はじめに
皆さんは日向坂46というアイドルグループを知っていますか?
乃木坂46,欅坂46に次ぐ第3の坂道シリーズで、
2019年3月27日にシングルデビューを果たした、
今ノリに乗っている女性アイドルグループです。
今回は私の趣味であるアイドルとプログラミングを組み合わせて、何か作ることはできないかと考え、
思いついたのが日向坂46 公式ブログをクローリング&スクレイピングして、
2016年8月2日から現在までのメンバー毎の更新回数を収集することでした。
注意
Webスクレイピングを行う際には、岡崎市立中央図書館事件などを参考に、1秒あたりのアクセス回数に注意したり、robots.txtを遵守するなど道徳的かつ節度のある行動を心掛けましょう。
できること
このチュートリアルを終えると、以下のようなことができるようになります。
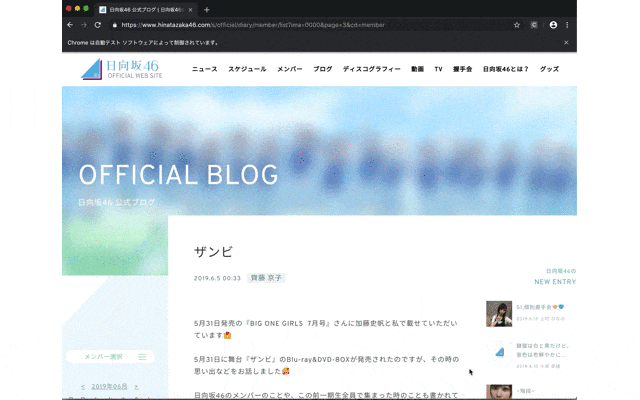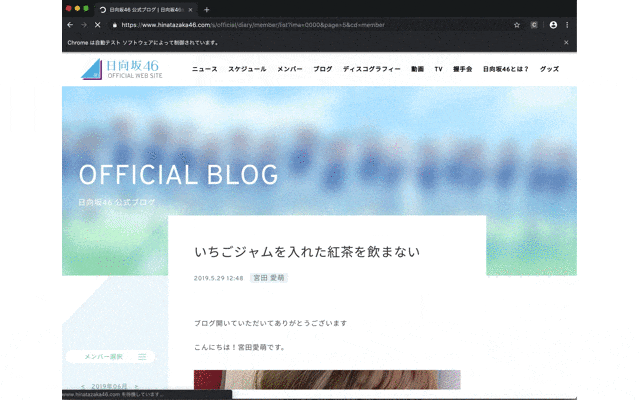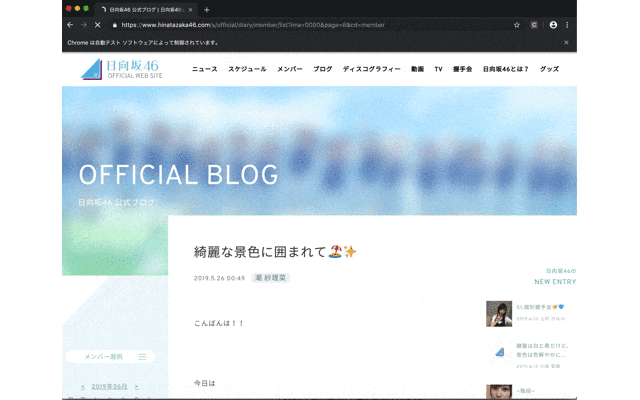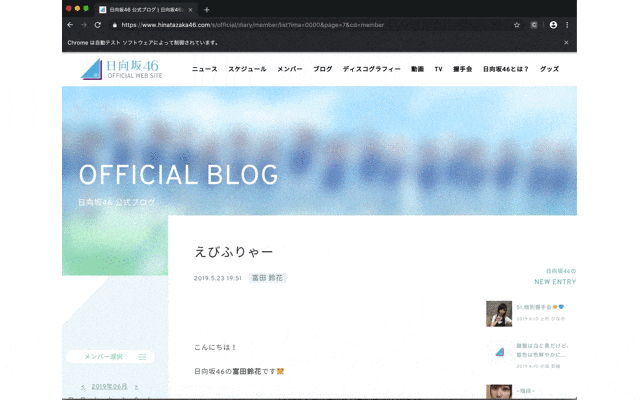
「Chromeは自動テスト ソフトウェアによって制御されています」と記載されている通り、
100%自動でブラウジングしています。普通はクリックしないとページ遷移できないところも
プログラムで動かしてるんですよ。普通に考えるとすごくないですか。
Python hinatazaka.py > hinatazaka.json
上記コマンドの実行例が以下のようになります。
今回は一番簡易な例として、JSONファイルに出力していますが、
NoSQLなどに保存することも可能です。
{'井口 眞緒': 694, '潮 紗理菜': 443, '柿崎 芽実': 262, '影山 優佳': 594, '加藤 史帆': 756, \
'齊藤 京子': 1143, '佐々木 久美': 399, '佐々木 美玲': 587, '高瀬 愛奈': 656, '高本 彩花': 620, \
'東村 芽依': 491, '金村 美玖': 171, '河田 陽菜': 118, '小坂 菜緒': 118, '富田 鈴花': 190, \
'丹生 明里': 201, '濱岸 ひより': 133, '松田 好花': 230, '宮田 愛萌': 206, '渡邉 美穂': 143, \
'上村 ひなの': 51}
結果として、以下のようなツイートができるようになります。
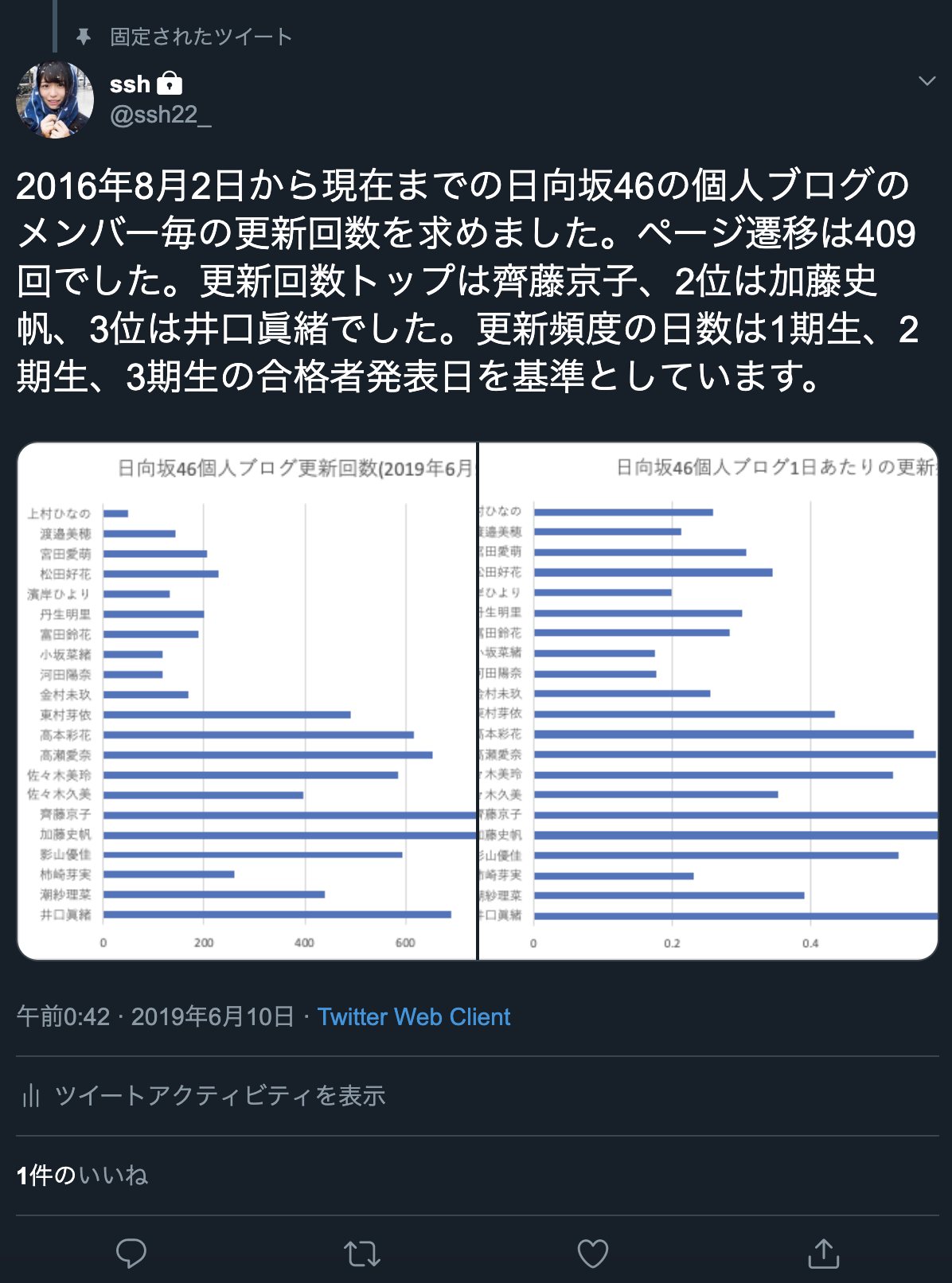
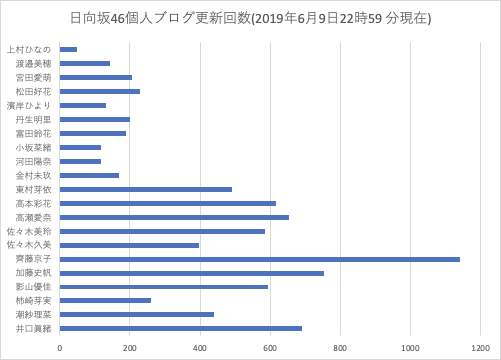
日向坂46の歴史を築いてきた1期生の奮闘ぶりが凄いですね。
1000回もやめずにブログ更新し続けられますか?
私は無理です。
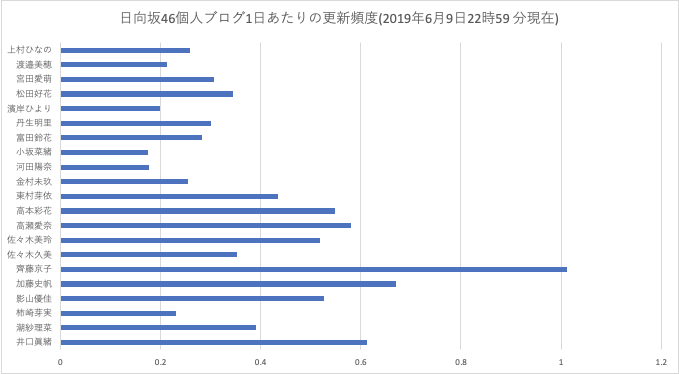
齊藤京子さんの1日あたりのブログ更新回数が1回超えてるのは凄くないですか。
簡略化のために、合格発表日を基準にしてるので、実際にブログを書けた日は
もっと短いはずなのにこの数字です。
利用方法
以下レファレンスを開きながら、Seleniumのオプションを確認し、
自分でコードを書きながら記事を読むと理解が深まります。
対象読者
- Python, JavaScriptの基礎的なコードの読み書きができる人
- 坂道シリーズのファン(乃木坂46、欅坂46、日向坂46)
- クローリング&スクレイピングしたい人(初心者想定)
前提条件
- macOS Mojave バージョン10.14.5(Windows, Linuxは対象外とします)
