Power Queryにおけるグルーピングは、データを指定した列の値ごとに整理・集約するための強力な手法です。この章では、基本的なグルーピング操作に加え、高度な利用方法やパフォーマンス向上に役立つ事例を詳しく解説します。
17.1 Table.Group
17.1.1 基本情報
グルーピングの基本は、指定した列を基準にデータをグループ化し、特定の操作(集計、フィルタリングなど)を実行することです。応用として、以下のようなシナリオで利用可能です。
- 期間ごとの売上や平均値の計算
- 地域やカテゴリごとのランキング作成
- データの圧縮による効率的な分析
- 詳細データの階層表示(例: 地域 > 商品カテゴリ > 売上)
特に、大量データの処理ではグルーピングを適切に活用することで、パフォーマンスの向上が期待できます。
- データの詳細情報が不要な場合、グルーピングを使ってデータ量を圧縮し、後続の処理を軽量化します。
- 不要な列を削除してグルーピングを行うことで、メモリ使用量を削減します。
- 大規模なデータセットを複数段階で処理する場合、途中でグルーピングを適用して中間データを作成すると、クエリの効率が向上します。
Table.Group(
table as table,
key as any,
aggregatedColumns as list,
optional groupKind as nullable number,
optional comparer as nullable function
) as table
key で示されたキー列によって table の行をグループ分けします。 key には、1 つの列名または列名のリストを指定できます。
Table.Group(
Table.FromRecords({
[CustomerID = 1, price = 20],
[CustomerID = 2, price = 10],
[CustomerID = 2, price = 20],
[CustomerID = 1, price = 10],
[CustomerID = 3, price = 20],
[CustomerID = 3, price = 5]
}),
"CustomerID",
{"total", each List.Sum([price]), type number}
)

17.1.2 groupKind
groupKindには、以下の GroupKind.Type が指定できます。
- GroupKind.Global: 全データを一度にグループ化します。データがソートされているかに関係なく、全体の中で一致する値を基準にグループ化を行います。
- GroupKind.Local: 隣接する行のみを基準にグループ化します。この場合、同じキーを持つ値が連続していなければ、異なるグループとして扱われます。
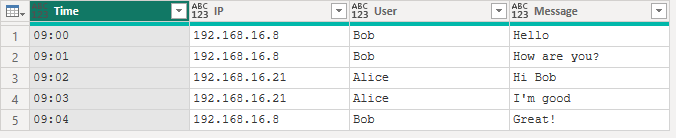
GroupKind.Local を指定すると、キーが連続していない場合、別のグループになってしまいます。以下の例では、あるチャットで、同じIPから連続で投稿しているものを抜き出しています。
let
ChatData = Table.FromRecords({
[Time = "09:00", IP = "192.168.16.8", User = "Bob", Message = "Hello"],
[Time = "09:01", IP = "192.168.16.8", User = "Bob", Message = "How are you?"],
[Time = "09:02", IP = "192.168.16.21", User = "Alice", Message = "Hi Bob"],
[Time = "09:03", IP = "192.168.16.21", User = "Alice", Message = "I'm good"],
[Time = "09:04", IP = "192.168.16.8", User = "Bob", Message = "Great!"]
}),
GroupedChats =
Table.Group(
ChatData,
{"IP"},
{
"Messages",
each Table.RowCount(_),
type number
},
GroupKind.Global
),
Repeats =
Table.SelectRows(
GroupedChats,
each [Messages] > 1
)
in
Repeats
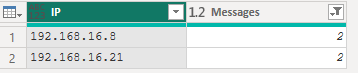
GroupKind.Global を指定した場合は、以下の様になります。

GroupKind.Local は、ストリーミング処理されるため、キー列が事前にソートされている場合は高速に処理されます。あるいは、連続したキーで集計を行うので、状態が変化するタイミングでの分析や特定の範囲のデータを抽出する際に効果的です。
17.1.3 comparer
comparer は、x と y という 2 つの指定された値が等しいかどうかをチェックし、それに基づいて0(一致)あるいは0以外(不一致)を返します。
大文字、小文字を区別しない場合は、Comparer.OrdinalIgnoreCaseを指定します。
let
Source = Table.FromRows(
{
{"A"},
{"APPLE"},
{"Apple"},
{"B"},
{"a"},
{"apple"}
},
type table [Value = text]
),
Grouped =
Table.Group(
Source,
{"Value"},
{"Count", List.Count, type number},
GroupKind.Global,
Comparer.OrdinalIgnoreCase
)
in
Grouped
let
Source = Table.FromRows(
{
{"A"},
{"APPLE"},
{"apple"},
{"B"},
{"a"},
{"apple"}
},
type table [Value = text]
),
Grouped =
Table.Group(
Source,
{"Value"},
{"Count", List.Count, type number},
GroupKind.Global,
Comparer.FromCulture("ja-JP", true) // 第2引数trueは大文字・小文字の区別をしない
)
in
Grouped

