RDBでツリー構造を扱う方法には、隣接リストや閉包テーブル(Closure Table)などいくつかの手法がありますが、このうち閉包テーブルからツリーのパス文字列をSQLだけで得たいことがあったので、記録ついでに紹介したいと思います。
※隣接リストやその他の構造でパス文字列を得る方法は、機会があれば別途書いてみたいと思います。
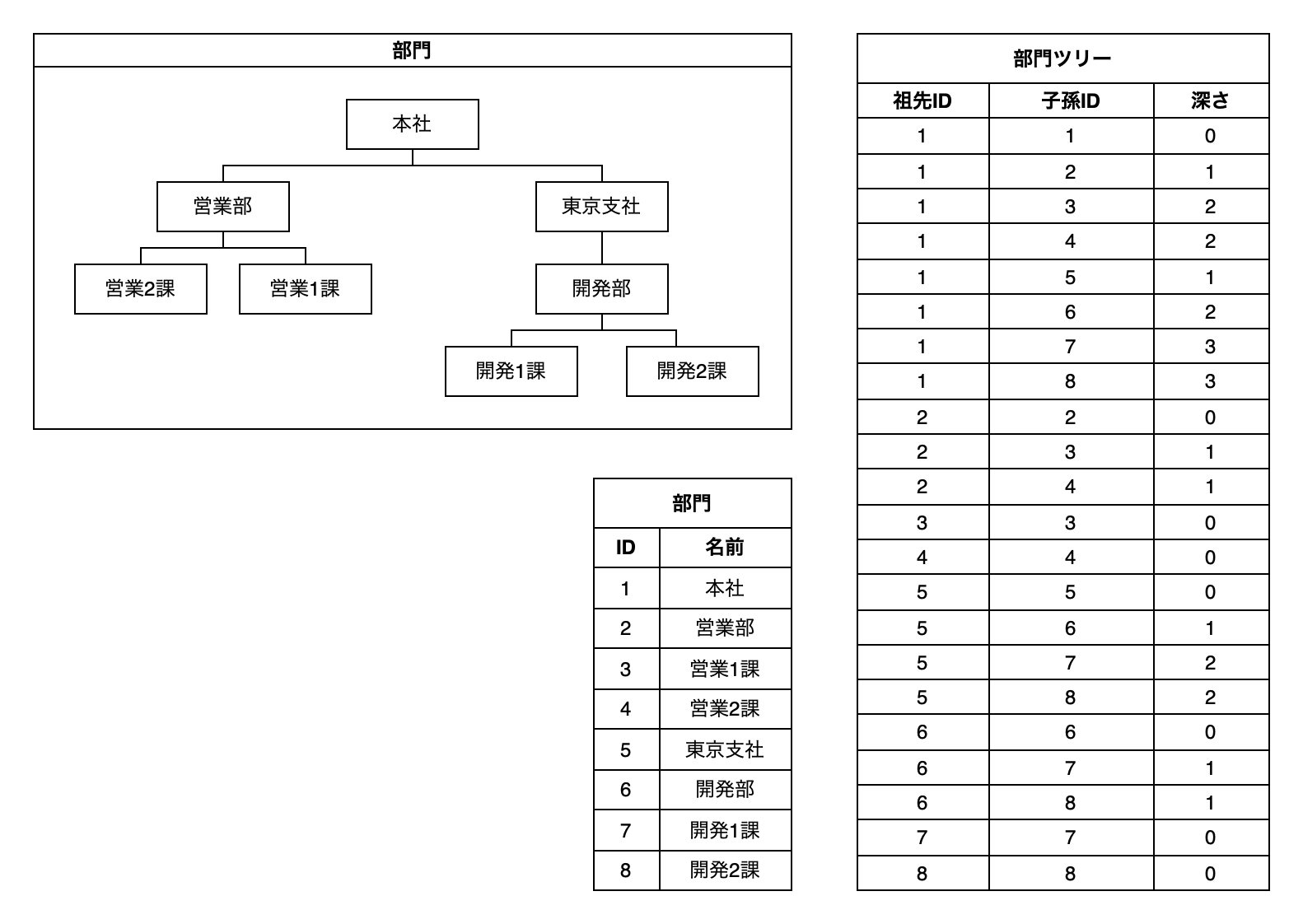
閉包テーブルとは
閉包テーブルとは、RDBでツリー構造を扱う手法のひとつです。
下図のように、ツリーの要素とツリー構造を別々のテーブルで持つのですが、ツリー情報の方は親子関係だけでなく、祖先と子孫の関係を余すところなく持った構成になっています(深さは持たせない場合もあります)。
このツリー情報を読み取ることで、直近の親子関係だけでなく、祖先や子孫を一気に把握することができます。
閉包テーブルのメリットやデメリットについて説明し始めると長くなってしまい本題から逸れてしまうので、ここでは割愛させていただきます。
ここではこういうデータ構造なんだなー、というぐらいに思っておいてください。
RDBでツリー構造を扱う際によく出てくる手法のひとつなので、詳しく知りたい方は検索してみたり、次のページをご参照ください。
なにがしたかったか
集約関数で集計したデータに、閉包テーブルで持ったツリー構造のパス文字列をくっつけて取得したいことがありました。
具体的にはこのような部門ごとの集計データみたいなのをSQL一発で取りたかったのです。
| id | path | count |
|---|---|---|
| 1 | 本社 | 10 |
| 2 | 本社/営業部 | 3 |
| 3 | 本社/営業部/営業1課 | 18 |
| 4 | 本社/営業部/営業2課 | 22 |
idに対する名前は普通にJOINすれば取れるので、次のような形であればなんの苦労もなく取れると思います。
| id | path | count |
|---|---|---|
| 1 | 本社 | 10 |
| 2 | 営業部 | 3 |
| 3 | 営業1課 | 18 |
| 4 | 営業2課 | 22 |
しかし、これでは階層がわかりにくいですし、例えば営業部と開発部の下にそれぞれ同じ名前の1課がある場合などに、どこの下にぶら下がっている1課なのかわからなくなってしまいます。
というわけで、なんとかして上記の本社/営業部/営業1課のような文字列を、SQLだけで取得してみたいと思います。
目標は閉包テーブルから次のような結果を得ることです。
このような結果が得られれば、あとはJOINするなりして使えますよね。
| id | path |
|---|---|
| 1 | 本社 |
| 2 | 本社/営業部 |
| 3 | 本社/営業部/営業1課 |
| 4 | 本社/営業部/営業2課 |
前準備
今回はこんなツリーがあるとします。よくある部門のツリーです。
本社
├─営業部
│ ├─営業1課
│ └─営業2課
└─東京支社
└─開発部
├─開発1課
└─開発2課
まずは準備として、上記のツリー情報を扱うための次のようなテーブルとデータを用意します。
部門テーブル(departments):
| id | name |
|---|---|
| 1 | 本社 |
| 2 | 営業部 |
| 3 | 営業1課 |
| 4 | 営業2課 |
| 5 | 東京支社 |
| 6 | 開発部 |
| 7 | 開発1課 |
| 8 | 開発2課 |
-- 部門テーブル
create table departments (
id integer primary key,
name varchar(100) not null
);
-- 部門データの追加
insert into departments (id, name) values
(1, '本社'),
(2, '営業部'),
(3, '営業1課'),
(4, '営業2課'),
(5, '東京支社'),
(6, '開発部'),
(7, '開発1課'),
