データ処理や分析の現場では、クエリのパフォーマンスやエラーの発生状況を把握し、効率的な処理を実現することが求められます。本章では、Power Queryにおけるクエリ診断の基本から、高度な診断技術、トラブルシューティングの手法までを具体例を交えて詳しく解説します。
24.1 クエリ診断の概要
クエリ診断とは、Power Queryで実行される操作のパフォーマンスやデータの流れを詳細に記録・分析する機能です。
この機能を使用すると、生成しているクエリの種類、作成の更新の間に発生する可能性のある速度低下、発生しているバックグラウンド イベントの種類を把握できます。
- パフォーマンスの最適化: クエリのどの部分で時間がかかっているかを特定し、改善することで、処理時間を短縮します。
- エラーの原因究明: クエリ内のどのステップで問題が発生しているかを明確にし、迅速な修正が可能です。
- データフローの可視化: クエリの処理順序や依存関係を理解しやすくします。
24.2 クエリ診断の機能と利点
24.2.1 クエリ診断ツール
Power Queryには、以下の診断ツールが用意されています。
-
診断トレースの有効化:
- クエリの実行中に、各ステップの処理時間やアクセスされるデータ量を記録します。
- 「ツール」タブ内の「診断を開始」と「診断を停止」を使って操作します。
-
診断データの解析:
- クエリ実行後に記録された情報を元に、実行ステップごとのパフォーマンスデータを確認します。
- 診断データは、ExcelやCSV形式でエクスポートして外部ツールで分析することも可能です。
24.2.2 クエリ診断の利点
- 迅速な問題解決: エラー発生箇所を特定し、修正を効率的に進められます。
- パフォーマンス向上: 実行時間が長い操作を特定し、最適化できます。
- 継続的な改善: 診断データを活用して、継続的なクエリ設計の改善が可能です。
24.3 クエリ診断の実践
24.3.1 オプションの設定

オプションの「診断」の項目にクエリ診断に関する設定があります。
クエリ診断は、レポートとクエリエディターの両方で有効にするか、クエリエディタのみで有効にするかを選択できます。マシンの管理者でない場合、クエリエディタのみでクエリ診断を有効にします。
診断の種類は3つあります。そのうち2つはオプションであり、「診断レベル」の項目で作成するかどうかを選択できます。
- 集約(Aggregated):クエリで時間がかかっている場所をすぐに把握できるよう、複数の関連する操作が1つにまとめられています。
- 詳細(Detailed):1行ずつの詳細な未集約の診断データを得ることができます。

その他の診断の「パフォーマンスカウンター(Performance counters)」は、各クエリのパフォーマンスデータをキャプチャします。CPU、メモリ、およびIOデータが500msごとにスナップショットされます。パフォーマンスカウンターは、クエリの相対的なリソース消費を最適化するために役立ちます。
「データプライバシーパーティション(Data privacy partitions)」は、データプライバシーのためにステップを分離する論理パーティションを示します。この診断は、異なるプライバシー設定を持つデータソースを扱う際に役立ちます。
※「第23章 コラボレーションとファイアウォールエラー」参照
24.3.2 診断の使用方法
-
診断の準備
- クエリがまだ保存されていない場合は、「ホーム」タブから「適用」を選択します。

- 診断オプションの設定(厳密な診断を行いたい場合)
- Power Queryエディターの「ツール」タブを開き、「診断オプション」を選択します。

- 「データの読み込み」セクションの「バックグランドデータ」で、「バックグラウンドでのデータプレビューのダウンロードを許可しない」にします。(※診断が終わったら元に戻しておきましょう)
- 「データの読み込み」セクションで「キャッシュをクリア」をクリックします。

- プライバシーレベルを判断する処理にかかるオーバーヘッドをなくします。(※診断が終わったら元に戻しておきましょう)

- オプションの設定については、Power BI Desktopの今後のバージョンで変更される可能性があります。
- Power Queryエディターの「ツール」タブを開き、「診断オプション」を選択します。
- クエリがまだ保存されていない場合は、「ホーム」タブから「適用」を選択します。
-
診断を開始する:
- Power Queryエディターの「ツール」タブを開き、「診断の開始」をクリックします。

- Power Queryエディターの「ツール」タブを開き、「診断の開始」をクリックします。
-
クエリを実行する:
- Power Queryエディタを開いたまま、Power BI Desktop のレポートビューで、データ・フィールドのテーブル名を右クリックし、データの更新を選択します。

