ARM SVE intrinsic命令のレジスタ操作関数の図を以前作ったときのメモ。自分で使うことがありそうなものしかまとめていないので、その他は公式マニュアル参照。
https://developer.arm.com/documentation/100987/latest/
-
{type}には[int{8,16,32,64}_t, uint{8,16,32,64}_t, float{16,32,64}_t]が入る -
{t}には[s{8,16,32,64}, u{8,16,32,64}, f{16,32,64}]が入る。[_{t}]部分は省略可能
例えば、TBL関数では
svfloat64_t svtbl_f64(svfloat64_t input1, svuint64_t indices)
svint16_t svtbl(svint16_t input1, svuint16_t indices)
のようにできる。
レジスタ要素移動系の関数
後ろに1が付く関数は偶数番目要素、2が付く関数は奇数番目の要素を移動させるので注意。
REV: Reverse the elements in a single input
レジスタ内で要素を反転。predicateなし。
sv{type} svrev[_{t}] (sv{type} input1)
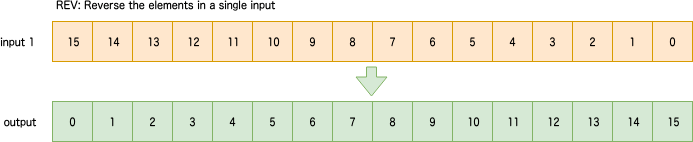
TBL: Table lookup/permute using vector of indices
要素番号のテーブルを作ってレジスタ内の要素を任意に並べ替え。テーブルを作るコストがかかるため可能な限り下に紹介する並び替えを駆使する方がいい。即値を与えて任意に並べ替える方法はわからなかったのでいちいちテーブル配列のレジスタを作る方法しかわからない。svuint??_t indicesの??は{type}のビット幅と同じ。predicateなし。
sv{type} svtbl[_{t}](sv{type} input1, svuint??_t indices)
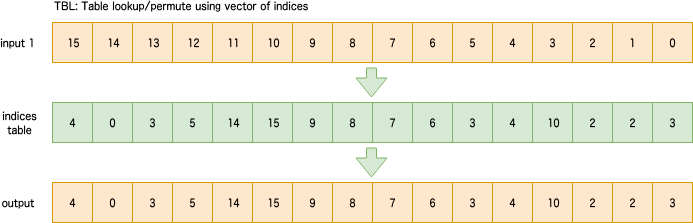
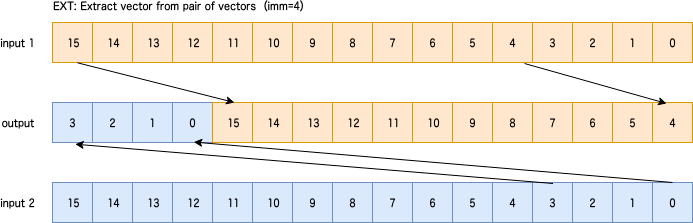
EXT: Extract vector from pair of vectors
2つのレジスタから図のように周期的に要素を選択。整数値immによってどれくらいずらすかを指定。
図の場合はimm=4。 predicateなし。
sv{type} svext[_{t}](sv{type} input1, sv{type} input2, uint64_t imm)
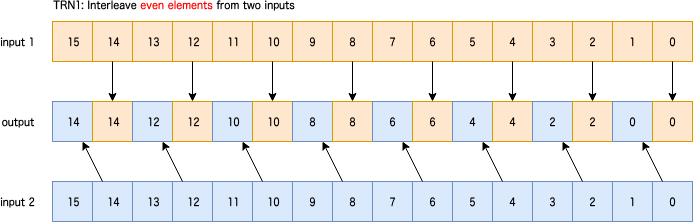
TRN1: Interleave even elements from two inputs
2つのレジスタから図のように偶数番目の要素を選択。predicateなし。
sv{type} svtrn1[_{t}](sv{type} input1, sv{type} input2)
TRN2: Interleave odd elements from two inputs
2つのレジスタから図のように奇数番目の要素を選択。predicateなし。
sv{type} svtrn2[_{t}](sv{type} input1, sv{type} input2)
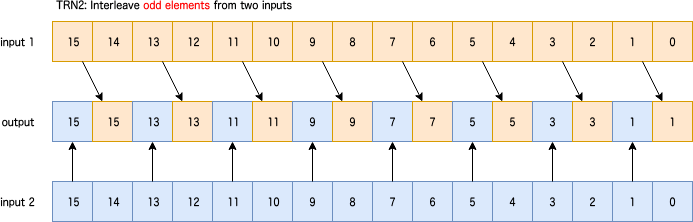
UZP1: Select even elements from two inputs
