22.1 Power Query を作成するときに重要なこと
22.1.1 意識(Awareness)
クエリを作成する際には、自動生成されるMコードやプレビュー段階でのデータ状態に注意を払うことが重要です。
たとえば、クエリエディタの「数式バー(formula bar)」を常に表示して、ステップがどのようなMコードを生成しているかを確認する習慣をつけましょう。

M言語の関数の知識がなくても、列名や値がハードコーディングされていないか(ダブルクォートで囲まれた固定の値として書かれていないか)をチェックすることで、後からデータが変化した際のエラーを防ぎやすくなります。
そして、更にM言語の知識を深めるためには、詳細エディタを開き、自動生成されたコードを整形し、どのような関数が使われているのか調べてみましょう。
22.1.2. ベストプラクティス(Best Practices)
意外にも、長く使えるコードを書くためには、人間関係が非常に重要な要素です。
外部データソースを管理する担当者との親密な関係を持つことで、列名変更やデータ構造の変更が計画される際に通知を受けたり、対応方法を教えてもらうことができます。そうして、必要な時点で必要な変更だけを行うことができます。さらに、データベースは通常トランザクション処理が重視されますが、データ分析に適したデータソースを提供してもらえる可能性もあります。
また、問題なく動いていた時のファイルは保存しておきましょう。正常に動作しているときの状態が残っていれば、エラーとなったものと結果を比較して失敗の原因を特定します。
そして、以下の落とし穴に注意することで、適切なクエリを作成することができます。
22.2 主な落とし穴(Pitfalls)の例と対策
以下に上げた落とし穴は、5番目以降は必ずしも必要でありません。しかし、対処方法を知っておくことは意味があります。
22.2.1. 数式バーを無視すること
自動生成されたM式を確認せずに進めると、意図せず特定の列名や値がハードコーディングされたままとなり、後でデータが変化(列名が変わる、列が削除されるなど)すると更新時にエラーが発生したり誤った集計につながります。
数式バーを常に表示・確認し、問題になりそうなハードコード部分を認識しておくことをお勧めします。

22.2.2. 自動的な型変換(Changed Type)
Power Queryで、更新が失敗することが多いのは「変更された型」のステップです。
Power Queryはインポート時に列の型推測を自動で行い、「変更された型」(Changed Type)ステップが勝手に追加されることがあります。このステップではすべての列が固定的に指定されるため、後で列名や列構造が変わるとエラーになります。
自動的に作られる「変更された型」ステップは削除し、必要になった段階で個別の列を明示的に型変換を行うようにします。オプションで「型の検出」をオフにすることも有効です。
Power BIで正しく分析を行うには、正確な型が定義されていることが重要になります。そのため、Power Queryは事あるごとに「変更された型」を生成しているのです。クエリの最後には、全ての列に型が指定されていなければなりません。
しかし、途中の「変更された型」のステップをすべて削除し、最後にまとめてやればいいというわけではありません。
データの変換処理を行う列に望ましくないデータが紛れ込む可能性がある場合は、操作を行うステップより前で、対象の列の型変換を行うことを検討すべきです。
注意することは、型の変換にはマシンのリソースを必要とします。従って、ある程度データを絞り込んだ後に型変換することで、クエリの更新時間を短縮することができます。
また、型変換を行うと、エラーが発生する可能性があります。必要なデータに絞り込まれた後に型変換することで、エラーの発生を抑えることができます。
最後に、型変換と、型の指定の違いを理解してください。Table.AddColumns や、Table.TransformColumns などの関数は、自動生成では変換後の型を指定するオプションが生成されませんが、M言語の中級者ともなれば、手作業で型の指定を入れておくべきです。自動生成で関数の内部で型の変換を行う処理や、事前に型が指定されていなければ動作しない関数もあります。
let
Source = Table.FromRows(
{
{1, "10"},
{5, "20"}
},
type table [A = Int64.Type, B = text]
),
Result =
Table.AddColumn(
Source,
"NewColumn",
each [A] + Number.FromText([B])
)
in
Result
let
Source = Table.FromRows(
{
{1, "10"},
{5, "20"}
},
type table [A = Int64.Type, B = text]
),
Result =
Table.TransformColumns(
Source,
{
{"A", Text.From, type text},
{"B", Number.From, Int64.Type}
}
)
in
Result
型変換は「最後に変更するほど良い」と言われますが、全体の処理の流れを見て適切に配置することが大切です。
- 自動生成された「変更された型」は削除する
- 明示的に型の指定・変換を行う
- 不要な列の型変換はしない
- 不要な行の型変換はしない
- 最終的には全ての列に型を指定する
- データソースについての理解を深める
22.2.3. 危険なフィルタリング(Dangerous Filtering)
この落とし穴は、エラーが発生しないため、問題が発生しても見落とされてしまい、非常に危険です。
フィルタペインで値を選択・非選択する際、意図と異なる条件式が生成されることがあります。特に検索ボックスを使ってフィルタする場合、本来は「特定の値を除外」したいのに、「特定の値のみを残す」になってしまったり、その逆も起こります。そして、将来的に新しい値が追加されたときに問題が発生します。
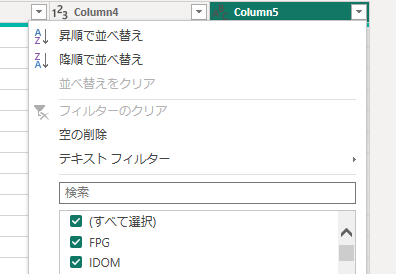
フィルター条件を生成するルールは以下の様になっています。
- $ 選択解除された値の数 \geqq 選択された値の数 $ : 選択された値に等号を使用して条件を生成
- $ 選択解除された値の数 < 選択された値の数 $ : 選択されていない値に不等号を使用して条件を生成
期待する条件式と異なる場合は、「行のフィルター」で条件を作成するか、数式バーで生成された条件をチェックし、条件を書き換えるなどMコードを修正します。

