概要・目的
Kaggle で公開されているデータセットを使って
胸部 X 線画像から正常 (Normal) か肺炎 (Pneumonia) を分類する
- 画像データ数は合計5856枚 (train: 5216, val: 16, test: 624)
- 画像サイズはデータによってまちまち
- trainデータの Normal とPneumonia の枚数の差が大きい (Normal: 1341, Pneumonia: 3875)
- テストデータでの accuracy: 95 % となった
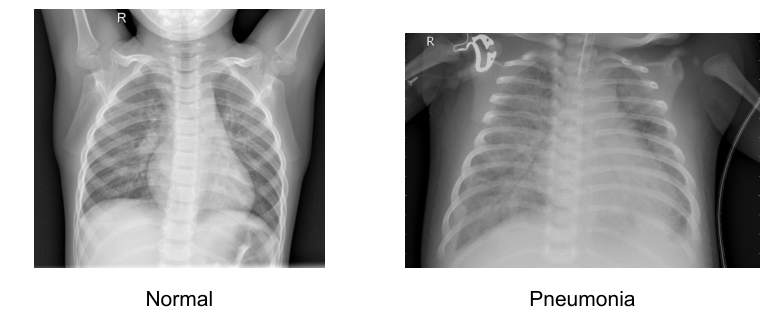
(画像出典: https://data.mendeley.com/datasets/rscbjbr9sj/2)
(Kaggle: https://www.kaggle.com/paultimothymooney/chest-xray-pneumonia)
採用アルゴリズム
画像の前処理
画像データの不要な部分をトリミング
- 画像両側にうつる背景部分を削除し、分類に必要な部分のみを残す狙い
- 画像の加工は以下の3種類について学習し、比較した
- a. 画像を引き延ばさず、224×224 pixel に合わせる
- b. 画像の両側をトリミングしたうえで 224×224 pixel に引き延ばす
- c. 画像をトリミングせずに224×224 pixel に引き延ばす
- テストデータでもっとも精度のよかった (b) を採用した

訓練、検証データの Normal:Pneumonia 比が同じになるよう分割
訓練データは Normal と Pneumonia の枚数がそれぞれ1341枚、3875枚と大きな開きがある。
これらのデータをそのまま結合して分割すると、訓練データにほとんど Normal の画像が無いといった事態が起こりうる。
Normal のデータ、Pneumonia のデータそれぞれを8:2 の割合で訓練データと検証データに分けることで、ばらつきを無くした。

データの学習
データの拡張(回転、拡大、平行移動)
過学習を防ぐために、Keras の ImageDataGenerator を用いて、バッチごとにランダムに回転・拡大・平行移動を施した。
他にも明暗を変化できるが、すべて Pneumonia と予測したため不採用。
(どうやらImageDataGenerator上で問題があるよう 参考: https://qiita.com/Kuru-chan/items/3365d48b3345d2b9cfd2)
回転・拡大・平行移動の最大値および最小値は、 3つのの場合を比較し、以下を採用。
- 回転: -20~20度
- 拡大: MAX 15%
- 平行移動: MAX 15%
VGG16を用いてファインチューニング、学習の進行とともに学習率を減少
今回は転移学習によく用いられるVGG16を使用した。
最後の畳み込み層 (conv5) がある部分のみ訓練データを学習させ、ファインチューニングした。
学習が進行するにつれ、精度の改善が見られなくなるため、学習の後半では、徐々に学習率を減少させるようにした。

テストデータでの予測結果
- Normal は Pneumonia と比較して学習画像が少ないため、精度が比較的低い
- 学習回数 (epoch 数) は40回に設定しているが、80回でもほとんど同じ結果であった
- Normal の画像が少ないことを考慮してNormal の重みを増やし、Pneumonia の重みを減らしてもほとんど同じ結果であった
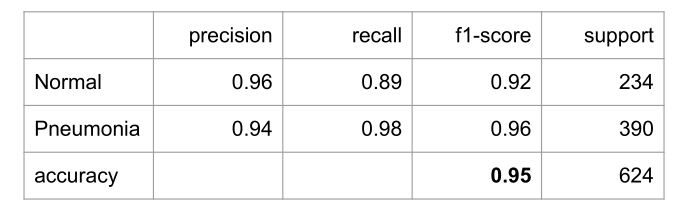
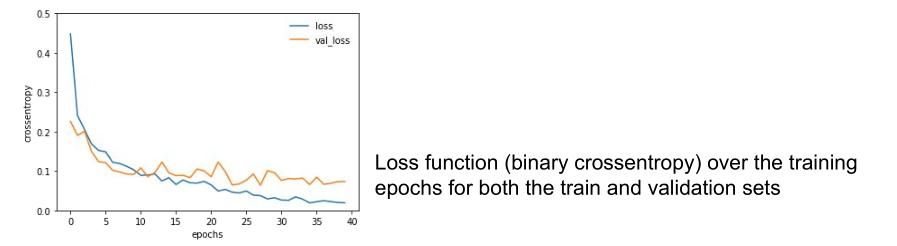
今回は試していないが、画像ごとにトリミング幅を調整することでさらなる精度向上が望める。
その他、訓練データに偏りがあることへの良い改善策が見つかると、1%程度精度が向上するかもしれない(希望)。
Githubでコードを公開しています