あるサイトのURLを取得試みたが、出来なかった
<a href="/company/cmi0179173001/nx1_rq0023287251/?fr=cp_s00700&list_disp_no=1&leadtc=n_ichiran_cst_n5_ttl" target="_blank" class="rnn-linkText rnn-linkText--black">CADオペ/設計補助エンジニア◆未経験歓迎◆年休122日</a>
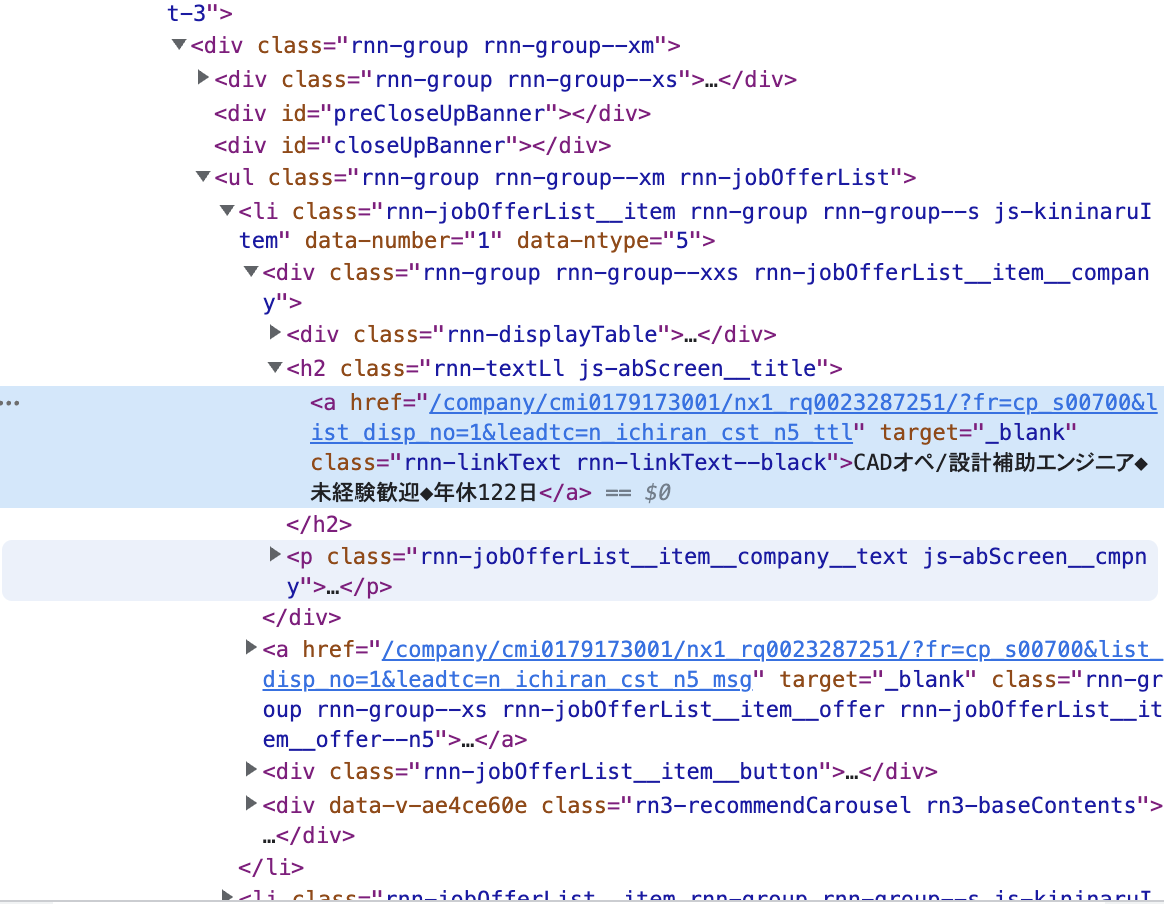
欲しいURLは下記だが、
/company/cmi0179173001/nx1_rq0023287251/?fr=cp_s00700&
boxs = soup.find_all('ul', attrs={'class': 'rnn-group rnn-group--xm rnn-jobOfferList'})
for box in boxs:
links = box.find_all('a', attrs={'class': 'rnn-linkText rnn-linkText--black'})
for link in links:
link = link.text
textを実施すると、「CADオペ/設計補助エンジニア◆未経験歓迎◆年休122日」が取得できてしまう
解決策はとても簡単で、textではなくget('href')で解決
boxs = soup.find_all('ul', attrs={'class': 'rnn-group rnn-group--xm rnn-jobOfferList'})
for box in boxs:
links = box.find_all('a', attrs={'class': 'rnn-linkText rnn-linkText--black'})
for link in links:
link = link.get('href')