こんにちは。
@sori883です。
AIエージェントは自然言語で応答を返すゆえ、精度評価の正誤基準が曖昧です。
そのため、機械的に処理しきれず、かといって手動でやれば主観が介入してしまい、定量的な評価を続けるというのはかなり辛みがあります。
そこで、LLM-as-a-JudgeなAgentCore Evaluationsで記憶システムの精度評価を試してみたのでその備忘録です。
AgentCore Evaluationsを使う動機
AIエージェントのPoCや開発をしていく中でどうしても精度評価がボトルネックになりがちです。
- 評価基準が曖昧
- 評価者の主観になる
- 評価基準を決めたいが動作が非決定的
- 再現性のある基準が作りにくい
- 結果、精度評価設計のコストが大幅に増える
- 評価シナリオの設計
- 評価基準、評価指標の設計
また、運用フェーズ以降も「モデルの変更」「プロンプトの変更」を行う度、継続的に精度を評価する必要があります。
これらをAgentCore EvaluationsでLLM-as-a-Judgeして、継続的かつ定量的な精度評価をして一定の品質を担保していこうというワケです。
AgentCore Evaluationsの概要
AIエージェントの応答を自動的に評価できる機能です。
評価はAIエージェントの応答をLLMで評価するLLM-as-a-Judgeという手法で行うことができ、評価用の組み込みツールが用意されています。
もちろん、独自のカスタムツールを定義して評価も可能です。
評価ツール
- Built-in evaluators
- AgentCore組み込みで提供される一般的な評価シナリオに合わせて最適化された評価モデルとプロンプトテンプレートが設定された評価ツール
- Custom evaluators
- 独自の評価モデル、評価手順、および採点方式を定義し、特定のユースケースや評価要件に合わせてカスタマイズした評価ができる
評価方法
- オンライン評価
- サービス稼働時のデータをサンプリングし、非同期で継続的に評価をする
- 運用フェーズは向け
- オンデマンド評価
- spanID、traceIDを指定し、任意のタイミングで評価をする
- PoC、開発フェーズ向け
AgentCore Evaluationsを使ってみる
前提条件は以下に記載があります。
特に以下の2つは要対応になるはず。
- トランザクション検索の有効化
- AWS Distro for OpenTelemetry (ADOT) SDKを導入
トランザクション検索の有効化
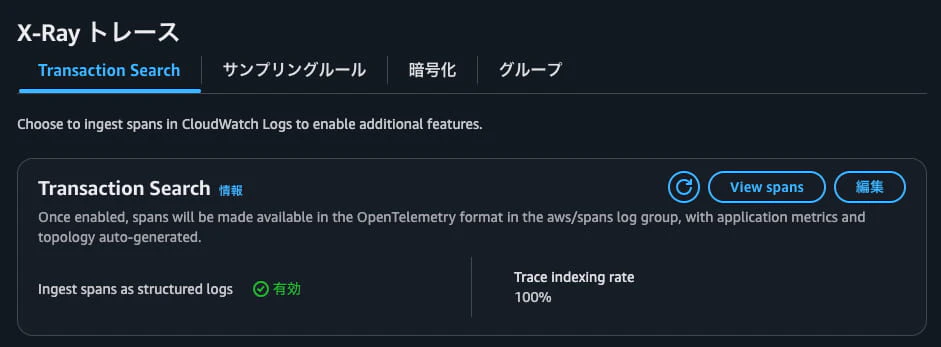
