれを参照させ、対象フォルダが増減したときにコードを変更する手間をなくすため)
- テーブル名:
paramTable - 列名:
folderPath - ほか任意
すっとばしの手順
-
詳細エディターを開く
- Excel - データ > データの取得 > その他のデータソースから > 空のクエリ
- Power Query エディター - ホーム > 詳細エディター
-
詳細エディター内のコードを上書きする
これまでの前提・事前準備に沿った命名になっているためそれぞれ読み替えること。let #"ソース" = Excel.CurrentWorkbook(){[Name = "paramTable"]}[Content], #"フォルダ内のファイル" = Table.AddColumn( #"ソース", "files", each Folder.Files([folderPath]) ), #"展開されたfiles" = Table.ExpandTableColumn( #"フォルダ内のファイル", "files", { "Content", "Name", "Extension", "Date accessed", "Date modified", "Date created", "Attributes", "Folder Path" }, { "file.Content", "file.Name", "file.Extension", "file.Date accessed", "file.Date modified", "file.Date created", "file.Attributes", "file.Folder Path" } ), #"追加されたカスタム" = Table.AddColumn( #"展開されたfiles", "カスタム", each Excel.Workbook( [file.Content], null, true ){[ Item = "theTable", Kind = "Table" ]} [Data] ), #"展開されたカスタム" = Table.ExpandTableColumn( #"追加されたカスタム", "カスタム", { "c1", "c2", "c3" }, { "theTable.c1", "theTable.c2", "theTable.c3" } ), #"区切り記号の後の抽出されたテキスト" = Table.TransformColumns( #"展開されたカスタム", { { "folderPath", each Text.AfterDelimiter( _, "\", { 1, RelativePosition.FromEnd } ), type text } } ), #"削除された列" = Table.RemoveColumns( #"区切り記号の後の抽出されたテキスト", { "file.Content", "file.Extension", "file.Date accessed", "file.Date modified", "file.Date created", "file.Attributes", "file.Folder Path" } ) in #"削除された列"「区切り記号の後…」以降は装飾のための操作のためなくても問題はない
-
完了、閉じて読み込む
ステップバイステップ
- テーブル
paramTableを起点にクエリを作成する
フォルダパスをファイルリストに展開して各ファイル内のテーブルを展開して、という流れのため、このテーブルが起点になる。- テーブル
paramTable内の適当なセルを選択する - Excel - データ > データの取得 > その他のデータソースから > テーブルまたは範囲から
- テーブル
- 不要なステップを削除する
- ステップ
変更された型は今回は不要なので×ボタンで消す
- ステップ
-
folderPath列のパスをファイルリストに変換した列を追加する- 列の追加 > カスタム列 > 列の追加
- 列名:
files - 式:
Folder.Files([folderPath])
式の意味: 指定フォルダー内のファイルを取得する。ファイルの各種プロパティをレコードとしたテーブルの形をとる。 - 完了
- ステップ名を設定する
- ステップを選択して F2
-
フォルダ内のファイルに変更して Enter - ※「完了」以降の手順は以降では省略する。デフォルトでわかりにくければ適宜リネームすること。
-
files列のファイル情報テーブルを展開する- プレビュー内で
files列の適当なセルを選択 - 変換 > 構造化列 > 展開
- 列名のプレフィックス:
file - 使わない列はチェックボックスで外してもよいが、後から追加すると後続のステップを壊す場合がある。また、ステップが多くなると読みにくくなるため、序盤はロジックに専念し、必要な情報が出揃ってから整形と合わせて列削除をするようにステップの棲み分けをすると、読みやすくなる。(メモリに優しくないかも知れないが未検証)
- プレビュー内で
-
file.Content列のファイルデータからtheTableテーブルを抽出した列を追加する-
列の追加 > カスタム列 > 列の追加
-
列名:
カスタム(考えてなかったのでデフォルトになった) -
式:
Excel.Workbook( [file.Content], null, true ){[ Item = "theTable", Kind = "Table" ]} [Data]式の意味:
Excel.Workbook()でバイナリからブックを開き、{...}で対象テーブルを取得、そのデータを得る。
-
-
カスタム列のtheTableテーブル を展開する- プレビュー内で
カスタム列の適当なセルを選択 - 変換 > 構造化列 > 展開
- 列名のプレフィックス:
theTable
- プレビュー内で
- できあがり
- 長い文字列のカットや不要な列の削除などを以降のステップで行う
- ホーム > 閉じる > 閉じて読み込む