この章では、Power Queryを使用してさまざまなデータソースからデータを統合するための高度な手法を学びます。ファイル、データベース、クラウドサービス、Web APIなど異なる形式のデータを効果的に組み合わせるためのテクニックを中心に解説します。また、データ統合の際に直面する共通の課題とその解決方法も紹介します。これにより、異なるデータソースを統合して一貫性のあるデータセットを構築し、効率的なデータ分析の基盤を作ることができるようになります。
2.1. データソースからのデータ取得
Power Queryは、Excel、CSV、SQLデータベース、Web APIなど、さまざまなデータソースに接続できる柔軟なデータ取得機能を備えています。このセクションでは、一般的なデータソースの接続方法と、データの取り込みにおけるポイントを紹介します。
2.1.1. ファイルデータソースからのデータ取得
File.Contents
File.Contents 関数は、単独で使用されることはほとんどありませんが、Excel.Workbook、Csv.Document、Json.Document、Xml.DocumentおよびXml.Tablesなどのファイルアクセス関数の第1パラメータとして利用されます。
File.Contents関数は、contentsパラメータと、省略可能なoptionsパラメータの2つを使います。この関数の戻り値は、バイナリになります。
contentsパラメータは、C:\Data\Sales.csvのようにファイルの場所を指定します。2番目のパラメータで使える有効なオプションは、公式なオンラインドキュメントには記載されていません。
Excelファイルからのデータ取得 ¹
M言語には、Excel.Workbook とExcel.CurrentWorkbook というExcel用の2つの標準データアクセス関数があります。
// Excelファイルからのデータ取得
let
Source =
Excel.Workbook(
File.Contents("C:\Data\SalesData.xlsx"), // workbook as binary
null, // optional useHeaders as any
true // optional delayTypes as nullable logical
),
SalesTable = Source{[[Item="Sales",Kind="Sheet"]]}[Data]
in
SalesTable
Excel.Workbook は、C:Data フォルダにある SalesData.xlsx ファイルを開き、シート名 Sales のデータを取り込んでいます。
2番目のパラメータは、テーブルの最初の行をヘッダーとして扱うかどうかを指定する論理値 (true または false)または null を指定できます。省略した場合は false です。
3番目のパラメータは、テーブルの列の型を自動で判別しないようにするかどうかを指定する論理値 (true または false) を指定できます。省略した場合は false です。true は自動判別しない、false は自動判別するとなることに注意してください。
GUI操作でエクセルファイルを読み込むと、第2パラメータは null 、第3パラメータは true になっています。つまり、ヘッダーを指定せず、自動判別はしないで読み込みを行います。そして、ヘッダーの有無を自動で判別し、ヘッダーがある場合は「昇格されたヘッダー数」(Promoted Headers)というステップを追加します。ヘッダーがないと版出された場合は、このステップは作成されません。その次に「変更された型」(Changed Type)というステップを追加し、データの型を自動で定義しています。
「昇格されたヘッダー数」を削除し、
Source = Excel.Workbook(File.Contents("C:\Data\SalesData.xlsx"), true, true),
と書き換えることもできます。
useHeaders にレコードフィールドを指定することができます。 (delayTypes は null)、次のレコード フィールドを指定することができます。
// Excelファイルからのデータ取得(レコードフィールド指定)
let
Source =
Excel.Workbook(
File.Contents("C:\Data\SalesData.xlsx"), // workbook as binary
[
UseHeaders = false, // テーブルの最初の行をヘッダーとして扱うかどうか
DelayTypes = false, // 各テーブルの列を型指定しないようにするかどうか
InferSheetDimensions = false
]
),
SalesTable = Source{[[Item="Sales",Kind="Sheet"]]}[Data]
in
SalesTable
InferSheetDimensions を true にすると、エクセルファイルからディメンションのメタデータを読み取るのではなく、Power Query がワークシート自体を読み取り、データを含むワークシートの領域を推定します。これは、エクセルファイルの中のディメンションのメタデータが正しくない場合に役立ちます。(拡張子 .xlsx ファイルのみで指定可能)²
データ型の判定は、自動で行うより手動で行うというベストプラクティスを推奨します。データ型の指定方法は別途解説します。
Excel.CurrentWorkbook 関数は、ExcelのPower Queryのみで動作します。現在開いているExcelファイルを参照し、テーブル、名前付き範囲、動的配列を返します。
let
Source = Excel.CurrentWorkbook(),
Table = Source{[Name="テーブル1"]}[Content]
in
Source
CSVファイルからのデータ取得 ³
GUIでCSVファイルを読み込むと、以下のようにレコードフィールドで指定された形式になります。
let
Source =
Csv.Document(
File.Contents("C:\Data\SalesData.csv"), // source as any
[
Delimiter=",",
Columns=18, // null、列数、列名のリスト、またはテーブル型のいずれか
Encoding=65001, // UTF-8
QuoteStyle=QuoteStyle.None
]
)
in
Source
列数は自動的に列数がカウントされ、Columns に設定されます。クエリ作成後に列数が増えた場合、最初に作成された列数以上は読み込まれませんし、減った場合は、空の列が作成されてしまいます。Columnsは、以下のように変更し、列名や型を指定することができます。
Columns = null
Columns = {"Name", "Value"}
Columns = type table [Name = text, Value = number]
Encodingには、直接65001の価が記述されていますが、Encoding=TextEncoding.Utf8のように指定することもできます。以下は指定できる値の一部です。
| 名前 | 値 |
|---|---|
| TextEncoding.Utf16 | 1200 |
| TextEncoding.Unicode | 1200 |
| TextEncoding.BigEndianUnicode | 1201 |
| TextEncoding.Windows | 1252 |
| TextEncoding.Ascii | 20127 |
| TextEncoding.Utf8 | 65001 |
GUIを開くと、更に多くの値を見ることができます。

