はじめに
Snowflake / dbt 初心者の私が、Snowflake / dbt を使って、「第2回 国土交通省 地理空間情報データチャレンジ」で環境構築から初提出まで1日 (といいつつ実質数時間) で実施した話です。
ハンズオンになかった?コードも補完し、一通りベースラインの提出までできるコードをまとめていますので、主に「まだ本データチャレンジに本格的に参加できていないが残り一週間で頑張りたい!」方向けの記事となります。
本チャレンジの高スコア解法や詳細なデータ分析結果については言及しませんので、予めご了承ください。
※ 個人的にずーっと Snowflake / dbt やりたいと言いつつ全然時間が取れなかったので、正月ボケ防止も兼ねてのエクササイズ的なサムシングです。
第2回 国土交通省 地理空間情報データチャレンジとは
国土交通省が整備するオープンデータ「国土数値情報」と民間企業のデータを活用し、不動産の売買価格の予測モデルを構築するコンペティションです。
提出締め切りは2026年1月9日 23:59までで、ちょうど残り一週間です。
詳細は公式サイトを見ていただければと思います。
開会式や勉強会動画もありますのでぜひご覧ください。
Snowflake / dbtとは
この記事を見る方には釈迦に説法となりそうなので割愛します。
Snowflake x dbt ハンズオン
2025年12月3日に実施された以下ハンズオンに従って実施します。
1. サインアップ後、app.snowflake.com へサインイン

