はじめに
プログラミングやBIツールやSQLを使った施策は、生成AIなどの普及により誰でも簡単に実装ができるようになりました。マーケター、営業、PdMなど、非エンジニアでもSQLを書いたり、BIツールで集計・可視化する場面は増えています。
一方で、
- テストではうまくいったのに本番環境でリリースしたら障害が起きた
- 生成AIを使ってもSQLがうまく作成できなくなった
といったトラブルも起きがちです。
本記事では、プログラミングやBIツールを使うときに、最低限押さえておくべき3点を紹介します。どれも「エンジニアっぽい話」に見えますが、気をつけるだけで生産性が飛躍的に向上するため、ぜひチャレンジしてみてください。
1. 差分管理をすること
新しい施策や分析を始めるとき、「前回から何を変えたのか?」を明確に把握できていますか?
過去のコードは別途保存しているから問題ないでしょ?
という声も聞こえてきそうですが、もう一歩踏み込んで差分管理までしておくことをお勧めします。
その理由として以下が挙げられます。
- 障害や数値不整合が起きたとき原因を特定しやすい
- 他人(未来の自分含め)が見ても理解しやすい
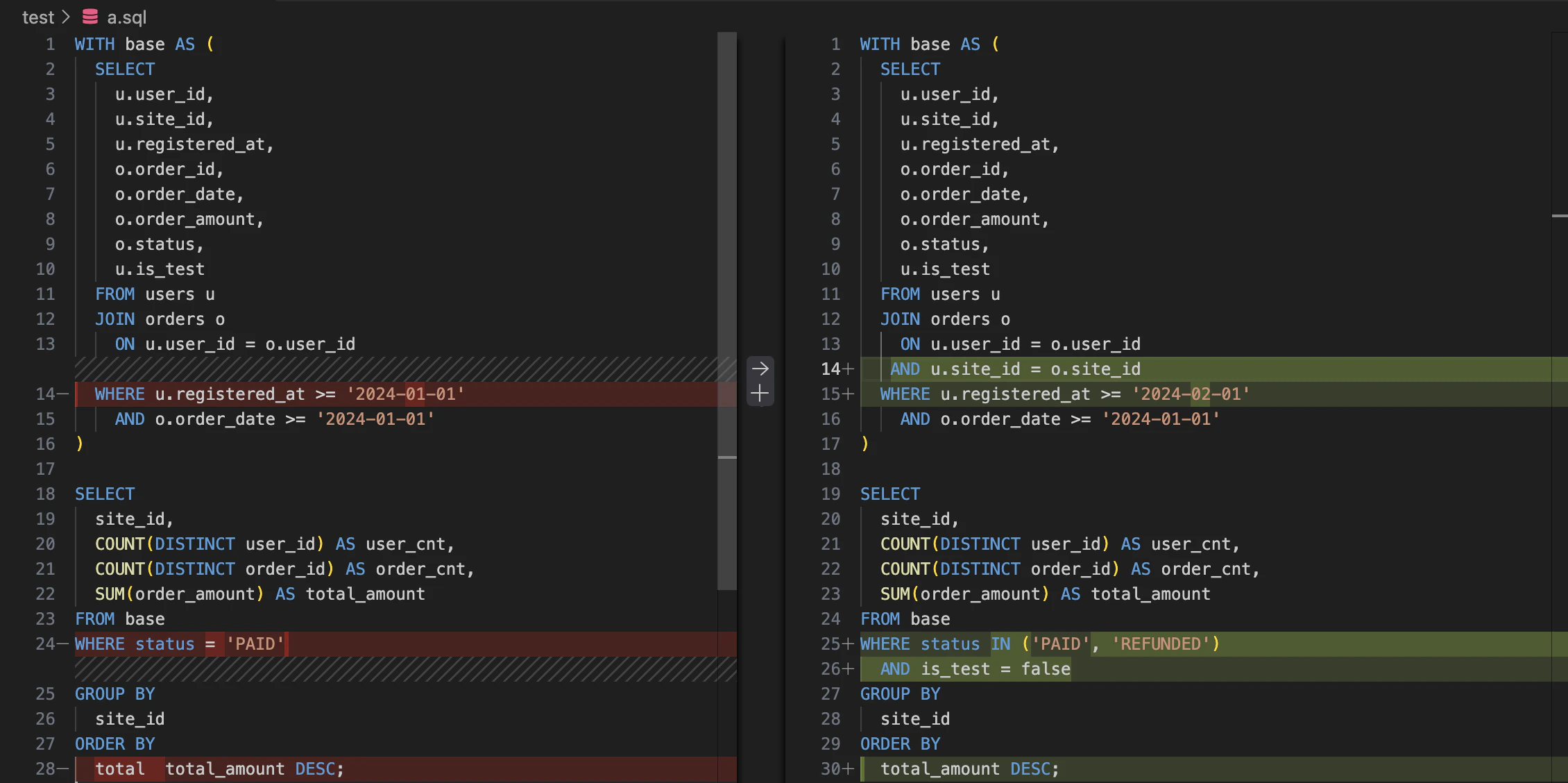
特にBIやSQLは、「ちょっと条件を足しただけ」「列を1つ追加しただけ」のつもりでも、結果が大きく変わります。極端な例ですが、以下のファイルの差分をパッと見分けることができるでしょうか?

