
さくらのAI Engineに、マルチモーダル対応の新規モデルが追加されました。ものすごいスピード感ですね!
公式ガイドはこちら
ということでまた試してみたので共有します。今回は事例として役所の申請書類を提出前にLINEでチェックできるBotとしました。Web対応も進んでいますが個人情報をふんだんに含むことも有り、まだまだ手書き&郵送で提出のパターンも多く恐らく莫大な手間がかかっているのではないかと。
完成図
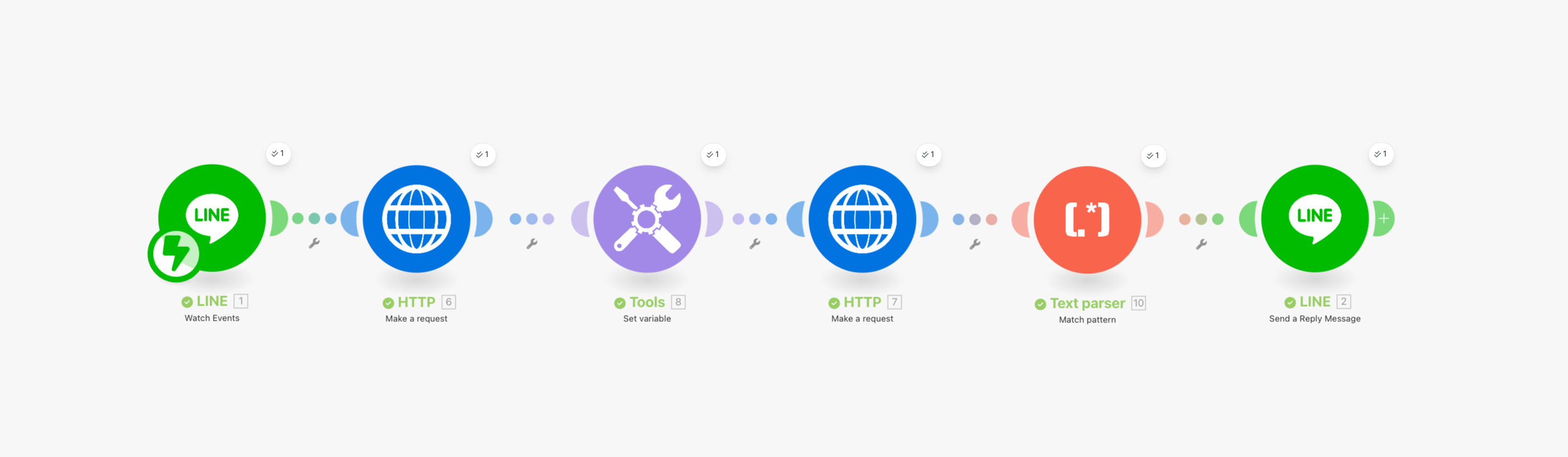
事前準備
今回もLINEで入力を受け取る部分までは同じですので、前回の記事
のユーザーの発話をファイルとして受け取るまでを終わらせておいて下さい。
