20.1 ピボット、ピボット解除とは
20.1.1 ピボットとは何か
ピボットとは、ある列の値を新しい列の見出し(ヘッダー)として展開し、それに関連するデータを再編成する操作のことです。たとえば、売上データを製品別の列に展開して、各月ごとの売上を表示するように変換できます。
ピボットの基本例
次のようなデータを例にします:
| 月 | 製品 | 売上 |
|---|---|---|
| 1月 | A | 100 |
| 1月 | B | 150 |
| 2月 | A | 200 |
| 2月 | B | 250 |
このデータを「製品」列を基にピボットすると、以下のようになります:
| 月 | A | B |
|---|---|---|
| 1月 | 100 | 150 |
| 2月 | 200 | 250 |
操作手順:
- 列の選択: 「製品」列を選択します。
- ピボット列の適用: 「変換」タブから「列のピボット」を選択します。
- 値列の選択: ピボットしたいデータ(この例では「売上」)を指定します。

let
Source = Table.FromRows(
{
{"1月", "A", 100},
{"1月", "B", 150},
{"2月", "A", 200},
{"2月", "B", 250}
}, type table [月 = text, 製品 = text, 売上 = Int64.Type]
),
PivotedColumn =
Table.Pivot(
Source,
List.Distinct(Source[製品]), // pivotValues as list
"製品", // attributeColumn as text
"売上", // valueColumn as text
List.Sum // aggregationFunction as nullable function(optional)
)
in
PivotedColumn

注意点
- 最初に、見出しとして展開したい列を選択します。
- 値が重複する場合(たとえば、同じ月・製品のデータが複数行ある場合)、集計関数(合計、平均など)を指定する必要があります。
- ピボット結果にNULL値が含まれる場合、後で補完やクリーニングが必要になることがあります。
20.1.2 ピボット解除とは何か
ピボット解除とは、複数の列を1つの列にまとめ、これに関連する値を対応付ける操作のことです。これは「アンピボット」とも呼ばれます。たとえば、複数の列に分かれた売上データを1つの列にまとめて、扱いやすくすることができます。
ピボット解除の基本例
次のようなデータを例にします:
| 月 | A | B |
|---|---|---|
| 1月 | 100 | 150 |
| 2月 | 200 | 250 |
操作手順:
- 列の選択: ピボット解除したい列を選択(この例では「A」と「B」)。
- 列のピボット解除の適用: 「変換」タブから「列のピボット解除」を選択します。

let
Source = Table.FromRows(
{
{"1月", 100, 150},
{"2月", 100, 150},
{"1月", 200, 250},
{"2月", 200, 250}
}, type table [月 = text, A = Int64.Type, B = Int64.Type]
),
UnpivotedColumns =
Table.UnpivotOtherColumns(
Source,
{"月"}, // pivotColumns as list
"属性", // attributeColumn as text
"値" // valueColumn as text
)
in
UnpivotedColumns

