はじめに
坂道シリーズの個人ブログ クローリング&スクレイピング第二弾です。第一弾はPythonで始めるクローリング&スクレイピング〜日向坂46の個人ブログから更新回数を取得する〜でした。まだご覧になられていない方は是非こちらもご覧ください。
欅坂46について簡単に説明すると、乃木坂46に続く第二の坂道シリーズの女性アイドルグループで、アイドルとは思えない激しいダンスやロックな楽曲に人気があります。
先日、日本武道館で行われた欅坂46 3rd YEAR ANNIVERSARY LIVEが初めての欅坂46ライブ参戦になりましたが、独特の雰囲気でどの曲も好きだったので最高に盛り上がりました。
今回は前回と同じような手順で、欅坂46の個人ブログをクローリング&スクレイピングし、メンバー毎の更新回数を収集することを目標とします。
また、難易度に関しては、欅坂46のHTMLの構造上、日向坂46より若干高くなります。
注意
Webスクレイピングを行う際には、岡崎市立中央図書館事件などを参考に、1秒あたりのアクセス回数に注意したり、robots.txtを遵守するなど道徳的かつ節度のある行動を心掛けましょう。
できること
このチュートリアルを終えると、以下のようなことができるようになります。

「Chromeは自動テスト ソフトウェアによって制御されています」と記載されている通り、100%自動でブラウジングしています。普通はクリックしないとページ遷移できないところもプログラムで動かしてるんですよ。普通に考えるとすごくないですか。
Python keyakizaka.py > keyakizaka.txt
上記コマンドの実行例が以下のようになります。
今回は一番簡易な例として、JSONファイルに出力していますが、NoSQLなどに保存することも可能です。
{'石森 虹花': 620, '上村 莉菜': 531, '尾関 梨香': 555, '織田 奈那': 561, '小池 美波': 546, \
'小林 由依': 432, '齋藤 冬優花': 1166, '佐藤 詩織': 537, '菅井 友香': 793, '鈴本 美愉': 233, \
'長沢 菜々香': 1197, '長濱 ねる': 345, '土生 瑞穂': 484, '原田 葵': 666, '平手 友梨奈': 109, \
'守屋 茜': 611, '渡辺 梨加': 109, '渡邉 理佐': 263, '井上 梨名': 23, '関 有美子': 36, \
'武元 唯衣': 28, '田村 保乃': 27, '藤吉 夏鈴': 36, '松田 里奈': 28, '松平 璃子': 25, \
'森田 ひかる': 28, '山﨑 天': 18}
利用方法
以下レファレンスを開きながら、Seleniumのオプションを確認し、自分でコードを書きながら記事を読むと理解が深まります。
