FORTHを理解する鍵は、すべての計算や制御が「スタック」という単純な構造の上で行われるという点にある。スタックとは、皿を積み重ねるようにデータを順に押し込み(push)、上から順に取り出す(pop)仕組みである。この単純な構造を使って、FORTHは変数も関数呼び出しもなく複雑な計算を行うことができる。
スタックの基本操作
FORTHでは、数値を入力するだけで自動的にスタックに積まれる。たとえば 2 3 と入力すれば、スタックの状態は [2 3] となる(左が底、右が上)。ここで + を実行すると、上の2つの値を取り出して加算し、結果を再び積み直す。結果は [5] となり、. を入力すればトップの値を表示する。
2 3 + .
→ 出力: 5

このように、FORTHでは「式」ではなく「操作の流れ」で考える。CやPythonのように「a = 2 + 3」と変数に代入するのではなく、“スタックに2と3を積み、加算して結果を得る”という逐次的な動作を積み上げていく。この明快な流れがFORTHの強さであり、バグが起きても目で追いやすい理由でもある。
算術演算とスタックの可視化
FORTHの算術演算はすべてスタックを介して行われる。
代表的なものは以下のとおりである。
| 演算子 | 意味 | 使用例 | 結果 |
|---|---|---|---|
+ |
加算 | 2 3 + . |
5 |
- |
減算 | 10 4 - . |
6 |
* |
乗算 | 5 2 * . |
10 |
/ |
除算 | 9 3 / . |
3 |
mod |
剰余 | 5 3 mod . |
2 |
/mod |
除算と剰余 | 5 3 /mod . . |
1 2 |
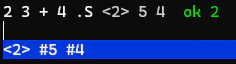
実行途中で .S を挟むとスタックの状態を確認できる。
たとえば 2 3 + 4 .S を実行すると、スタックに積まれている全ての値(この場合は5 と 4)が確認できる。.と違って、スタックから値が消えることはない。このような対話的な可視化が、FORTHの学習を直感的にする。
また、gforthのバージョン 0.7.9 では、画面の下部にスタックの状態が常に表示されているので、とても分かりやすい。
複合式の思考
FORTHの初心者が最初につまずくのは、「式を書く」ことができない点である。しかしFORTHでは、あらゆる計算を「スタックに値を積み、命令で変形する」流れとして捉える。これは“スタックで考える脳”を育てる訓練でもある。
たとえば (a*b) + (c*d) を書く場合、C言語なら a*b + c*d と書くだけだが、FORTHでは次のように展開される。
a b * c d * +
最初に a b * で a*b を計算し、それをスタックに残したまま c d * を計算。最後に + で両方を加算して完了する。この「逐次処理+スタックの保持」という発想が、FORTHのデータフロー設計の基本である。上級者になると、スタック操作を頭の中でシミュレーションしながらコードを組み立てられるようになる。
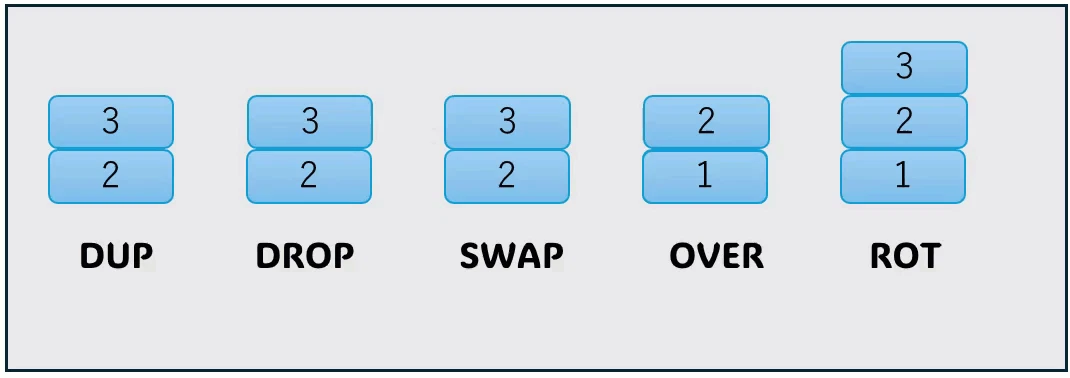
基本的なスタック操作ワード
FORTHの強力さは、スタックを自在に操る基本ワードにある。以下の操作を組み合わせることで、ほとんどの処理を構築できる。
| ワード | 動作 | 例 | 結果 |
|---|---|---|---|