かっこいいですね。
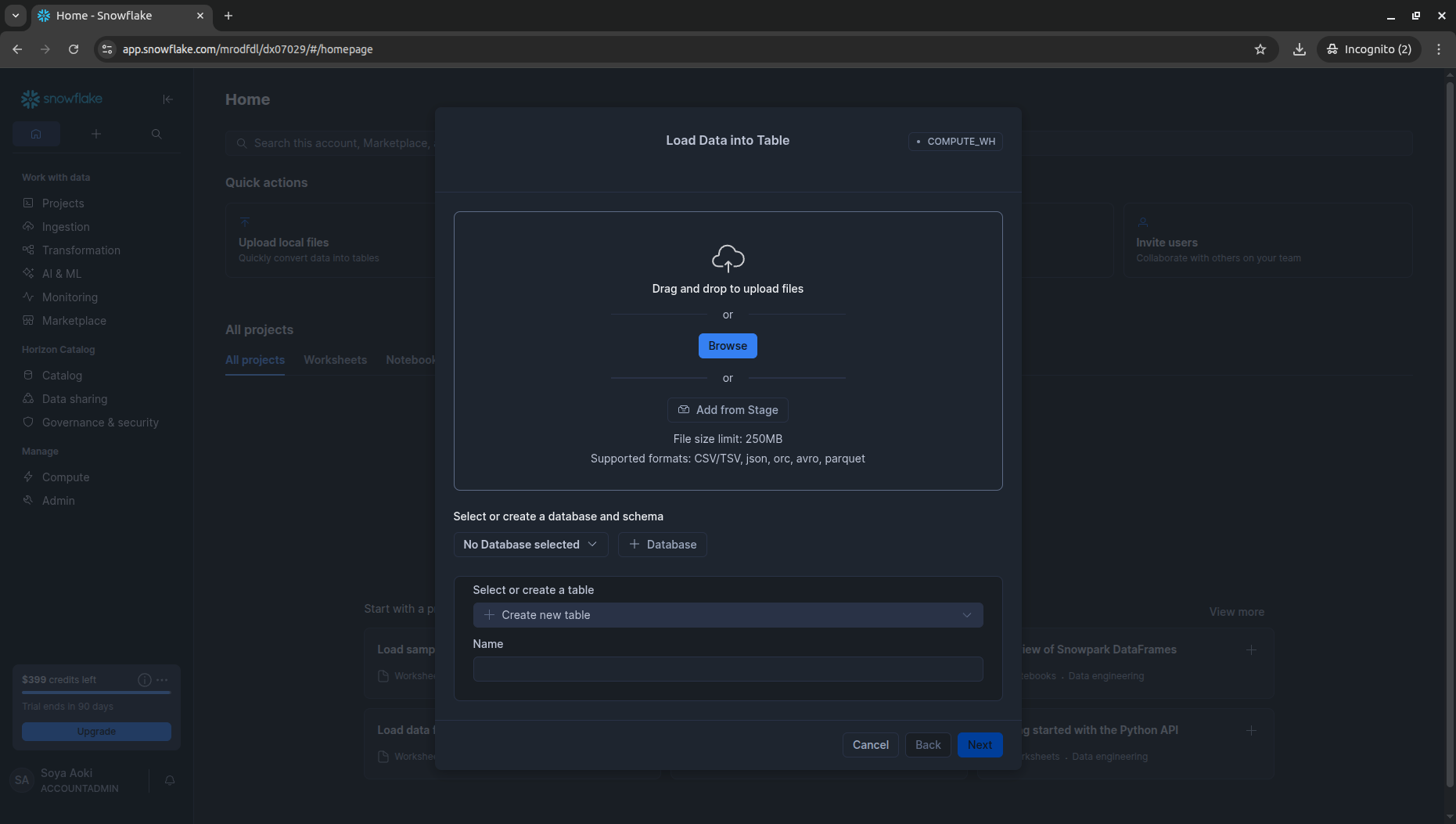
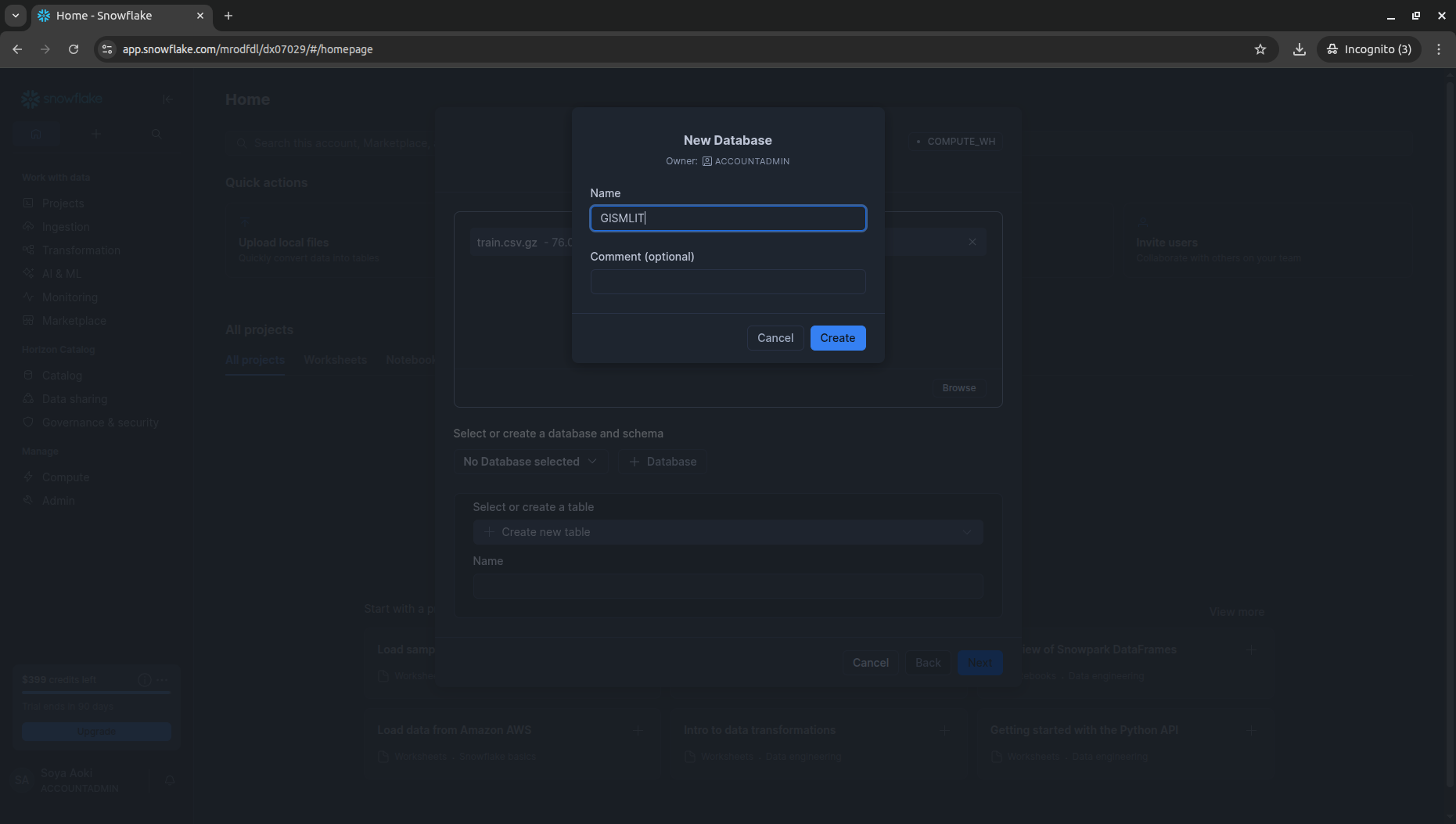
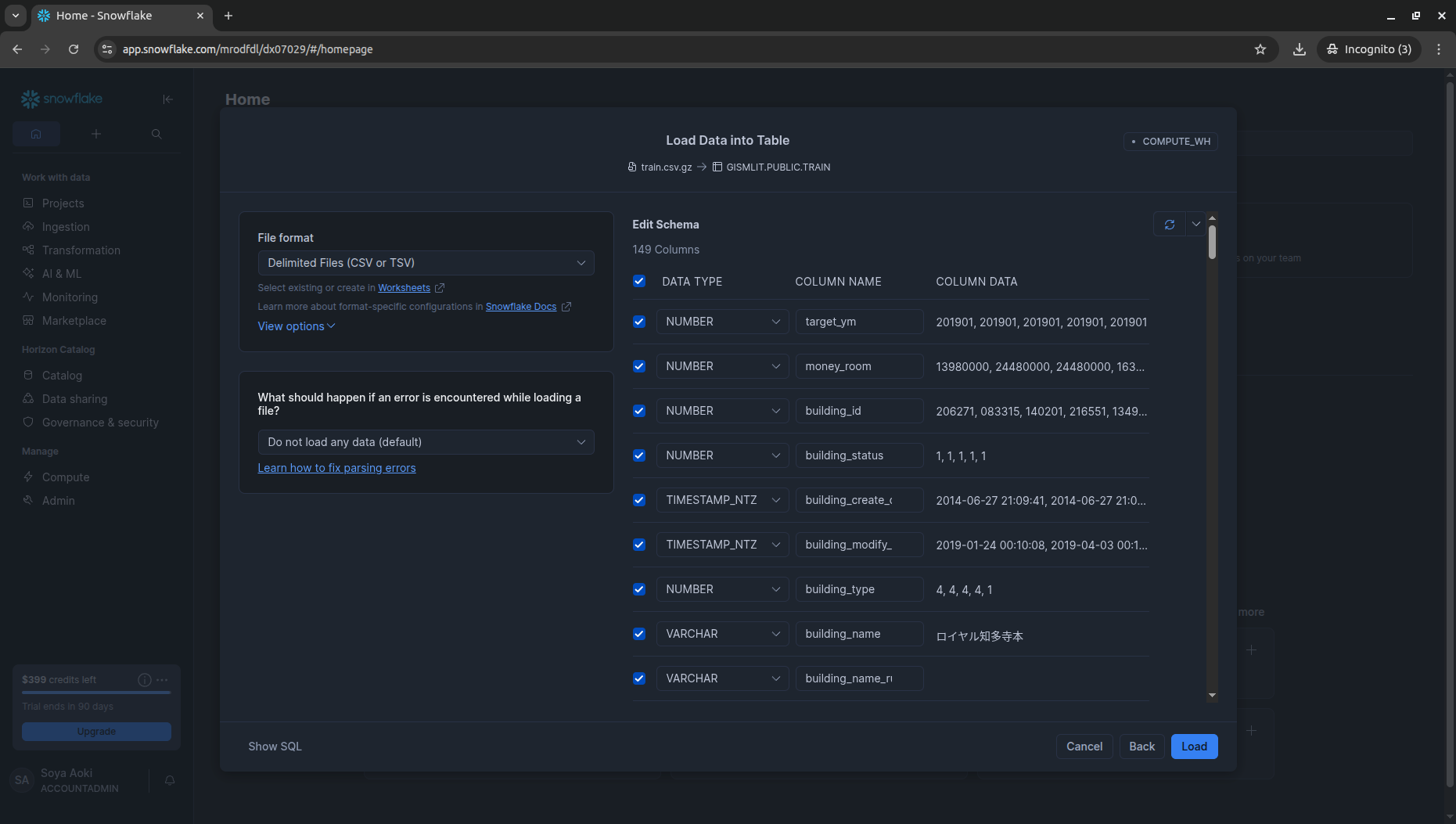
2. tran.csv.gz / test.csv.gz を手動アップロード
ハンズオンに沿ってデータを取り込んでいきます。まずtrainから。

続いてtestを取り込みます。
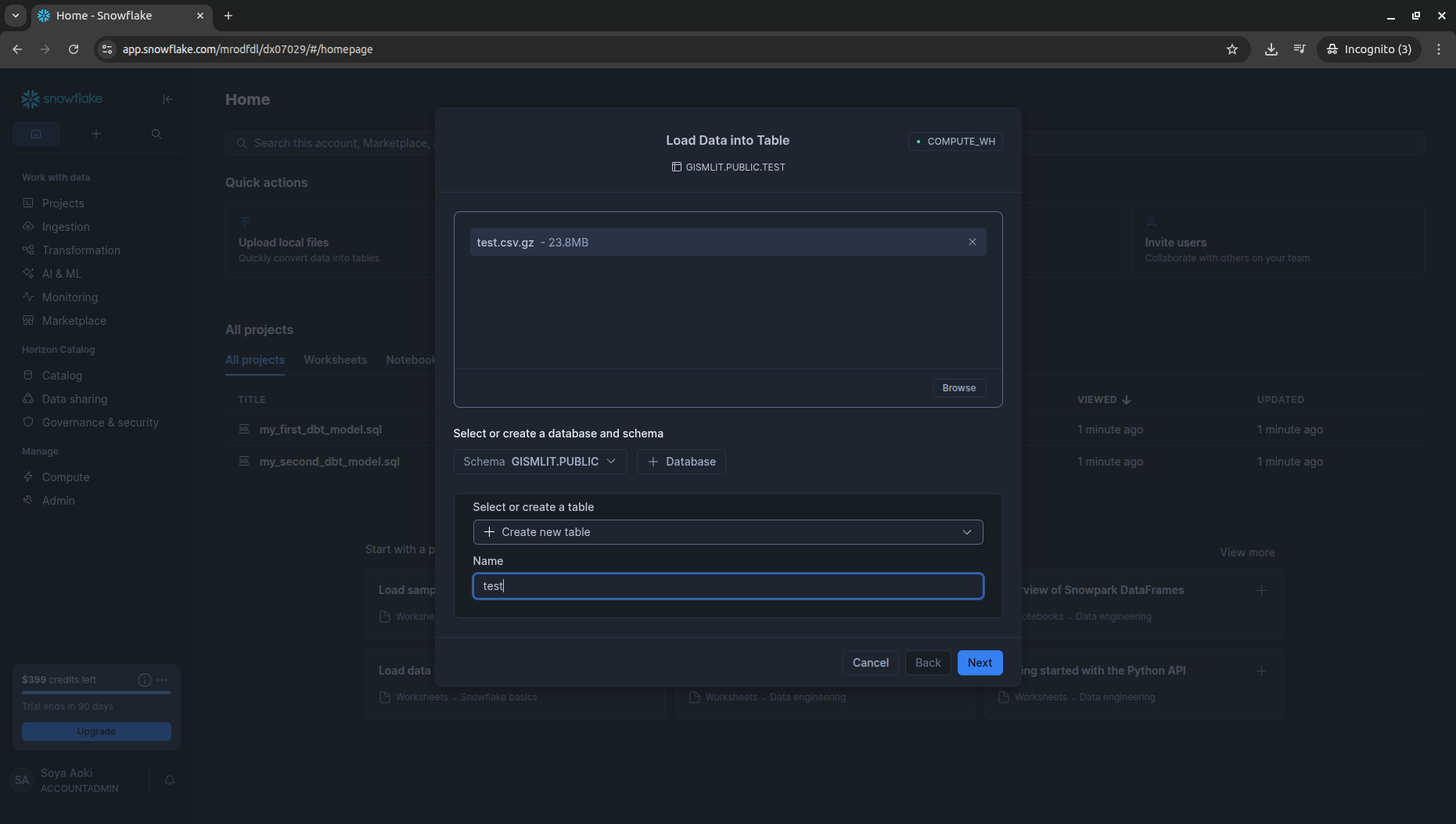
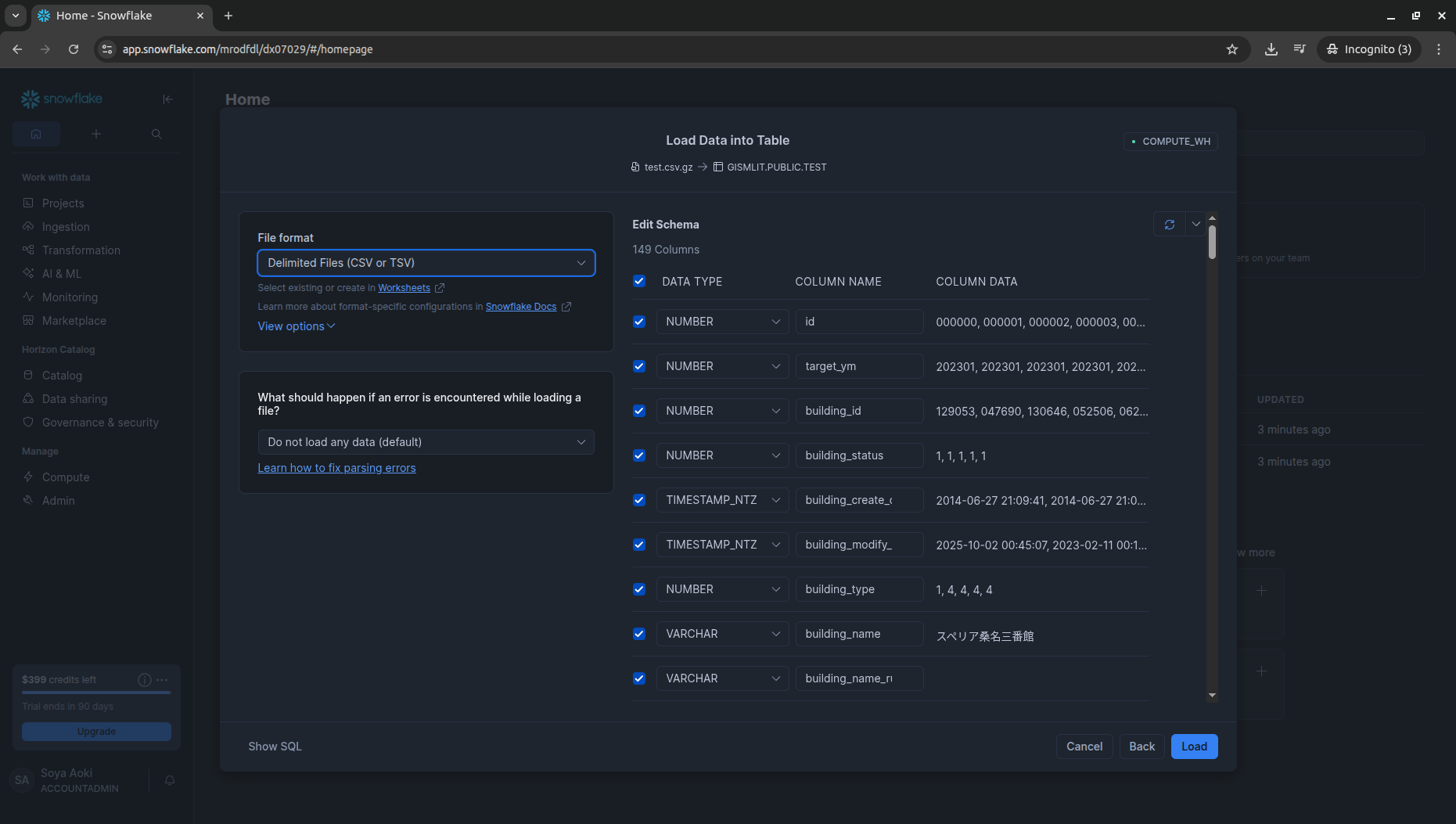
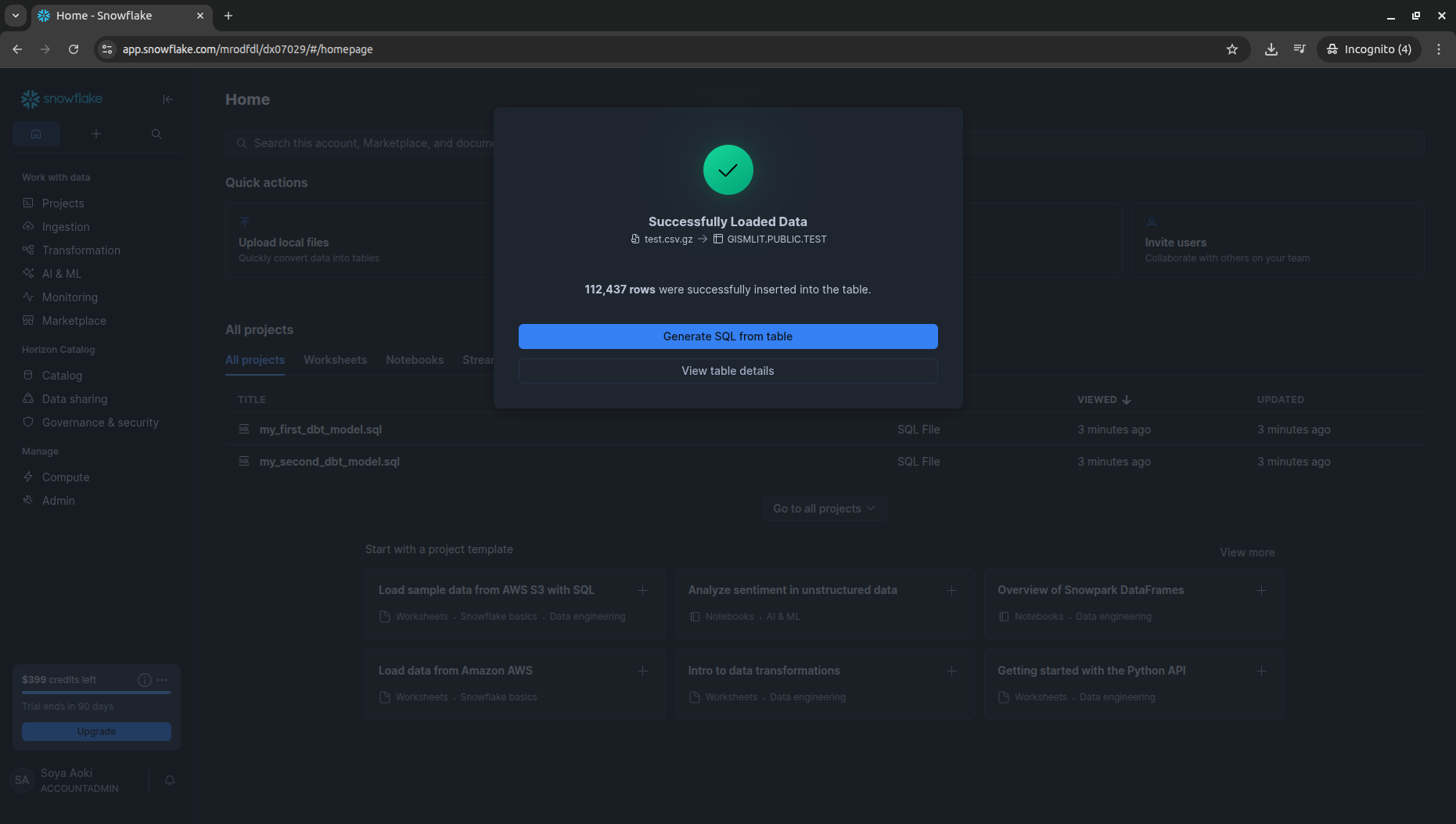