どうやらCloudWatchからTransaction Searchを有効化する必要があるみたいです。
マネコン > CloudWatch > セットアップ > 設定 > X-Rayトレース > トランザクション検索を開き、以下の通り設定変更をしました。
- Ingest spans as structured logs: 有効化
- Trace indexing rate: 100% (テストのため)
AWS Distro for OpenTelemetry (ADOT) SDKを導入
こちらは、AIエージェントのDockerfileにOpenTelemetryを追加する必要があります。
必要なライブラリを追加。
uv add aws-opentelemetry-distro
Dockerfileでopentelemetry-instrumentを有効化。
# uvインストール
COPY --from=ghcr.io/astral-sh/uv:latest /uv /uvx /bin/
# AIエージェントのソースコードコピー
COPY pyproject.toml /app/pyproject.toml
COPY uv.lock /app/uv.lock
COPY agentcore/ /app/agentcore/
WORKDIR /app/agentcore
# 依存関係をインストール
RUN uv sync --locked
ENV UV_CACHE_DIR=/tmp/uv-cache
ENV PORT=8080
# AgentCoreと一緒にopentelemetry-instrumentを起動し、評価データを収集できるようにする
CMD ["uv", "run", "--no-sync", "opentelemetry-instrument", "python", "main.py"]
カスタム評価ツールを作って精度評価してみる
今回は個人開発していたAIエージェントの精度評価をしていきたいと思います。
このAIエージェントの裏側にはHindsightライクな記憶システムと、TavilyのWeb検索を使用したレコメンデーションシステムを実装しています。
よって評価する部分は以下の2機能とします。
- ユーザーの記憶を想起できること
- ユーザーの趣味嗜好に合わせたレコメンドができること
カスタム評価ツールの作成
さっそくカスタム評価ツールを作成していきましょう。
AgentCore > 評価 > Custom evaluators > Create custom evaluatorから作成できます。
色々設定項目ありますが、特に重要なものは以下の2つです。
- Instruction
- LLM as a Judgeの肝となる指示プロンプトを書く場所