- Python 3.6以上(Python3.x系なら動作すると思います。導入方法はお任せしますが、パスが通っていれば問題ないです)
- pipのインストール(Seleniumをインストールするために必要です)
-
Chrome Canary
(Chromeでも実行できるようですが、万が一起動しなくなったら困るので、クローリング用に別途インストールすることをお薦めします)
Seleniumのインストール
Seleniumとはブラウザを任意のプログラムで自動操作するために用いられるツール群のことです。
Pythonの他にもC#, Java, Perl, PHP, Rubyなどで利用することができます。
Seleniumはクローラーを開発するために必ずしも必要な訳ではありませんが、
SPAなどJavaScriptを多用しているサイトをクローリングする際には利用が必須となります。
早速、Seleniumをインストールしましょう。
pip install selenium
Chrome Canaryのダウンロード
以下サイトにアクセスして、ダウンロードしてください。
https://www.google.com/intl/ja/chrome/canary/
実装手順
具体的な実装手順を記載しています。
- JavaScriptで必要なHTMLの要素を抽出しよう
- Seleniumと融合させよう
- 完成
JavaScriptで必要なHTMLの要素を抽出しよう
ブログを書いたメンバーの名前を取得する
日向坂46 公式ブログから今回取得したい「メンバーの名前を識別できる情報」がJavaScriptでどのように抽出できるか考慮します。Command + Option + Iで開発者コンソールを開き、マウスのボタンをクリックして要素のHTMLを検証します。

以下画像のように、class名で抽出できることが分かります。

document.getElementsByClassName('c-blog-article__name')
// HTMLCollection(20)
// div.c-blog-article__name, div.c-blog-article__name, div.c-blog-article__name, div.c-blog-article__name, div.c-blog-article__name, div.c-blog-article__name, div.c-blog-article__name, div.c-blog-article__name, div.c-blog-article__name, div.c-blog-article__name, div.c-blog-article__name, div.c-blog-article__name, div.c-blog-article__name, div.c-blog-article__name, div.c-blog-article__name, div.c-blog-article__name, div.c-blog-article__name, div.c-blog-article__name, div.c-blog-article__name, div.c-blog-article__name
document.getElementsByClassName('c-blog-article__name')[0].innerText
// "上村 ひなの"
ページネーションの「>」ボタンを取得する
Seleniumを利用したクローリング&スクレイピングの醍醐味です。