対象読者
- Python, JavaScriptの基礎的なコードの読み書きができる人
- 坂道シリーズのファン(乃木坂46、欅坂46、日向坂46)
- クローリング&スクレイピングしたい人(初心者想定)
前提条件
- macOS Mojave バージョン10.14.5(Windows, Linuxは対象外とします)
- Python 3.6以上(Python3.x系なら動作すると思います。導入方法はお任せしますが、パスが通っていれば問題ないです)
- pipのインストール(Seleniumをインストールするために必要です)
- ChromeDriver(お使いのChromeのバージョンに合わせてダウンロードしてください)
- XPath Helper
Seleniumのインストール
Seleniumとはブラウザを任意のプログラムで自動操作するために用いられるツール群のことです。
Pythonの他にもC#, Java, Perl, PHP, Rubyなどで利用することができます。
Seleniumはクローラーを開発するために必ずしも必要な訳ではありませんが、
SPAなどJavaScriptを多用しているサイトをクローリングする際には利用が必須となります。
早速、Seleniumをインストールしましょう。
pip install selenium
ChromeDriverのダウンロード
以下の手順を参考にしてChromeのバージョンを最新にしてから、対応するバージョンのChromeDriverをダウンロードしてください。ダウンロードしたら、/usr/local/bin/配下に置いてください。Permission Deniedと怒られたら、sudoつけてから再度実行してください。
アップデートが利用可能かどうかと、パソコンの現在のブラウザのバージョンを確認する手順
パソコンで Chrome を開きます。
右上のその他アイコン 高 をクリックします。
[ヘルプ] 次に [Google Chrome について] をクリックします。
[Google Chrome] という見出しの下に表示される番号が現在のバージョン番号です。このページを表示したとき、アップデートがあるかどうかが確認されます。
アップデートがある場合は、[再起動] をクリックして適用します。
XPath Helperのダウンロード
本チュートリアルでは欅坂46ブログのHTMLの構造上、ID、クラス名での抽出ができないため、
XPATHで抽出します。XPATH Helperを使うと簡単に要素のXPATHが分かるため、オススメです。
実装手順
具体的な実装手順を記載しています。
- JavaScriptで必要なHTMLの要素を抽出しよう
- Seleniumと融合させよう
- 完成
JavaScriptで必要なHTMLの要素を抽出しよう