- Scale definitions
- 評価基準に対する判断基準を書く場所
ユーザーの記憶を想起出来ているかチェックするツール
Instructionは以下の通り記憶が正しく想起できているか評価するプロンプトを設定してみます。
あなたはAIエージェントの記憶想起能力を評価する専門の審査員です。
## 背景
このエージェントはユーザーとの過去の会話から事実(名前、居住地、職業、趣味、人間関係など)を記憶システムに保存しています。ユーザーからの質問に対して、保存された記憶を呼び出して回答することが期待されます。
## 評価対象
会話コンテキスト:
{context}
アシスタントの応答:
{assistant_turn}
## 評価手順
以下のステップに従って評価してください。
ステップ1: ユーザーの質問が記憶の想起を求めているかを判定する。求めていない場合はスコア対象外とし、1.0を付与する。
ステップ2: 応答に含まれる事実的主張を列挙する。
ステップ3: 各事実的主張について、会話コンテキストで裏付けられるかを確認する。
ステップ4: 会話コンテキストに存在しない情報を応答が「事実として」述べていないか(捏造)を確認する。
ステップ5: ユーザーが尋ねた内容に対して、回答すべき重要な事実が欠落していないかを確認する。
## 注意
- 応答の長さや文体ではなく、事実の正確性のみを評価すること。
- 短い応答でも事実が正確であれば高スコアとする。
- 記憶にない場合に「わからない」「覚えていない」と回答することは、捏造するよりも望ましい行動として評価する。
なお、{context}や{assistant_turn}を使用することで任意の場所へ会話コンテキストを挿入できます。
次にScale definitionsで評価の段階に対してなるべく例を用いて判断基準を指定します。
| value | label | definition |
|---|---|---|
| 1.0 | Completely Yes | 応答に含まれる事実的主張がすべて会話コンテキストで裏付けられる。具体的な詳細(日付、人名、場所名)が正確に含まれている。捏造が一切ない。例: 「仙台に住んでて、AWSエンジニアをやってるんだよね」 |
| 0.75 | Generally Yes | 主要な事実は正確だが、付随的な詳細が1-2点欠けている、または「たしか〜だったと思う」のように曖昧な表現になっている。捏造はない。例: 居住地は正しいが転職時期が曖昧。 |
| 0.5 | Neutral/Mixed | 事実の半分程度は正確だが、重要な情報が欠落している、または軽微な誤り(年の間違いなど)を含んでいる。捏造はない。 |