今回クローリングする日向坂46 公式ブログには、以下画像のように、執筆時点で411ページあることが分かります。
1ページ目から411ページまでページ遷移をする必要があります。
以下画像のように、>ボタンをクリックし続ければページ遷移できることが分かります。

document.getElementsByClassName('c-pager__item--count c-pager__item--next')
// HTMLCollection [li.c-pager__item--count.c-pager__item--next]
document.getElementsByClassName('c-pager__item--count c-pager__item--next')[0]
// <li class="c-pager__item--count c-pager__item--next"> <svg space="preserve" style="enable-background:new 0 0 300 300;" version="1.1" viewBox="0 0 300 300" x="0px" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" y="0px"><polygon points="82,300 68.1,286.1 204.2,150 68.1,13.9 82,0 231.9,150 "></polygon></svg></li>
Seleniumと融合させよう
メンバー毎のブログ更新回数をカウントする
Pythonの辞書オブジェクト{Key: Value}を利用して、Keyに一致する名前があった時に
Valueを更新するようにしましょう。
# 日向坂46のメンバーとブログの更新回数のカウンター
members = {
'井口 眞緒': 0, '潮 紗理菜': 0, '柿崎 芽実': 0, '影山 優佳': 0, \
'加藤 史帆': 0, '齊藤 京子': 0, '佐々木 久美': 0, '佐々木 美玲': 0, \
'高瀬 愛奈': 0, '高本 彩花': 0, '東村 芽依':0, '金村 美玖': 0, \
'河田 陽菜': 0, '小坂 菜緒': 0, '富田 鈴花': 0, '丹生 明里': 0, \
'濱岸 ひより': 0, '松田 好花': 0, '宮田 愛萌': 0, '渡邉 美穂': 0, \
'上村 ひなの' : 0
}
# ブログを書いたメンバーの名前を抽出しています。driver.find_elementではないことに注意してください。
names = driver.find_elements_by_class_name('c-blog-article__name')
# 2重のforループで回して、日向坂46のメンバー名==ブログを書いたメンバーの名前の時、
# 日向坂46のカウンターを更新しています。
for name in names:
for member in members:
if member == name.text:
members[member] += 1
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.common.by import By
# 日向坂46のメンバーとブログの更新回数のカウンター
members = {
'井口 眞緒': 0, '潮 紗理菜': 0, '柿崎 芽実': 0, '影山 優佳': 0, \
'加藤 史帆': 0, '齊藤 京子': 0, '佐々木 久美': 0, '佐々木 美玲': 0, \