ブログを書いたメンバーの名前を取得する
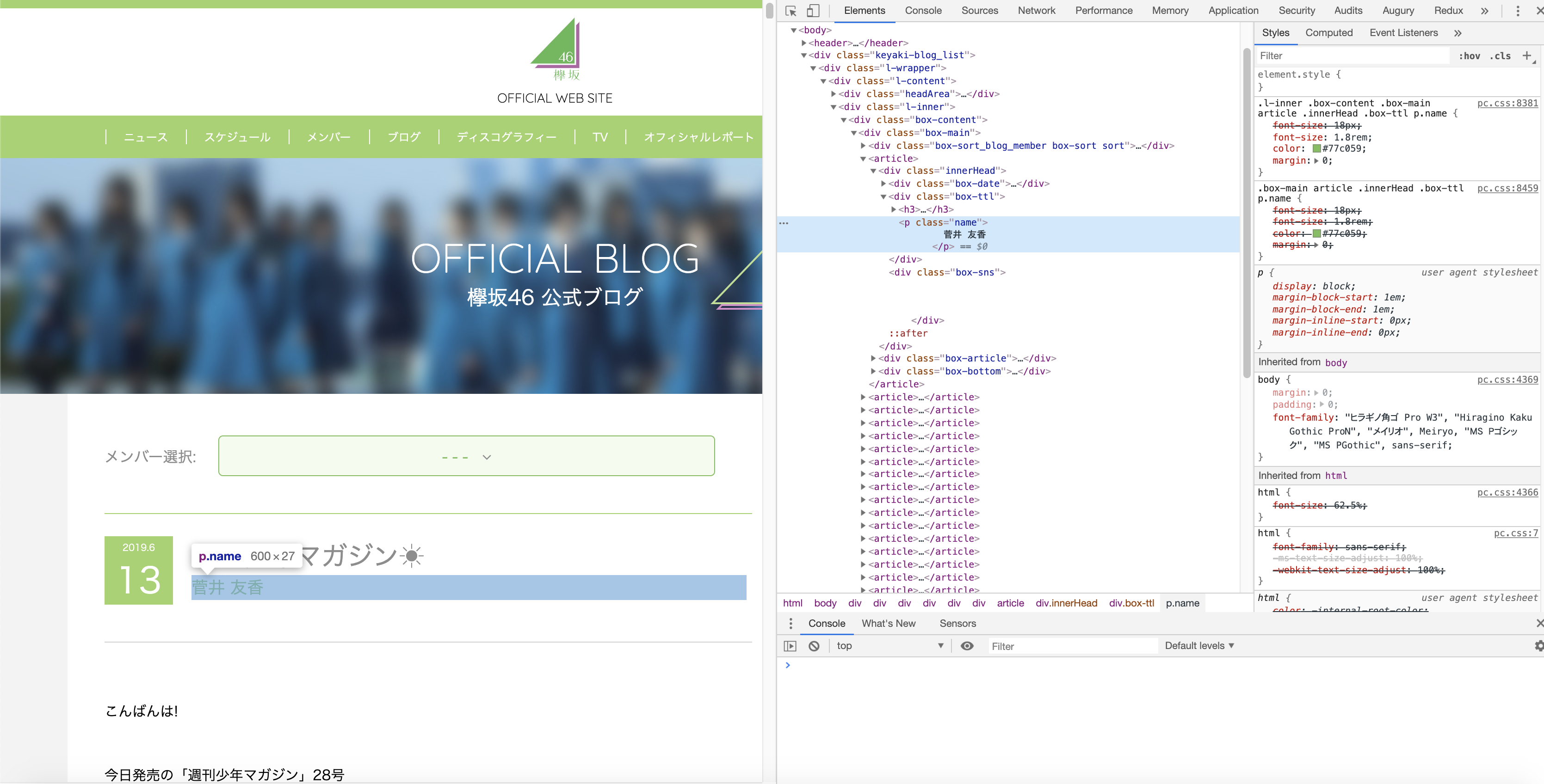
まず、一番すぐに思いつく方法でやってみましょう。
実際に実行すると分かるのですが、ページ下部のメンバー紹介欄にあるメンバー名にもマッチしてしまい、
目的であるブログを書いたメンバーの名前が抽出できません。
document.getElementsByClassName('name')
// HTMLCollection(57) [p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name]
一意に抽出するために少なくとも2つの方法があります。
- Document.querySelectorAll()を利用して、CSSセレクタの記法で要素を抽出する方法
- XPATHを用いて要素を抽出する方法
まずはCSSセレクターで指定する方法を解説します。
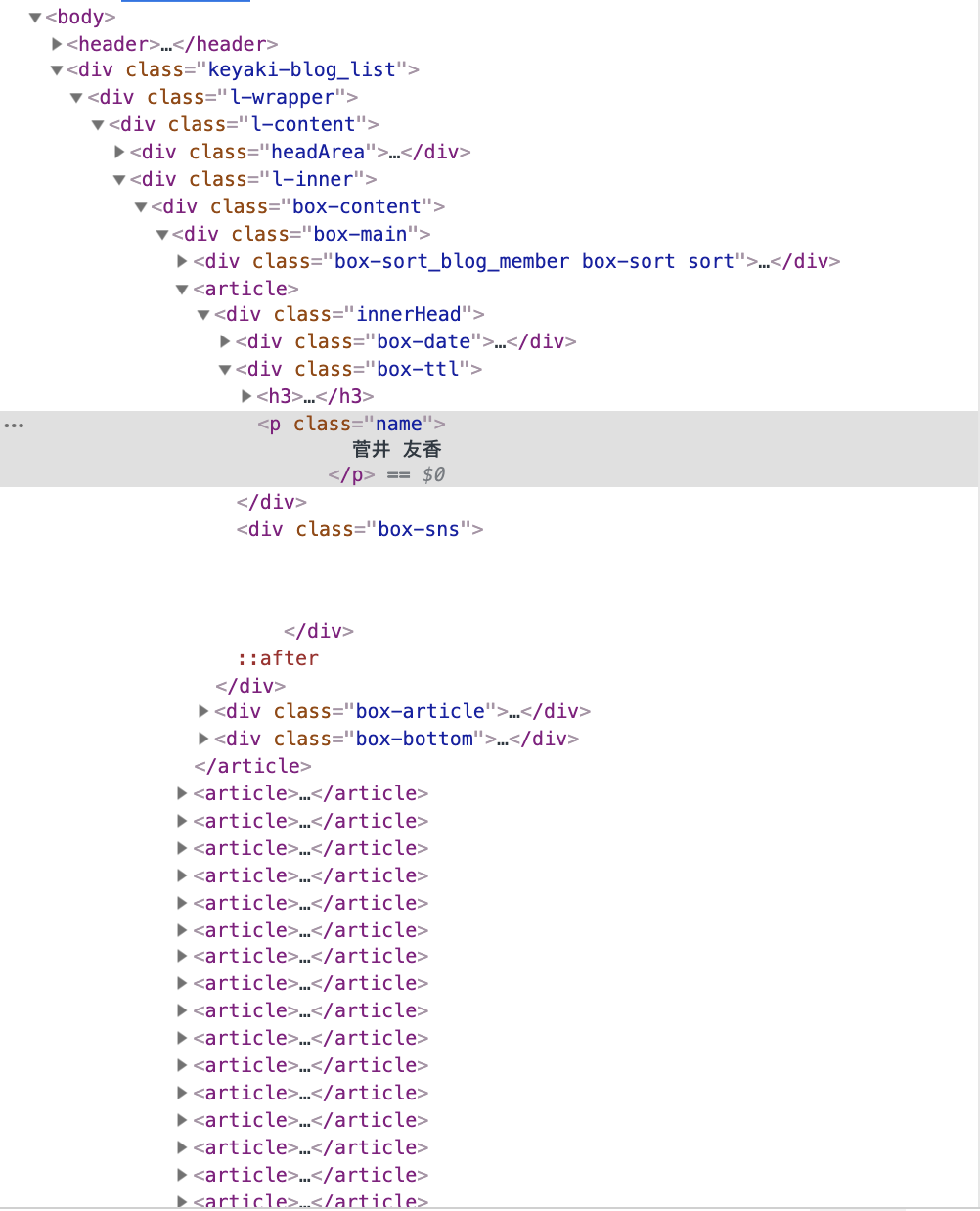
取得したいブログを書いたメンバー名はdivタグ(クラス名: box-ttl)配下のpタグ(クラス名: name)にあるため、
以下のメソッドを用います。
document.querySelectorAll('div.box-ttl p.name')
// NodeList(20) [p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name, p.name]
2つ目の方法はXPATHで要素を抽出する方法です。
XPATH Helperをクリックで実行してShiftキーを押しながら、要素をHoverすると、XPATHの絶対パスが表示されます。
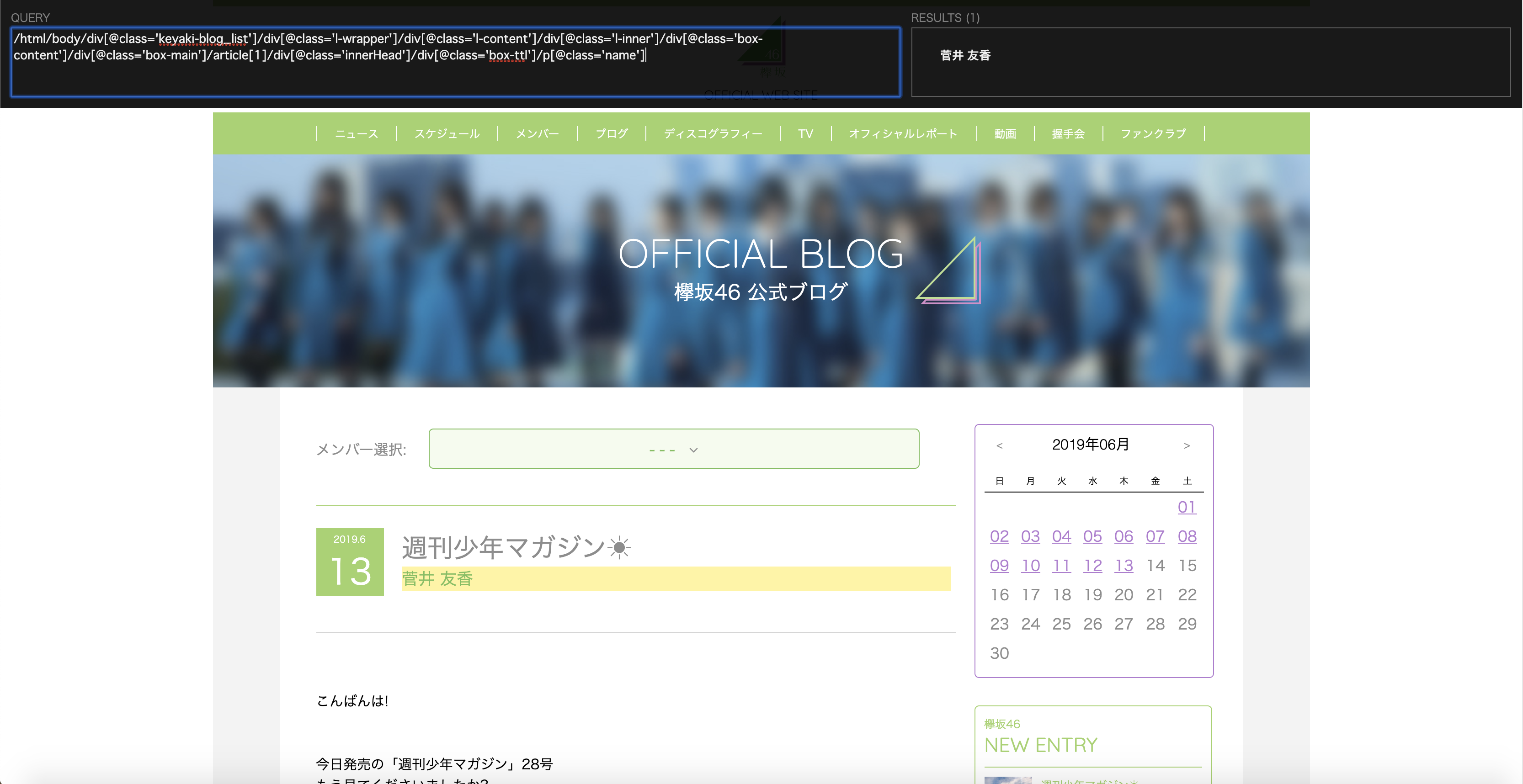
画像だと見にくいので、XPATHを併記します。
注目してもらいたいのは、article[1]の部分で、このままだと1つ目の記事のメンバー名しか取得できません。
/html/body/div[@class='keyaki-blog_list']/div[@class='l-wrapper']/div[@class='l-content']/div[@class='l-inner']/div[@class='box-content']/div[@class='box-main']/article[1]/div[@class='innerHead']/div[@class='box-ttl']/p[@class='name']
// RESULTS (1) 菅井友香
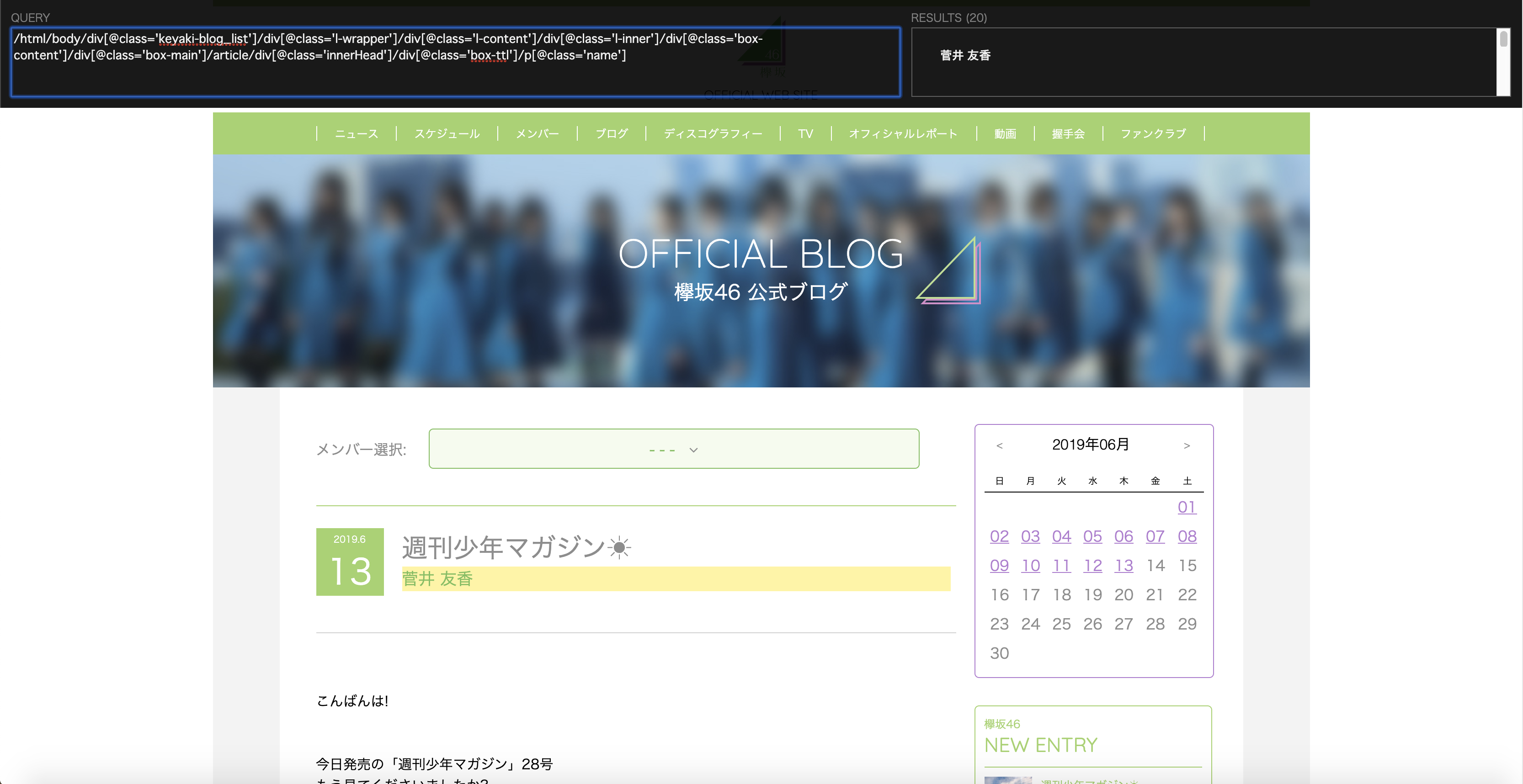
article[1]をarticleに変更します。すると、以下のようにブログのメンバー名のみを取得できます。