2つのレジスタから図のように偶数番目の要素を選択。predicateなし。
sv{type} svuzp1[_{t}](sv{type} input1, sv{type} input2)
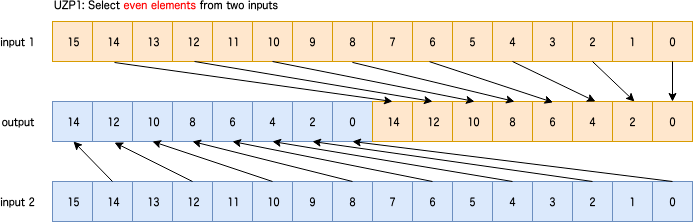
UZP2: Select odd elements from two inputs
2つのレジスタから図のように奇数番目の要素を選択。predicateなし。
sv{type} svuzp2[_{t}](sv{type} input1, sv{type} input2)
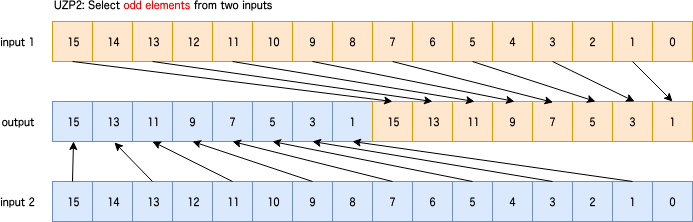
ZIP1: Interleave elements from low halves of two inputs
2つのレジスタから図のように下半分の要素を選択。predicateなし。
sv{type} svzip1[_{t}](sv{type} input1, sv{type} input2)
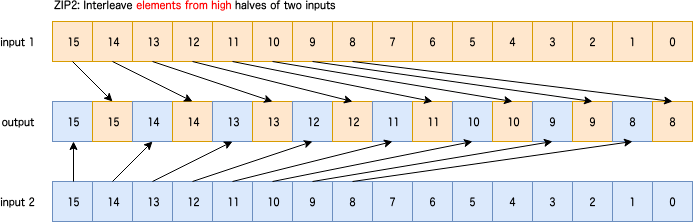
ZIP2: Interleave elements from high halves of two inputs
2つのレジスタから図のように上半分の要素を選択。predicateなし。
sv{type} svzip2[_{t}](sv{type} input1, sv{type} input2)
レジスタ要素変換系の関数
UNPKLO: Unpack and extend low half of an input
なぜか整数型のみ。レジスタの下半分の要素を一段階上のビット幅の型にキャスト。アウトプットの要素数は半分になる。predicateなし。
ここでの {type_n?} は [int{8,16,32,64}_t, uint{8,16,32,64}_t]。 {type_n2} は {type_n1} より一段階大きい。
sv{type_n2} svunpklo[_{t_n2}](sv{type_n1} input1)
例: svuint64_t svunpklo[_u64](svuint32_t input1)

UNPKHI: Unpack and extend high half of an input
なぜか整数型のみ。レジスタの上半分の要素を一段階上のビット幅の型にキャスト。アウトプットの要素数は半分になる。predicateなし。
ここでの {type_n?} は [int{8,16,32,64}_t, uint{8,16,32,64}_t]。 {type_n2} は {type_n1} より一段階大きい。
sv{type_n2} svunpkhi[_{t_n2}](sv{type_n1} input1)
例: svint16_t svunpkhi[_s16](svint8_t input1)

CVT: Convert floating-point value to wider type
整数型も浮動小数点型もあり。図のように偶数番目の要素を一段階上のビット幅の型にキャスト。奇数番目の要素は無視。要素数は半分になる。predicateあり。
sv{type_n2} svcvt_{t2}[_{t1}]_x(svbool_t pg, sv{type_n1} input1)
例: svfloat64_t svcvt_f64[_f32]_x(svbool_t pg, svfloat32_t input1)

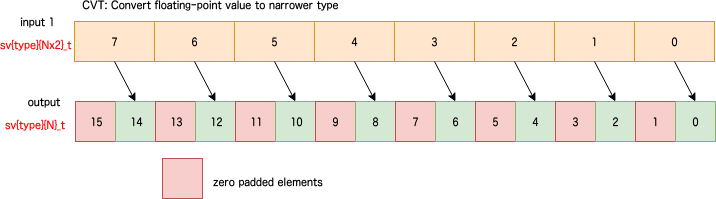
