SPSS Modelerの平均値ノードで複数カテゴリの複数フィールドの平均を比較します。
Modelerの「平均値」ノードを使うと複数カテゴリで複数フィールドの平均値を比較して、特徴量を重要度順に並べ替えることができます。これはとても強力なので例をご紹介します。
以下のようなデータを用意しました。
各顧客に対して、アクセサリの購入金額合計などのさまざまな集計がなされています。
「マネタリー5」というフラグ列があり、これは購入金額が全体の上位20%の優良顧客であるということを示しています。
この優良顧客とそうでない顧客でどんな差があるかどうかを「平均値」ノードを使って調べてみます。

「フィールド内のグループ間で比較」を選び「グループ化フィールド」に比較したいカテゴリ列を指定します。この例では「マネタリー5」です。
「テストフィールド」に比較したい値を設定します。ここではすべての数値列を選びました。この中から特に平均値の差を注目すべき特徴量を探します。
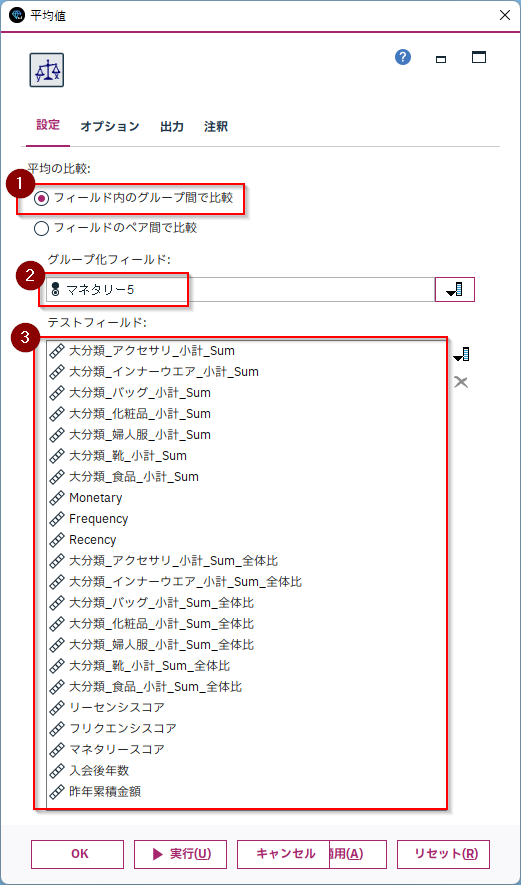
表示を「詳細」にして、「F検定」の降順で並べ替えます。
そうするとF値が大きい順に並びますので、優良顧客とそれ以外で平均値の違いが顕著な順に特徴量が並べ替えられます。(「重要度」で並べ替えても本来は同じ順序になるべきなのですが、p値がとても小さいと丸められてしまって順位がつかなくなるのでF値で並べ替えるのがコツです)
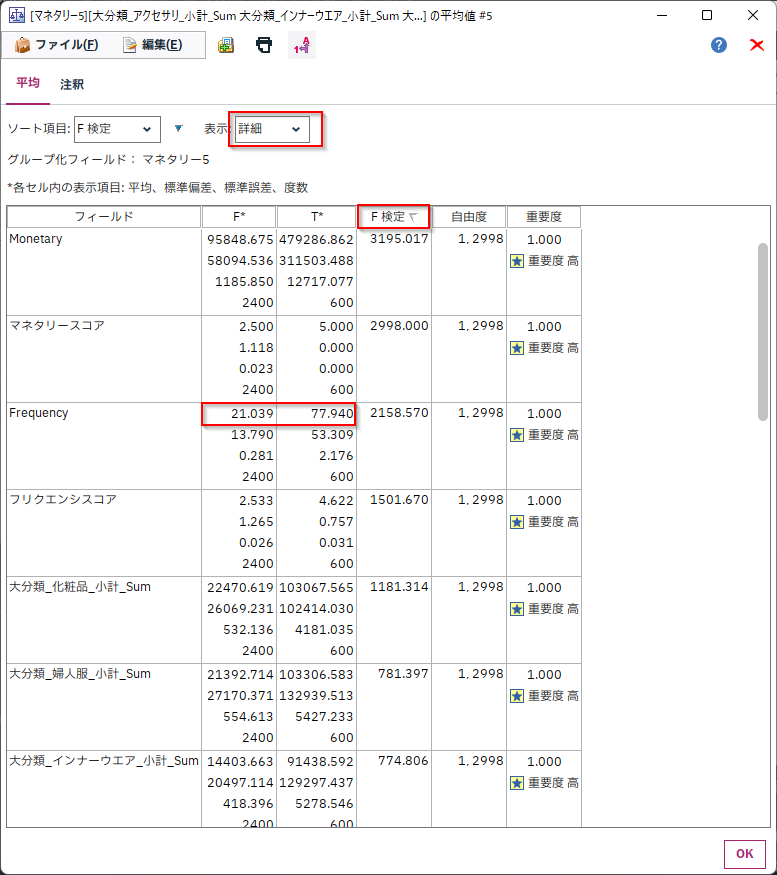
中身をみてみると、「Monetary」や「マネタリースコア」が最上位に来ています。これは「購入金額が全体の上位20%の優良顧客」が「マネタリー5」=Trueなのでチートになり、当たり前の結果です。
次点の「Frequency」は優良顧客は77.9回、そうでない顧客は21回なので大きな差があることがわかります。
このようにチートも含まれますが、たくさんの特徴量候補があるときに、とりあえず、すべての特徴量から重要そうな特徴量を知りたいときにとても便利です。
ちなみに「特徴量選択」ノードでも、目的変数がカテゴリ型で説明変数が数値型の場合は、同様のロジックを使っています。ただ「平均値」ノードの場合は各カテゴリの平均値も表示されるので、具体的な値で各カテゴリでどちらがどれだけ大きいのか小さいのかも比べることができるのがメリットです。
サンプル
サンプルは以下に置きました。
サンプルストリーム
利用データ
■テスト環境
Modeler 18.4
Windows 10 64bit
Python 3.8.10
pandas 1.4.1
scipy 1.8.0
statsmodels 0.13.2
参考
SPSS Modeler ノードリファレンス 6-9 平均値 - Qiita
SPSS Modelerの平均値ノードをpythonに書き換える - Qiita
上の記事の3mを抜粋しました。