(8, '開発2課');
部門ツリーテーブル(department_tree_paths):
| ancestor_id | descendant_id | depth |
|---|---|---|
| 1 | 1 | 0 |
| 1 | 2 | 1 |
| 1 | 3 | 2 |
| 1 | 4 | 2 |
| 1 | 5 | 1 |
| 1 | 6 | 2 |
| 1 | 7 | 3 |
| 1 | 8 | 3 |
| 2 | 2 | 0 |
| 2 | 3 | 1 |
| 2 | 4 | 1 |
| 3 | 3 | 0 |
| 4 | 4 | 0 |
| 5 | 5 | 0 |
| 5 | 6 | 1 |
| 5 | 7 | 2 |
| 5 | 8 | 2 |
| 6 | 6 | 0 |
| 6 | 7 | 1 |
| 6 | 8 | 1 |
| 7 | 7 | 0 |
| 8 | 8 | 0 |
-- 部門ツリーテーブル
create table department_tree_paths (
ancestor_id integer not null references departments(id),
descendant_id integer not null references departments(id),
depth integer not null,
primary key (ancestor_id, descendant_id)
);
-- 部門ツリーの登録
insert into department_tree_paths (ancestor_id, descendant_id, depth) values
(1, 1, 0), (1, 2, 1), (1, 3, 2), (1, 4, 2),
(1, 5, 1), (1, 6, 2), (1, 7, 3), (1, 8, 3),
(2, 2, 0), (2, 3, 1), (2, 4, 1), (3, 3, 0),
(4, 4, 0), (5, 5, 0), (5, 6, 1), (5, 7, 2),
(5, 8, 2), (6, 6, 0), (6, 7, 1), (6, 8, 1),
(7, 7, 0), (8, 8, 0);
パスの取得(よくある解説)
さて、上記のテーブルから部門のパスを取る場合、次のようなSQLを発行して得られたレコードを繋げば取れるよ、という解説をよく見かけます。
-- 営業1課(id=3)のパスを得たい場合
select
p.ancestor_id,
p.descendant_id,
p.depth,
d.name
from
department_tree_paths as p
inner join
departments as d
on (d.id = p.ancestor_id)
where
descendant_id = 3
order by
depth desc
| ancestor_id | descendant_id | depth | name |
|---|---|---|---|
| 1 | 3 | 2 | 本社 |
| 2 | 3 | 1 | 営業部 |
| 3 | 3 | 0 | 営業1課 |
確かにこれを上から繋いでいけば期待する文字列本社/営業部/営業1課は組み立てることができます。
ですがそれをやるのはDBの外側(アプリケーションのプログラム側)になります。
例えばこんなイメージですね。
// 上記の3レコードを取る
const rows = db.query("上記のSQL");
// nameの配列を作って、"/"でjoinする
const names = rows.map((it) => it.name);
const path = names.join("/");
そうではなくて、DB上で次のような結果を得て、それをJOINして使いたいわけです。
| id | path |
|---|---|
| 1 | 本社 |
| 2 | 本社/営業部 |
| 3 | 本社/営業部/営業1課 |