QuoteStyleでは、文字列内の引用符の扱いを決め、QuoteStyle.NoneとQuoteStyle.Csvの値をとります。既定値はQuoteStyle.Csvで、引用符で囲まれた中に改行がある、2行になったデータを扱うことできます。QuoteStyle.Noneでは、引用符は無視されます。
ただし、デリミタの直後に空白が入っている場合、正しく処理されません。その場合は、CsvStyleを指定し、CsvStyle=CsvStyle.QuoteAlwaysを設定します。
let
Source = """Bright#(lf)Orange"",174, ""US""#(lf)""Aldo Motors"",168, ""UK""",
CsvDocument =
Csv.Document(
Source,
[
Delimiter=",",
Encoding=65001,
QuoteStyle=QuoteStyle.Csv,
CsvStyle=CsvStyle.QuoteAlways
]
)
in
CsvDocument
"Bright
Orange",174, "US"
"Aldo Motors",168, "UK"

レコードフィールドで指定しない方法もあります。
let
Source =
Csv.Document(
File.Contents("C:\Data\SalesData.csv"),
10, // columns
",", // delimiter
ExtraValues.List, // extraValues
65001 // TextEncoding.Utf8
)
in
Source
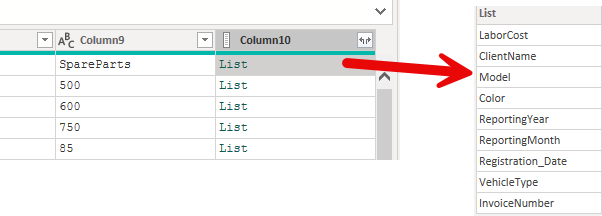
extraVlues は、列数がcolumnsで指定した数と異なる場合の処理を指定します。
- ExtraValues.List : 列の数が想定より多い場合、残りの列はリストになります
- ExtraValues.Error : 列の数が想定より多い場合、エラーを発生させます
- ExtraValues.Ignore : 列の数が想定より多い場合、残りの列は無視されます
ExtraValues.Listでは、上の例で10を超えた列の内容は、下記のようにリストに収められます。
XMLファイルの活用 ⁴
XML(eXtensible Markup Language)は、データを保存するために広く使われているファイル形式です。使用は標準化されており、その柔軟性により、アプリケーション間のデータ交換に適しています。
XML関数軍には、Xml.Tables と Xml.Document があります。両関数の最初の引数は、ファイルの内容を指定します。両関数の最後の引数はオプションのエンコーディング番号(TextEncoding.Type)です。
-
Xml.TablesはXMLを解析し、要素をテーブル形式に変換します

