はじめに
ループで同じ構造のデータから特徴量を効率的に生成してみます。
工場や製品など同じ形式のデータから同じ特徴量をつくりたいことがあります。その場合にストリームを複数作る事もできますが、たくさんある場合は大変ですし、修正をする時に修正箇所がその分増えてしまいます。
ここではこの記事で作った特徴量を、ループを使って、複数の工場に対しても同様に生成していきます。
この記事はSPSS秋のユーザーイベント2024の東日本旅客鉄道の堀様のご講演の「ものづくり領域で活かされるSPSSの今とこれから-2異常検知と自動化」でご紹介したデモ②「ループ処理による効率化」の解説です。
『実践! 異常検知と故障予測―IBM SPSS ModelerによるIoT時系列データ活用』(東京図書)の「1-3 実務で使える異常検知」(p.78-96)の一部を簡略化してご紹介しています。詳しい内容をお知りになりたい方はぜひ書籍もご参照いただければと思います。
■テスト環境
- Modeler 18.5
- Windows 11 64bit
テストデータ
テストデータは、以下のような時系列データです。「第一工場」と「第二工場」の2つの工場のデータが一つのファイルに入っています。
「製品切替Bボタン」が押されてから「温度」が210度にあがるところまでの3分という時間を特徴量としてそれぞれの工場分、取り出したいと思います。

工場名のインスタンス化
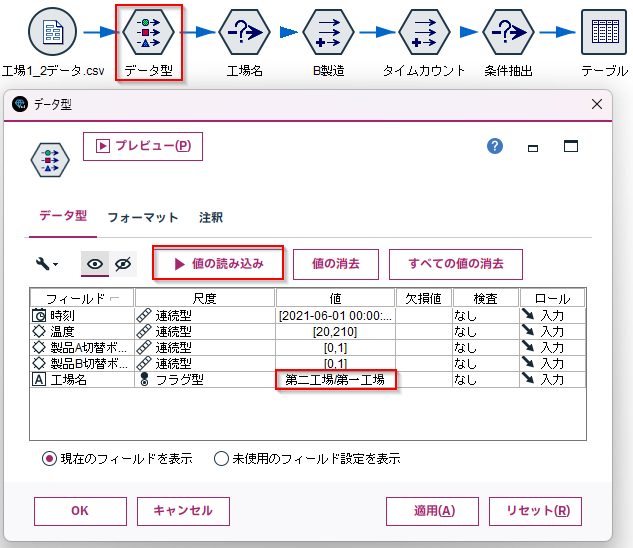
「データ型ノード」で「値の読み込み」を行って、「工場名」をインスタンス化しておきます。これによって「工場名」には「第一工場」と「第二工場」のデータが入っていることが認識できます。
工場名の絞り込み
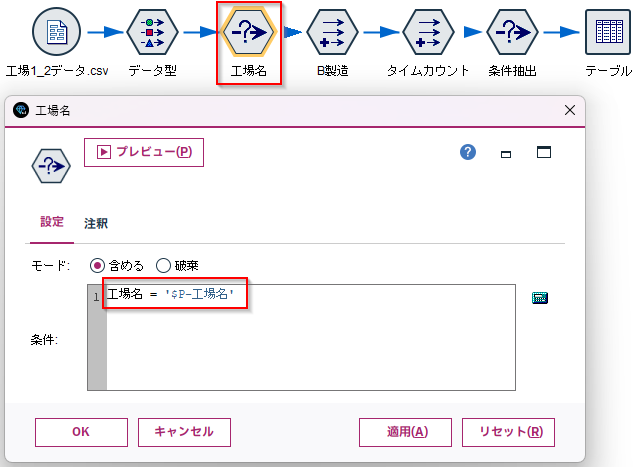
「条件抽出ノード」をつなぎます。
「条件」に「工場名 = '$P-工場名'」を設定します。
「工場名」はパラメータで与えるという設定です。
残りの処理はこの記事で作った処理です。「製品切替Bボタン」が押されてから「温度」が210度にあがるところまでの時間が3レコード抽出されます。
パラメータの設定
「ツール」_「ストリームのプロパティー」_「パラメータ」でパラメータの設定を開きます。
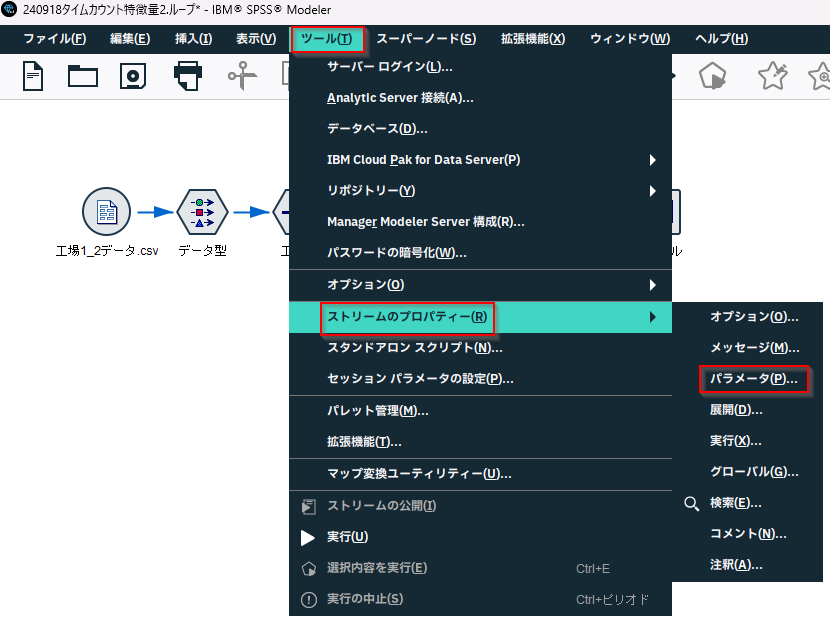
以下の設定でパラメータ「$P-工場名」を作ります。
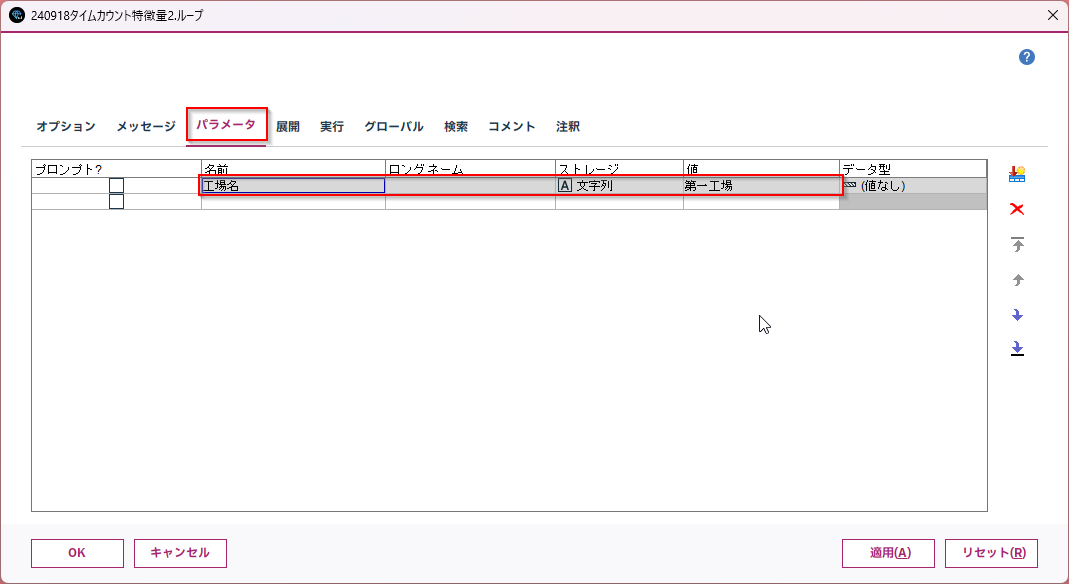