| 4 | 本社/営業部/営業2課 |
パスの取得(PostgreSQLの場合)
PostgreSQLでこのような結果を得たい場合、string_aggという集約関数を使うことで実現できます。
string_aggは集約した集合のカラム値を指定の区切り文字で結合した結果を得られる関数です。
先程得られた3レコードのnameをこの関数で繋げてあげればよさそうですね。
具体的には、先程のクエリ(下記のサブクエリの部分)に対してdescendant_idで集約し、string_aggでnameを/区切りで繋いでやると、期待した結果が得られます。
select
descendant_id as id,
string_agg(name, '/' order by depth desc) as path -- depthの降順で繋ぐ
from (
select
p.ancestor_id,
p.descendant_id,
p.depth,
d.name
from
department_tree_paths as p
inner join
departments as d
on (d.id = p.ancestor_id)
) as t
group by
descendant_id
order by
id
| id | path |
|---|---|
| 1 | 本社 |
| 2 | 本社/営業部 |
| 3 | 本社/営業部/営業1課 |
| 4 | 本社/営業部/営業2課 |
| 5 | 本社/東京支社 |
| 6 | 本社/東京支社/開発部 |
| 7 | 本社/東京支社/開発部/開発1課 |
| 8 | 本社/東京支社/開発部/開発2課 |
目標としていた結果が得られました。
あとは集計した結果にこれをJOINするなりして好きなように使えそうですね。
余談ですが、PostgreSQLには似たような関数でarray_aggという配列化する関数もあるので、これを使うと配列操作で他にもいろいろなことができて楽しそうです。
ちなみに、今回の例をarray_aggで組み立てると次のような感じになります。
- string_agg(name, '/' order by depth desc)
+ array_to_string(array_agg(name order by depth desc), '/')
パスの取得(MySQLの場合)
MySQLの場合はGROUP_CONCATという集約関数を使うと同じことができます。
引数の書き方は若干異なりますが、機能はPostgreSQLのstring_aggとほぼ同じです。
select
descendant_id as id,
group_concat(name order by depth desc separator '/') as path
from (
select
p.ancestor_id,
p.descendant_id,
p.depth,
d.name
from
department_tree_paths as p
inner join
departments as d
on (d.id = p.ancestor_id)
) as t
group by
descendant_id
order by
id
※結果は同じなので割愛
おわりに
SQLで様々な集計レポートを作成することはよくあると思いますが、今回このような閉包テーブルに出くわして、「これはスクリプトとか書いて対応するしかないのかなー。嫌だなー。SQLだけで完結させたいなー」という思いから、なんとかパスを得る方法を調べてみました。
実は各RDBMSの関数にはCOUNTやSUMといった定番のもの以外にも、今回使ったような面白い関数がたくさんあります(集約関数以外の関数も色々あります)。
一度、公式マニュアルの関数ページをご覧になってみてはいかがでしょうか。
ちなみに、今回は取り上げませんでしたが、SQL Serverにはstring_agg、OracleにはLISTAGGという、同様のことができそうな関数があるようです。