※どこが変更されていたか?
-
JOIN条件の追加
-
AND u.site_id = o.site_idを追加 - サイトをまたいだ注文データが除外され、
集計結果(件数・売上)が大きく変わる可能性がある
-
-
ユーザー抽出期間の変更
-
u.registered_at >= '2024-01-01'
→u.registered_at >= '2024-02-01' - 対象ユーザーが減り、母数やサイト別傾向が変化する
-
-
注文ステータス条件の変更
-
status = 'PAID'
→status IN ('PAID', 'REFUNDED') - 返金データを含めるかどうかで、
total_amountの意味合いが変わる
-
-
テストユーザー除外の追加
-
AND is_test = falseを追加 - テストデータ混入を防げる一方、
前回施策との単純比較はできなくなる
-
これらは目視でチェックするのは困難ですし、見落とさなかったとしても確認にかなり労力がかかります。
エンジニアはどうしているか
一般的にはGitなどを使った差分管理が主流です。
この管理をすることのメリットとして、
- 何を変更したかが一目で分かる
- いつでも過去に戻せる
- レビューができる
などが挙げられます。実際に先ほどの例題のSQLをGitで差分管理してみると、以下のように分かりやすく変更点を表示してくれます。
とはいえ、Gitは初心者には分かりにくい部分も多々あるので手元で試しつつ書籍などで体系的に学ぶことをお勧めします。
2. インフラ構築はGUIではなくテキストベースで行うこと
BIツールやMAツールでは、画面操作(GUI)で設定できるものが多いです。しかし、GUIだけで構築することには大きな落とし穴があります。
- 「何をどう設定したか」が後から追えない
- 環境構築時に人為的ミスが入りやすい
例えば、SFMCのオートメーションを例に挙げてみましょう。
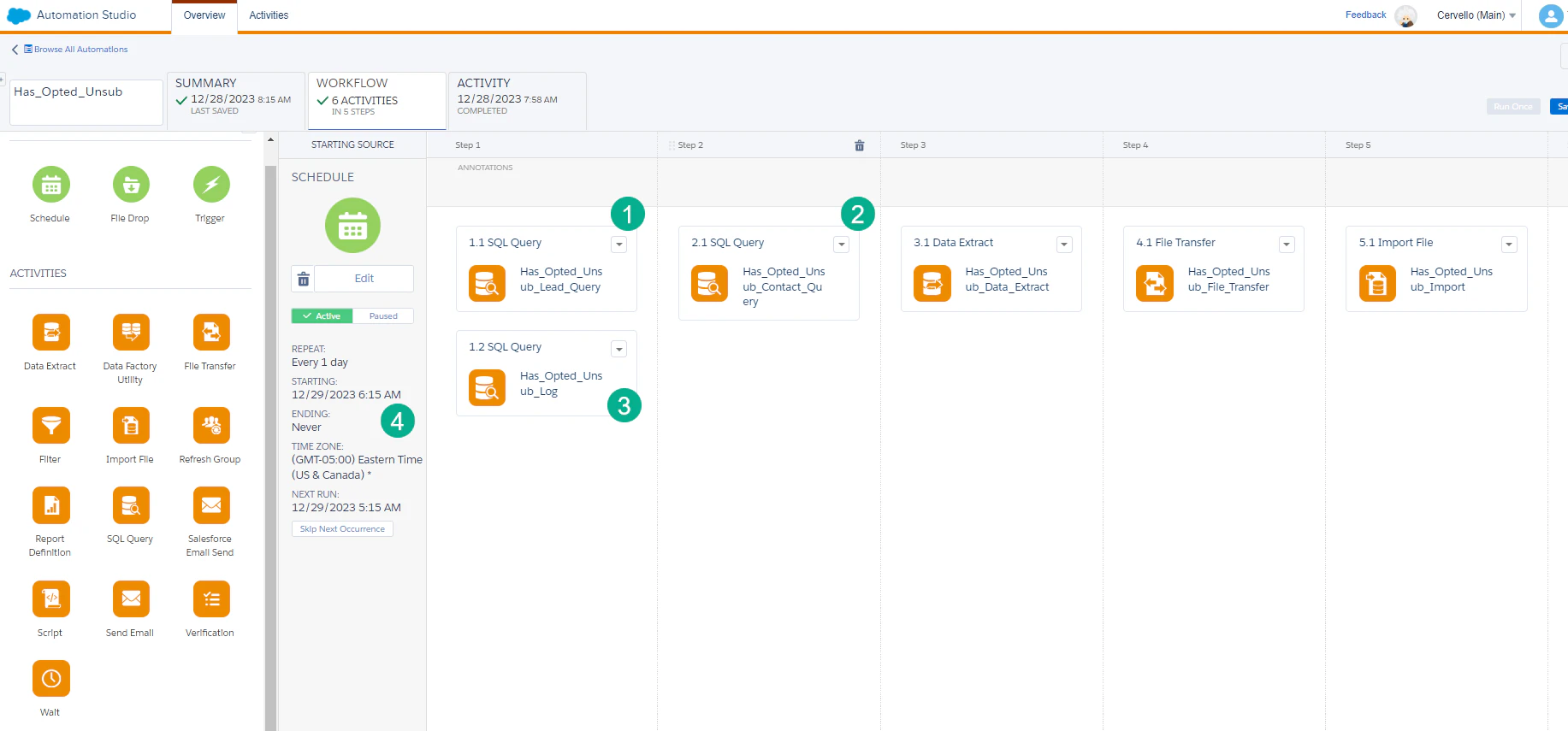
出典:https://handsonsfmc.com/how-to-set-up-an-automated-unsubscribe-process-in-marketing-cloud-part-ii/
この画像を見て、以下の観点について答えることはできるでしょうか?
- それぞれのSQLアクティビティがどのようなSQLを実行するか?
- SQLアクティビティは「上書き」か「更新」か?
BIツールは非エンジニアでも使いやすいUIにはなっているものの、その反面一覧画面で情報が省略されていることが多く、保守管理の観点とトレードオフになっています。
エンジニアの世界ではどうしているか
最近のエンジニア開発ではIaC(Infrastructure as Code)で上記のようなインフラを管理するのが一般的です。簡単にいうと以下のようにテキストで設定を管理するような仕組みになっています。

出典:https://dev.classmethod.jp/articles/awssummit-2021-aws-31/
このようにテキストで管理することにより、
- Gitと組み合わせることで差分が明確になる
- 再現性が高い
- 生成AIに読み込ませやすい
などのメリットを享受することができます。
3. 適度に分割すること
生成AIに任せればいい感じにコードを書いてくれるようになりましたが、一点気をつけるべきことがあります。それはコードの責務を適度に分割することです。
極端な例ですが、以下のSQLどのような処理をしているか分かるでしょうか?
長ーいSQL
SELECT
t.site_id,
t.campaign_id,
t.channel,
t.period_yyyymm,
t.user_segment,
t.send_user_cnt,
t.open_user_cnt,
t.click_user_cnt,
t.cv_user_cnt,
t.order_cnt,
t.gmv,
t.refund_cnt,
t.refund_amount,
t.net_gmv,