名前:「工場名」
ストレージ:文字列
値:「第一工場」←デフォルト値が「第一工場」であるという意味です。
「テーブルノード」を右クリックして、実行してみます。

「工場1」の特徴量を抽出できました。

ループの設定
次にループを使って、このパラメーターに自動的に「第一工場」と「第二工場」の値を入れて実行します。
「ツール」_「ストリームのプロパティー」_「実行」で実行の設定を開きます。
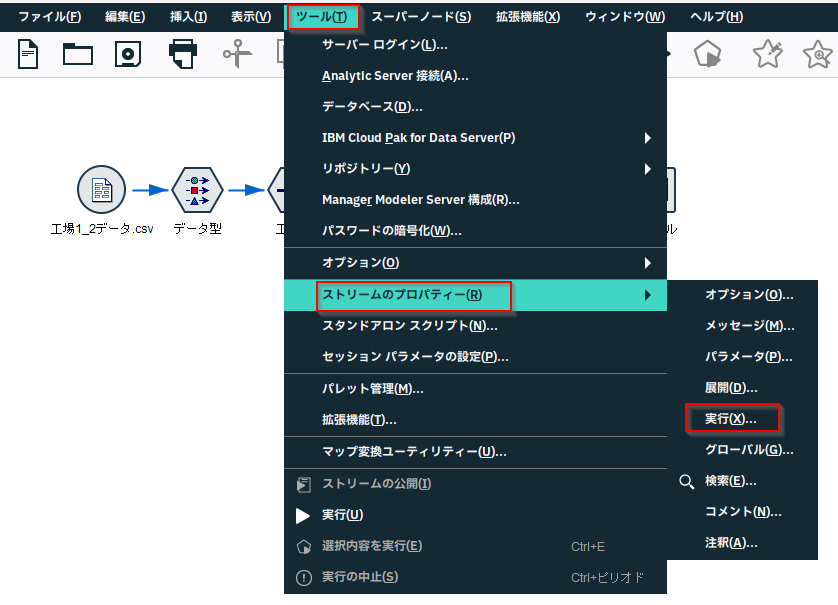
「ループ」のオプションを選び、「ループ」のタブを選び、「反復キー」をクリックします。
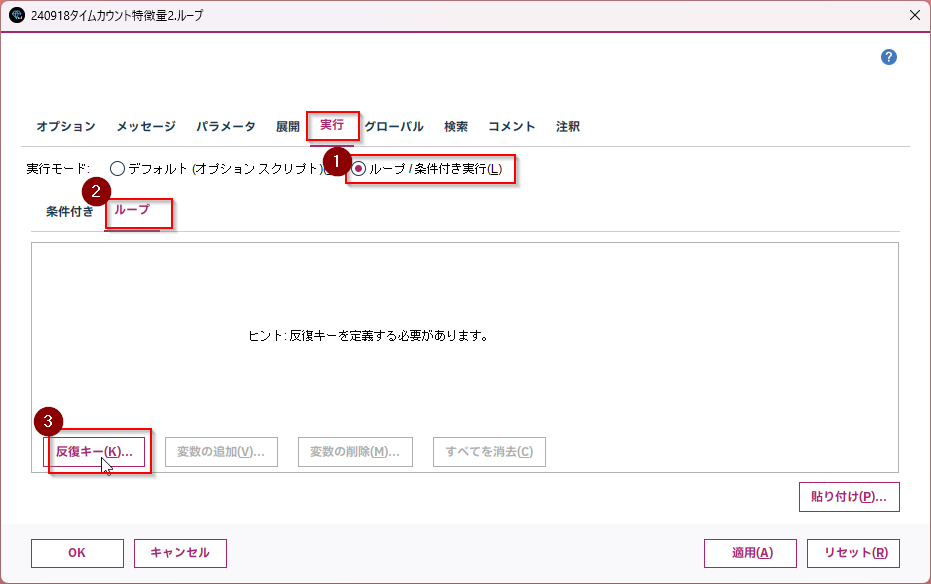
以下の設定で反復キーを設定します。。
反復対象:「ストリームパラメータ - 値」←パラメータの値を変えながらループするという意味です。
パラメータ:「工場名」
ノード:「工場名:select」←工場名の条件抽出ノードです。
フィールド:「工場名」
値:「第一工場」と「第二工場」←データ型ノードでインスタンス化していたので値を選ぶことができます。
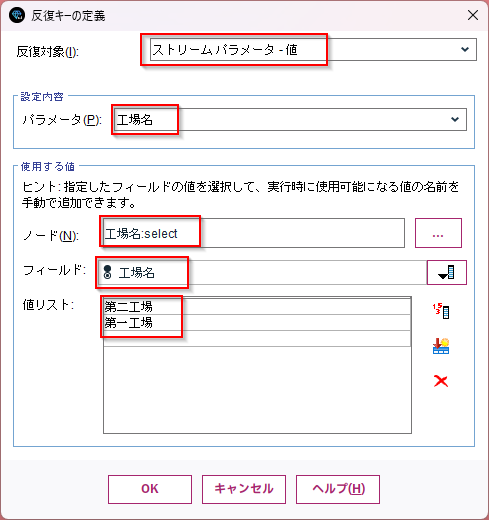