Value.Compare 関数は、2つの引数が一致する場合は 0 、それ以外は -1 か 1 を返すので、これを使用してカスタム関数を作ります。
let
// 元のテーブル
Source = Table.FromRows(
{
{"Yamaha", "YZF-R1"},
{"Yamaha", "YZF-R6"},
{"Kawasaki", "Ninja 400"},
{"Yamaha", "MT-10"},
{"Yamaha", "TMAX"},
{"Kawasaki", "Ninja 650"},
{"Yamaha", "MT-09"}
},
type table [Manufacturer = text, Model = text]
),
// メーカー名とモデル名の頭2文字でグループ化
GroupedTable = Table.Group(
Source,
{"Manufacturer", "Model"},
{
"Count",
List.Count,
type number
},
GroupKind.Global,
// カスタム関数
(x, y) =>
Value.Compare(
x[Manufacturer] & Text.Start(x[Model], 2),
y[Manufacturer] & Text.Start(y[Model], 2)
)
)
in
GroupedTable

17.1.4 高度なグルーピングテクニック
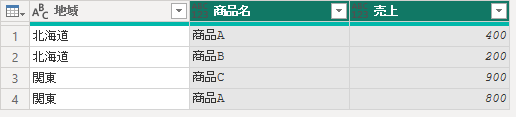
地域ごとの売上トップNのデータを抽出します。
let
Source = Table.FromRows(
{
{"北海道", "商品A", 200},
{"北海道", "商品A", 400},
{"北海道", "商品B", 200},
{"北海道", "商品C", 100},
{"関東", "商品A", 800},
{"関東", "商品B", 400},
{"関東", "商品B", 600},
{"関東", "商品C", 900}
},
type table [地域 = text, 商品名 = text, 売上 = Int64.Type]
),
Group =
Table.Group(
Source,
{"地域"},
{
"トップ商品",
each
Table.FirstN(
Table.Sort(_, {{"売上", Order.Descending}})
, 2
),
type table
}
),
#"Expanded {0}" = Table.ExpandTableColumn(
Group,
"トップ商品",
{"商品名", "売上"},
{"商品名", "売上"}
)
in
#"Expanded {0}"
17.2 Table.Partition
17.2.1 基本情報
Table.Partition は、大きなテーブルを複数の小さなテーブル(パーティション)に分割するために使用されます。
Table.Partition(
table as table,
column as text,
groups as number,
hash as function
) as list
-
table: 分割する元のテーブル。 -
column: パーティションの基準となる列名。 -
groups: 分割するテーブルの数(整数値)。 -
hash: 分割ロジックを指定する関数。この関数は行を受け取り、対応するパーティションのインデックス(0 からgroups - 1)を返します。
戻り値: 指定された数のパーティション(テーブル)のリスト。
17.2.2 数値列で分割
元のテーブルの "ID" 列を基に、3つのパーティションに分割します。
let
SourceTable = Table.FromRecords(
{
[ID = 1, Name = "Alice"],
[ID = 2, Name = "Bob"],
[ID = 3, Name = "Charlie"],
[ID = 4, Name = "Diana"],
[ID = 5, Name = "Eve"]
},
type table [ID = number, Name = text]
),
Partitions = Table.Partition(
SourceTable,
"ID",
3,
each Number.Mod(_, 3)
)
in
Partitions