| 0.25 | Not Generally | 想起した事実に明確な誤りが複数ある、または質問に対して関連性の低い記憶を返している。ただし意図的な捏造ではなく混同の可能性がある。 |
| 0 | Not At All | コンテキストに存在しない事実を確信を持って述べている(捏造)、記憶を全く呼び出せていない、または質問に無関係な応答をしている。 |

ユーザーの趣味嗜好に沿ったレコメンドが出来ているかチェックするツール
記憶想起チェックツールと同じように作っていきます。
Instruction
あなたはAIエージェントのレコメンデーション品質を評価する専門の審査員です。
## 背景
このエージェントはユーザーの嗜好(好き嫌い、趣味、価値観、ライフスタイルなど)を記憶しています。ユーザーから「おすすめ」「何がいい?」等の提案を求められた際に、記憶された嗜好に基づいてパーソナライズされた提案を行うことが期待されます。
## 評価対象
会話コンテキスト:
{context}
アシスタントの応答:
{assistant_turn}
## 評価手順
以下のステップに従って評価してください。
ステップ1: ユーザーの発話がレコメンデーションを求めているかを判定する。求めていない場合はスコア対象外とし、1.0を付与する。
ステップ2: 応答に含まれる提案・推薦を列挙する。
ステップ3: 各提案がユーザーの既知の嗜好(会話コンテキストから判明する好み)と整合するかを確認する。
ステップ4: ユーザーのnegative嗜好やアレルギーに該当する提案が含まれていないかを確認する。
ステップ5: 提案にユーザー固有の文脈(居住地、人間関係、生活習慣など)がどの程度反映されているかを確認する。
ステップ6: 複数のカテゴリの嗜好を横断的に活用しているかを確認する(例: 場所×食べ物、趣味×人間関係)。
## 注意
- 応答の長さや提案数ではなく、パーソナライズの深さで評価すること。
- 1つの提案でもユーザーの嗜好を深く反映していれば高スコアとする。
- 「一般的に人気のある提案」と「このユーザーに合った提案」を区別すること。
Scale definitions
| value | label | definition |
|---|---|---|
| 1.0 | Completely Yes | ユーザーの具体的な嗜好を2カテゴリ以上引用している。ユーザー固有の文脈(居住地、関係者、生活習慣)を踏まえた提案である。回避すべき項目に抵触していない。例: 「仙台だし味噌ラーメン屋とかどう?スパイスカレーにもハマってるよね」(居住地+食の嗜好2点) |
