この章では、Power Queryを用いたクエリのパフォーマンス最適化について学びます。大規模データを効率的に処理するために、クエリステップの順序、データソースのフォールディング活用、バッファリングの使用、不要なステップの削減など、具体的なテクニックとベストプラクティスを紹介します。これにより、クエリの実行速度を改善し、効率的なデータ変換が実現できます。
4.1. メモリの制限と調整
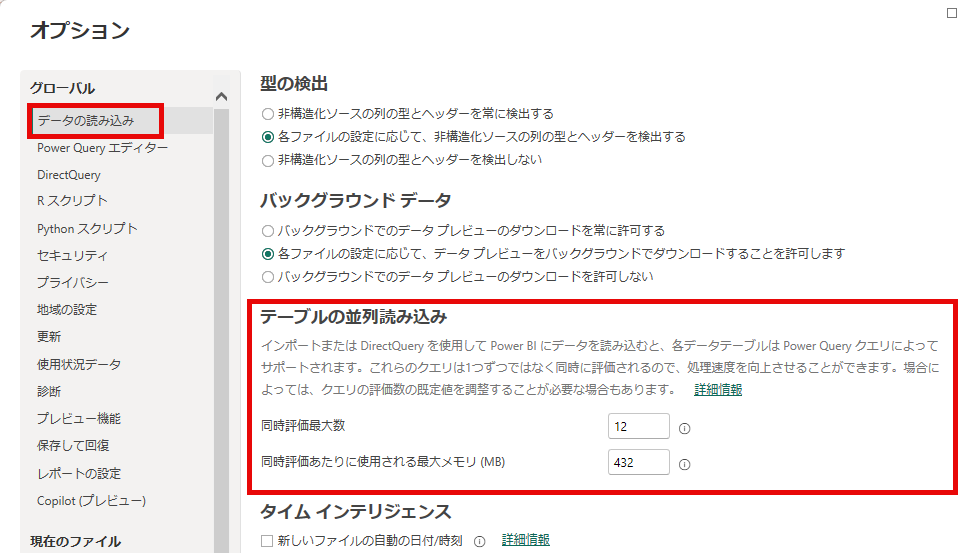
Power BI Desktop のオプションには、テーブルの並列読み込みの同時評価最大数と最大メモリを設定できます。同時評価最大数には,使用しているマシンの最大論理プロセッサ数、最大メモリは既定では432MBとなっています。
使用するメモリの最大値は、使用しているマシンのRAMの90%を同時評価最大数で割った値を設定するのがベストプラクティスになります。
4.2. クエリフォールディングの理解と活用
クエリフォールディングとは、クエリの評価をデータベース側で実行させる機能です。これにより、Power Queryの操作をサーバーで処理し、データの取得を必要最小限にすることでメモリの使用量を減らし、パフォーマンスを向上させます。
4.2.1. クエリフォールディングの仕組み
クエリフォールディングとは、Power Queryで行ったフィルタリングやソートなどの操作がサーバー側でSQLクエリとして処理されることを指します。これにより、データの取得量を減らし、パフォーマンスが向上します。
クエリフォールディングは、SQL ServerやAzure SQL Databaseなど、一部のリレーショナルデータベースでサポートされています。しかし、Excelファイル、CSV、Webソースなどのデータソースではサポートしていません。
4.2.2. クエリフォールディングの確認と維持方法
Power Queryの「診断」ツールを用いて、クエリフォールディングが適用されているか確認できます。
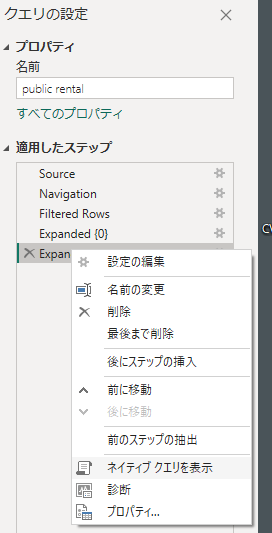
Power Queryコネクタは、全てのMコードをデータソースクエリに変換することはできず、一部の操作はクエリフォールディングを壊します。クエリフォールディングが無効化される原因(例: 非サポート操作の使用)を把握し、できるだけクエリフォールディングを維持するようにします。
また、フォールディングを維持するために、ステップの順序を変更し、フィルタリングや列選択のクエリフォールディングが有効な操作を早い段階で行うと効果的です。
以下の操作はクエリフォールディングが行われます。
- 列の選択、削除、名前変更、または並べ替え
- SELECT句で使用できるテキスト変換、数学演算、データ型変換などの基本的ロジック
- SQLの
ORDER BYに対応する列のソート - SQLの
WHEREに対応する行のフィルタリング - SQLの
GROUP BYに対応するデータのグループ化 -
UNIONALL演算子を使用するクエリの追加 - SQLの
PIVOTUNPIVOTに対応するデータのピボットおよびアンピボット
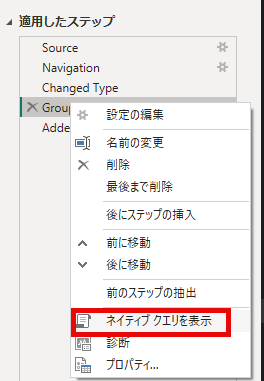
クエリフォールディングが行われていると、「ネイティブクエリを表示」が使える。
以下の操作はクエリフォールディングを壊します。
- indexまたはranking列の追加
- 異なるデータソースの結合または追加
- 異なるプライバシーレベルを持つクエリの結合
- データソースが同等の操作を持たない場合
例えば転置、下位N行の保持、文字列の各単語の最初の文字を大文字にするなど -
Table.BufferやList.BufferおよびBinary.Buffer関数
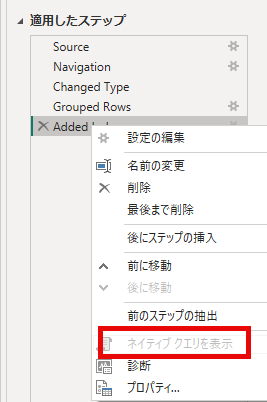