'高瀬 愛奈': 0, '高本 彩花': 0, '東村 芽依':0, '金村 美玖': 0, \
'河田 陽菜': 0, '小坂 菜緒': 0, '富田 鈴花': 0, '丹生 明里': 0, \
'濱岸 ひより': 0, '松田 好花': 0, '宮田 愛萌': 0, '渡邉 美穂': 0, \
'上村 ひなの' : 0
}
options = Options()
options.binary_location = '/Applications/Google Chrome Canary.app/Contents/MacOS/Google Chrome Canary'
driver = webdriver.Chrome(options=options)
# 最初に開くページ(クロールの起点となるページ, 日向坂46の個人ブログを想定)
baseUrl = 'https://www.hinatazaka46.com/s/official/diary/member/list?ima=0000'
# 日向坂ブログのトップページを開く
driver.get(baseUrl)
# タイトルに日向坂46 公式ブログが含まれていることを確認する
assert '日向坂46 公式ブログ' in driver.title
# 最大10秒待機
wait = WebDriverWait(driver, 10)
# ブログの著作者を一つでも取得できるまで最大10秒待機
wait.until(expected_conditions.presence_of_element_located((By.CLASS_NAME, 'c-blog-article__name')))
names = driver.find_elements_by_class_name('c-blog-article__name')
for name in names:
for member in members:
if member == name.text:
members[member] += 1
print(members)
# ウィンドウを閉じる
driver.quit()
ページ遷移を実装しよう
ページネーションの要素(>ボタン)がある限り、クリックし続ければ良いだけです。
以下画像より、最後のページにはページネーションの要素(>ボタン)がないことが分かっているので、
ボタンが見つからなかった時に例外を発生させるようにします。
from selenium.common.exceptions import NoSuchElementException
while True:
try:
# ページネーションを一つでも取得できるまで最大10秒待機
wait.until(expected_conditions.presence_of_element_located((By.CLASS_NAME, 'c-pager__item--count')))
# >ボタンを探す
link = driver.find_element_by_css_selector('.c-pager__item--count.c-pager__item--next')
link.click()
except (KeyboardInterrupt, NoSuchElementException):
# Ctrl + Cを押した時,>ボタンがない時に日向坂46のメンバーとブログの更新回数のカウンターを表示する
print(members)
break
# ウィンドウを閉じる
driver.quit()
完成
お疲れ様でした。これで一通りの実装が完了しました。
興味を持った方はスクレイピングの対象を変えたりして、自分で一からコードを書いてみてください。