この段階ではシナリオはこのような形になっています。
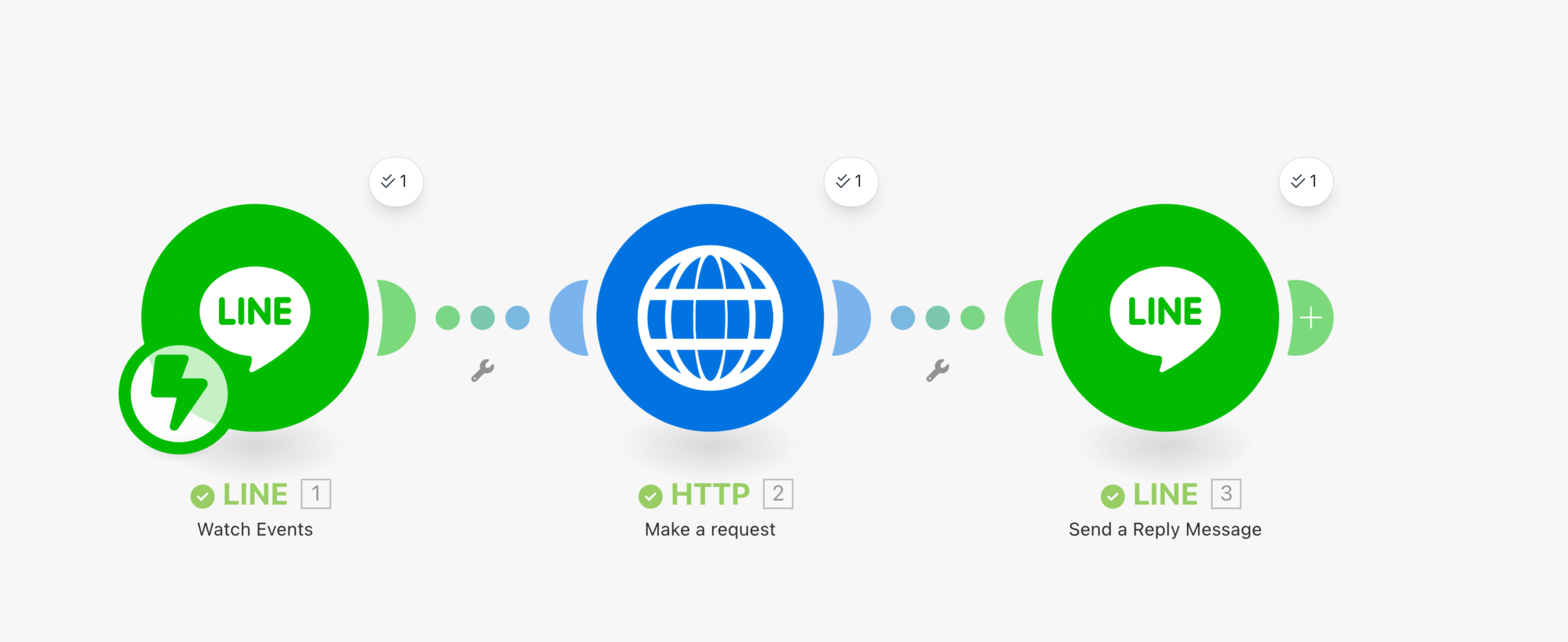
実装
プロンプト定義用のモジュール作成
では作っていきましょう。まず、今回はプロンプトを定義するためだけのモジュールを追加しましょう。場所は画像を取得するHTTPモジュールの後に置きました。
変数名はsystem_promptとしましたが何でも構いません。プロンプトは「画像を送るので、説明して下さい。」としておきましょう。
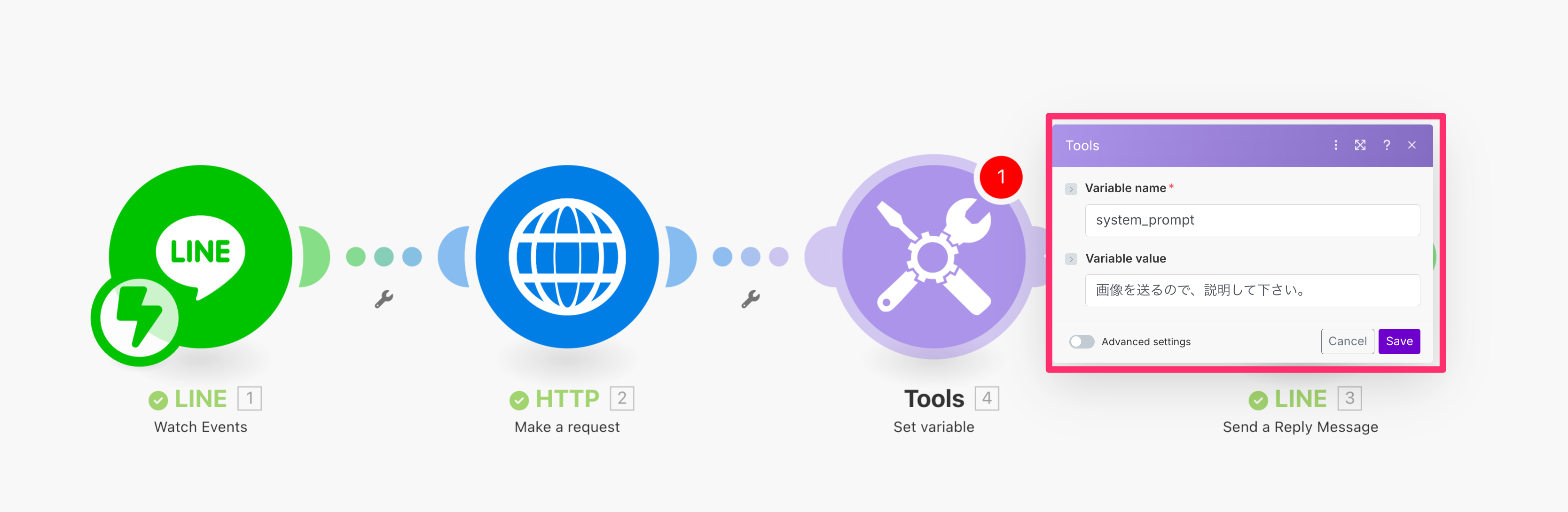
プロンプトが複雑な場合は何度も修正することになるのでこのように別に分けておいたほうが楽です。