/html/body/div[@class='keyaki-blog_list']/div[@class='l-wrapper']/div[@class='l-content']/div[@class='l-inner']/div[@class='box-content']/div[@class='box-main']/article/div[@class='innerHead']/div[@class='box-ttl']/p[@class='name']
// RESULTS (20) 菅井 友香 齋藤 冬優花 石森 虹花 長沢 菜々香 井上 梨名 松平 璃子 武元 唯衣 田村 保乃 長沢 菜々香 菅井 友香 武元 唯衣 齋藤 冬優花 佐藤 詩織 守屋 茜 齋藤 冬優花 齋藤 冬優花 武元 唯衣 長沢 菜々香 守屋 茜 藤吉 夏鈴
絶対パスで指定すると親要素が一つないだけで抽出が上手くいかない場合があるので、
相対パスで指定する方法に修正します。こんなに短いXPATHで抽出できるのですね。
//div[@class='box-ttl']/p[@class='name']
// RESULTS (20) 菅井 友香 齋藤 冬優花 石森 虹花 長沢 菜々香 井上 梨名 松平 璃子 武元 唯衣 田村 保乃 長沢 菜々香 菅井 友香 武元 唯衣 齋藤 冬優花 佐藤 詩織 守屋 茜 齋藤 冬優花 齋藤 冬優花 武元 唯衣 長沢 菜々香 守屋 茜 藤吉 夏鈴
ページネーションの「>」ボタンを取得する
XPATHでページ遷移の次へボタンを取得すると、以下のようになります。
- 1ページ目の場合
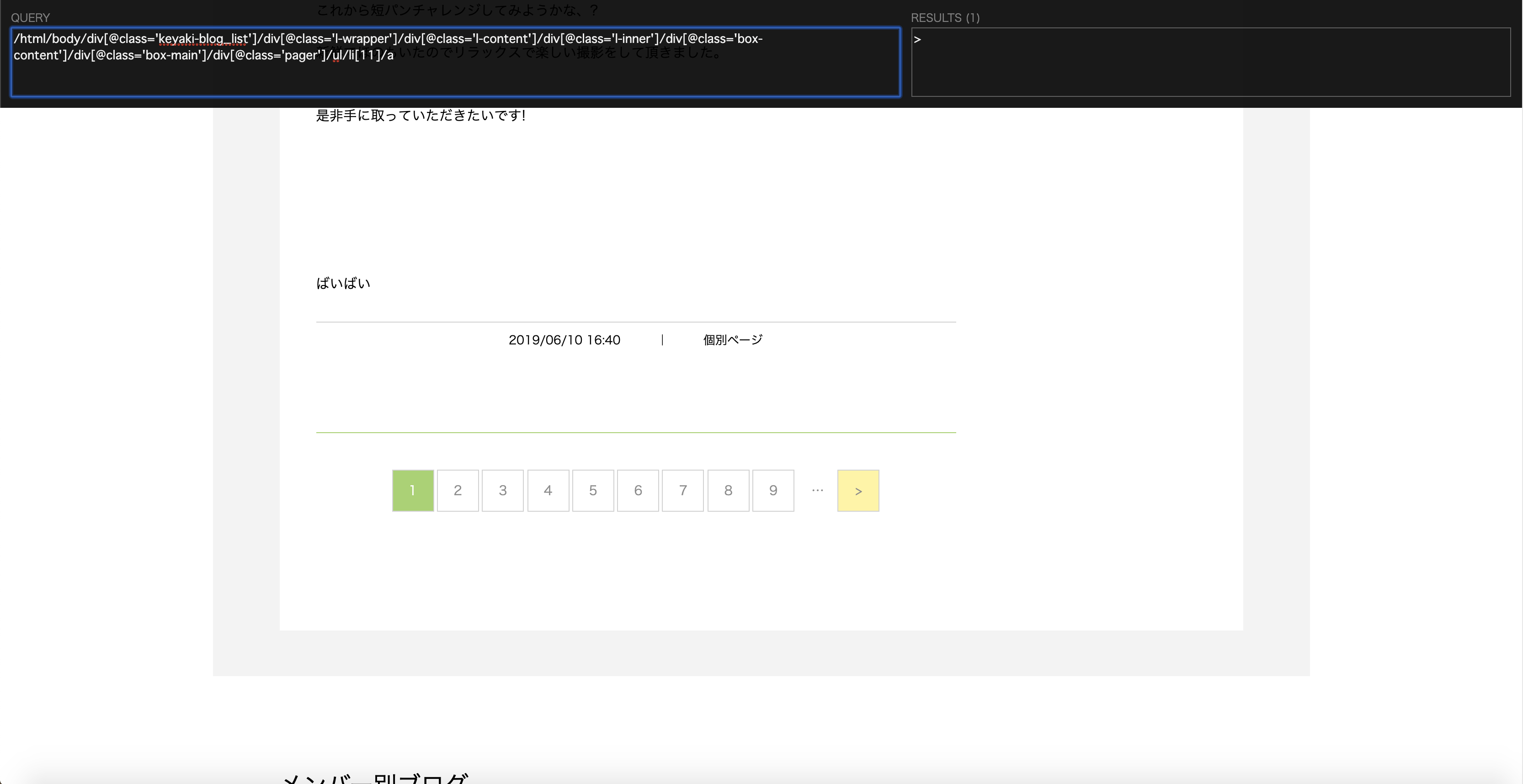
/html/body/div[@class='keyaki-blog_list']/div[@class='l-wrapper']/div[@class='l-content']/div[@class='l-inner']/div[@class='box-content']/div[@class='box-main']/div[@class='pager']/ul/li[11]/a
- 2ページ目以降の場合
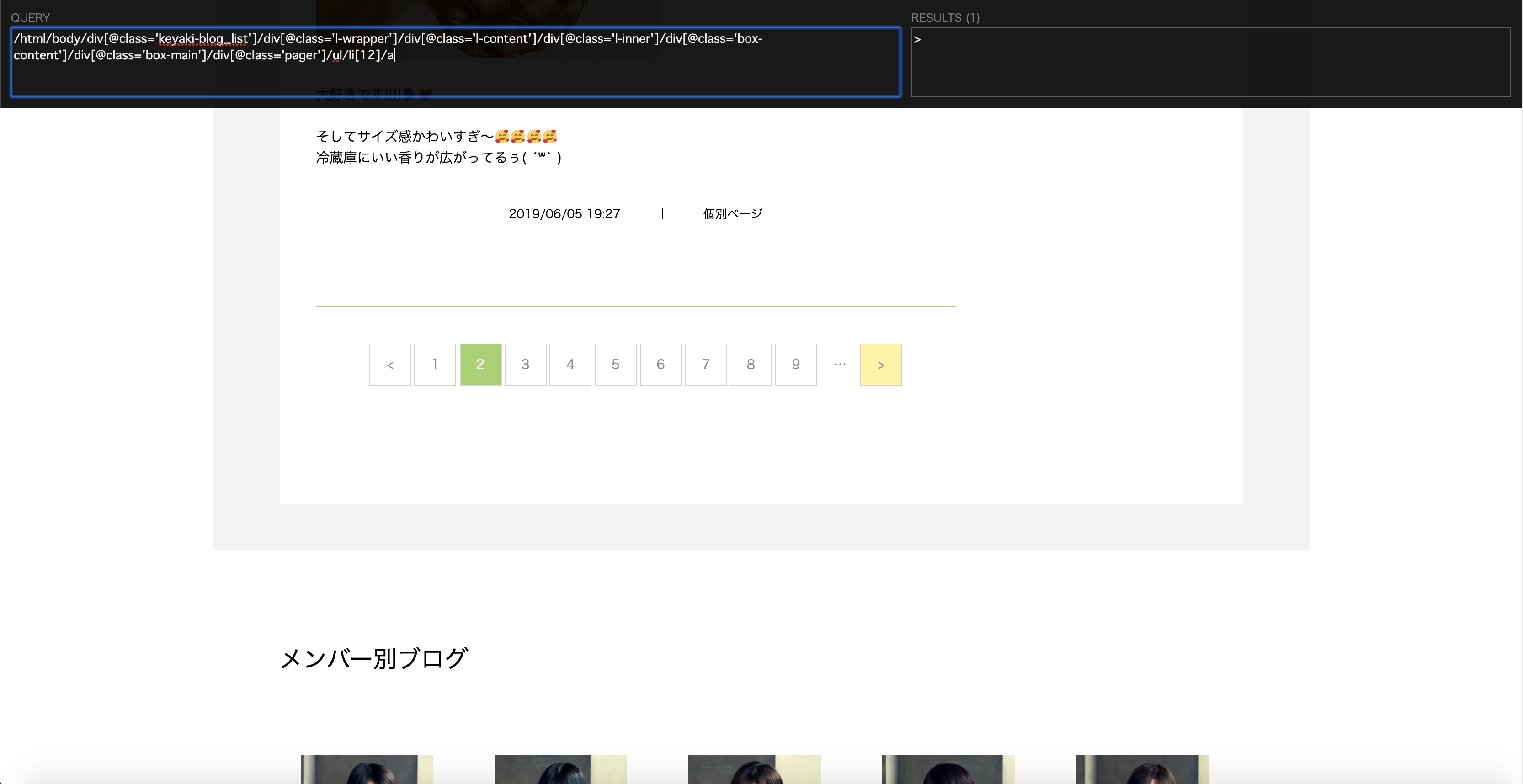
/html/body/div[@class='keyaki-blog_list']/div[@class='l-wrapper']/div[@class='l-content']/div[@class='l-inner']/div[@class='box-content']/div[@class='box-main']/div[@class='pager']/ul/li[12]/a
