この章では、Power Queryのクエリ言語である「M言語」の高度な機能を活用して、複雑なデータ変換やカスタムロジックを実装する方法を学びます。M言語を使うことで、Power QueryのGUIでは対応が難しい複雑なデータ処理や、動的な変換ロジックをクエリに組み込むことが可能になります。特に、再帰関数やレコード操作、リスト操作などを活用することで、Power Queryの柔軟性と効率が格段に向上します。
8.1. M言語の基本構文と構造
M言語を効果的に活用するためには、その基本的な構文やデータ構造について理解することが重要です。
8.1.1. M言語の基本構文
M言語は、1つの式だけでクエリが出来上がっている場合は、その式を記述します。
1 + 1
複数の式が記述される場合は、let で始まり、in の後に戻り値を記述します。式の左に書かれる変数は、一意にならなければなりません。
let
Step1 = 1,
Step2 = Step1 + 1
in
Step2 + 1
M言語は「ステップ」と呼ばれる一連のデータ変換操作で構成され、各ステップは任意の名前を付けて定義できます。コードの可読性を高めるために、ステップ名を適切に付けることが推奨されます。
8.1.2 部分的な遅延評価 (Partial Laziness)
M言語は、全体的には即時評価を行いますが、let から in の間に記述された式は遅延評価(Lazy Evaluation)され、定義された名前が参照されるまで計算が実行されません(部分的遅延評価)。実行順序は、結果として返される値に必要な順番で行われ、結果として返される値に関連しない式は、評価自体がスキップされます。
let
x = z,
y = 2,
z = 1
in
x
上記では、最初の x に代入される z の値は後ろの行で定義されていますが、処理は z = 1が先に行われます。そして、y = 2 は、評価されずに終わります。
8.1.3 イミュータビリティ (Immutability)
M 言語では、変数の値を変更することはできません。これにより、一貫性のある結果が得られます。この性質をイミュータビリティ (Immutability)と呼びます。
-
不変性の性質
- 一度作成されたデータやオブジェクトの状態を変更することができません。
-
変化は生成で表現
- 状態を変更する代わりに、新しいデータやオブジェクトを生成します。
- 例えば、リストに新しい要素を追加する場合、元のリストを変更せず、新しいリストを生成します。
-
参照透過性を保証
- イミュータブルなデータは、操作の結果が予測可能で副作用を持ちません。
以下のコードでは、A の計算結果が保存され、何度も再評価されることはありません。
イミュータブルなデータは一度作られると内容が変わらないため、プログラムの動きを予測しやすく、エラーが起きた場合も原因を簡単に見つけられます。また、複数の処理が同時に進んでもデータが変わらないので安全に使えます。さらに、データの変更ミスを防ぐことでバグを減らすことができ、変更履歴を追跡しやすく、過去の状態に戻すのも簡単です。
8.1.4. スコープの理解
M言語のスコープは、クエリ内で変数や関数がどの範囲で使用できるかを決定し、データ変換やデータ操作を行う上で重要な役割を果たします。
各ステップ内で定義した変数は、利用できるスコープ(範囲)を持ちます。このスコープは、データ変換やデータ操作の流れを制御する上で重要な役割を果たします。
クエリ内のトップレベルで定義されるすべての変数がグローバルスコープに含まれます。一方、ローカルスコープは、特定の let 式や関数内で定義され、定義されたスコープ外ではアクセスできません。
let
GlobalValue = 10, // グローバルスコープ
// ローカルスコープを持つ関数
LocalFunction = (x as number) =>
let
LocalValue = x * 2, // ローカルスコープ
Result = LocalValue + GlobalValue // ローカルとグローバルを組み合わせる
in
Result
in
LocalFunction(5)
また、関数のパラメータは、関数のスコープ内でローカル変数と見なされます。これらは関数内でアクセス可能ですが、外部からはアクセスできません。
異なるスコープで同じ名前を持つ変数や関数が存在する場合、M言語ではレキシカルスコーピング(lexical scoping、あるいはスタティックスコーピング)というプロセスを通じてスコープの競合を回避します。レキシカルスコーピングは、同じ名前の変数や関数がローカルとグローバルの両方に存在する場合、特定のコンテキスト内ではローカルのものが優先されます。
letを使用してスコープを制御している例を挙げます。
let
x = 10,
y =
let
x = 1,
z = x,
in
z
in
y
このクエリの結果は 1 になります。z = x で使われる x は、入れ子になった let 式の中で定義された x = 1 の値になります。もし、x = 1 の行がなかったら、上位の x = 10 の値が参照されることになります。
let
x = a,
y = 20,
z =
let
a = 30
in
a
in
x
このコードは以下のようにエラーになってしまいます。