CVT: Convert floating-point value to narrower type
整数型も浮動小数点型もあり。図のように一段階下のビット幅の型にキャスト。偶数番目の要素に値が入り、奇数番目の要素はゼロ埋め。要素数は2倍になる。predicateあり。
sv{type_n1} svcvt_{t1}[_{t2}}]_x(svbool_t pg, sv{type_n2} input1)
例: svfloat32_t svcvt_f32[_f64]_x(svbool_t pg, svfloat64_t input1)
もう少し使いやすい関数を作る
ARM SVE intrinsic命令で使えそうなレジスタ操作関数はおそらく上記のものくらいしかないがいまいち使いにくいので上記の関数を組み合わせて変換関数を作っておく。predicateは32bit要素のレジスタが全部実行されるものを入れておかないとおかしくなると思う。
svfloat32_tの下半分をsvfloat64_tに変換
static inline svfloat64_t svcvt_f32lo_to_f64(svbool_t pg, svfloat32_t in32)
{
svfloat64_t out64 = svcvt_f64_x(pg, svzip1(in32, in32));
return out64;
}
svfloat32_tの上半分をsvfloat64_tに変換
static inline svfloat64_t svcvt_f32hi_to_f64(svbool_t pg, svfloat32_t in32)
{
svfloat64_t out64 = svcvt_f64_x(pg, svzip2(in32, in32));
return out64;
}
svfloat64_tをsvfloat32_tに変換し、下半分に入れる
svfloat32_tの上半分はゼロ埋め。
static inline svfloat32_t svcvt_f64_to_f32lo_z(svbool_t pg, svfloat64_t in64)
{
svfloat32_t out32 = svcvt_f32_x(pg, in64);
out32 = svuzp1(out32, svdup_f32(0.0f));
return out32;
}
svfloat64_tをsvfloat32_tに変換し、上半分に入れる
svfloat32_tの下半分はゼロ埋め。
static inline svfloat32_t svcvt_f64_to_f32hi_z(svbool_t pg, svfloat64_t in64)
{
svfloat32_t out32 = svcvt_f32_x(pg, in64);
out32 = svuzp1(svdup_f32(0.0f), out32);
return out32;
}
2つのsvfloat64_tをsvfloat32_tに変換し、上半分下半分にそれぞれ入れる
static inline svfloat32_t svcvt_2f64_to_f32(svbool_t pred, svfloat64_t in64lo, svfloat64_t in64hi)
{
svfloat32_t out32a = svcvt_f32_x(pg, in64lo); // lo
svfloat32_t out32b = svcvt_f32_x(pg, in64hi); // hi
out32a = svuzp1(out32a, out32b);
return out32a;
}