- Power Queryエディタを開いたまま、Power BI Desktop のレポートビューで、データ・フィールドのテーブル名を右クリックし、データの更新を選択します。
-
診断を停止する:
- 実行が終了したらPower Queryエディタに戻り、「診断の停止」をクリックします。
- 記録された診断データが新しいクエリとして生成されます。
作成された診断データには以下の種類があります。
- 集約された主要診断(Aggregated)
- 詳細な主要診断(Detailed)
- データプライバシーパーティション(Partitions)
- パーフォーマンスカウンター(Counters): メモリの消費量など
Aggregated と Detailed の診断データ
| 項目 | 内容 |
|---|---|
| Id | セッションの識別子 |
| Query | 評価されたクエリの名前 |
| Step | 適用されたステップの名前 |
| Category | 操作カテゴリ |
| Data Source Kind | アクセスしているデータソース |
| Operation | 実行されている操作 |
| Stat Time | 操作の開始時間 |
| End Time | 操作の終了時間 |
| Exclusive Duration(%) | イベントがアクティブであった時間の割合 |
| Exclusive Duration | 排他的持続時間 |
| Resource | アクセスしているリソースの名前 |
| Data Source Query | 生成されたデータ ソース クエリ |
| Additional Info | コネクタによって取得された各種の情報 |
| Row Count | データソースクエリによって返された行数 |
| Is User Query | クエリがユーザーによって作成された銅貨を示す真偽値 |
| Path | 操作の相対的なルート |
| Group Id | 評価中にステップがグループ化された識別子 |
| Partition Key |
Partitions の診断データ
| 項目 | 内容 |
|---|---|
| Id | セッションの識別子 |
| Partition Key | ファイアウォール パーティションとして使用されるクエリとステップ |
| Firewall Group | パーティションのプライバシー レベルの分類 |
| Accessed Resources | データ ソース |
| Partition Inputs | 現在のパーティションが依存するパーティション キーの一覧 |
| Expression | パーティションのクエリとステップで評価された式 |
| Start Time | 評価が開始した時刻 |
| End Time | 評価が終了した時刻 |
| Duration | 終了時間ー開始時間 |
| Exclusive Duration | 排他的継続時間 |
| Exclusive DDuration(%) | 排他的継続時間の割合 |
| Diagnostics | 診断 |
24.3.2 診断結果を見る
選択したテーブルの更新に関連するクエリが合わせて診断結果に表示されます
- 集約された主要診断(Aggregated)詳細な主要診断(Detailed)
- 主に見るのは、
IdQueryStepStart TimeExclusive Duration(%)Exclusive DurationRow CountPathなどです。 -
Start Timeの最小値とEnd Timeの最大値が全体の処理時間になります。 - SQLやODataなど外部のデータベースへの接続や、Webコンテンツを取得している場合は
Data Source Queryでクエリが見えます。

-
Diagnostics.Trace関数を使ってトレースしている場合は、Additional Infoも見ます。
- 主に見るのは、
- パーフォーマンスカウンター(Counters)
- メモリの利用状況を追いかけます。
24.3.3 ステップ診断でクエリフォールディングを確認する
以下のようなクエリを作成します。
let
// ODataフィードからデータを取得
Source =
OData.Feed(
"services.odata.org/V3/OData/Odata.svc",
null,
[Implementation="2.0"]
),
// Categoriesを選択
Categories_table =
Source{[Name="Categories",Signature="table"]}[Data],
// Products列を展開
ExpandedProducts =
Table.ExpandTableColumn(
Categories_table,
"Products",
{"Name"},
{"Products.Name"}
),
// リネーム
RenamedColumns =
Table.RenameColumns(
ExpandedProducts,
{
{"Name", "Categories"},
{"Products.Name", "Product"}
}
)
in
RenamedColumns
このクエリを「参照」して FilterProductThenCategory クエリを作成し、フィルターを施したクエリを作成します。

let
Source = Categories,
// Productをフィルター
FilteredProduct =
Table.SelectRows(
Source,
each [Product] <> "Milk"
),
// Categoriesをフィルター
FilteredCategory =
Table.SelectRows(
FilteredProduct,
each [Categories] <> "Electronics"
)
in
FilteredCategory
クエリ「FilterProductThenCategory」の最後のステップ FilteredCategory を選択し、ツールタブで「ステップを診断する」を選択します。