ポイントは1ページ目の場合、li[11]となりますが、2ページ目以降の場合、li[12]となることです。
共通点はli要素の最後の要素であることです。XPATHではli[last()]で指定できます。
//div[@class='pager']/ul/li[last()]/a
Seleniumと融合させよう
メンバー毎のブログ更新回数をカウントする
Pythonの辞書オブジェクト{Key: Value}を利用して、Keyに一致する名前があった時に
Valueを更新するようにしましょう。
# 欅坂46のメンバーとブログの更新回数のカウンター
members = {
'石森 虹花': 0, '上村 莉菜': 0, '尾関 梨香': 0, '織田 奈那': 0, \
'小池 美波': 0, '小林 由依': 0, '齋藤 冬優花': 0, '佐藤 詩織': 0, \
'菅井 友香': 0, '鈴本 美愉': 0, '長沢 菜々香': 0, '長濱 ねる': 0, \
'土生 瑞穂': 0, '原田 葵': 0, '平手 友梨奈': 0, '守屋 茜': 0, \
'渡辺 梨加': 0, '渡邉 理佐': 0, '井上 梨名': 0, '関 有美子': 0, \
'武元 唯衣': 0, '田村 保乃': 0, '藤吉 夏鈴': 0, '松田 里奈': 0, \
'松平 璃子': 0, '森田 ひかる': 0, '山﨑 天': 0
}
# ブログを書いたメンバーの名前を抽出しています。driver.find_elementではないことに注意してください。
names = driver.find_elements_by_xpath("//div[@class='box-ttl']/p[@class='name']")
# 2重のforループで回して、欅坂46のメンバー名==ブログを書いたメンバーの名前の時、欅坂46のカウンターを更新しています。
for name in names:
for member in members:
if member == name.text:
members[member] += 1
ページ遷移を実装しよう
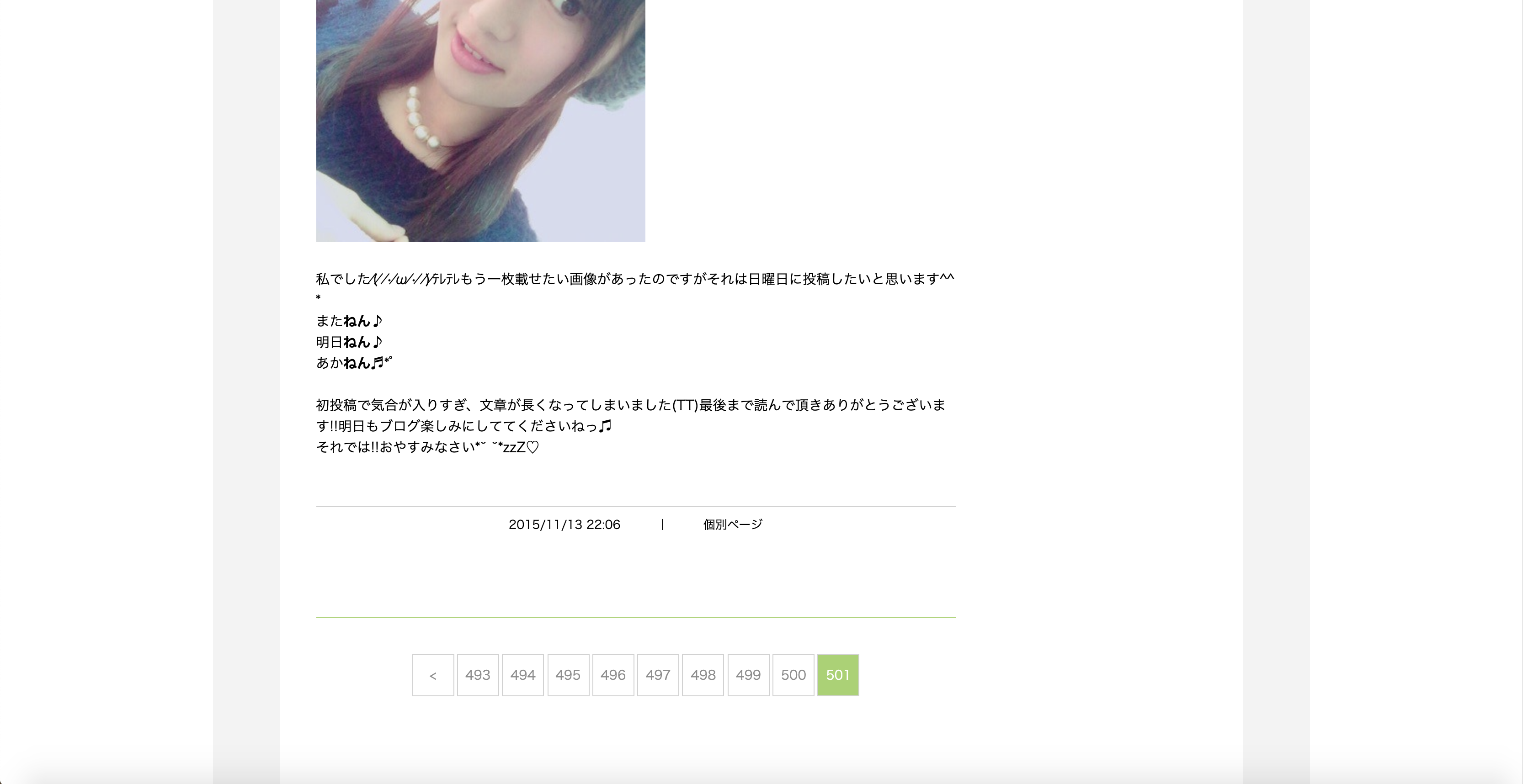
ページネーションの要素(>ボタン)がある限り、クリックし続ければ良いだけです。
以下画像より、最後のページにはページネーションの要素(>ボタン)がないことが分かっているので、
ボタンが見つからなかった時に例外を発生させるようにします。
from selenium.common.exceptions import NoSuchElementException
while True:
try:
# ページネーションを一つでも取得できるまで最大10秒待機
wait.until(expected_conditions.presence_of_element_located((By.XPATH, "//div[@class='pager']/ul/li/a")))