| DUP | 最上段を複製 | 3 DUP |
[3 3] |
| DROP | 最上段を削除 | 3 4 DROP |
[3] |
| SWAP | 上2つを入れ替え | 2 3 SWAP |
[3 2] |
| OVER | 2段目を複製 | 1 2 OVER |
[1 2 1] |
| ROT | 上3つを回転 | 1 2 3 ROT |
[2 3 1] |
| .S | スタック内容を表示 | 1 2 3 .S |
1 2 3 <top> |
これらの操作は単純に見えるが、組み合わせると極めて柔軟な計算ができる。
たとえば (a + b) * 2 をFORTHで書くと次のようになる。
a b + 2 *
もし途中で同じ値を再利用したいときには DUP を使う。
3 DUP * 2 *
これは「3を複製→3×3=9→9×2=18」を意味する。このように、スタック操作は一つひとつの処理を視覚的に追える設計であり、プログラム全体を“数値の流れ”として考えられるようになる。
ほとんどの操作は前のワードの組み合わせで行えるが、それだけでは冗長になることがある。以下のワードも覚えておくとよい。
| ワード | 動作 | 例 | 結果 |
|---|---|---|---|
| ?DUP | 最上段が0でない場合複製 | 1 ?DUP 0 ?DUP |
[1 1 0] |
| DOWN | ROTの逆 | 1 2 3 DOWN |
[3 1 2] |
| -ROT | ROTの逆 | 1 2 3 DOWN |
[3 1 2] |
| NIP | 2段目のを削除 | 1 2 NIP |
[2] |
| TUCK | 最上段を2段目の下に複製 | 1 2 TICK |
[2 1 2] |
| 2DUP | 上2つを複製 | 1 2 2DUP |
[1 2 1 2] |
| 2DROP | 上2つを削除 | 1 2 3 2DROP |
[1] |
| 2OVER | 3段目4段目を複製して上に乗せる | 1 2 3 4 2OVER |
[1 2 3 4 1 2] |
| 2SWAP | 1段目2段目を3段目4段目と入れ替え | 1 2 3 4 2SWAP |
[3 4 1 2] |
| PICK | n+1段目の値を複製して上に乗せる | 1 2 3 2 PICK |
[1 2 3 1] |
| ROLL | n+1段目の値を上に移動 | 1 2 3 2 ROLL |
[2 3 1] |
gforthや他のほとんどのFORTHシステムは、大文字小文字を区別しない。ワードは大文字、小文字どちらで入力しても同じ結果になる。
gforthを終了するには「bye」と入力するか、まだ入力されていない行の先頭で Ctl~d を押す。
ワードの定義と再利用
FORTHでは、任意の処理を「ワード」として定義できる。ワードとはFORTHにおける命令の単位であり、関数やサブルーチンに相当する。
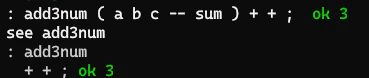
: ADD3NUM ( a b c -- sum ) + + ;
この定義により、2 3 4 ADD3NUM . を実行すれば 9 が出力される。ワード定義はFORTHの辞書に登録され、定義した瞬間から利用可能になる。この「定義即実行」という構造が、FORTHを“自分で育てる言語”にしている。
: add3num ( a b c -- sum ) + + ;
2 3 4 add3num .