3. dbt projectを作成
こちらもハンズオン通りに「gismlit」のdbt projectを作ります。

sources.yaml / concatenated.sql / transformed.sql を作成し実行、DAGを確認します。

4. dbt_snowflake_ml を使用してモデル学習〜推論を実施
マクロの作成
以下OSSを使用します。
実質必要なのは以下マクロとのことなので、3で作成したプロジェクトの macros 下にコピーします。
※ ただし単純なコピーだと動かなかったので、後述のつまずきポイントにて詳細解説します。
学習・推論部の作成
ハンズオン資料やこのあたりを参考に、model.py / predict.sql を作成し、buildを実行します。60秒強でbuildが完了した後、Database Explorer 上にPREDICTテーブルやML Modelsが作成されます。

※ model.py がサンプルとして提供がなかった?ので自作しています、後述のつまずきポイントにて詳細解説します。
5. 推論結果を提出
推論結果をSQLでクエリしダウンロード、ヘッダーを削除して提出します。
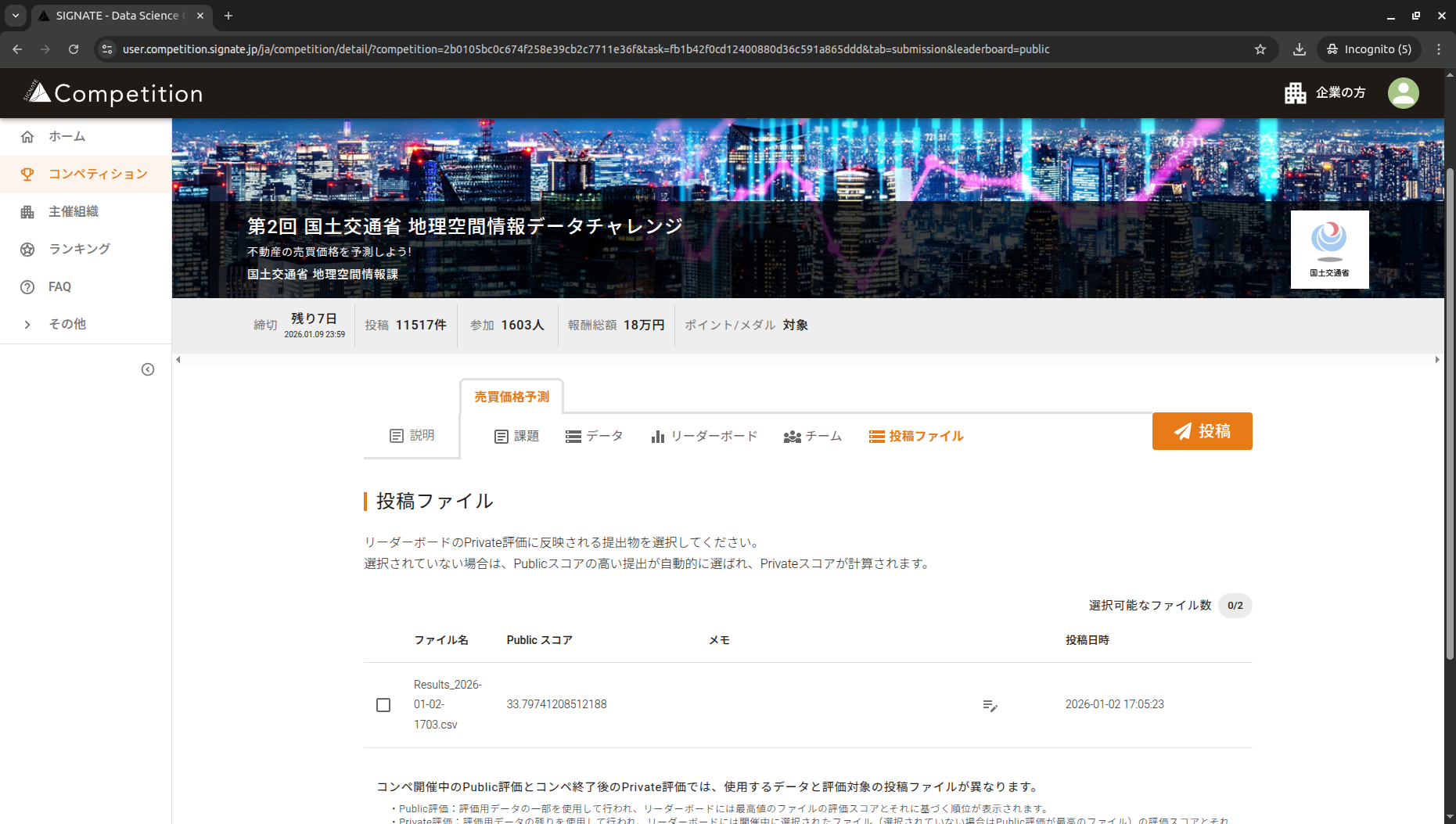
SIGNATEって提出後スコア算出が完了するとメールが来るんですね…便利だ…
つまずきポイント
1. dbt_snowflake_ml の未定義エラー
macros/dbt_snowflake_ml.sql 実行時に以下のエラーが出ました。
DBT job failed: 1 model(s) failed out of 4 total (total time: 2.28s)
First error in model 'model': Compilation Error in model model (mels/model.py)
'dbt_snowflake_ml' is undefined
> in macro materialization_model_snowflake (macros/dbt_snowflake_ml.sql)
> called by model model (models/model.py).