# >ボタンを探す
link = driver.find_element_by_xpath("//div[@class='pager']/ul/li[last()]/a")
link.click()
except (KeyboardInterrupt, NoSuchElementException):
# Ctrl + Cを押した時,>ボタンがない時に欅坂46のメンバーとブログの更新回数のカウンターを表示する
print(members)
break
# ウィンドウを閉じる
driver.quit()
完成
お疲れ様でした。日向坂46に続いて欅坂46の個人ブログの更新回数を取得できるようになりましたね。
興味を持った方はスクレイピングの対象を変えたりして、自分で一からコードを書いてみてください。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.common.by import By
from selenium.common.exceptions import NoSuchElementException, TimeoutException
# 欅坂46のメンバーとブログの更新回数のカウンター
members = {
'石森 虹花': 0, '上村 莉菜': 0, '尾関 梨香': 0, '織田 奈那': 0, \
'小池 美波': 0, '小林 由依': 0, '齋藤 冬優花': 0, '佐藤 詩織': 0, \
'菅井 友香': 0, '鈴本 美愉': 0, '長沢 菜々香': 0, '長濱 ねる': 0, \
'土生 瑞穂': 0, '原田 葵': 0, '平手 友梨奈': 0, '守屋 茜': 0, \
'渡辺 梨加': 0, '渡邉 理佐': 0, '井上 梨名': 0, '関 有美子': 0, \
'武元 唯衣': 0, '田村 保乃': 0, '藤吉 夏鈴': 0, '松田 里奈': 0, \
'松平 璃子': 0, '森田 ひかる': 0, '山﨑 天': 0
}
options = Options()
# options.binary_location = '/Applications/Google Chrome Canary.app/Contents/MacOS/Google Chrome Canary'
# headlessモードで起動する
# options.add_argument('--headless')
driver = webdriver.Chrome(options=options)