フィルタリング条件は、「行のフィルター」ダイアログを表示させて条件式を定義するようにします。
22.2.4 列順序の変更(Reordering Columns)
列順序を変更すると、そのステップ(並び替えられた列, Table.ReorderColumns)はすべての列名を明示的に参照し、将来一部列が削除・名称変更された場合にエラーの原因になります。

列順序変更はPowr Queryで処理する段階では意味がなく、クエリのパフォーマンスを落とすので、なるべく避けるべきです。見栄えが問題となるのであれば、後続のアプリ側で処理すべきでしょう。
ただし、本当に必要な場合はTable.ReorderColumns と Table.ColumnNames()を用いて動的に列名を取得したり、一部の列だけを柔軟に並び替えるMコードを書きます。
ReorderedColumns = Table.ReorderColumns(Source,{"OrderDate", "OrderID", "ProductID", "Country", "City", "Region", "Sales", "Quantity", "Discount", "Profit"})
2つの項目を入れ替えます。
let
Source = Table.FromRows(
{
{"CA-2016-152156","2016/11/8","United States","Henderson","South","FUR-BO-10001798",261.96,2,0,41.9136},
{"CA-2016-152156","2016/11/8","United States","Henderson","South","FUR-CH-10000454",731.94,3,0,219.582},
{"CA-2016-138688","2016/6/12","United States","Los Angeles","West","OFF-LA-10000240",14.62,2,0,6.8714},
{"US-2015-108966","2015/10/11","United States","Fort Lauderdale","South","FUR-TA-10000577",957.5775,5,0.45,-383.031}
},
type table [OrderID = Int64.Type, OrderDate = text, Country = text, City = text, Region = text, ProductID = text, Sales = Decimal.Type, Quantity = Int64.Type, Discount = Decimal.Type, Profit = Decimal.Type]
),
ReorderColumns =
Table.ReorderColumns(
Source,
{"OrderDate", "OrderID"} // 2項目の入れ替え
)
in
Source
複数項目を項目を一番左に並べます。
let
Source = Table.FromRows(
{
{"CA-2016-152156","2016/11/8","United States","Henderson","South","FUR-BO-10001798",261.96,2,0,41.9136},
{"CA-2016-152156","2016/11/8","United States","Henderson","South","FUR-CH-10000454",731.94,3,0,219.582},
{"CA-2016-138688","2016/6/12","United States","Los Angeles","West","OFF-LA-10000240",14.62,2,0,6.8714},
{"US-2015-108966","2015/10/11","United States","Fort Lauderdale","South","FUR-TA-10000577",957.5775,5,0.45,-383.031}
},
type table [OrderID = Int64.Type, OrderDate = text, Country = text, City = text, Region = text, ProductID = text, Sales = Decimal.Type, Quantity = Int64.Type, Discount = Decimal.Type, Profit = Decimal.Type]
),
// 見出しになる項目
LineHeadings = {"OrderDate", "OrderID", "Region"},
ReorderColumns =
Table.ReorderColumns(
Source,
LineHeadings &
List.Difference(
Table.ColumnNames( Source ),
LineHeadings
)
)
in
ReorderColumns