Context: DBT 1.9.4, Command: dbt build.
Check logs/dbt.log for more details.
どうやらdbt_snowflake_mlというプロジェクトを想定されているようだったので、マクロからdbt_snowflake_mlという文言を削除しました。パワーである。修正したものは次章に載せます。
2. model.py のサンプルがない?
ハンズオン資料にはmodel.pyの一部しか記載がなかった? (加えてインターネット上で発見できなかった) ため、残り部分を自作しました。一旦ベースラインということで、緯度経度・築年数・徒歩距離を入力とする、GradientBoostingRegressorにしました。こちらもまとめて次章に載せます。
※ 特徴量や学習アルゴリズムについては検討の余地ありです、生データすら見てないので…
コード全体
プロジェクト構成は以下の通りです。
gismlit/
├── analyses/
├── logs/
├── macros/
│ ├── .gitkeep
│ └── dbt_snowflake_ml.sql
├── models/
│ ├── concatenated.sql
│ ├── model.py
│ ├── predict.sql
│ ├── sources.yaml
│ └── transformed.sql
├── seeds/
├── snapshots/
├── target/
├── tests/
├── .gitignore
├── dbt_project.yml
├── profiles.yml
├── metrics.sql
└── submit.sql
コード本体は以下で、記載がないものはdbt project作成時のデフォルトとなります。
dbt_snowflake_ml.sql
{% materialization model, adapter = "snowflake", supported_languages = ["python"] -%}
{% set original_query_tag = set_query_tag() %}
{%- set identifier = model["alias"] -%}
{%- set language = model["language"] -%}
{% set grant_config = config.get("grants") %}
{%- set existing_relation = adapter.get_relation(
database=database, schema=schema, identifier=identifier
) -%}
{%- set target_relation = api.Relation.create(
identifier=identifier,
schema=schema,
database=database,
type="external",
) -%}
{{ run_hooks(pre_hooks) }}
{# dropping model relation is not supported yet
{% if target_relation.needs_to_drop(existing_relation) %}
{{ drop_relation_if_exists(existing_relation) }}
{% endif %}#}
{% call statement("main", language=language) -%}
{{ snowflake__create_model_as(target_relation, compiled_code, language) }}
{%- endcall %}
{{ run_hooks(post_hooks) }}
{% set should_revoke = should_revoke(existing_relation, full_refresh_mode=True) %}
{% do apply_grants(target_relation, grant_config, should_revoke=should_revoke) %}
{% do persist_docs(target_relation, model) %}
{% do unset_query_tag(original_query_tag) %}
{{ return({"relations": [target_relation]}) }}
{% endmaterialization %}
{% macro snowflake__create_model_as(relation, compiled_code, language="sql") -%}
{# Generate DDL/DML #}
{%- if language == "python" -%}
{%- if relation.is_iceberg_format %}
{% do exceptions.raise_compiler_error(
"Iceberg is incompatible with Python models. Please use a SQL model for the iceberg format."
) %}
{%- endif %}
{{ py_write_model(compiled_code=compiled_code, target_relation=relation) }}
{%- else -%}
{% do exceptions.raise_compiler_error(
"snowflake__create_model_as macro didn't get supported language, it got %s"
% language
) %}
{%- endif -%}
{% endmacro %}
-- fmt: off
{% macro py_write_model(compiled_code, target_relation) %}
{% set packages = config.get("packages", []) %}
{% set packages = packages + (["snowflake-ml-python"] if packages | count == 0 else []) %}
import importlib.util
if importlib.util.find_spec("snowflake.ml") is None:
raise ImportError("snowflake.ml is not found. Add snowflake-ml-python to package dependencies.")