t.cvr,
t.ctr,
t.open_rate,
t.aov,
t.gmv_rank_in_site,
t.alert_flag
FROM (
SELECT
a.site_id,
a.campaign_id,
a.channel,
a.period_yyyymm,
a.user_segment,
a.send_user_cnt,
a.open_user_cnt,
a.click_user_cnt,
a.cv_user_cnt,
a.order_cnt,
a.gmv,
a.refund_cnt,
a.refund_amount,
a.gmv - a.refund_amount AS net_gmv,
SAFE_DIVIDE(a.cv_user_cnt, a.send_user_cnt) AS cvr,
SAFE_DIVIDE(a.click_user_cnt, a.send_user_cnt) AS ctr,
SAFE_DIVIDE(a.open_user_cnt, a.send_user_cnt) AS open_rate,
SAFE_DIVIDE(a.gmv, NULLIF(a.order_cnt, 0)) AS aov,
DENSE_RANK() OVER (
PARTITION BY a.site_id, a.period_yyyymm
ORDER BY a.gmv - a.refund_amount DESC
) AS gmv_rank_in_site,
CASE
WHEN a.send_user_cnt < 100 THEN 'LOW_SAMPLE'
WHEN SAFE_DIVIDE(a.cv_user_cnt, a.send_user_cnt) < 0.003 THEN 'LOW_CVR'
WHEN SAFE_DIVIDE(a.click_user_cnt, a.send_user_cnt) < 0.01 THEN 'LOW_CTR'
WHEN a.gmv - a.refund_amount < 0 THEN 'NEGATIVE_GMV'
ELSE 'OK'
END AS alert_flag
FROM (
SELECT
b.site_id,
b.campaign_id,
b.channel,
b.period_yyyymm,
CASE
WHEN b.user_first_order_date IS NULL THEN 'NO_PURCHASE'
WHEN DATE_DIFF(b.send_date, b.user_first_order_date, DAY) <= 30 THEN 'NEW_30D'
WHEN DATE_DIFF(b.send_date, b.user_first_order_date, DAY) <= 180 THEN 'MID_180D'
ELSE 'OLD_180D_PLUS'
END AS user_segment,
COUNT(DISTINCT IF(b.send_flg = 1, b.user_id, NULL)) AS send_user_cnt,
COUNT(DISTINCT IF(b.open_flg = 1, b.user_id, NULL)) AS open_user_cnt,
COUNT(DISTINCT IF(b.click_flg = 1, b.user_id, NULL)) AS click_user_cnt,
COUNT(DISTINCT IF(b.cv_flg = 1, b.user_id, NULL)) AS cv_user_cnt,
COUNT(DISTINCT IF(b.is_paid_order = 1, b.order_id, NULL)) AS order_cnt,
SUM(IF(b.is_paid_order = 1, b.order_amount, 0)) AS gmv,
COUNT(DISTINCT IF(b.is_refund_order = 1, b.order_id, NULL)) AS refund_cnt,