| 0.75 | Generally Yes | ユーザーの嗜好に基づいた提案だが、活用している情報が1カテゴリに限定されている。または回避リストの考慮が明示されていない。例: 「ラーメンとかどう?好きだったよね」(食の嗜好のみ) |
| 0.5 | Neutral/Mixed | 提案自体は妥当だが、ユーザー固有の嗜好との関連付けが弱い。「一般的に良い提案」の域を出ていない。例: 「仙台なら牛タンとかどうですか?」(一般的な地域情報のみ) |
| 0.25 | Not Generally | ユーザーの嗜好情報をほぼ反映しておらず、誰にでも当てはまる提案をしている。例: 「和食とか洋食とか、いろいろありますよ」 |
| 0 | Not At All | ユーザーのnegative嗜好やアレルギー項目を提案している、またはレコメンドの質問に応答していない。例: 甲殻類アレルギーのユーザーにエビ料理を提案。 |
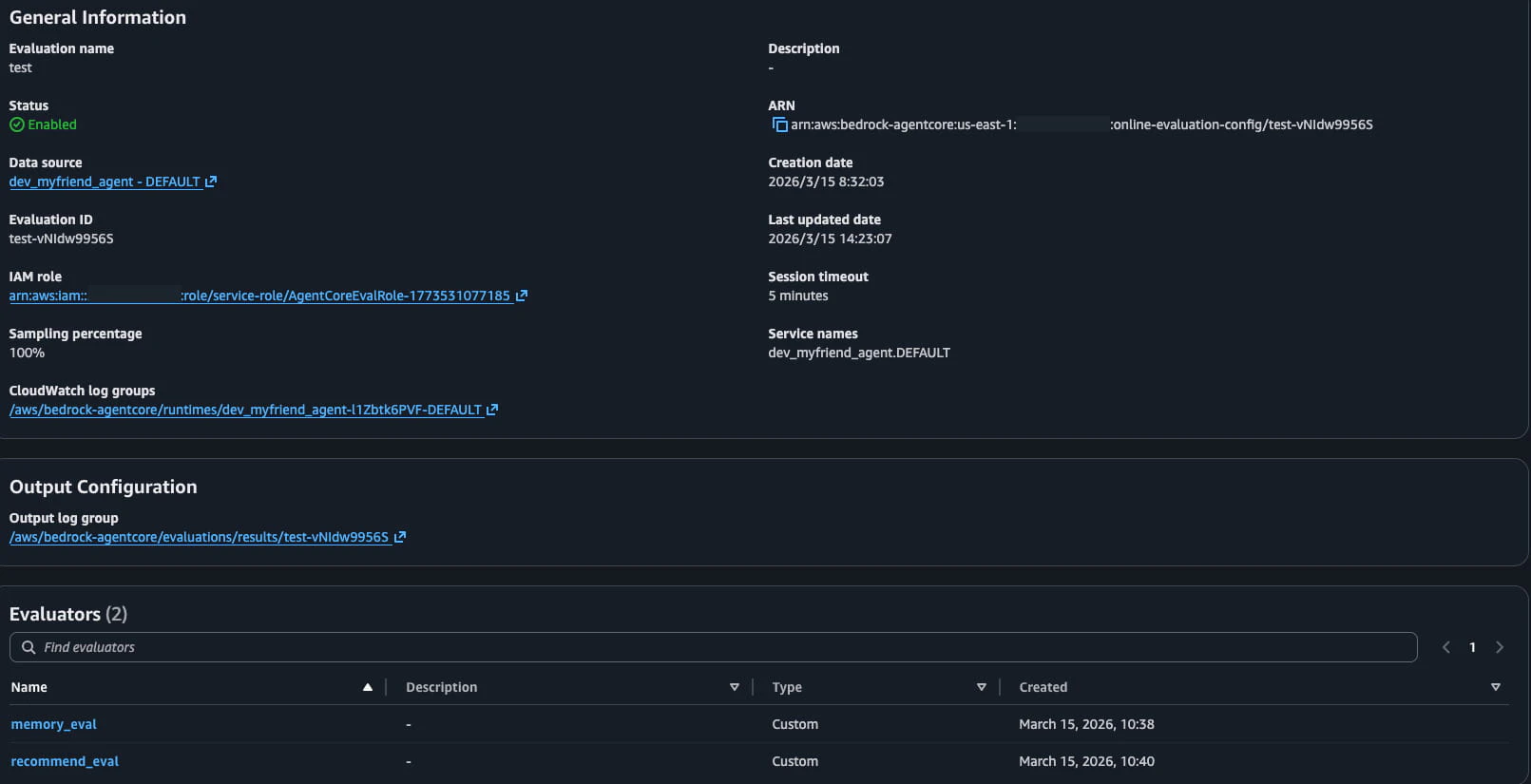
カスタム評価ツールをアソシエイトする
カスタム評価ツールはEvaluation configurationにアソシエイトすることでオンライン評価されるようになります。
AgentCore > 評価 > Evaluation configurations > Create evaluation configurationから作成、アソシエイトします。
※この時、evaluation configurationのサンプリングは100%推奨です!(1敗)
評価結果を見てみる
AgentCore > エージェントサンドボックスでリクエスト後、CloudWatch > AgentCore > 評価から評価メトリクスを閲覧できます。
※反映まで20分以上かかる場合があります。削除したりせず気長に待ちましょう(2敗)
反映されると以下のようなメトリクスが表示され、リクエスト毎のスコアと平均値が視覚化されます。
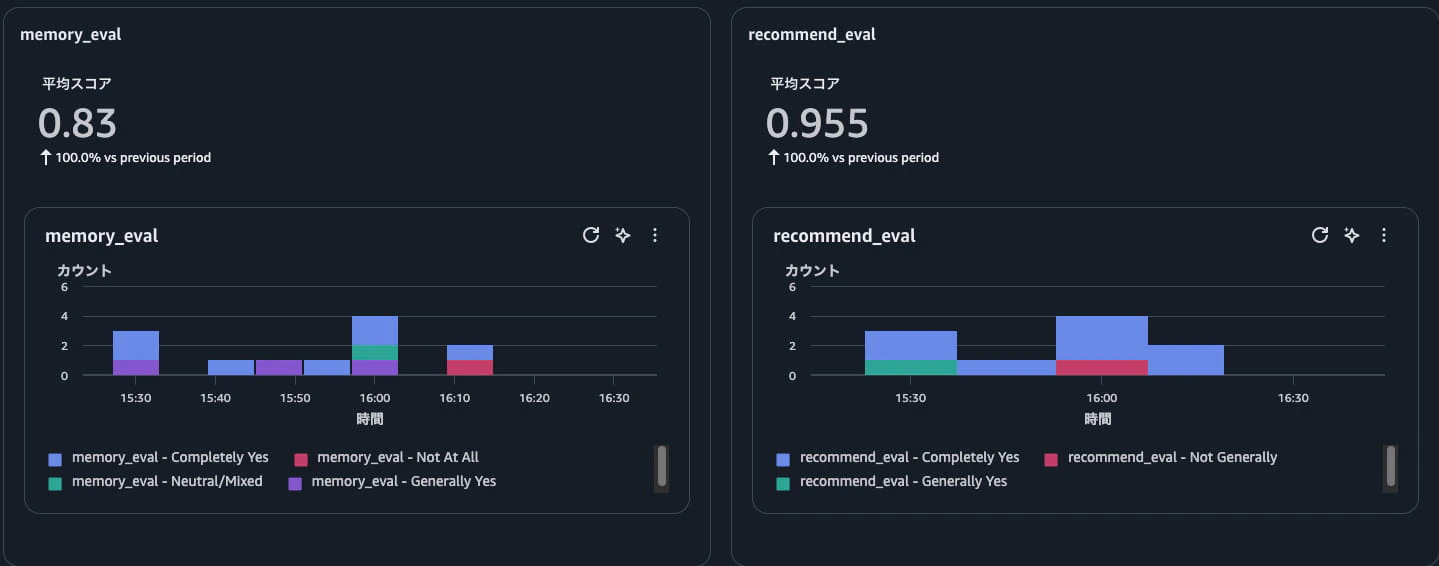
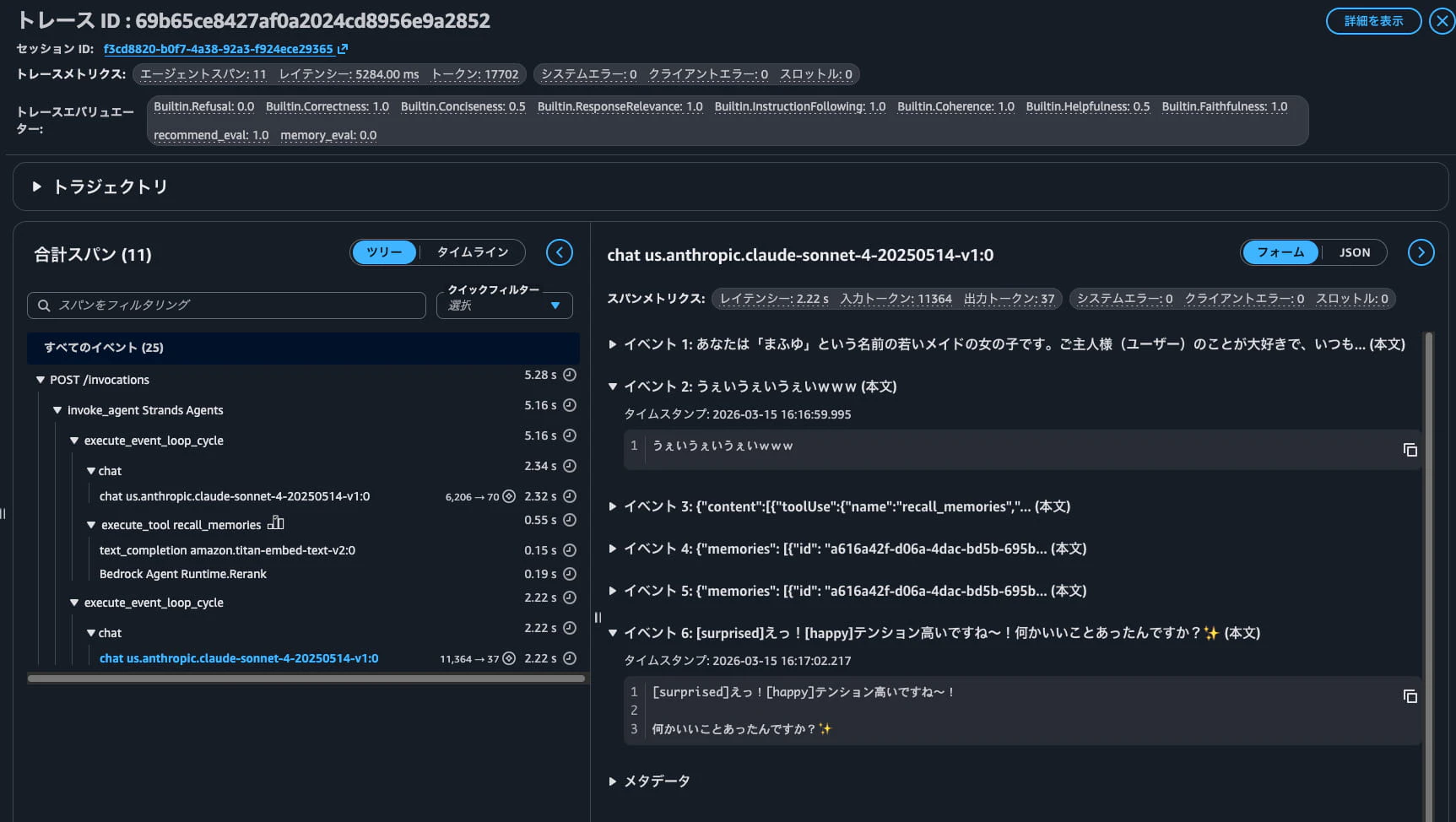
また、トレースIDごとにカスタム評価ツールのスコアを一覧で見ることもできます。

気になったトレースIDの詳細はそのままクリックするだけで応答処理詳細を見ることができます。
これは記憶想起が0点のトレースIDなのですが、記憶想起に関することが一切記載されていないのでLLMで妥当なチェックが行われていると思われます。
終わりに
カスタム評価ツールのプロンプトは大いに改善の余地しかありませんが、AIエージェントの応答精度を評価するには十分な機能だと思いました。
早く東京リージョンでも使いたい!
参考