from snowflake.ml.registry import Registry
{{ compiled_code }}
def main(session):
dbt = dbtObj(session.table)
model_dict = model(dbt, session)
reg = Registry(
session = session,
database_name = dbt.this.database,
schema_name = dbt.this.schema
)
set_default = model_dict.pop("set_default", False)
assert "model_name" not in model_dict, "model_name cannot be overridden"
assert "conda_dependencies" not in model_dict, "conda_dependencies cannot be overridden"
mv = reg.log_model(
**model_dict,
model_name = "{{ resolve_model_name(target_relation) }}",
conda_dependencies = ['{{ packages | join("', '") }}'],
)
if set_default:
reg.get_model(dbt.this.identifier).default = mv
return "OK"
{% endmacro %}
-- fmt: on
{% macro list_model(model_name) %}
{% do run_query("show versions in model " ~ ref(model_name)).print_table(
**kwargs
) %}
{% endmacro %}
{% macro set_model_default_version(model_name, version_name) %}
{% do run_query(
"alter model "
~ ref(model_name)
~ " set default_version = '"
~ version_name
~ "'"
).print_table(**kwargs) %}
{% endmacro %}
{% macro drop_model_version(model_name, version_name) %}
{% do run_query(
"alter model " ~ ref(model_name) ~ " drop version " ~ version_name
).print_table(**kwargs) %}
{% endmacro %}
sources.yaml
sources:
- name: public
schema: public
tables:
- name: train
- name: test
concatenated.sql
select
null::integer as id,
money_room,
* exclude (money_room)
from
{{ source('public', 'train') }}
union all
select
id,
null::integer as money_room,
* exclude (id)
from
{{ source('public', 'test') }}
transformed.sql
select
id, house_area, money_room,
money_room / unit_area as unit_price,
lat, lon, year_built, walk_distance1
from
{{ ref('concatenated') }}
model.py
import datetime
import numpy as np
import pandas as pd
import snowflake.snowpark.functions as f
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.experimental import enable_iterative_imputer
from sklearn.impute import IterativeImputer
from sklearn.preprocessing import PolynomialFeatures
from snowflake.ml.model import model_signature
from snowflake.ml.model import custom_model
def model(dbt, session):
dbt.config(
materialized="model",
python_version="3.11",
packages=["snowflake-ml-python", "pandas", "scikit-learn"],
)
features = dbt.ref("transformed")
data = features.to_pandas()
train_data = data[data["UNIT_PRICE"].notnull()].copy()
x = train_data.drop(columns=["ID", "UNIT_PRICE", "MONEY_ROOM", "HOUSE_AREA"], errors="ignore").apply(pd.to_numeric, errors='coerce')
y = train_data["UNIT_PRICE"]
imputer = IterativeImputer()
x_imputed = imputer.fit_transform(x)
model_obj = GradientBoostingRegressor()
model_obj.fit(x_imputed, y)
mc = custom_model.ModelContext(
models={
"model": model_obj,
"imputer": imputer,
},
)
class CustomModel(custom_model.CustomModel):
def __init__(self, context: custom_model.ModelContext) -> None:
super().__init__(context)
@custom_model.inference_api
def predict(self, input: pd.DataFrame) -> pd.DataFrame:
model = self.context.model_ref("model")
imputer = self.context.model_ref("imputer")
x = input.drop(columns=["ID", "UNIT_PRICE", "MONEY_ROOM", "HOUSE_AREA"], errors="ignore").apply(pd.to_numeric, errors='coerce')
x = imputer.transform(x)
return pd.DataFrame({"0": model.predict(x)})
return {
"model": CustomModel(mc),
"signatures": {"predict": model_signature.infer_signature(x.iloc[:10], y.iloc[:10])},
"version_name": datetime.datetime.today().strftime("V%Y%m%d_%H%M%S"),
"metrics": {"r2_score": float(model_obj.score(x_imputed, y))},
"comment": f"r2_score: {model_obj.score(x_imputed, y)}",
"set_default": True,
}
predict.sql
{{ config(materialized = "table") }}
select
id,
{{ ref("model")}}!predict(* exclude(id, house_area, money_room, unit_price)):"0"::float * house_area as money_room
from
{{ ref("transformed") }}
where
id is not null
submit.sql
select * from GISMLIT.PUBLIC.PREDICT order by ID asc;
metrics.sql
show versions in model GISMLIT.PUBLIC.MODEL;
提出結果
2026年1月2日 17:10時点で、publicリーダーボード上で 502位 / 1462チーム でした。
上位約34%ということで、ベースラインとしてはまあまあ?でしょうか。

おわりに
第2回 国土交通省 地理空間情報データチャレンジ、残り一週間で頑張りたい方の参考になれば幸いです。
なお今回の構成で、より高度なMLパイプラインを作りたい方は以下が参考になると思います、XGBoostを使ってSHAP値計算まで実行しています。
また公開されている勉強会もとても勉強になるのでおすすめです。
個人的には、Snowflake / dbt の雰囲気を味わえたので良かったです。
Databricksにも興味ありなのですが…また別の機会に…