→ 出力: 9
定義されたワードを逆コンパイルするには、see に続けてワードを入力する。
コメント
( から ) の間の文字と、\ から行末までの文字ははコメントになる。( と \ の後にはスペースが必要となるが、) の前にはスペースがなくてもよい。
1 2 ( one two ) 3 4 \ three four
.s
→ 出力: <4> 1 2 3 4
スタック図で考える
FORTHでは、ワード(命令)の入出力を明示するために「スタック図」を書く習慣がある。( から ) まではコメント扱いになる。その機能を使って、スタック図は、そのワードがスタックからどんなデータを取り、どんなデータを返すのかを (入力 -- 出力) の形で記述する。
スタック図の書式は、ANS Forth 標準(1994以降) で定義されている。
( before -- after ) \ データスタック
( before -- after ) ( R: beforeR -- afterR ) \ リターンスタックも併記可能
スタック図 ( n -- n^2 ) は、「入力としてnを取り、出力としてn²を返す」という意味である。この表記を読むことで、プログラムの振る舞いを式でなく“流れ”として理解できる。複雑なプログラムでも、各ワードがどのようにスタックを消費し、何を積むかを追うだけで全体の挙動を把握できる。
スタックを操作するFORTHのプログラミングは、実はデータフロー図に近い。各ワードが「入力を受け取り、出力を渡す」ノードとなり、スタック上のデータがそのノードを順に通過していく。
たとえば次のようなプログラムを考えてみよう。
: HYPOT ( a b -- c ) DUP * SWAP DUP * + FSQRT ;
これは直角三角形の斜辺を求めるワードである。スタック図 ( a b -- c ) は、値aとbを入力して、出力cを返すことを示す。この一行の中で、DUPやSWAPがデータの流れを調整し、+とFSQRTが数学的処理を行う。各操作の意味をスタック図で追えば、アルゴリズム全体を視覚的に理解できる。
スタック図で使用される記号
| 略号 | 意味 |
|---|---|
n |
通常整数 |
u |
符号なし整数 |
x |
任意型 |
c |
キャラクタ値(1byte) |
addr |
アドレス |
a-addr |
整列されたアドレス |
c-addr |
文字アドレス |
d |
ダブル整数(2cells) |
f r
|
浮動小数点値 |
xt |
実行トークン |
flag |
ブーリアンフラグ |
len |
文字列長 |
i |
インデックス |
特殊スタックや領域の表記
| 記号 | 意味 | 例 |
|---|---|---|
(--) |
データスタック | 通常のスタック図 |
(R:--) |
リターンスタック | 例:>R(x--R:x)
|
(F:--) |
浮動小数点スタック | 例:F+(F:r1r2--r3)
|
(C:--) |
制御スタック(コンパイル時) | コンパイルワードの説明などに使われる |
変数・配列・アドレス関係の例
| ワード | スタック図 | 意味 |
|---|---|---|
@ |
(addr--x) |
アドレスから値を読み出す |
! |
(xaddr--) |
アドレスに値を書き込む |
+! |
(naddr--) |
アドレスの内容にnを加算して書き戻す |
CREATE |
("<name>"--) |
名前を作る(辞書登録) |
ALLOT |
(n--) |
nバイト分のメモリ確保 |
, |
(x--) |
現在の辞書ポインタに値を書き込む |
スタックの深さを調べる
FORTH では “スタックにいくつ値が積まれているか(深さ)” を返す depth というワードが使える。
1 2 3 depth . \ → 3
: SUM
DEPTH 1 DO
+
LOOP
;
: CLEAR
BEGIN DEPTH 0> WHILE
DROP
REPEAT
\ 浮動小数点スタックも削除
BEGIN FDEPTH 0> WHILE
FDROP
REPEAT
;
スタックで考えるということ
FORTHにおけるプログラミングは、「文を書いて機械に指示すること」ではなく、「データがどのように流れ、どこで形を変えるか」を設計する作業である。この考え方は、現代的なデータフロー言語(LabVIEWやTensorFlowなど)にも通じている。
スタックという極小の構造を通して、FORTHは“最小の要素で最大の表現”を実現している。手続き的ではなく、流体的に――FORTHのプログラミングは、数値が流れ、命令がその流れを彫刻するように進むのである。