-
Xml.Documentは、XMLデータをツリー構造として読み込みます。XMLの階層が深く複雑な場合、ノードの特定の属性にアクセスしたり、部分的にデータを抽出するなど、細かいコントロールが必要な場合はXml.Documentが適しています。

Xml.Document で読み込んだ後にテーブルを作成するには、以下のようにより多くの変換が必要となります。
let
Source = Xml.Document(File.Contents("C:\Data\Chapter-02\sample02.xml")),
// 不要な列の削除
#"Removed Other Columns" = Table.SelectColumns(Source,{"Value"}),
// Valueを展開
#"Expanded {0}" = Table.ExpandTableColumn(#"Removed Other Columns", "Value", {"Value"}, {"Value.1"}),
// インデックス列の追加
#"Added Index" = Table.AddIndexColumn(#"Expanded {0}", "インデックス", 0, 1, Int64.Type),
// Value.1 を展開
#"Expanded {0}1" = Table.ExpandTableColumn(#"Added Index", "Value.1", {"Name", "Value"}, {"Name", "Value"}),
// インデックス列を一番左に移動
#"Reordered Columns" = Table.ReorderColumns(#"Expanded {0}1",{"インデックス", "Name", "Value"}),
// ピボット処理
#"Pivoted Column" = Table.Pivot(#"Reordered Columns", List.Distinct(#"Reordered Columns"[Name]), "Name", "Value"),
// 不要となったインデックス列の削除
#"Removed Columns" = Table.RemoveColumns(#"Pivoted Column",{"インデックス"})
in
#"Removed Columns"
PDFファイルの活用⁵
PDF(Portable Document format)ファイルに記載された表データを取得するには、Pdf.Tables関数を使用します。
let
Source =
Pdf.Tables(
File.Contents("C:\Data\Chapter-02\Sample.pdf"),
[
Implementation="1.3"
]
),
Table001 = Source{[Id="Table001"]}[Data]
in
Table001
Implimentationは、PDFファイル内のテーブルを識別するためのアルゴリズムです。
その他のオプションは、
-
StartPage: データ取得に含める最初のページを指定する -
EndPag: 利用可能内最後のページを指定する -
MultiPageTables: 複数のページにまたがるテーブルを単一のテーブルとして扱う場合はtrue。複数のテーブルとして扱う場合はfalse(ただし、必ずしも識別に成功するわけではない) -
EnforceBorderLines: テーブル内のセルの識別で境界線を強調するかどうか。既定値はfalse
しかし、PDFは、必ずしも期待通りの表が取得できないかもしれません。その場合は、追加の処理が必要となります。
フォルダー ⁶
単一ファイルへのアクセスに加えて、任意の数のファイルを含むフォルダーを扱う2つの関数、Folder.Contents と Folder.Files があります。どちらの関数も、最初のパラメータにファイルパスを、2番目のパラメータにオプションレコードをとります。
Folder.Contents 関数の出力は、指定されたフォルダー内のフォルダーとファイルを返すのに対して、Folder.Files 関数は、指定されたフォルダーとすべてのサブフォルダー内にあるファイルを返します。
- Folder.Contents

- Folder.Files

フォルダー内で直近に作成されたCSVファイルを開く場合は、以下のようにします。
let
Source = Folder.Contents("C:\Data\Folder"),
// CSVファイルだけ
#"Filtered Rows" = Table.SelectRows(Source, each ([Extension] = ".csv")),
// 作成日を降順に並び替える
#"Sorted Rows" = Table.Sort(#"Filtered Rows",{{"Date created", Order.Descending}}),
// 最初の行のContentをCsv.Documentで開く
CsvData = Csv.Document(#"Sorted Rows"{1}[Content])
in
CsvData
フォルダー内のファイルを全て結合したい場合、Contents の横にあるボタンで「ファイルの結合」を行うことができます。その場合、自動的に複数のクエリからなるヘルパークエリが作成されます。ヘルパークエリに関しては、別の章で説明します。