-
Number.Mod(_, 3)は、IDの値を 3 で割った余りを計算します。 - この余りに基づいてテーブルが分割されます。
結果:
- パーティション 0: ID = 3
- パーティション 1: ID = 1, ID = 4
- パーティション 2: ID = 2, ID = 5
17.2.3 地域別にデータを分割
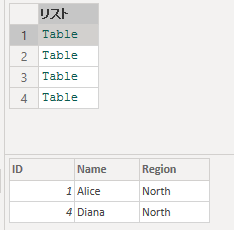
地域列 (Region) を基に、4つの地域データを分割します。
let
SourceTable = Table.FromRecords(
{
[ID = 1, Name = "Alice", Region = "North"],
[ID = 2, Name = "Bob", Region = "East"],
[ID = 3, Name = "Charlie", Region = "West"],
[ID = 4, Name = "Diana", Region = "North"],
[ID = 5, Name = "Eve", Region = "South"]
},
type table [ID = number, Name = text, Region = text]
),
// hash カスタム関数
RegionHash = (region) =>
List.PositionOf(
{"North", "East", "South", "West"},
region
),
Partitions = Table.Partition(
SourceTable,
"Region",
4,
each RegionHash(_)
)
in
Partitions
-
RegionHash関数で地域ごとのインデックスを指定します。 -
"North"はパーティション 0、"East"はパーティション 1 として分類されます。
結果:
- パーティション 0: North 地域のデータ
- パーティション 1: East 地域のデータ
- パーティション 2: South 地域のデータ
- パーティション 3: West 地域のデータ
17.2.4 日付範囲で分割
日付列を基に、月ごとにデータを分割します。
let
SourceTable = Table.FromRecords(
{
[ID = 1, Date = #date(2023, 1, 10), Value = 100],
[ID = 2, Date = #date(2023, 1, 15), Value = 200],
[ID = 3, Date = #date(2023, 2, 20), Value = 300],
[ID = 4, Date = #date(2023, 3, 25), Value = 400]
},
type table [ID = number, Date = date, Value = number]
MonthHash = (date) => Date.Month(date) - 1,
Partitions = Table.Partition(
SourceTable,
"Date",
12, // 各月ごとのパーティション
each MonthHash(_)
)
in
Partitions
結果:
- パーティション 0: 1月のデータ
- パーティション 1: 2月のデータ
- パーティション 2: 3月のデータ
- パーティション 3~11: 4~12月のデータ(null)

17.2.5 留意点
-
パーティション数の設定:
適切なパーティション数を選択することで、処理の分散効果を最大化できます。過剰な分割は逆効果になる場合があります。 -
カスタムハッシュ関数の設計:
適切なハッシュ関数を使用することで、各パーティションに均等なデータ分布を実現できます。 -
分割後の操作:
パーティション化されたデータを並列処理することで、特に大規模データセットにおける処理効率が向上します。
使用上の注意
-
リスト形式の出力:
Table.Partitionはリストを返すため、データを操作する場合はリストから適切にアクセスする必要があります。 - 正確なハッシュ計算: ハッシュ関数の設計を誤ると、不均等なパーティション分布が発生し、処理効率が低下する可能性があります。
17.3 Table.AddFuzzyClusterColumn
17.3.1 基本情報
Table.AddFuzzyClusterColumn は、データのあいまい一致に基づいてクラスタリングを行い、新しい列にその結果を追加します。この機能は、類似した値を同一グループとして扱う際に役立ちます。たとえば、名前や住所などのデータで微妙に異なる表記が存在する場合でも、同一の値として処理できるようになります。
Table.AddFuzzyClusterColumn(
table as table,
columnName as text,
newColumnName as text,
optional options as nullable record
) as table
-
table: 元のテーブル。 -
columnName: クラスタリングの基準となる列の名前。 -
newColumnName: クラスタリング結果を格納する新しい列の名前。 -
options: あいまい一致の設定を指定するオプション(省略可能)。
主要なオプション
-
IgnoreCase- 大文字と小文字を区別しない場合は
true(既定値)。 - 例: "John" と "john" を同一視します。
- 大文字と小文字を区別しない場合は
-
IgnoreSpace- 空白を無視する場合は
true(既定値)。 - 例: "John" と "Jo hn" を同一視します。
- 空白を無視する場合は
-
Culture- 比較に使用するカルチャ(ロケール)を指定します。たとえば、
"en-US"や"ja-JP"を指定できます。
- 比較に使用するカルチャ(ロケール)を指定します。たとえば、
-
Threshold- クラスタリングの感度を指定します(
0~1の範囲)。 - 値が小さいほど緩やかな一致条件、値が大きいほど厳密な一致条件になります。
- 既定値は
0.8。
- クラスタリングの感度を指定します(
-
TransformationTable- あいまい一致を補助するための変換ルールを指定するテーブル。変換元と変換先のペアを持つ列で構成されます。
以下の例は、従業員のLocationの代表値を検索します。
Table.AddFuzzyClusterColumn(
Table.FromRecords(
{
[EmployeeID = 1, Location = "Seattle"],
[EmployeeID = 2, Location = "seattl"],
[EmployeeID = 3, Location = "Vancouver"],
[EmployeeID = 4, Location = "Seatle"],
[EmployeeID = 5, Location = "vancover"],
[EmployeeID = 6, Location = "Seattle"],
[EmployeeID = 7, Location = "Vancouver"]
},
type table [EmployeeID = nullable number, Location = nullable text]
),
"Location",
"Location_Cleaned",
[IgnoreCase = true, IgnoreSpace = true, Threshold=0.8]
)