挿入場所を指定する場合は、Line.InsertRange 関数を使います。
22.2.5. 列の削除と選択(Removing and Selecting Columns)
不要な列を「列の削除」で削除すると、将来的にその列がデータソースから消えた場合にエラーが起こる可能性があります。あなたが不要と思っている項目は、管理者も同じことを考えているかもしれません。
削除する列を選択するのではなく、残したい列だけを「列の選択」で選択すれば、後で不要な列が消えてもエラーになることはありません。「列の削除」を指定するより、「列の選択」を選択する方が将来変更に強くなります。
Table.RemoveColumns および Table.SelectColumns には列が見つからない場合の動作を指定する3番目のオプションがあります。
-
MissingField.Ignoreは、列が見つからなかった場合無視して処理を続けます。 -
MissingField.UseNullは、エラー時に列名を保持しつつnullで埋めます。
しかし、これらのオプションを使用することで、エラーの検出がされず、予期しない結果が生じる可能性があります。
Table.ColumnNames()やList.Range()などを用いて位置ベースで列を指定する方法も、場合によっては有効です。
let
Source = Table.FromRows(
{
{"CA-2016-152156","2016/11/8","United States","Henderson","South","FUR-BO-10001798",261.96,2,0,41.9136},
{"CA-2016-152156","2016/11/8","United States","Henderson","South","FUR-CH-10000454",731.94,3,0,219.582},
{"CA-2016-138688","2016/6/12","United States","Los Angeles","West","OFF-LA-10000240",14.62,2,0,6.8714},
{"US-2015-108966","2015/10/11","United States","Fort Lauderdale","South","FUR-TA-10000577",957.5775,5,0.45,-383.031}
},
type table [OrderID = Int64.Type, OrderDate = text, Country = text, City = text, Region = text, ProductID = text, Sales = Decimal.Type, Quantity = Int64.Type, Discount = Decimal.Type, Profit = Decimal.Type]
),
RemovedColumns =
Table.RemoveColumns(
Source,
Table.ColumnNames( Source ){ 3 } // 4番目の列
)
in
RemovedColumns
let
Source = Table.FromRows(
{
{"CA-2016-152156","2016/11/8","United States","Henderson","South","FUR-BO-10001798",261.96,2,0,41.9136},
{"CA-2016-152156","2016/11/8","United States","Henderson","South","FUR-CH-10000454",731.94,3,0,219.582},
{"CA-2016-138688","2016/6/12","United States","Los Angeles","West","OFF-LA-10000240",14.62,2,0,6.8714},
{"US-2015-108966","2015/10/11","United States","Fort Lauderdale","South","FUR-TA-10000577",957.5775,5,0.45,-383.031}
},
type table [OrderID = Int64.Type, OrderDate = text, Country = text, City = text, Region = text, ProductID = text, Sales = Decimal.Type, Quantity = Int64.Type, Discount = Decimal.Type, Profit = Decimal.Type]
),
RemovedColumns =
Table.RemoveColumns(
Source,
List.FirstN( Table.ColumnNames( Source ), 3) // 頭から3つの列
)
in
RemovedColumns
let
Source = Table.FromRows(
{
{"CA-2016-152156","2016/11/8","United States","Henderson","South","FUR-BO-10001798",261.96,2,0,41.9136},
{"CA-2016-152156","2016/11/8","United States","Henderson","South","FUR-CH-10000454",731.94,3,0,219.582},
{"CA-2016-138688","2016/6/12","United States","Los Angeles","West","OFF-LA-10000240",14.62,2,0,6.8714},
{"US-2015-108966","2015/10/11","United States","Fort Lauderdale","South","FUR-TA-10000577",957.5775,5,0.45,-383.031}
},
type table [OrderID = Int64.Type, OrderDate = text, ReportingCountry = text, ReportingCity = text, ReportingRegion = text, ProductID = text, Sales = Decimal.Type, Quantity = Int64.Type, Discount = Decimal.Type, Profit = Decimal.Type]
),
RemovedColumns =
Table.RemoveColumns(
Source,
List.Select(
Table.ColumnNames(Source),
each Text.Contains( _, "Reporting" ) // Reportingが含まれる列
)
)
in
RemovedColumns
22.2.6. 列名のリネーム(Renaming Columns)
エクセル表などでは、列名が頻繁に変更されることが一般的です。しかし、そのようなデータソースをPower Queryで利用する場合、更新失敗の可能性が高くなります。
そこで、Table.TransformColumnNamesを使ってパターンに応じて列名を変えたり、Table.ColumnNames()とインデックス参照で安全にリネームします。
let
Source = Table.FromRows(
{
{"CA-2016-152156","2016/11/8","United States","Henderson","South","FUR-BO-10001798",261.96,2,0,41.9136},
{"CA-2016-152156","2016/11/8","United States","Henderson","South","FUR-CH-10000454",731.94,3,0,219.582},
{"CA-2016-138688","2016/6/12","United States","Los Angeles","West","OFF-LA-10000240",14.62,2,0,6.8714},
{"US-2015-108966","2015/10/11","United States","Fort Lauderdale","South","FUR-TA-10000577",957.5775,5,0.45,-383.031}
},
type table [OrderID = Int64.Type, OrderDate = text, ReportingCountry = text, ReportingCity = text, ReportingRegion = text, ProductID = text, Sales = Decimal.Type, Quantity = Int64.Type, Discount = Decimal.Type, Profit = Decimal.Type]
),
RenamedColumns =
Table.RenameColumns(
Source,
{
{ Table.ColumnNames(Source){0}, "ID" },
{ Table.ColumnNames(Source){1}, "Date" },
{ Table.ColumnNames(Source){2}, "Country" }
}
)
in
RenamedColumns
let
Source = Table.FromRows(
{
{"CA-2016-152156","2016/11/8","United States","Henderson","South","FUR-BO-10001798",261.96,2,0,41.9136},
{"CA-2016-152156","2016/11/8","United States","Henderson","South","FUR-CH-10000454",731.94,3,0,219.582},
{"CA-2016-138688","2016/6/12","United States","Los Angeles","West","OFF-LA-10000240",14.62,2,0,6.8714},
{"US-2015-108966","2015/10/11","United States","Fort Lauderdale","South","FUR-TA-10000577",957.5775,5,0.45,-383.031}
},
type table [OrderID = Int64.Type, OrderDate = text, Country = text, City = text, Region = text, ProductID = text, Sales = Decimal.Type, Quantity = Int64.Type, Discount = Decimal.Type, Profit = Decimal.Type]
),
Renamed =
Table.RenameColumns(
Source,
List.Transform(
Table.ColumnNames(Source),
each { _, Text.Upper(_) } // 元の列名と大文字に変換した列名のペアを作成
)
)
in
Renamed