画像を送って解析させてみる
画像をさくらのAI Engineに投げ、新しく使えるようになったマルチモーダルのモデルを使って理解、説明させてみましょう。
HTTP > Make a requestモジュールを追加し、以下のように設定します。
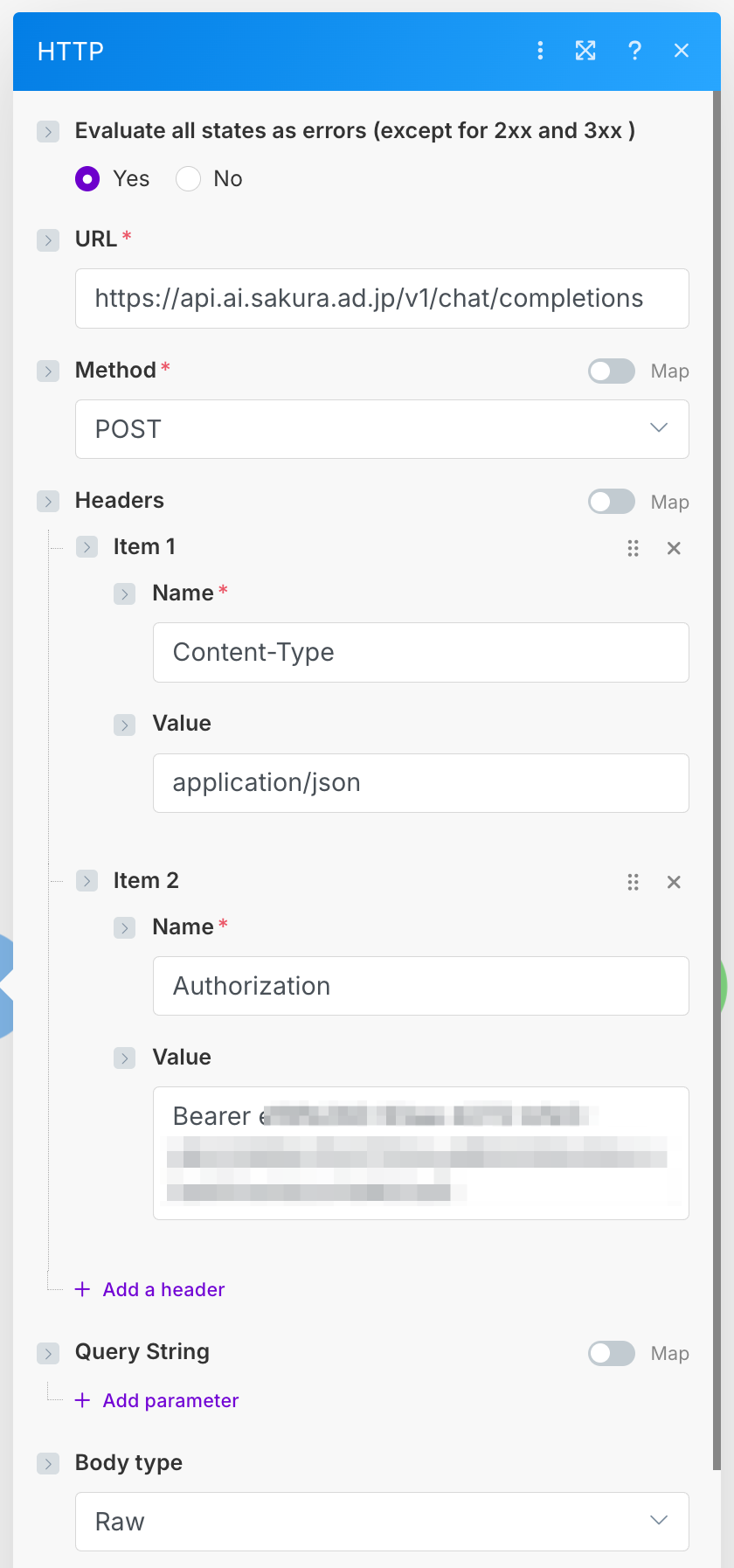
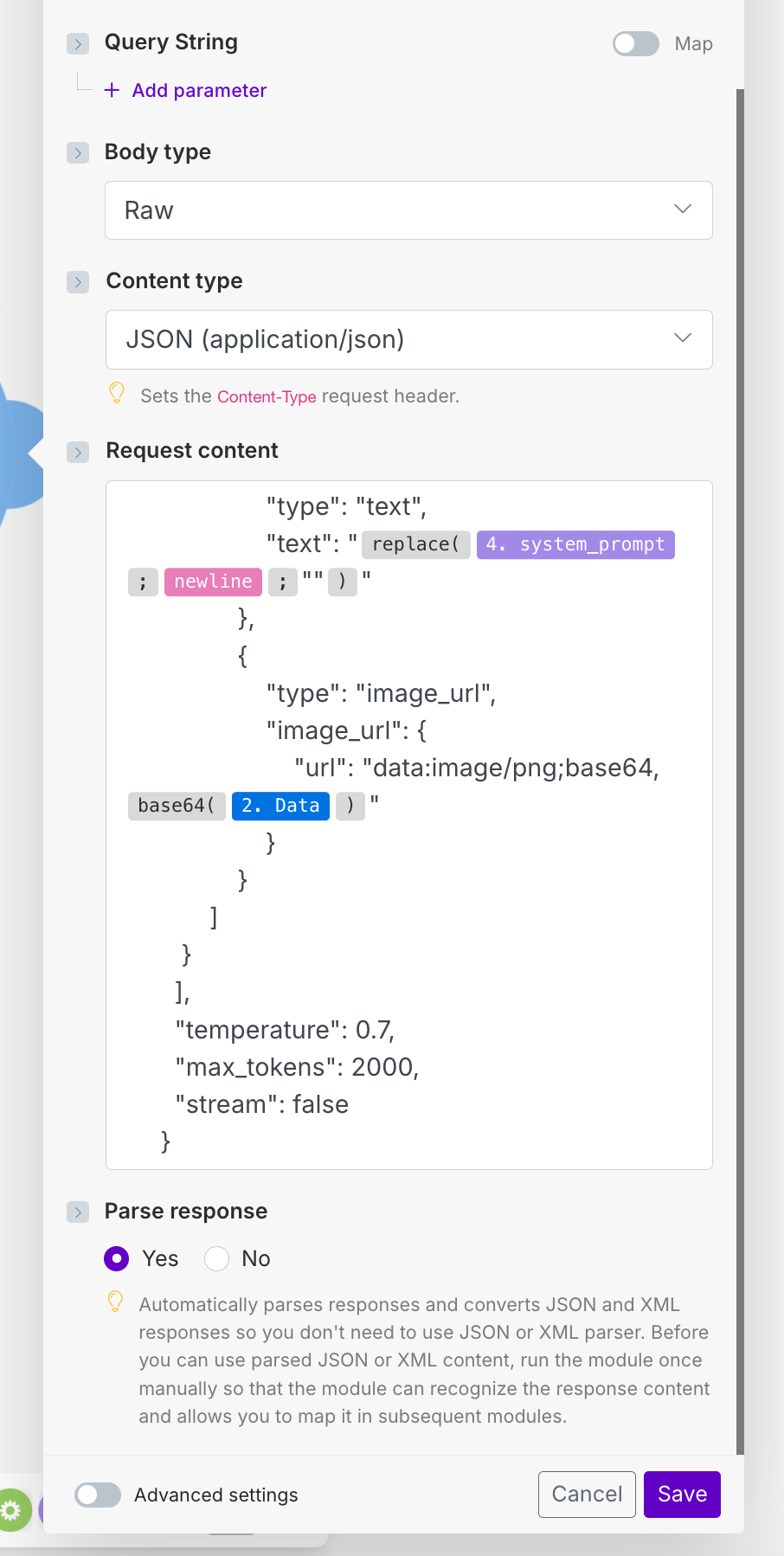
Request Contentは以下です。
{
"model": "preview/Qwen3-VL-30B-A3B-Instruct",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "{{replace(4.system_prompt; newline; "")}}"
},
{
"type": "image_url",
"image_url": {
"url": "data:image/png;base64,{{base64(2.data)}}"
}
}
]
}
],
"temperature": 0.7,
"max_tokens": 2000,
"stream": false
}
マルチモーダルのモデルはpreview/Qwen3-VL-30B-A3B-Instruct、preview/Phi-4-multimodal-instructの2つが追加されましたが、OCR用途ではQwen3-VL-30B-A3B-Instructの方が圧倒的に精度がよかったのでこちらを利用しました。
今はこうなっていると思います。

LINE Botと友だちになり、適当な画像を送ってみましょう。
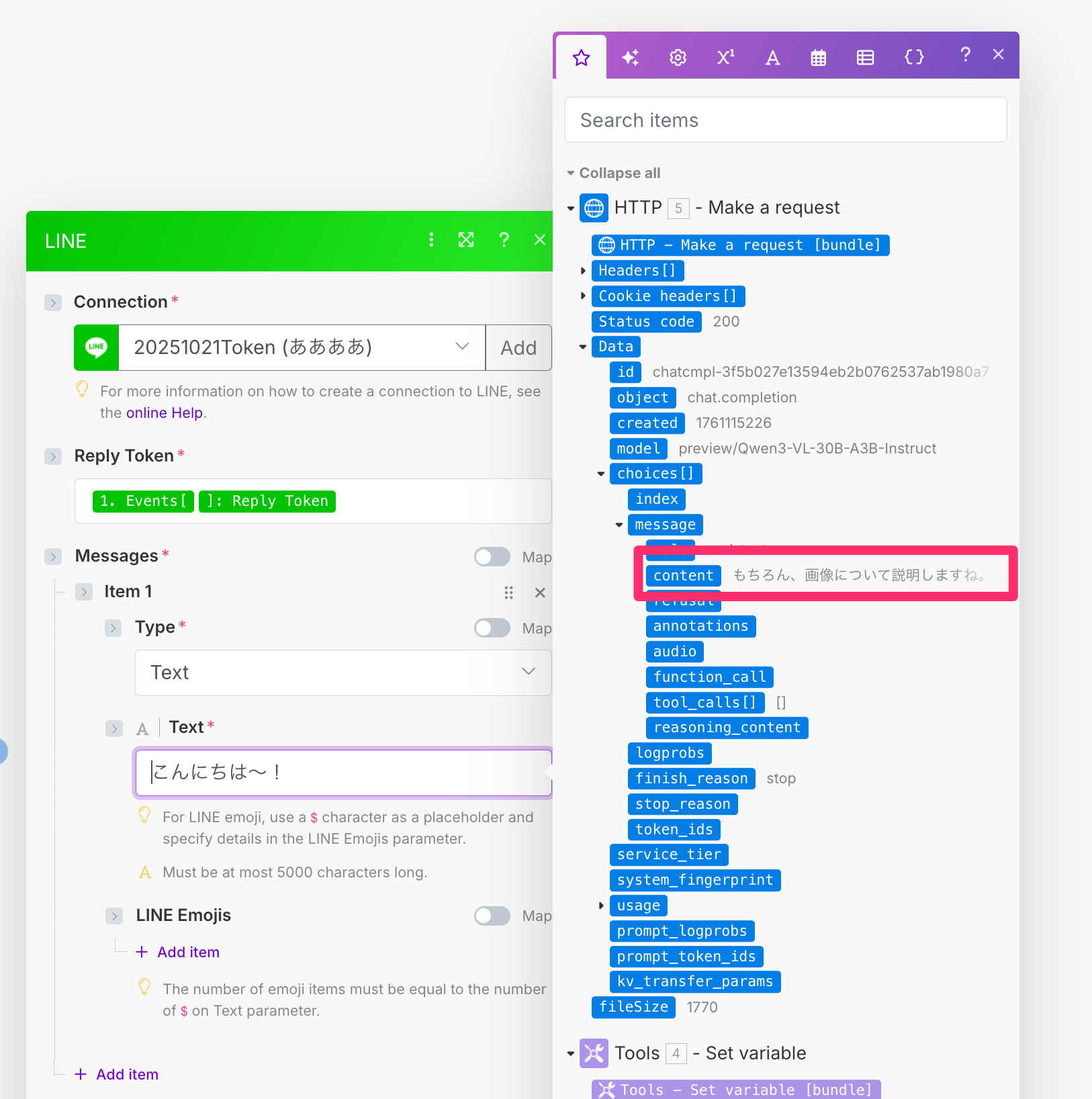
返答は変わっていませんが、モジュールのテキストボックスクリックから確認すると問題なく解析されていることがわかります。最後のLINE > ReplyモジュールのTextをこちらに変更します。
もう一度送ってみます。
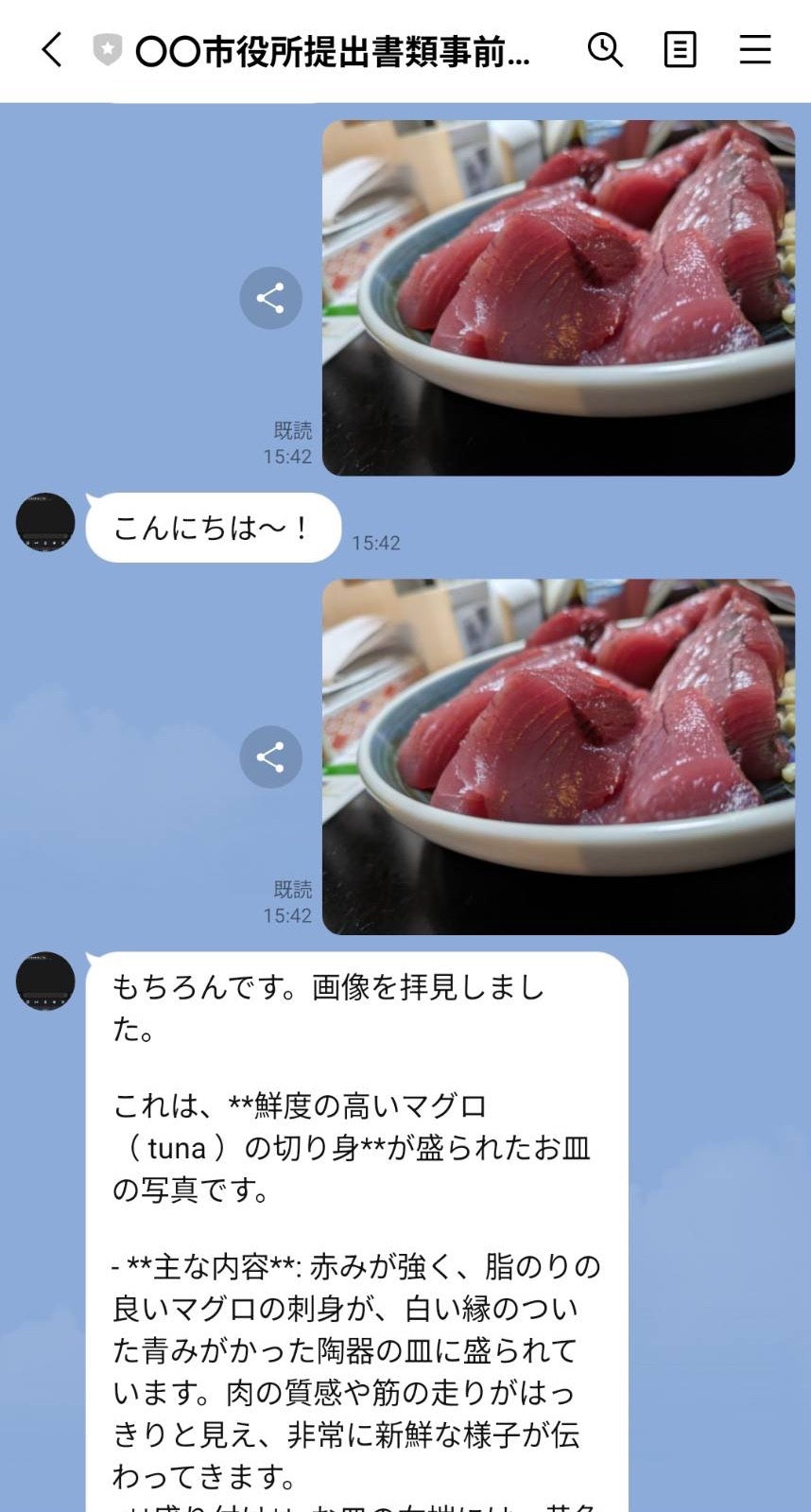
解析された結果をLINEで見ることができるようになりました!