注意点
- 「列のピボット解除」を選択しても
Table.UnpivotOtherColumns関数が使われます。 - ピボット解除後、新しい列に適切な名前(この例では「製品」と「売上」)を付ける必要があります。
20.1.3 2x2レベルのピボット解除
このようなデータをピボット解除します。
| 地域 | 月 | A | B |
|---|---|---|---|
| 東京 | 1月 | 100 | 150 |
| 東京 | 1月 | 100 | 150 |
| 神奈川 | 2月 | 200 | 250 |
| 神奈川 | 2月 | 200 | 250 |
操作手順:
- 列の選択: ピボット解除したい列を選択(この例では「A」と「B」)。
- 列のピボット解除の適用: 「変換」タブから「列のピボット解除」を選択します。
let
Source = Table.FromRows(
{
{"東京", "1月", 100, 150},
{"東京", "2月", 100, 150},
{"神奈川", "1月", 200, 250},
{"神奈川", "2月", 200, 250}
}, type table [地域 = text, 月 = text, A = Int64.Type, B = Int64.Type]
),
UnpivotedColumns =
Table.UnpivotOtherColumns(
Source,
{"地域", "月"}, // pivotColumns as list
"属性", // attributeColumn as text
"値" // valueColumn as text
)
in
UnpivotedColumns
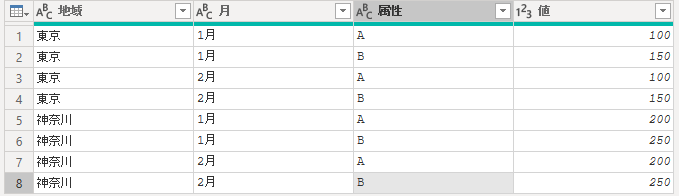
注意点
- 「列のピボット解除」を選択しても
Table.UnpivotOtherColumns関数が使われます。 - ピボット解除後、新しい列に適切な名前(この例では「製品」と「売上」)を付ける必要があります。
- ピボット解除前の列名がデータとして扱われるので、内容をわかりやすく整理するのが重要です。
20.2 設計が悪いテーブル
20.2.1 設計が悪いテーブルを判断する
テーブルが適切に設計されていれば、ExcelのピボットテーブルやPower BIのビジュアルで効果的に使用できます。下図のような設計が悪いテーブルは、必要な分析計算の実装を過度に複雑にします。



ピボットされたテーブルは、好ましくありませんし、列の中に異なる属性の値が紛れているのも問題です。理想的なテーブルは、先ほどのピボット解除されたテーブルのように、属性の列、値の列と、同種の値が列に並んでいるテーブルです。
このように構造化されたテーブルは「ファクト・テーブル」と呼ばれます。「ファクト・テーブル」は「ルックアップ・テーブル」あるいは「ディメンション・テーブル」と一緒に使用されます。
20.3 ピボット解除の詳細
20.3.1 Table.UnpivotOtherColumns
ピボット解除(アンピボット、英: Unpivot)は、列形式のデータを行形式のデータに変換する操作です。特定の列を「属性(attributeColumn)」として扱い、その列の値を「値(valueColumn)」として扱うことで、データを縦方向に展開します。この操作は、複数の列を持つデータを一つの軸でまとめて扱いたい場合や、列形式のデータを動的に処理する必要がある場合に有効です。
下の図では、属性は「アクセサリ」「自転車」「衣類」「部品」で、値は数値で表されている部分です。「店舗A」「店舗B」「店舗C」の列はアンカーカラムで、ピボット解除されない列です。
| 店舗名 | アクセサリ | 自転車 | 衣類 | 部品 |
|---|---|---|---|---|
| 店舗A | 1200 | 70000 | 2000 | 9000 |
| 店舗B | 800 | 50000 | 1500 | 6000 |
| 店舗C | 500 | 30000 | 1000 | 4000 |
ピボット解除は、アンカーカラムとピボット解除された二つの列(AttributeとValue)に変換されます。
UIの操作では、「列のピボット解除」と「その他の列のピボット解除」のいずれも数式レベルで Table.UnpivotOtherColumns として実行されます。メニューが分かれているのは、単にユーザーがどちらの操作がやりやすいかだけです。ピボット解除する列がアンカーカラムより多い場合は、アンカーカラムを選択して「その他の列のピボット解除」を選択します。

また、将来的に、アンカーカラムよりピボットされた列が増える可能性の方が高いと想定されます。Table.UnpivotOtherColumnsを使用することで、新しい項目が追加されても修正なしで使用できます。
Table.UnpivotOtherColumnsの構文は以下の様になっています。
Table.UnpivotOtherColumns(
table as table,
pivotColumns as list,
attributeColumn as text,
valueColumn as text
) as table
この構文で pivotColumns で指定されるのは、実際はアンカーカラムです。
ピボットされた列が増えた場合