let
Source = Table.FromRows(
{
{"CA-2016-152156","2016/11/8","United States","Henderson","South","FUR-BO-10001798",261.96,2,0,41.9136},
{"CA-2016-152156","2016/11/8","United States","Henderson","South","FUR-CH-10000454",731.94,3,0,219.582},
{"CA-2016-138688","2016/6/12","United States","Los Angeles","West","OFF-LA-10000240",14.62,2,0,6.8714},
{"US-2015-108966","2015/10/11","United States","Fort Lauderdale","South","FUR-TA-10000577",957.5775,5,0.45,-383.031}
},
type table [OrderID = Int64.Type, OrderDate = text, ReportingCountry = text, ReportingCity = text, ReportingRegion = text, ProductID = text, Sales = Decimal.Type, Quantity = Int64.Type, Discount = Decimal.Type, Profit = Decimal.Type]
),
RenamedColumns =
Table.RenameColumns(
Source,
List.Transform(
List.Select(
Table.ColumnNames(Source),
each Text.Contains(_, "Reporting")
),
each { _, Text.Replace( _, "Reporting", "") }
)
)
in
RenamedColumns
原則として、データソースの列名の変更は頻繁に行われないようにすべきです。ほとんどの場合、これまで通りのシンプルな名前変更で十分です。過度に考えすぎないでください。
22.2.7. 列を複数の列に分割する(Splitting a Column into Columns)
カンマ区切りなどの文字列を列分割するとき、デフォルトでは「複数の列」へ分割が行われます。この場合、将来値が増えて分割列数が足りなくなると、あふれたデータが無視され、データが欠落してしまう可能性があります。。
また、UIを使った列の分割では、上位200件のデータを調べて、分割する列数を決めています。「区切り記号による列の分割」ダイアログで「詳細設定オプション」を開くと、分割後の列数が表示されます。実際は、203件目には3つに分かれるデータがあったとしても無視され、データは欠落してしまいます。
let
Source = Table.FromRows(
List.Repeat( {{"2016/11/8","FUR-BO-10001798","White", 261.96}} ,200) &
{
{"2016/11/8","FUR-CH-10000454","Red,Yellow", 731.94},
{"2016/6/12","OFF-LA-10000240","Black,Silver",14.62},
{"2015/10/11","FUR-TA-10000577","White,Black,Red",957.5775}
},
type table [OrderDate = text, ProductID = text, Color = text, Sales = Decimal.Type]
),
SplitColumnbyDelimiter =
Table.SplitColumn(
Source,
"Color",
Splitter.SplitTextByDelimiter(",", QuoteStyle.Csv),
{"Color.1", "Color.2"} // 2つの列に分割
)
in
SplitColumnbyDelimiter