今回利用する申請書類の説明、準備
今回は例として横浜市の施設利用申請書を利用します。こちらのリンクから、「プール専用利用申込書(PDF:114KB)」をダウンロードして下さい。
1ページ目が提出用、2ページ目が記載見本となっています。
これをそれぞれキャプチャするなどして、どこか適当な場所にアップロードし、URLでアクセスできるようにしておいて下さい。
私はGoogle Driveにアップロードしました。
Google Driveにアップロードする場合はファイルIDを使ってhttps://lh3.googleusercontent.com/d/【ファイルID】=w1000?authuser=0というような形で直接画像を指すURLに変換する必要がありますのでご注意下さい。
申請書類のチェックに変更
準備ができましたので、単純な画像の解析ではなく申請書類の誤入力や入力漏れを検知し、その箇所を出力できるようなプロンプトに変更しましょう。Toolsモジュールで定義した変数の値を書き換えます。
あなたは優秀な事務作業アシスタントです。申請書類の記入忘れと違反をチェックします。
[入力]
1枚目に記載見本、2枚目に全て未記載の書類、3枚目にユーザーが記載済みの書類を送ります。
[タスク1]
まず1枚目と2枚目を比較して、記載されるべき項目をしっかりと認識してください。1枚目2枚目双方で未記載の使用料の額、減免の取扱い、納付使用料は記載されるべき項目ではありません。表上部の申込者の住所から利用者番号までは記載されるべき項目です。
これらを辞書形式の変数Aとして所持して下さい。valueはnullとして下さい。
[タスク2]
変数Aの各keyについて、3枚目のユーザーが記載済みの書類画像に記載されている内容を読み取り、記載があればvalueに格納していってください。
[タスク3]
配列型変数Bを定義します。変数Aの中でvalueがnullのkeyを抽出し、1件ごとに変数Bに追加して下さい。
その際「keyが未入力です」という文字列を追加して下さい。
[タスク4]
変数Aのkey利用人数について、20名を超えている場合は変数Bに「利用人数がオーバーしています」という文字列要素を追加して下さい。