C列が追加されても、同じクエリで下の様にピボット解除が行われます。

アンカーカラムが増えた場合

アンカーカラムが追加されると、同じクエリを実行させると以下の様になってしまいます。
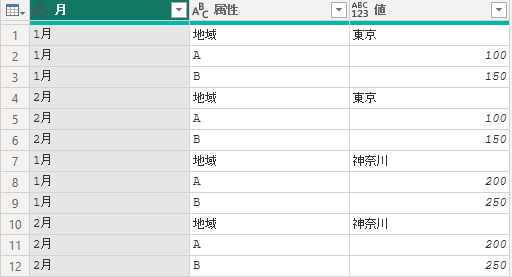
20.3.2 Table.PivotColumns
UIの操作から Table.Unpivot を使うには、「選択した列のみをピボット解除」を選択します。

let
Source = Table.FromRows(
{
{"東京", "1月", 100, 150},
{"東京", "2月", 100, 150},
{"神奈川", "1月", 200, 250},
{"神奈川", "2月", 200, 250}
}, type table [地域 = text, 月 = text, A = Int64.Type, B = Int64.Type]
),
UnpivotedOnlySelectedColumns =
Table.Unpivot(
Source,
{"A", "B"}, // pivotColumns as list
"属性", // attributeColumn as text
"値" // valueColumn as text
)
in
UnpivotedOnlySelectedColumns
Table.Unpivot の構文は以下の様になっています。
Table.Unpivot(
table as table,
pivotColumns as list,
attributeColumn as text,
valueColumn as text
) as table
こちらの pivotColumns で指定するのは、その名前の通りピボットされている列です。
20.3.3 ピボット解除の重要なポイント
-
保持列と解除対象列の区別
ピボット解除を行う際、どの列を保持するかを明確に指定する必要があります。保持列はデータの基準となる識別子として残り、他の列が解除されます。 -
属性列の生成
ピボット解除で新たに生成される属性列には、元の列名が格納されます。この列は、データの意味を明確にするキーとなります。 -
値列のまとめ方
ピボット解除によって生成された値列には、元の各列の値が格納されます。この列は、データの実際の内容を持つ重要な部分です。 -
動的列の処理
ピボット解除は、動的に増減する列の処理に向いています。たとえば、月次データが毎月追加される場合でも、Table.UnpivotOtherColumnsを使えば、同じクエリで全ての月のデータを行形式にまとめられます。
| 地域 | 製品 | 1月 | 2月 | 3月 | 4月 | ・・・ |
|---|---|---|---|---|---|---|
| 北部 | A | 100 | 200 | 300 | 400 | ・・・ |
| 南部 | B | 150 | 250 | 350 | 450 | ・・・ |
20.3.4 ピボット解除の利点と制約
ピボット解除には、以下のような利点があります。
-
データの正規化
ピボット解除によって、複数の列に分散しているデータを一つの軸で統一することで、データの正規化を実現できます。 -
柔軟な分析が可能
縦持ちの形式にすることで、データを動的にフィルタリングしたり、集計したりする操作が容易になります。 -
スケーラビリティ
動的列に対応できるため、新しい列が追加されても柔軟に処理できます。
一方で、以下の制約があることも留意してください。
ピボット解除の制約
- 元のデータの列名に特殊文字や空白が含まれている場合、意図した結果を得られないことがあります。
- 大規模データセットでピボット解除を行うと、データの行数が急増し、パフォーマンスが低下する可能性があります。
ピボット解除は、データ整形や柔軟な分析に欠かせない操作であり、その仕組みを正確に理解することで、効率的なデータ処理が可能になります。
20.4 最適化
データ量が大きい場合、ピボットとピボット解除操作の効率を上げるために次の点に注意してください:
-
事前にフィルタリングを行う
必要なデータのみを対象にピボットやピボット解除を実行することで、不要な計算を減らします。 -
適切な列の選択
過剰に多くの列やデータを対象にすると、操作が遅くなる可能性があります。 -
集計関数の指定
ピボットの際に、適切な集計関数を指定することで効率が上がります。
大規模なデータセットでは、ピボットやピボット解除の前にグルーピングを行うことで、パフォーマンスを向上させることができます。
例: 年間売上の地域別集計
次のようなデータを例にします:
| 年 | 地域 | 製品 | 月 | 売上 |
|---|---|---|---|---|
| 2023 | 北部 | A | 1月 | 100 |
| 2023 | 北部 | A | 2月 | 120 |
| 2023 | 北部 | B | 1月 | 150 |
| 2023 | 北部 | B | 2月 | 160 |
| 2023 | 南部 | A | 1月 | 200 |
結果:
| 年 | 地域 | A | B |
|---|---|---|---|
| 2023 | 北部 | 220 | 310 |
| 2023 | 南部 | 200 | null |
let
Source = Table.FromRows(
{
{"2023", "北部", "A", "1月", 100},
{"2023", "北部", "A", "2月", 120},
{"2023", "北部", "B", "1月", 150},
{"2023", "北部", "B", "2月", 160},
{"2023", "南部", "A", "1月", 200}
}, type table [年 = text, 地域 = text, 製品 = text, 月 = text, 売上 = Int64.Type]
),
GroupedRows =
Table.Group(
Source,
{"年", "地域", "製品"},
{
{"売上", each List.Sum([売上]), type number}
}
),
PivotedColumn =
Table.Pivot(
GroupedRows,
List.Distinct(GroupedRows[製品]),
"製品",
"売上",
List.Sum
)
in
PivotedColumn
グループ化によって、以下の様にピボットするデータを減らすことができました。