クエリフォールディングが壊れると、「ネイティブクエリを表示」がグレーアウトする。
4.2.3. クエリフォールディングでの注意
Power Queryに記述された変換が、クエリフォールディングによってデータソースで実行される場合、異なる結果が返されることがあります。
- Power Queryでは、左外部ジョインを行う場合、2つのnull値を等価とみなしますが、多くのデータベースシステムでは、null値は等しいとみなされません。
- Power Queryでは、大文字小文字を区別します。しかし、データベースの多くはテキストのフィルタリング時に大文字小文字を無視するため、異なる結果を返す可能性があります。
このような場合、Table.StopFolding 関数を使用して、意図的にクエリフォールディングさせないという手段があります。
4.3. バッファリングとストリーミングの違い
Power Queryでは、データを一時的にメモリに保持する「バッファリング」と、データを直接処理する「ストリーミング」があります。ここでは、それぞれの利点と使い分け方について学びます。
4.3.1. バッファリングの概要
バッファリングでは、一度データをメモリに保持し、そこから変換処理を行います。これにより、処理の途中でデータが変わらない安定性を保つことができます。
4.3.2. ストリーミング処理
ストリーミングは、データを一度にメモリに展開するのではなく、必要に応じて逐次的に処理する方法です。メモリ消費を抑え、特に大規模データやファイルベースのデータ(CSVやExcel)に対して有効です。
しかし、データのソートやピボットなどで、クエリフォールディングが有効になっていない場合、全体を読み込んでから処理を行っています。また、データを何度も読み込むような処理は、処理速度を極端に増加させてしまいます。
4.4. クエリステップの最適化と順序の工夫
クエリステップの順序は、パフォーマンスに大きな影響を与えます。このセクションでは、クエリを効率化するためのステップ順序の工夫について解説します。
4.4.1. 行のフィルタリングの早期実行
クエリの初期段階で不要なデータを除去することで、後続のステップで処理するデータ量を減らし、パフォーマンスを向上させます。
// クエリの早い段階でフィルタリングを行う例
let
Source = Sql.Database("ServerName", "DatabaseName"),
SalesTable = Source{[Schema="dbo", Item="Sales"]}[Data],
// クエリの初期段階でデータをフィルタリング
FilteredData = Table.SelectRows(SalesTable, each [Category] = "Electronics"),
// 後続のステップで他の操作を実施
AddedYearColumn = Table.AddColumn(FilteredData, "Year", each Date.Year([SalesDate]), Int64.Type)
in
AddedYearColumn
4.3.2. 列の選択と削除
データの取り込み後、すぐに不要な列を削除することで、後続のステップで取り扱うデータ量を減らし、パフォーマンスを最適化します。
// 取り込み後すぐに不要な列を削除する例
let
Source = Sql.Database("ServerName", "DatabaseName"),
SalesTable = Source{[Schema="dbo", Item="Sales"]}[Data],
// 不要な列を早期に削除して処理効率を向上
CleanedTable = Table.RemoveColumns(SalesTable, {"UnnecessaryColumn1", "UnnecessaryColumn2"})
in
CleanedTable