a は、x のスコープ内にないためです。
スコープを理解することは、功利的で保守性の高いコードを書くために必要不可欠です。スコープを適切に管理することで、変数や関数が適切なコンテキストで使用され、計算やデータ操作が正確に実行されることが保証されます。
8.1.5. クロージャの理解
Power Queryにおけるクロージャ (Closure)とは、M言語で記述される関数が外部のスコープから変数や値を取り込み、それを保持して動作する仕組みのことを指します。この概念は、多くの関数型言語で一般的に見られる機能であり、Power Queryでも柔軟で強力なデータ処理を可能にします。
クロージャは、関数が定義された環境での変数を「キャプチャ」し、それを関数内で利用できるようにします。クロージャを用いると、関数外で定義された変数を、関数内で参照して保持することが可能になります。
クロージャでは、関数が定義されたときに外部スコープの変数がキャプチャされ、その変数の値が関数内で使用されます。キャプチャされた変数は、関数が実行されるときまで保持されます。
let
multiplier = 2,
multiplyFunction = (x) => x * multiplier, // クロージャ: 外部スコープの'multiplier'をキャプチャ
result = multiplyFunction(5) // 実行時に'multiplier'が2として利用される
in
result
上記のコードでは、multiplyFunction関数が外部スコープにあるmultiplierをキャプチャしています。multiplyFunction(5)を呼び出すと、キャプチャされたmultiplierの値が関数内で使われ、結果は10になります。
let
createAdder = (n) => (x) => x + n, // 外部スコープの'n'をキャプチャする関数
addFive = createAdder(5), // 'n'を5としてキャプチャした関数を作成
result = addFive(10) // キャプチャされた5と10を加算
in
result
この例では、createAdder関数は引数nをキャプチャし、それを保持する新しい関数を生成します。addFiveはn = 5をキャプチャしており、addFive(10)を呼び出すと結果は15になります。
クロージャは、特定の値や状態を保持した関数を作成することができ、必要に応じて柔軟な動作を持つ関数を作成できます。
しかし、クロージャが多くの外部変数をキャプチャすると、予期しない挙動やパフォーマンス低下が起こる可能性があります。また、クロージャを多用すると、コードが複雑になるため、適切なコメントや設計が必要です。
8.2 グローバル環境
M言語において、グローバル環境は、Power Query全体を包含する最上位のスコープです。グローバル環境には、以下の3つのコンポーネントが含まれています。
- 標準ライブラリ
- 組み込み関数
- 組み込み型
- 組み込み列挙体
- 共有拡張関数
sharedキーワードを使用して定義される - 現在のクエリ
現在のセクション内で定義されたクエリ
#shared キーワードを使用してグローバル環境を見ることができます。
#shared

このクエリで返されるのは、Name と Value の列を持つテーブルです。スクロールすると、Power Queryエディター内で作成された既存のクエリや、全ての標準M関数、型、および列挙体、さらにはPower BI Desktopにバンドルされているサードパーティコネクタの関数を見つけることができます。
8.3 型とデータ型
8.3.1 型システム
M言語には数値型、テキスト型、ブール型、日付型、リスト型、レコード型、テーブル型などの基本データ型があり、それぞれのデータ型に応じた処理が可能です。
M言語の型システムは、値を分類するのに役立ちます。カスタム関数を作成する際、データ型は必要な値や返す値を指定します。
let
Source =
Table.FromRows(
{
{"abc"},
{123},
{true},
{#date(2025,1,1)}
},
type table [Mixed Data = any]
)
in
Source