[タスク5]
変数Aのkey利用利用者番号について、ハイフンが含まれる場合、「利用者番号は電話番号ではなく会員番号を記載して下さい」という文字列要素を追加して下さい。
[タスク6]
条件により変わります。
変数Tの要素が1個以上の場合:
変数Tを以下の形の文字列で定義して下さい
「【変数Bの各要素を。区切り】」
変数Tの要素が0個の場合:
変数Tを以下として下さい
「記入に問題は有りません。提出可能です。」
- タスク4で精度の確認のため人数を20名に制限するプロンプトを追加していますが、実際の上限人数は未確認です
- タスク5でよくありそうな間違いをチェックするプロンプトを追加しています
全然まだ改良できると思うのですが、きりがないので今回はこちらとしました。
続いて、HTTPモジュールの方も書き換えます。
{
"model": "preview/Qwen3-VL-30B-A3B-Instruct",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "{{replace(4.system_prompt; newline; "")}}"
},
{
"type": "image_url",
"image_url": {
"url": "入力見本の画像URL"
}
},
{
"type": "image_url",
"image_url": {
"url": "全て未入力の画像URL"
}
},
{
"type": "image_url",
"image_url": {
"url": "data:image/png;base64,{{base64(2.data)}}"
}
}
]
}
],
"temperature": 0.7,
"max_tokens": 2000,
"stream": false
}
少しややこしくなってきたのですが、仕組みは単純で、以下のようになっています。
-
content>text> プロンプト -
content>image_url(1個目)> 入力済みの見本画像のURL、Google Drive等のURLを指定。今回の場合はPDFの2ページ目 -