以下のように「第一工場」と「第二工場」がパラメータとして与えられるループの設定ができます。
「OK」で確定させてください。
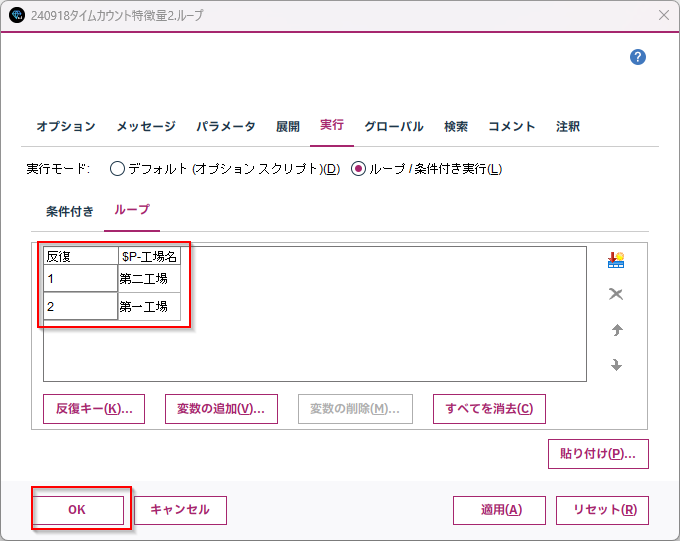
結果
ループの対象になった工場名の条件抽出ノードにループのマークがついています。
「現在のストリームを実行」で実行します(選択内容の実行」ではありません)。
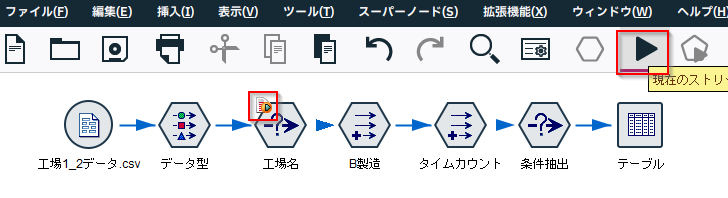
ストリームが二回実行されて、テーブルノードの結果が2つ出てきます(重なって出てくるのでウインドウは後ろに隠れていることがあります)。結果は以下のように「第一工場」と「第二工場」の特徴量が抽出されています。
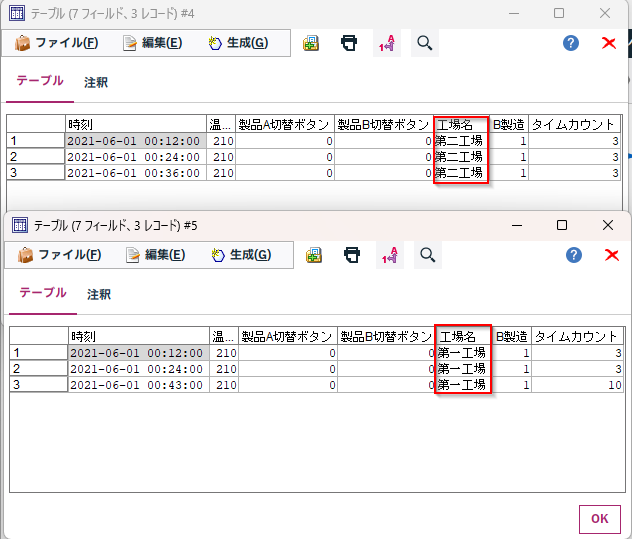
ループでパラメーターを与えて特徴量を生成する事ができました。
サンプル
サンプルストリーム
サンプルデータ
参考
20241127SPSS秋02_東日本旅客鉄道 堀様資料
『実践! 異常検知と故障予測―IBM SPSS ModelerによるIoT時系列データ活用』(東京図書)
SPSS Modelerで時系列データから「時間」の特徴量を作る