type any のような型がついている場合でも、列の値は同じ型であるとは限りません。
M言語は、弱い動的型付けのクエリ言語です。変数やデータを使用する前に型の宣言をする必要がありません。しかし、データ型を明示的に指定しないことはデータ処理においてリスクがあります。列が type any としてラベル付けされている場合、そこには異なる値を含んでいる可能性があり、操作によってエラーが発生する可能性があります。
列内の値の性質を明確にし、一貫性を確保するために、データ型を明示することは大切です。データ型を設定することで、データが特定の型に準拠していることを確認でき。エラーハンドリング技術を使いデータ検証とエラーの防止において重要な役割を果たします。
また、データ型を定義すると、Power Queryはデータの保存および取得方法を最適化してくれるので、クエリの実行速度が向上します。
更に、他のシステムと統合する場合やデータをエクスポートする場合、データ型が重要になります。データ型を使用することで、他のシステムとの互換性を確保することができます。
8.3.2 プリミティブ型
プリミティブ型は、全ての他のデータ型が作成される基本的なデータ型です。また、レコード、テーブル、関数などの複雑なデータ型の構成要素としても利用されます。
M言語には、18のプリミティブ型があります。そのうち6つは抽象型です。
| プリミティブ型 | 値 | 例 |
|---|---|---|
| binary | バイナリ | |
| date | 日付 | #date(2025,1,1) |
| datetime | 日付/時刻 | #datetime(2010, 12, 31, 11, 56, 02) |
| datetimezone | 日付/時刻/タイムゾーン | #datetimezone(2020, 10, 30, 01, 30, 00, -8, 00) |
| duration | 期間 | #duration(0,0,7,0) |
| list | リスト型 | {1,2,3} |
| logical | 論理型 | true, false |
| null | ヌル | null |
| number | 数値 | 1, -3.14, 2.0e5, 0xff |
| record | レコード型 | [ID=1, Name="Chris"] |
| text | テキスト | "abcd" |
| time | 時刻 | #time(14,53,0) |
| type | 型 | |
| function | 関数型 | |
| table | テーブル型 | |
| any | 任意 | |
| anynonnull | ヌルを除く任意 | |
| none | 未定義 |
8.3.3 型を設定する
型の変換はM言語で重要な操作であり、特定のデータ型に変換するために Table.TransformColumnTypes が使われます。また、Number.From、Text.From、Date.Fromなどの関数を使用して型を変更することができます。
let
Source =
Table.FromRows(
{
{1,"abc"},
{2,123},
{3,true},
{4,#date(2025,1,1)}
},
type table [ID = any, Mixed Data = any]
),
// 列の型を変換
#"Changed Type" =
Table.TransformColumnTypes(
Source,
{
{"ID", type number}, // 数値型に
{"Mixed Data", type text} // テキスト型に
}
)
in
#"Changed Type"
8.4 条件文
if ... then ... else 条件分岐を使用して、条件に応じた異なる処理を行うことができます。条件式には、and、or、notなどの論理演算子や、=、<>、>などの比較演算子を使って、複雑な条件を設定できます。
ただし、条件分岐の使用はコストが高くなります。他のロジックを使用することも検討してみてください。
8.5 リストとレコードの操作
M言語でのリストとレコードの操作は、複雑なデータ構造の処理において非常に有用です。ここでは、リストとレコードを活用したデータ変換方法を学びます。
8.5.1 リストの作成と操作
リストは、M言語で複数の要素を1つの変数に格納できるデータ構造です。{}を使用してリストを定義し、List.First、List.Last、List.Sum、List.Countなどの関数を用いて操作します。
List.Transformを使ってリスト内の各要素に対して処理を行ったり、List.Selectを使って条件に一致する要素を抽出することができます。
let
Source = {1,2,3,4,5},
Select =
List.Select(Source, each _ > 2),
AddOne =
List.Transform(
Select,
each _ + 1
)
in
AddOne

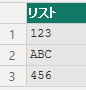
[] を使って、テーブルの特定の列をリスト形式で取り出すことができます。
let
Source = Table.FromRows(
{
{"1", "123"},
{"2", "ABC"},
{"3", "456"}
},
{"ID", "Value"}
),
Result = Source[Value]
in
Result
8.5.2 レコードの操作
レコードは、フィールド(列名)とその値をペアで持つデータ構造です。[フィールド名 = 値]の形式で定義します。
[ID = 1, Name = "Chris", Age = 30]

テーブルから特定のレコードを取り出すには、列 No の値が Second の列を取り出すには以下のようにします。
let
Source = Table.FromRows(
{
{"First", "123"},
{"Second", "ABC"},
{"Third", "456"}
},
{"No", "Value"}
),
GetSecondRecord = Source{[No="Second"]}
in
GetSecondRecord
単純に、2番目のレコードを取り出すには、Source{1} と指定することもできます。
先の列の指定と合わせて、 Source{1}[Value] とすることで、ABC の値を取り出すことができます。