フォルダー内のCSVファイルが全て同じフォーマットであれば、以下のようにして全て結合する方法もあります。データ量が多かったり、読み込んだ後の処理が必要な場合は、ヘルパークエリを使った方法を選択してください。
let
Source = Folder.Contents("C:\Data\Folder"),
// CSVファイルのみ
#"Filtered Rows" = Table.SelectRows(Source, each ([Extension] = ".csv")),
// Contentの中身をテーブルに変換して新しい列に入れる
AddNewColumn =
Table.AddColumn(
#"Filtered Rows",
"Table",
each Csv.Document(_[Content])
),
// ほかの列はすべて削除
#"Removed Other Columns" = Table.SelectColumns(AddNewColumn,{"Table"}),
// テーブルを展開
#"Expanded {0}" =
Table.ExpandTableColumn(
#"Removed Other Columns",
"Table",
{"Column1", "Column2"}, // サンプルはColumn1 と Column2 の2列だけのデータ
{"Column1", "Column2"}
)
in
#"Expanded {0}"

詳細は、「第10章 ヘルパークエリ」を参照してください。
2.1.2. データベースとの接続
SQL ServerやOracleなどのリレーショナルデータベースへの接続: Power Queryは主要なリレーショナルデータベースに接続してデータを取得することができます。ほとんどのデータベースでは、テーブルやビューへ接続できますが、関数への接続はサポートされていません。更に考慮すべき点としては、PCに正しいクライアント・コンポーネントがインストールされていることを確認する必要があります。
ネイティブなSQLクエリを記述することもできますが、Power Queryでは、クエリ全体を評価し、より効率的なクエリを作成して問い合わせを行う クエリフォールディング が行われます。
2.1.3. Webデータソースからのデータ取得
Web上のデータを取得する関数として、 Web.Contents と Web.BrowserContents があります。
Web.Contents は、HTTPリクエストを送信してデータを取得するための関数で、APIや静的なWebリソースのデータを高速に取得できます。リクエストヘッダーやクエリパラメータを柔軟に指定できます。
Web.BrowserContents は、Webページをブラウザーのようにレンダリングし、結果を取得します。JavaScriptを使用した動的に生成されるデータの取得ができます。Web.Contentsと比べ、ユーザーのローカルブラウザーコンテキストでレンダリングされるため、パフォーマンスは落ちます。また、サーバー側で動作するデータフローなどの環境では使用できません。
Web.Contents⁷
Web.Contents関数は、File.Contents関数と同様に、Web上のデータをバイナリデータとして返します。Web上に表示されるデータや、エクセル、CSVなどの形式のファイルを取得することができます。
この関数の第1パラメータはテキストのURI(URL)で、第2パラメータは以下のオプションレコードです。
-
Query: URLにクエリストリングを追加 -
ApiKeyName: URLで使用されるキーの名前を指定 -
Headers: リクエストで使用される追加のHTTPヘッダ -
Timeout: タイムアウトまで待機する時間を指定する時間値。デフォルトは100秒 -
ExcludedFromCacheKey: キャッシュの計算から除外するHTTPヘッダキーのリスト -
IsRetry: trueを指定すると、既存のキャッシュされたレスポンスを無視 -
ManualStatusHandling: HTTPステータスコードのリストで、応答にこれらのいずれかの状態コードが含まれると、自動的に処理されない -
RelativePath: リクエストを行う際に指定された値をベースURLに追加 -
Content: バイナリ値で、この値を指定すると、POST のコンテンツにオプションの値が使用され、Web 要求が GET から POST に変更される
このパラメータを使用し、動的なURLを作成することもできます。
詳細は「第11章 Webコンテンツの取得」を参照してください。