SUM(IF(b.is_refund_order = 1, b.refund_amount, 0)) AS refund_amount
FROM (
SELECT
u.site_id,
s.campaign_id,
s.channel,
s.user_id,
DATE(s.send_ts) AS send_date,
FORMAT_DATE('%Y%m', DATE(s.send_ts)) AS period_yyyymm,
1 AS send_flg,
IF(o.open_ts IS NULL, 0, 1) AS open_flg,
IF(c.click_ts IS NULL, 0, 1) AS click_flg,
IF(
ord.order_id IS NOT NULL
AND TIMESTAMP_DIFF(ord.order_ts, COALESCE(c.click_ts, s.send_ts), HOUR) BETWEEN 0 AND 168,
1,
0
) AS cv_flg,
ord.order_id,
DATE(ord.order_ts) AS order_date,
ord.order_amount,
IF(ord.status IN ('PAID','CAPTURED','SETTLED'),1,0) AS is_paid_order,
IF(ord.status IN ('REFUNDED','CHARGEBACK'),1,0) AS is_refund_order,
IF(ord.status IN ('REFUNDED','CHARGEBACK'), ord.refund_amount, 0) AS refund_amount,
f.user_first_order_date
FROM send_log s
JOIN users u
ON s.user_id = u.user_id
LEFT JOIN open_log o
ON s.send_id = o.send_id
LEFT JOIN click_log c
ON s.send_id = c.send_id
LEFT JOIN orders ord
ON s.user_id = ord.user_id
LEFT JOIN (
SELECT
user_id,
MIN(DATE(order_ts)) AS user_first_order_date
FROM orders
WHERE status IN ('PAID','CAPTURED','SETTLED')
GROUP BY user_id
) f
ON s.user_id = f.user_id
WHERE DATE(s.send_ts) BETWEEN '2024-01-01' AND '2024-06-30'
AND u.is_test = false
) b
GROUP BY
b.site_id,
b.campaign_id,
b.channel,
b.period_yyyymm,
user_segment
) a
) t
WHERE t.alert_flag <> 'LOW_SAMPLE'
ORDER BY
t.site_id,
t.period_yyyymm,
t.gmv_rank_in_site;
このようなコードの問題点としては、
- 引き継ぎ時のコストの増大
- 次回改修の時間がかかる
- バグが混入しやすい
などが挙げられます。
しかもさらにタチが悪いのは生成AIとの相性も最悪です。
- 処理が詰め込まれすぎていると再開発が難しい
- 背景説明が膨大になる
などなど、人間や機械にとっても最悪な結果を引き起こします。
エンジニアの世界ではどうしているか
この問題に関しては、残念ながら明確な解決方法はありません。
ただしある程度の知見は存在します。
例えばSQLで言えば、
- CTE(WITH句)で段階的に分ける
- 中間テーブルやビューを作る
といったルールを作成することで注視する部分を切り分けることができます。
そのほかのプログラミング言語で作成されたコードに関しても同様の対応で解決できるのですが、以下の書籍に体系的に知識がまとめられていたため、興味があれば読んでみてください。