seattl は Seattle に、vancover は Vancouver に変換されています。
17.3.2 名前のクラスタリング
以下のデータを基に、名前の類似性に応じてクラスタリングを行います。
let
Source = Table.FromRecords({
[Name = "John", Value = 100],
[Name = "Jon", Value = 200],
[Name = "Jonh", Value = 150],
[Name = "Joan", Value = 300],
[Name = "Jean", Value = 400]
}),
Clustered = Table.AddFuzzyClusterColumn(
Source,
"Name",
"Cluster"
)
in
Clustered
結果:
-
"John","Jon","Jonh"が同一クラスタに分類されます。 -
"Joan"や"Jean"は別クラスタとなります。
17.3.3 大文字小文字を無視したクラスタリング
オプション IgnoreCase を使用して、大文字と小文字を無視してクラスタリングを行います。
let
Source = Table.FromRecords(
{
[Name = "Alice", Value = 100],
[Name = "alice", Value = 150],
[Name = "ALICE", Value = 200],
[Name = "Alicia", Value = 250]
},
type table [Name = text, Value = number]
),
Clustered = Table.AddFuzzyClusterColumn(
Source,
"Name",
"Cluster",
[IgnoreCase = true]
)
in
Clustered
結果:
-
"Alice","alice","ALICE"が同一クラスタに分類されます。

17.3.4 TransformationTable を使ったルールベースのクラスタリング
変換ルールを指定してクラスタリングを行います。
let
Source = Table.FromRecords(
{
[Name = "Bob", Value = 100],
[Name = "Robert", Value = 200],
[Name = "Rob", Value = 150],
[Name = "Bobby", Value = 300]
},
type table [Name = text, Value = number]
),
TransformationRules = Table.FromRecords(
{
[From = "Bob", To = "Robert"],
[From = "Rob", To = "Robert"],
[From = "Bobby", To = "Robert"]
},
type table [From = text, To = text]
),
Clustered = Table.AddFuzzyClusterColumn(
Source,
"Name",
"Cluster",
[TransformationTable = TransformationRules]
)
in
Clustered
結果:
-
"Bob","Rob","Bobby"が"Robert"のクラスタに分類されます。

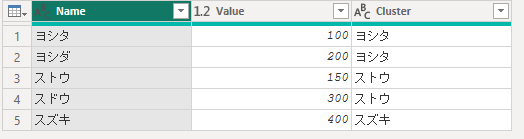
17.3.5 日本語データでのクラスタリング
以下のデータで、日本語の表記揺れを考慮したクラスタリングを行います。
let
Source = Table.FromRecords(
{
[Name = "ヨシタ", Value = 100],
[Name = "ヨシダ", Value = 200],
[Name = "ストウ", Value = 150],
[Name = "スドウ", Value = 300],
[Name = "スズキ", Value = 400]
},
type table [Name = text, Value = number]
),
Clustered = Table.AddFuzzyClusterColumn(
Source,
"Name",
"Cluster",
[Culture = "ja-JP", IgnoreCase = true, Threshold = 1.0]
)
in
Clustered
結果:
-
"ヨシタ"と"ヨシダ","ストウ"と"スドウ"が同一クラスタに分類されます。
17.3.6 注意点とベストプラクティス
-
パフォーマンスに注意:
- 大規模データセットに対して
Table.AddFuzzyClusterColumnを使用すると、計算に時間がかかる場合があります。条件を絞ったり、変換ルールを明確に設定して効率化を図ることを推奨します。
- 大規模データセットに対して
-
感度の調整:
-
Thresholdオプションの値を調整することで、クラスタリングの厳密さを制御できます。最適な値を選ぶことで、必要な一致結果を得ることが可能です。
-
-
変換ルールの活用:
-
TransformationTableを活用することで、より明確で正確なクラスタリングが可能です。特に、日本語の表記揺れや漢字とひらがなの混在するデータに有効です。
-
-
カルチャ(Culture)の選定:
- 文字列比較のカルチャ設定を適切に指定することで、地域ごとの言語特性に対応した一致条件を実現できます。