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.common.by import By
from selenium.common.exceptions import NoSuchElementException
# 日向坂46のメンバーとブログの更新回数のカウンター
members = {
'井口 眞緒': 0, '潮 紗理菜': 0, '柿崎 芽実': 0, '影山 優佳': 0, \
'加藤 史帆': 0, '齊藤 京子': 0, '佐々木 久美': 0, '佐々木 美玲': 0, \
'高瀬 愛奈': 0, '高本 彩花': 0, '東村 芽依':0, '金村 美玖': 0, \
'河田 陽菜': 0, '小坂 菜緒': 0, '富田 鈴花': 0, '丹生 明里': 0, \
'濱岸 ひより': 0, '松田 好花': 0, '宮田 愛萌': 0, '渡邉 美穂': 0, \
'上村 ひなの' : 0
}
options = Options()
options.binary_location = '/Applications/Google Chrome Canary.app/Contents/MacOS/Google Chrome Canary'
driver = webdriver.Chrome(options=options)
# 最初に開くページ(クロールの起点となるページ, 日向坂46の個人ブログを想定)
baseUrl = 'https://www.hinatazaka46.com/s/official/diary/member/list?ima=0000'
# 日向坂ブログのトップページを開く
driver.get(baseUrl)
# タイトルに日向坂46 公式ブログが含まれていることを確認する
assert '日向坂46 公式ブログ' in driver.title
# 最大10秒待機
wait = WebDriverWait(driver, 10)
while True:
try:
# ブログの著作者を一つでも取得できるまで最大10秒待機
wait.until(expected_conditions.presence_of_element_located((By.CLASS_NAME, 'c-blog-article__name')))
names = driver.find_elements_by_class_name('c-blog-article__name')
for name in names:
for member in members:
if member == name.text:
members[member] += 1
# ページネーションを一つでも取得できるまで最大10秒待機
wait.until(expected_conditions.presence_of_element_located((By.CLASS_NAME, 'c-pager__item--count')))
# >ボタンを探す
link = driver.find_element_by_css_selector('.c-pager__item--count.c-pager__item--next')
link.click()
except (KeyboardInterrupt, NoSuchElementException):
# Ctrl + Cを押した時, >ボタンがない時に日向坂46のメンバーとブログの更新回数のカウンターを表示する
print(members)
break
# ウィンドウを閉じる
driver.quit()