Table.SplitColumn は、次の2種類の操作を行います。
- 一つの列を複数の列に分割する
- 複数の区切り文字で区切られた値を行に分割する
「詳細設定オプション」を開き「分割の方向」で「行」を選ぶと、新たな値にも柔軟に対応できます。
let
Source = Table.FromRows(
List.Repeat( {{"2016/11/8","FUR-BO-10001798","White", 261.96}} ,200) &
{
{"2016/11/8","FUR-CH-10000454","Red,Yellow", 731.94},
{"2016/6/12","OFF-LA-10000240","Black,Silver",14.62},
{"2015/10/11","FUR-TA-10000577","White,Black,Red",957.5775}
},
type table [OrderDate = text, ProductID = text, Color = text, Sales = Decimal.Type]
),
SplitColumnbyDelimiter =
Table.ExpandListColumn(
Table.TransformColumns(
Source,
{
{
"Color",
Splitter.SplitTextByDelimiter(",", QuoteStyle.Csv),
let
itemType = (type nullable text)
meta [Serialized.Text = true]
in
type {itemType}
}
}
),
"Color"
)
in
SplitColumnbyDelimiter

もしどうしても列へ分割するなら、将来を見越した最大数を「分割後の列数」に入力します。余分な列には null が入ります。
22.2.8. 列のマージ(Merging Columns)
複数列をマージする場合、自動生成コードはすべての列名を明記し、数値列を文字列に変換する処理も固定的に書かれます。これによって将来列構造が変わった場合に問題が発生する可能性が生じます。