content>image_url(2個目)> 全て未入力の画像のURL、Google Drive等のURLを指定。今回の場合はPDFの1ページ目 -
content>image_url(3個目)> LINEから送られた、チェックが必要な画像のデータ
事前の学習無しでもそれなりの精度が出るよう、このような構成にしました。
続いてHTTPモジュールの後にモデルが返してきた出力から必要な部分だけを抜き出すため、Text Parser > Match patternモジュールを追加し、以下のように設定します。
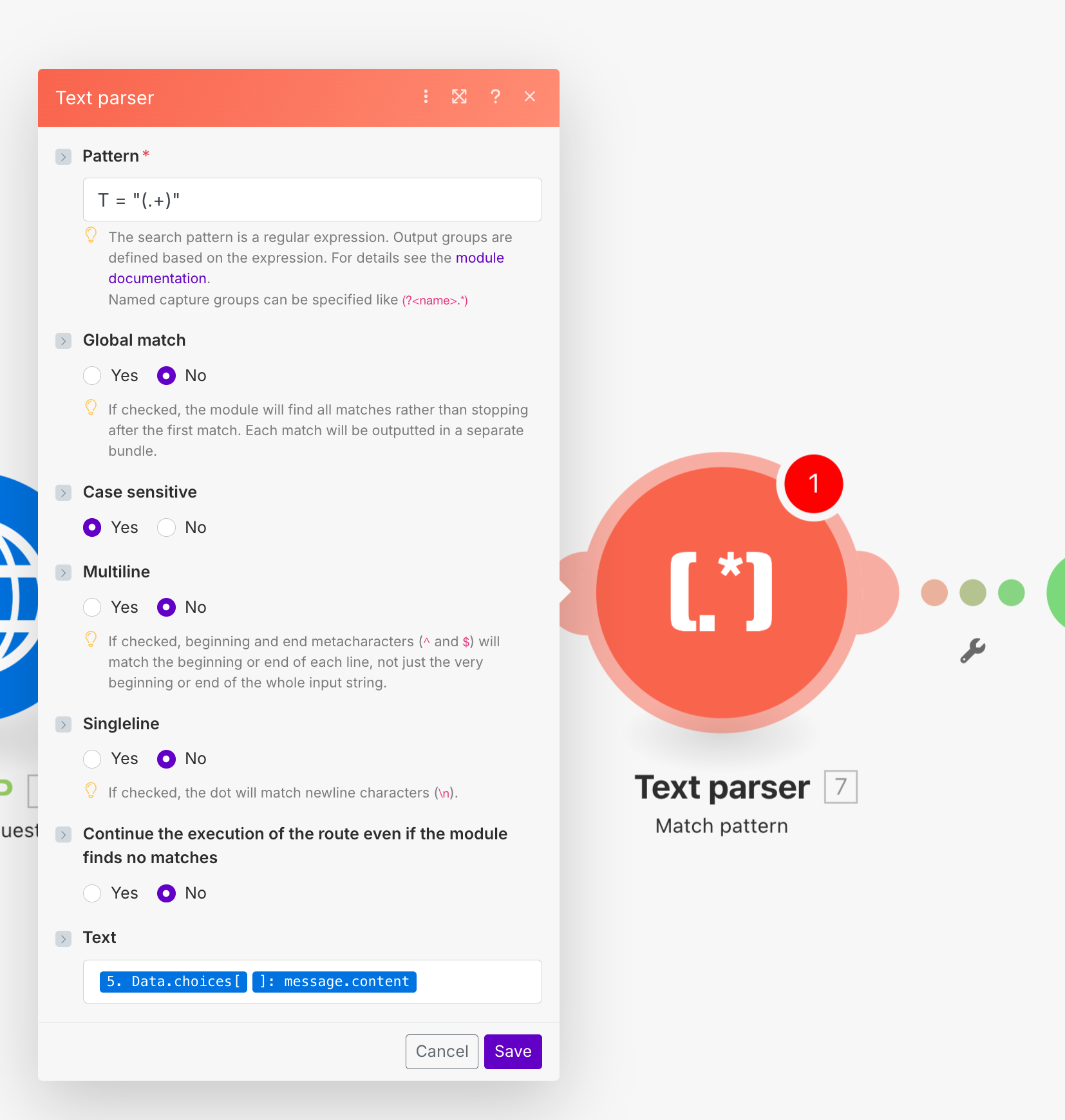
ここまでモデルがやってくれればよかったのですがどうしても出力を絞ろうとすると精度がブレるのでこのような形にしています。
最後に、LINEのReplyの内容も変えておきましょう。
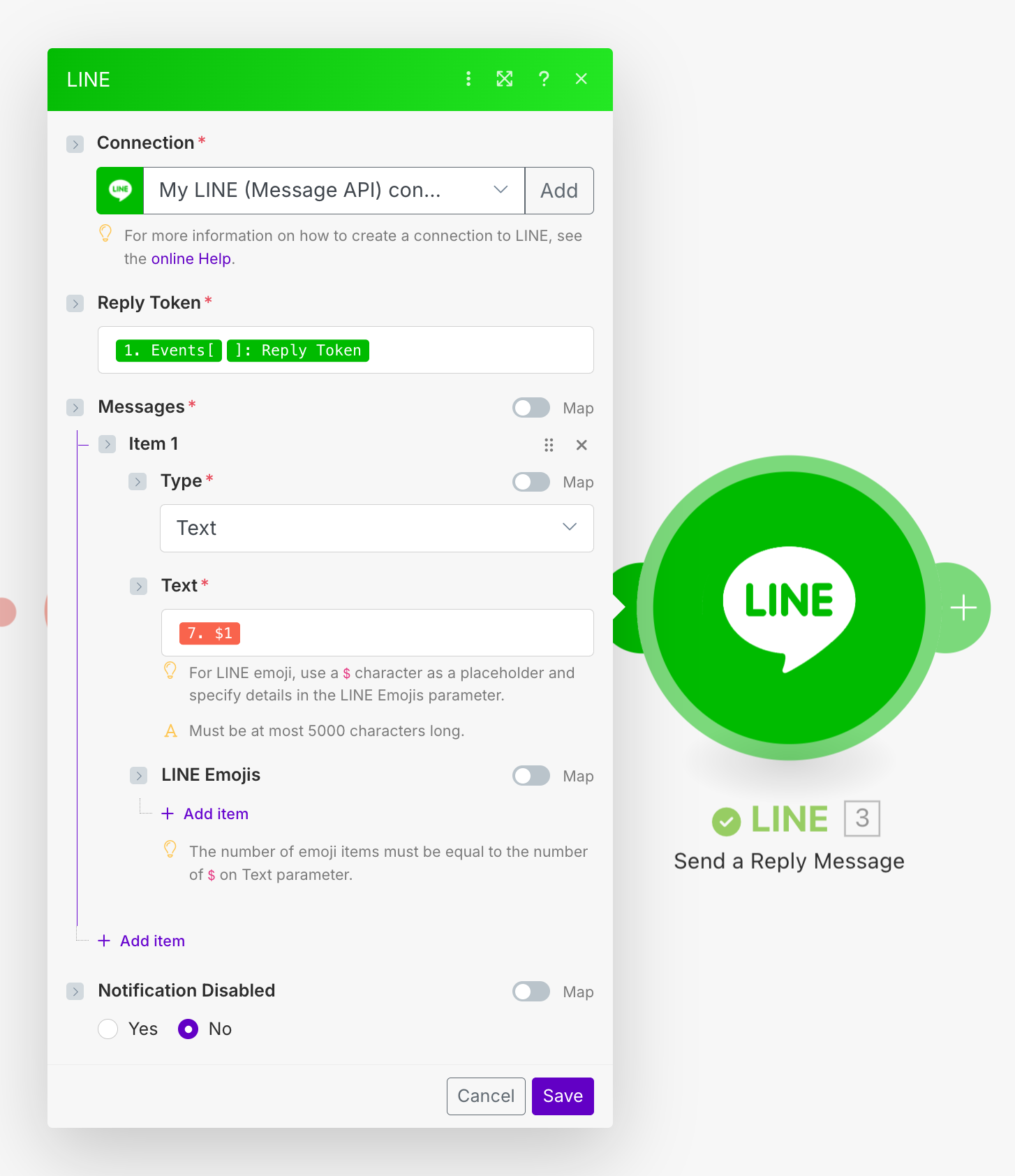
動作確認
これで完成ですので、動作チェックをしてみましょう。
まず
- 利用者番号に会員番号ではなく電話番号を記載する
- 利用の目的を空欄にする
- 人数を上限(仮)を超える35名と記載する
という間違いをあえてしたものを送ってみます。
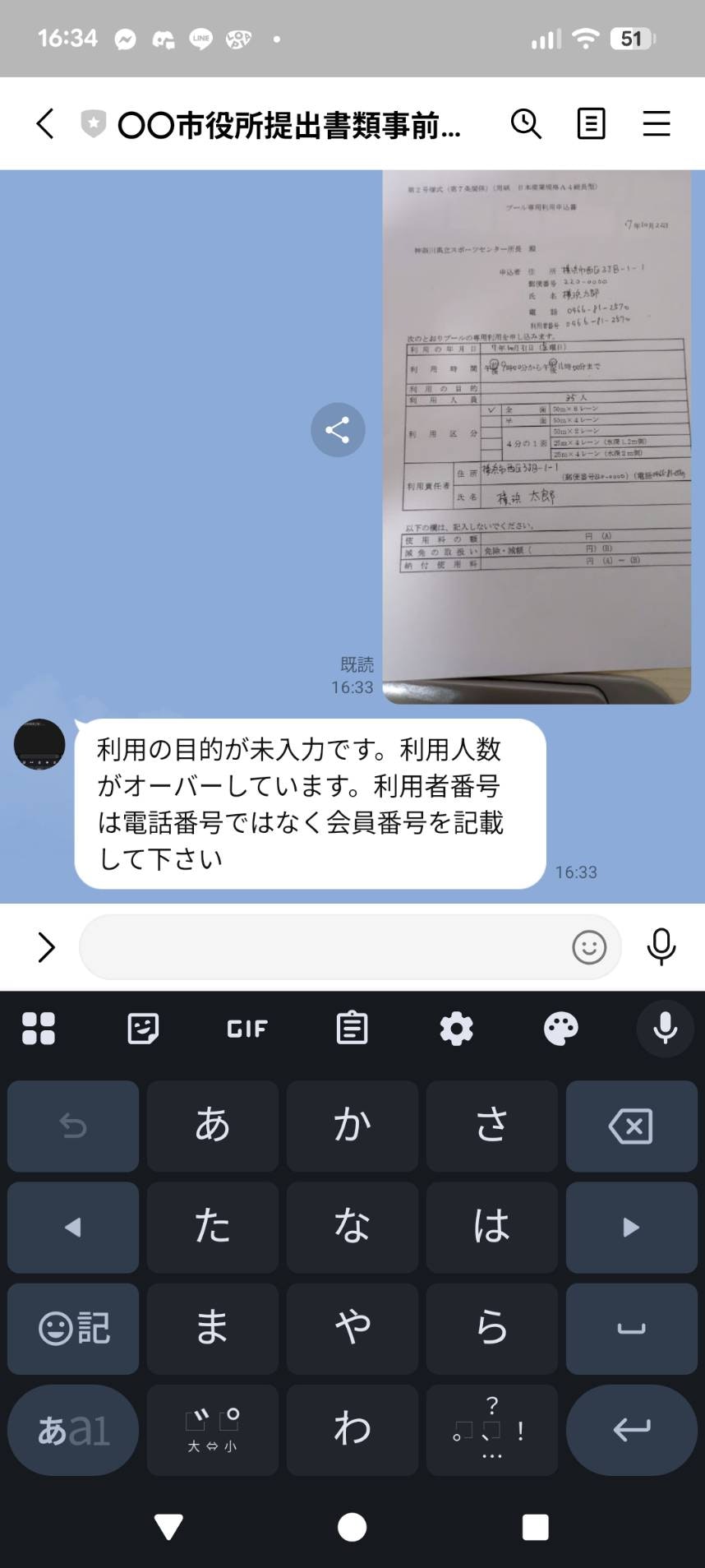
未入力、上限超過、よくあるエラー全て誤入力を認識し指摘してくれています!
エラーを修正したものを送ってみましょう。
問題なく動作しています。
まとめ
今回も大して詰まるところなく(プロンプト除く😫)、スムーズにプロトタイプを作れました。しかも結構使いましたがまだ全然無料の範囲内です。
生成AIを活用したサービスはどんどん敷居が下がっていますね。ありがたい限りです。
皆様も是非お試し下さい。
ちょっとだけコミュニティ宣伝
LINE Developer CommunityではLINEや生成AI、クラウド等の情報が日々アウトプットされております。
皆様によるさくらのAI × LINE Botのノウハウはもちろん、LINEやチャットボットに関する知見のアウトプットを心よりお待ちしております。