または、「適用したステップ」で FilteredCategoryを右クリックし、「診断」を選択しても同様の結果が得られます。

作成された診断結果の中から、Aggregated を選択します。

Data Source Query 列のnullを除外した最後の値には、このデータソースに対するクエリが表示されます。
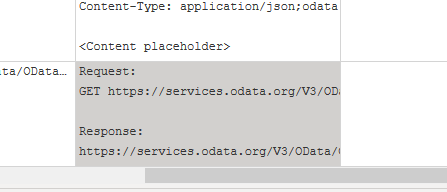
このクエリでは、ProductとCategoryのフィルタリングがフォールドされていないことが分かります。
Request:
GET https://services.odata.org/V3/OData/OData.svc/Categories?$expand=Products HTTP/1.1
Response:
https://services.odata.org/V3/OData/OData.svc/Categories?$expand=Products
HTTP/1.1 200 OK
それでは、先ほどのクエリを「複製」し、名前を FilterCategoryThenProduct に変更します。そして、最後のステップの FilteredCategory の順番を FilteredProduct の上にします。
let
Source = Categories,
// Categoriesをフィルター
FilteredCategory = Table.SelectRows(
Source,
each [Categories] <> "Electronics"
),
// Productをフィルター
FilteredProduct =
Table.SelectRows(
FilteredCategory,
each [Product] <> "Milk"
)
in
FilteredProduct
このクエリの最後のステップ FilteredProduct を選択して「ステップを診断する」を実行します。作成された Aggregated の診断を先ほどと同じように調べると、以下の結果が出ています。
Request:
GET https://services.odata.org/V3/OData/OData.svc/Categories?$filter=Name ne 'Electronics'&$expand=Products HTTP/1.1
Response:
https://services.odata.org/V3/OData/OData.svc/Categories?$filter=Name ne 'Electronics'&$expand=Products
HTTP/1.1 200 OK
Categories が Electronics でフィルターされていおり、クエリフォールディングが効いていることが分かります。
24.4 診断関数
24.4.1 Diagnostics.Trace
Diagnostics.Trace を利用すると、Power Query の実行されたステップを追跡することができます。
Diagnostics.Trace(
traceLevel as number,
message as anynonnull,
value as any,
optional delayed as nullable logical
) as any
value は返される値で、値が返されるとき、messageをログに記録します。value の値はログには含まれないため、記録したい場合はmessageに含める必要があります。
traceLevelは、以下の値を選択します。
-
TraceLevel.Critical: 重大 -
TraceLevel.Error: エラー -
TraceLevel.Warning: 警告 -
TraceLevel.Information: インフォメーション -
TraceLevel.Verbose: 冗長
delayパラメータは、trueまたはfalseの値を取り、メッセージがトレースされるまで value の評価を遅らせるかどうかを指定します。通常はtrueにしますが、このパラメータの設定によってvalueの設定が変わります。
-
true:valueは関数の値 -
false:valueは実際の値
let
Source =
List.Transform(
List.Numbers(0,9), // 0から9の値のリスト
each _ + 1 // リストの値をそれぞれ +1 する
)
in
Source

let
fxTrace = (message as text, value as any) =>
Diagnostics.Trace(
TraceLevel.Information,
message,
value,
true
),
Source =
List.Transform(
List.Numbers(0,9),
each fxTrace( "Trace", ()=> _ + 1) // valueに関数を渡す
)
in
Source
let
fxTrace = (message as text, value as any) =>
Diagnostics.Trace(
TraceLevel.Information,
message,
value,
false
),
Source =
List.Transform(
List.Numbers(0,9),
each fxTrace( "Trace", _ + 1) // valueに値を渡す
)
in
Source
具体例
以下のようなクエリは、CSVファイルの読み込みをシミュレートするためのものです。無限の長さのCSVファイルに対して List.FirstN を適用すると、100行読み込んだところで読み込みが終了し、最後まで読み込まずに処理が行われます。
let
// ログ出力
fxTrace = (message as text, value as any) =>
Diagnostics.Trace(
TraceLevel.Information,
message,
value,
true
),
// 0から100までの行からなるCSVの読み込みをシミュレート
Source =
Table.FromColumns(
{
List.FirstN(
List.Generate(
fxTrace( "First Item", ()=> ()=> 0 ),
each true,
each fxTrace( Text.Format("Next #{0}", {_ + 1}), ()=> _ + 1)
),
100
)
}
)
in
Source
Diagnostics.Traceを呼び出す関数も中に記載されており、このクエリを診断します。
作成された詳細な診断(Detailed)のAdditional Infoを展開してmessageを見ると、以下のようなメッセージが記録されていることが分かります。

24.5 クエリ診断を用いたトラブルシューティング
24.5.1 パフォーマンスの問題解決
例: クエリの実行時間が長い場合
-
診断結果の確認:
- 診断データを確認し、どの操作に最も時間がかかっているかを特定します。
-
改善策:
- フィルタリングや結合などの操作を、データソース側で行えるようにクエリを最適化します(クエリフォールディングを有効化)。
- 不要な列やデータの削除を早い段階で行い、処理データ量を削減します。
- 時間のかかる処理の前に列の削除やフィルターを先に行い、処理対象のデータを減らします。
24.5.2 クエリ診断とベストプラクティス
-
定期的な診断の実施:
- クエリが複雑になるたびに診断を実施し、パフォーマンスを最適化します。
-
エラー処理の標準化:
- try...otherwiseを活用し、クエリが失敗しても適切に処理できるように設計します。
-
ログの保存と共有:
- 診断結果を保存し、チーム内で共有して共同作業を円滑にします。
-
クエリ設計の改善:
- パフォーマンスが低下する操作(例: 不必要なステップ)を削除し、効率的なクエリを作成します。