# 最初に開くページ(クロールの起点となるページ, 欅坂46の公式sブログを想定)
baseUrl = 'http://www.keyakizaka46.com/s/k46o/diary/member/list?ima=0000'
# 欅坂ブログのトップページを開く
driver.get(baseUrl)
# タイトルに欅坂46 公式ブログが含まれていることを確認する
assert '欅坂46 公式ブログ' in driver.title
# 最大10秒待機
wait = WebDriverWait(driver, 10)
while True:
try:
# ブログを書いたメンバーの名前を取得できるまで待つ
wait.until(expected_conditions.presence_of_element_located((By.XPATH, "//div[@class='box-ttl']/p[@class='name']")))
# XPATHの場合
names = driver.find_elements_by_xpath("//div[@class='box-ttl']/p[@class='name']")
# CSSセレクタの場合
# names = driver.find_elements_by_css_selector('div.box-ttl p.name')
for name in names:
for member in members:
if member == name.text:
members[member] += 1
# ページネーション要素(>ボタン)を取得できるまで待つ
wait.until(expected_conditions.presence_of_element_located((By.XPATH, "//div[@class='pager']/ul/li/a")))
link = driver.find_element_by_xpath("//div[@class='pager']/ul/li[last()]/a")
link.click()
except (KeyboardInterrupt, NoSuchElementException, TimeoutException):
print(members)
# ウィンドウを閉じる
driver.quit()
break
余談
while True:
try:
# ブログを書いたメンバーの名前を取得できるまで待つ
wait.until(expected_conditions.presence_of_element_located((By.XPATH, "//div[@class='box-ttl']/p[@class='name']")))
names = driver.find_elements_by_xpath("//div[@class='box-ttl']/p[@class='name']")