20.5 複雑なテーブルのピボット解除
エクセルでよく見かける以下のような表をピボット解除で整形してみます。

手順
- 年の列をフィルダウンする
- 年と月をテキスト型に変換した後、空白を挟んで「列のマージ」を行う

- 「1行目をヘッダーとして使用」で、「山根商事グループ」をヘッダーに充てる
- 「山根商事グループ」の列をピボット解除する

- 「1行目をヘッダーとして使用」で、ヘッダーを作成

- 「赤坂店」「新橋店」「品川店」を選択して、ピボット解除
- 「年月」列を日付け型に、「値」列を整数に変換
let
Source = Table.FromRows(
{
{null,null,"山根商事グループ",null,null},
{"年","月","品川店","赤坂店","新橋店"},
{2024,9,890,640,520},
{null,10,750,700,460},
{null,11,920,620,480},
{null,12,1010,830,580}
}
),
年をフィルダウン = Table.FillDown(Source,{"Column1"}),
年と月をテキスト型に =
Table.TransformColumnTypes(
年をフィルダウン,
{ {"Column1", type text}, {"Column2", type text} }
),
年と月をまとめる =
Table.CombineColumns(
年と月をテキスト型に,
{ "Column1", "Column2" },
Combiner.CombineTextByDelimiter(" ", QuoteStyle.None),
"結合済み"
),
山根商事をヘッダーに上げる =
Table.PromoteHeaders( 年と月をまとめる, [PromoteAllScalars=true] ),
山根商事を展開 =
Table.UnpivotOtherColumns(
山根商事をヘッダーに上げる,
{" ", "Column3", "Column4"},
"属性",
"値"
),
#"1行目をヘッダーにする" =
Table.PromoteHeaders( 山根商事を展開, [PromoteAllScalars=true]),
ピボット解除 =
Table.UnpivotOtherColumns(
#"1行目をヘッダーにする",
{"年 月", "山根商事グループ"},
"属性",
"値"),
型変換 =
Table.TransformColumnTypes(
ピボット解除,
{{"年 月", type date}, {"値", Int64.Type}})
in
型変換