let
Source = Table.FromRows(
{
{"2016/11/8","FUR-BO-10001798","White", 261.96},
{"2016/11/8","FUR-CH-10000454","Red,Yellow", 731.94},
{"2016/6/12","OFF-LA-10000240","Black,Silver",14.62},
{"2015/10/11","FUR-TA-10000577","White,Black,Red",957.5775}
},
type table [OrderDate = text, ProductID = text, Color = text, Sales = Decimal.Type]
),
MergedColumns =
Table.CombineColumns(
Table.TransformColumnTypes(
Source,
{ { "Sales", type text } }, // 数値列をテキストに変換
"ja-JP"
),
{"Color", "Sales"},
Combiner.CombineTextByDelimiter("", QuoteStyle.None),
"結合済み"
)
in
MergedColumns
「列のマージ」で自動生成されるコードには、マージする列が数値型だった場合、まずテキスト型に変換した後、結合します。数値や日付などの列をマージする場合、適切に変換が行われるようにコードの修正が必要になることがあります。
また、マージする列のリストを作成して処理を行う方法を使えば、列名がコード中に散らばることが無くなります。
let
Source = Table.FromRows(
{
{"2016/11/8","FUR-BO-10001798","White", 261.96},
{"2016/11/8","FUR-CH-10000454","Red,Yellow", 731.94},
{"2016/6/12","OFF-LA-10000240","Black,Silver",14.62},
{"2015/10/11","FUR-TA-10000577","White,Black,Red",957.5775}
},
type table [OrderDate = text, ProductID = text, Color = text, Sales = Decimal.Type]
),
// マージ対象の列
ColumnsToMerge = {"ProductID", "Color", "Sales"},
// 型変換
TypeChange =
Table.TransformColumnTypes(
Source,
List.Transform(
ColumnsToMerge,
each {_, type text}
),
"ja-JP"
),
// マージ
MergedColumns =
Table.CombineColumns(
TypeChange,
ColumnsToMerge,
Combiner.CombineTextByDelimiter(":", QuoteStyle.None),
"Merged"
)
in
MergedColumns
22.2.9. テーブル列の展開(Expanding Table Columns)
マージクエリやフォルダ内ファイルの結合などで「列の展開」を行うと、新たな列が後から増えても認識されず、結果セットに含まれないままになることがあります。
let
Source = Table.FromRows(
{
{"CA-2016-152156","2016/11/8", "FUR-BO-10001798",261.96,
Table.FromRecords({[City = "Henderson", Region = "South"]})},
{"CA-2016-152156","2016/11/8","FUR-CH-10000454",731.94,
Table.FromRecords({[City = "Henderson", Region = "South"]})},
{"CA-2016-138688","2016/6/12","OFF-LA-10000240",14.62,
Table.FromRecords({[City = "Los Angeles", Region = "West"]})},
{"US-2015-108966","2015/10/11","FUR-TA-10000577",957.57,
Table.FromRecords({[City = "Fort Lauderdale", Region = "South"]})}
},
type table [OrderID = Int64.Type, OrderDate = text, ProductID = text, Sales = Decimal.Type, Geography = table]
),
Expanded =
Table.ExpandTableColumn(
Source,
"Geography",
{"City", "Area"},
{"City", "Area"}
)
in
Expanded


以下の様に、入れ子になっているテーブルの項目名を引き出して処理を行います。
let
Source = Table.FromRows(
{
{"CA-2016-152156","2016/11/8", "FUR-BO-10001798",261.96,
Table.FromRecords({[City = "Henderson", Region = "South"]})},
{"CA-2016-152156","2016/11/8","FUR-CH-10000454",731.94,
Table.FromRecords({[City = "Henderson", Region = "South"]})},
{"CA-2016-138688","2016/6/12","OFF-LA-10000240",14.62,
Table.FromRecords({[City = "Los Angeles", Region = "West"]})},
{"US-2015-108966","2015/10/11","FUR-TA-10000577",957.57,
Table.FromRecords({[City = "Fort Lauderdale", Region = "South"]})}
},
type table [OrderID = Int64.Type, OrderDate = text, ProductID = text, Sales = Decimal.Type, Geography = table]
),
Expanded =
Table.ExpandTableColumn(
Source,
"Geography",
Table.ColumnNames( Source{0}[Geography] ),
Table.ColumnNames( Source{0}[Geography] )
)
in
Expanded

また、特定の列を指定して展開したい場合は、以下の様にします。
// 展開したい項目
SelectColumns = {"City", "Region"},
Expanded =
Table.ExpandTableColumn(
Source,
"Geography",
SelectColumns,
SelectColumns
)
逆に、特定の列を外したい場合は List.Difference を使います。
// 外したい項目
nonSelect = {"Country"},
Expanded =
Table.ExpandTableColumn(
Source,
"Geography",
List.Difference(
Table.ColumnNames( Source{0}[Geography] ),
nonSelect
),
List.Difference(
Table.ColumnNames( Source{0}[Geography] ),
nonSelect
)
)
22.2.10. 重複削除(Removing Duplicates)
Power Query は大文字小文字の区別を行いますが、Power BI では大文字小文字の区別を行いません。そのため、ディメンションテーブルを作成するためPower Queryで重複削除を行っても、Power BIで使用するとリレーションシップが正しく1対多にならない場合があります。
let
Source = Table.FromRows(
{
{"Apple"},
{"Apple"},
{"apple"},
{"Orange"}
}
),
RemovedDuplicates = Table.Distinct(Source)
in
RemovedDuplicates
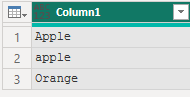
重複を取り除く際、トリミングや大文字小文字の整合を先に行わずに重複削除すると、Power BI でリレーションシップの整合性に問題が発生する恐れがあります。

Text.TrimやText.Lowerなどを事前に適用し、キー列を正規化した上で重複削除を行う必要があります。