for name in names:
for member in members:
if member == name.text:
members[member] += 1
# ページネーション要素(>ボタン)を取得できるまで待つ
wait.until(expected_conditions.presence_of_element_located((By.XPATH, "//div[@class='pager']/ul/li/a")))
link = driver.find_element_by_xpath("//div[@class='pager']/ul/li[last()]/a")
link.click()
except (KeyboardInterrupt, NoSuchElementException, TimeoutException):
print(members)
break
# ウィンドウを閉じる
driver.quit()
とすべきところを誤ってbreakのインデントをtry句、except句と同じ位置に置いてしまったため、
「>ボタン」をクリックした後に何も表示されないまま、スクリプトが終了する現象が発生しました。
些細な違いですが、breakのインデントには気をつけましょう。
while True:
try:
# ブログを書いたメンバーの名前を取得できるまで待つ
wait.until(expected_conditions.presence_of_element_located((By.XPATH, "//div[@class='box-ttl']/p[@class='name']")))
names = driver.find_elements_by_xpath("//div[@class='box-ttl']/p[@class='name']")
for name in names:
for member in members:
if member == name.text:
members[member] += 1
# ページネーション要素(>ボタン)を取得できるまで待つ
wait.until(expected_conditions.presence_of_element_located((By.XPATH, "//div[@class='pager']/ul/li/a")))
link = driver.find_element_by_xpath("//div[@class='pager']/ul/li[last()]/a")
link.click()
except (KeyboardInterrupt, NoSuchElementException, TimeoutException):
print(members)
break
# ウィンドウを閉じる
driver.quit()